目录
(1)项目需求
现在有一份来自美国国家海洋和大气管理局的数据集,里面包含近30年每个气象站、每小时的天气预报数据,每个报告的文件大小大约15m。一共有263个气象站,每个报告文件的名字包含气象站id,每条记录包含气温、风向、天气状况等多个字段信息。现在要求统计美国各气象站30年平均气温。
(2)数据格式
天气预报每行数据的每个字段都是定长的,完整数据格式如下。

数据格式由year(年)、month(月)、day(日)、hour(时)、temperature(气温)、dew(湿度)、pressure(气压)、wind dir.(风向)、wind speed(风速)、sky cond.(天气状况)、rain 1h(每小时降雨量)、rain 6h(每6小时降雨量)组成。
(3)实现思路
我们的目标是统计近30年每个气象站的平均气温,由此可以设计一个mapreduce如下所示:
map = {key = weather station id, value = temperature}
reduce = {key = weather station id, value = mean(temperature)}首先调用mapper的map()函数提取气象站id作为key,提取气温值作为value,然后调用reducer的reduce()函数对相同气象站的所有气温求平均值。
(4)项目开发
打开idea的bigdata项目,开发mapreduce分布式应用程序,统计美国各气象站近30年的平均气温。
(1)引入hadoop依赖
由于开发mapreduce程序需要依赖hadoop客户端,所以需要在项目的pom.xml文件中引入hadoop的相关依赖,添加如下内容:
<dependency>
<groupid>org.apache.hadoop</groupid
<artifactid>hadoop-client</artifactid>
<version>2.9.2</version>
</dependency>(2)实现mapper
由于天气预报每行数据的每个字段都是固定的,所以可以使用substring(start,end)函数提取气温值。因为气象站每个报告文件的名字都包含气象站id,首先可以使用filesplit类获取文件名称,再使用substring(start,end)函数截取气象站id。
在reducer中,重写reducer()函数,首先对所有气温值累加求和,最后计算出每个气象站的平均气温值。
完整代码如下:
package com.itheima;
import org.apache.hadoop.conf.configuration;
import org.apache.hadoop.conf.configured;
import org.apache.hadoop.fs.path;
import org.apache.hadoop.io.intwritable;
import org.apache.hadoop.io.longwritable;
import org.apache.hadoop.io.text;
import org.apache.hadoop.mapreduce.job;
import org.apache.hadoop.mapreduce.mapper;
import org.apache.hadoop.mapreduce.reducer;
import org.apache.hadoop.mapreduce.lib.input.fileinputformat;
import org.apache.hadoop.mapreduce.lib.input.filesplit;
import org.apache.hadoop.mapreduce.lib.input.textinputformat;
import org.apache.hadoop.mapreduce.lib.output.fileoutputformat;
import org.apache.hadoop.mapreduce.lib.output.textoutputformat;
import java.io.ioexception;
public class weatheranalysis {
public static class mymapper extends mapper<longwritable, text, text, intwritable> {
@override
protected void map(longwritable key, text value, mapper<longwritable, text, text, intwritable>.context context) throws ioexception, interruptedexception {
string line = value.tostring();
int temperature = integer.parseint(line.substring(14, 19).trim());
if (temperature != -9999) {
filesplit failsplit = (filesplit) context.getinputsplit();
string id = failsplit.getpath().getname().substring(5, 10);
//输出气象站id
context.write(new text(id), new intwritable(temperature));
}
}
}
public static class myreducer extends reducer<text, intwritable, text, intwritable> {
private intwritable sean = new intwritable();
@override
protected void reduce(text key, iterable<intwritable> values, reducer<text, intwritable, text, intwritable>.context context) throws ioexception, interruptedexception {
int sum = 0;
int count = 0;
for (intwritable val : values) {
sum += val.get();
count++;
}
//求平均值气温
sean.set(sum / count);
context.write(key, sean);
}
}
public static void main(string[] args) throws ioexception, classnotfoundexception, interruptedexception {
org.apache.hadoop.conf.configuration conf = new configuration();
job job = job.getinstance(conf, "weatheranalysis");
job.setjarbyclass(weatheranalysis.class);
//输入输出路径
fileinputformat.addinputpath(job,new path(args[0]));
fileoutputformat.setoutputpath(job,new path(args[1]));
//输入输出格式
job.setinputformatclass(textinputformat.class);
job.setoutputformatclass(textoutputformat.class);
//设置mapper及map输出的key value类型
job.setmapperclass(mymapper.class);
job.setmapoutputkeyclass(text.class);
job.setmapoutputvalueclass(intwritable.class);
//设置reducer及reduce输出key value类型
job.setreducerclass(myreducer.class);
job.setoutputkeyclass(text.class);
job.setoutputvalueclass(intwritable.class);
job.waitforcompletion(true);
}
}③项目编译打包
在idea工具的terminal控制台中,输入mvn clean package命令对项目进行打包
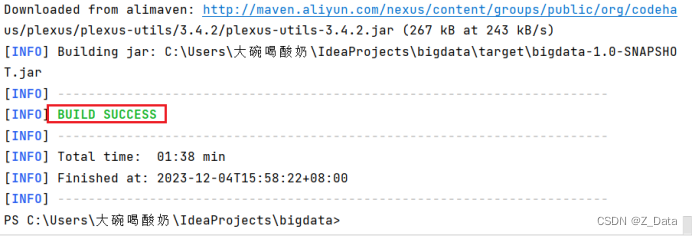
打包成功后,在项目的targer目录下找到编译好的bigdata-1.0-snapshot.jar包,然后将其上传至/home/hadoop/shell/lib目录下(没有相关目录可手动创建)

④准备数据源
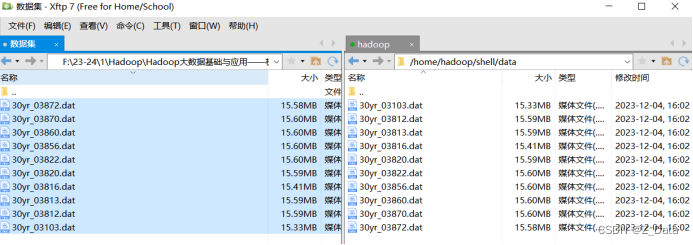
由于气象站比较多,为了方便测试,这里只将10个气象站的天气报告文件上传至hdfs的/weather目录下。(没有需要手动创建该目录)
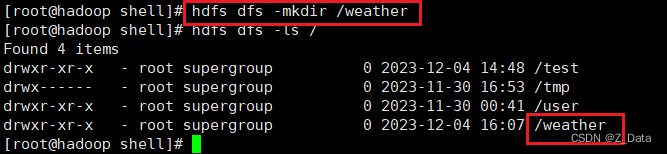
hdfs上创建/weather目录
hdfs dfs -mkdir /weather
先将数据源上传至本地虚拟机目录/home/hadoop/shell/data(该目录需要手动创建)
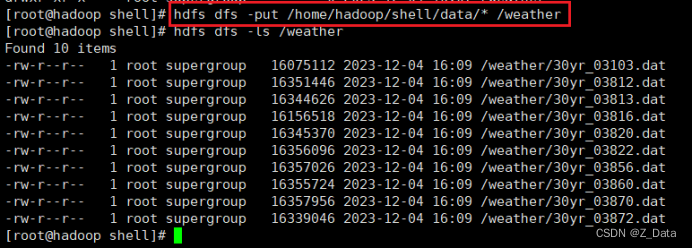
再将本地数据源上传至hdfs的/weather目录
hdfs dfs -put /home/hadoop/shell/data/* /weather
⑤编写shell脚本
为了便于提交mapreduce作业,在/home/hadoop/shell/bin目录下编写weathermr.sh脚本,封装作业提交命令,具体脚本内容如下:
#!/bin/bash
echo "start weather mapreduce"
hadoop_home=/soft/hadoop
if($hadoop_home/bin/hdfs dfs -test -e /weather/out)
then
$hadoop_home/bin/hdfs dfs -rm -r /weather/out
fi
$hadoop_home/bin/yarn jar /home/hadoop/shell/lib/bigdata-1.0-snapshot.jar com.itheima.weatheranalysis -dmapreduce.job.queuename=root.offline /weather/* /weather/out >> /home/hadoop/shell/logs/weather.log 2>&1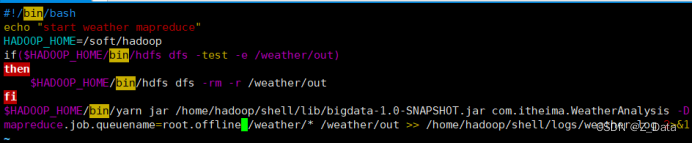
⑥为weathermr.sh 脚本添加可执行权限:
chmod u+x weathermr.sh
⑦提交mapreduce作业
到该脚本目录下,执行weathermr.sh脚本提交mapreduce作业
./weathermr.sh
⑧查看运行结果
使用hdfs命令查看美国各气象站近30年的平均气温:
hdfs dfs -cat /weather/out/part-r-00000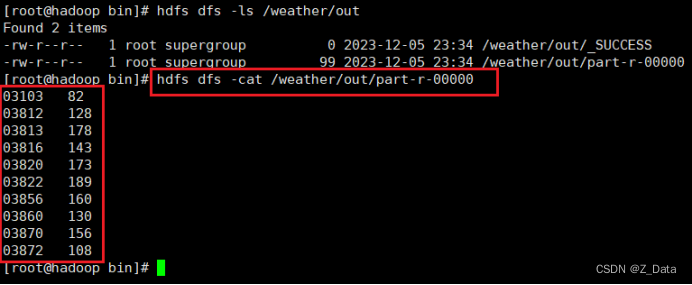

![[嵌入式系统-65]:RT-Thread-组件:FinSH控制台, 用户与RT Thread OS实时命令行交互工具](https://images.3wcode.com/3wcode/20240802/s_0_202408020258083263.png)
发表评论