文章目录
- prologue
- 欢迎大家点赞收藏与我交流讨论
- paper list
- vision-based occupancy :
- 1. [monoscene: monocular 3d semantic scene completion [cvpr 2022]](https://arxiv.org/pdf/2112.00726.pdf)
- 2. [tri-perspective view for vision-based 3d semantic occupancy prediction [cvpr 2023]](https://arxiv.org/pdf/2302.07817.pdf)
- [3. surroundocc: multi-camera 3d occupancy prediction for autonomous driving [iccv 2023]](https://arxiv.org/pdf/2303.09551.pdf)
- 4. [occformer: dual-path transformer for vision-based 3d semantic occupancy prediction [iccv 2023]](https://arxiv.org/pdf/2304.05316.pdf)
- interesting thing
- 5. [openoccupancy: a large scale benchmark for surrounding semantic occupancy perception](https://arxiv.org/pdf/2303.03991.pdf)
- 6. [voxformer: sparse voxel transformer for camera-based 3d semantic scene completion [cvpr 2023 highlight]](https://arxiv.org/pdf/2302.12251.pdf)
- 7. [occupancydetr: making semantic scene completion as straightforward as object detection](https://arxiv.org/pdf/2309.08504.pdf)
- [8.cotr: compact occupancy transformer for vision-based 3d occupancy prediction](https://arxiv.org/pdf/2312.01919.pdf)
- stereo-based
- 1. [occdepth: a depth-aware method for 3d semantic scene completion](https://arxiv.org/pdf/2302.13540.pdf)
- [2. stereoscene: bev-assisted stereo matching empowers 3d semantic scene completion](https://arxiv.org/pdf/2303.13959.pdf)
- 3. [stereovoxelnet: real-time obstacle detection based on occupancy voxels from a stereo camera using deep neural networks](https://arxiv.org/pdf/2209.08459.pdf)
- cvpr 2023 3d occupancy prediction challenge
- 1. [scene as occupancy](https://arxiv.org/pdf/2306.02851.pdf)
- 2. [occ3d: a large-scale 3d occupancy prediction benchmark for autonomous driving](https://arxiv.org/pdf/2304.14365.pdf)
- 3. fb-occ: 3d occupancy prediction based on forward-backward view transformation [[paper]](https://opendrivelab.com/e2ead/ad23challenge/track_3_nvocc.pdf)
- 4. milo: multi-task learning with localization ambiguity suppression for occupancy prediction [[paper]](https://opendrivelab.com/e2ead/ad23challenge/track_3_42dot.pdf)
- 5.uniocc: unifying vision-centric 3d occupancy prediction with geometric and semantic rendering[[paper]](https://arxiv.org/pdf/2306.09117.pdf)
- 6. multi-scale occ: 4th place solution for cvpr 2023 3d occupancy prediction challenge [[paper]](https://opendrivelab.com/e2ead/ad23challenge/track_3_occ-heiheihei.pdf)
- 7. occtransformer: improving bevformer for 3d camera-only occupancy prediction [[paper]](https://opendrivelab.com/e2ead/ad23challenge/track_3_occ_transformer.pdf)
- 今天是2023年12月31日,2023年最后一天了,在公司写完了这篇blog,这一年不能说是碌碌无为吧,也可以说是一事无成,2024希望自己越来越好,也希望自动驾驶越来越好!!!
prologue
欢迎大家点赞收藏与我交流讨论
照老样子先说为什么会写这篇文章,因为到目前我的分割大模型对实际部署的小模型并没有帮助。这让我有点郁闷,更郁闷的是后面蒸馏的环节目前也不是我在做,照理直接拿推理结果当hard label来搞也不是不可以吧。卡不够我的大模型还在训,等训完想自己上手搞一搞蒸馏,我还就不信了学不好!所以这段时间就写一写看过的paper了,看bev的时候occupancy相关的有些文章也顺便看了,写一写挺好的。
ok,那第一个,为什么自动驾驶感知都已经有bev了,又出来了occupancy(占用网格)?
这是2022年特斯拉提出来的一个“技术?”。他和bev最主要的区别就是,bev是二维的呈现形式把所有的结果在高度上拍扁了,而occupancy则是三维的,空间上的。那他的好处显而易见,他可以表达存在在空中的东西以及空间中的状态 。拿一个场景来举例,比如大家在小区的车位上会有一个地锁。或者高速收费站停车场的抬杆,这个地锁或者杆子如果你从bev的视角去看由于没有高度信息地锁关闭和打开看起来是一样的。但如果是传统2d的检测或者occupancy这样可以看到3d空间的占用状态,这样的是可以检出来的。不管怎么说,occupancy相比原来的bounding box,细粒度更高,更加能够表达物体的细节了,这些细节则代表了更多的corner case可以被解决。
下面拿雷总的图来举个例子,该图来自2023年12月28日小米技术发布会

原本的占用网格像“我的世界”一样,使用一个一个的小立方体来代表物体,立方体越小,物体的分辨率就越高,越吃算力。小米这次出的超分矢量算法还是有点东西,看起来输出的结果像是mesh拟合了物体,但没有很精细还是有很多空洞。当然这样并非首创,特斯拉在前段时间也有放出泊车视频,也是这样的形式但更加精细和连贯。
在share paper之前还是说一些题外话,占用网格理论上可以说bev的升级版,把占用网格切换到鸟瞰图的视角下就可以当bev来用。关于bev之前已经有写过文章讲过( )大家感兴趣可以看一下。
第二个是关于bev和occupancy,这两个东西并不是完全割裂的,许多bev检测的算法也都在支持occ task,比如我们之前介绍过的bevdet,方法叫bevdet4d-occ

再有就是semantic scene completion 与 occupancy,因为占用网格之前都是一个一个带语义的小方块,所以有个任务和他很相似叫做语义场景补全在semantic kitti上有个task,他的真值是对激光雷达数据的逐点标注,把他体素化后就可以拿来做occupancy的预测。现在的占用网格真值大家一般也都是这样搞起来的,当然nuscenes也可以。但这两个task还是不太一样的,3d semantic scene completion更关注于从稀疏的输入数据中恢复出完整的3d场景的几何和语义信息,而occupancy则更侧重于通过体素网格来表示和理解3d空间的占用情况。
之前我也有想过和同学一起搞一下占用网格,但是太耗资源了根本搞不起来,能搞得起占用网格的都是大户人家(ps 这是重点!!!)。在自动驾驶里面小公司是根本搞不起的,大多数公司还在追bev的方案,其实跑通真正量产了的不多,占用网络应该是下一个要追赶的技术点了。
paper list
vision-based occupancy :
1. monoscene: monocular 3d semantic scene completion [cvpr 2022]
- 点评:单目来做3d语义场景补全很难的,再加上提出的时间在22年也算比较早了,也没有用transformer,自己设计了一些模块,是不错的工作!这篇文章后面有时间我会专门出一篇来细讲。当然作为经典工作肯定会是被后面出来的新工作各种摩擦。
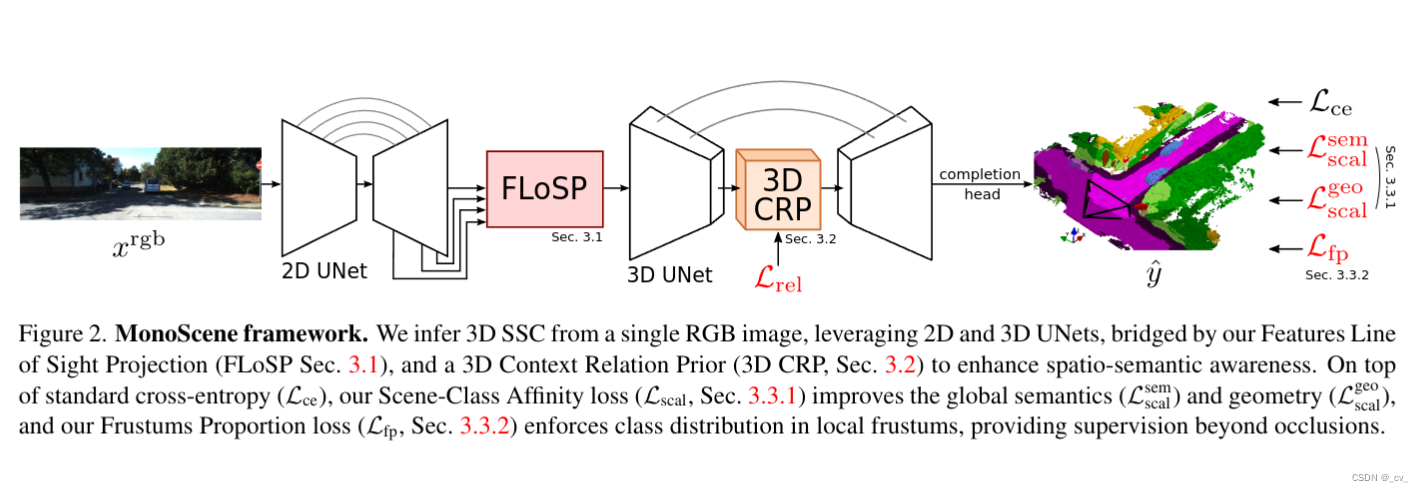
对着上面的图通俗易懂的简单说一下,一个图像进来,过2d unet,flosp(features line of sight projection),再过3d unet,3d unet中间插入了一个3d crp(3d context relation prior)模块,然后做语义补全任务。
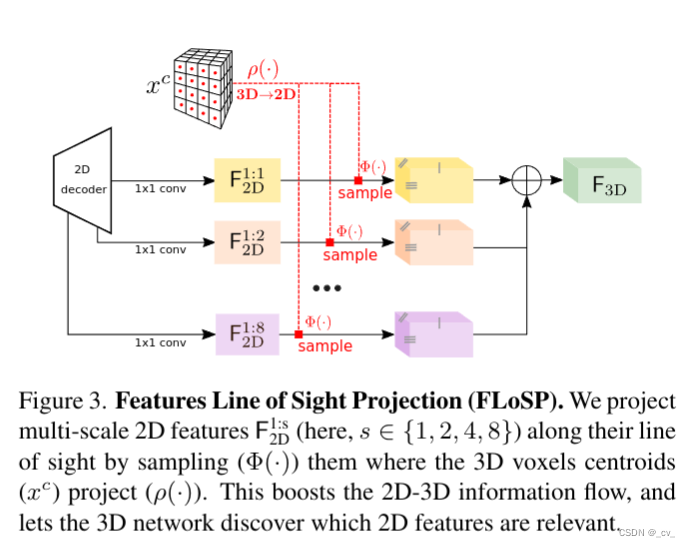
最核心的是flosp模块,如何将2d特征提升到3d? 其实就是从不同尺度下3d投影到2d,拿到多个尺度采样特征后混合相加完了给后面的3d unet,就是这样。
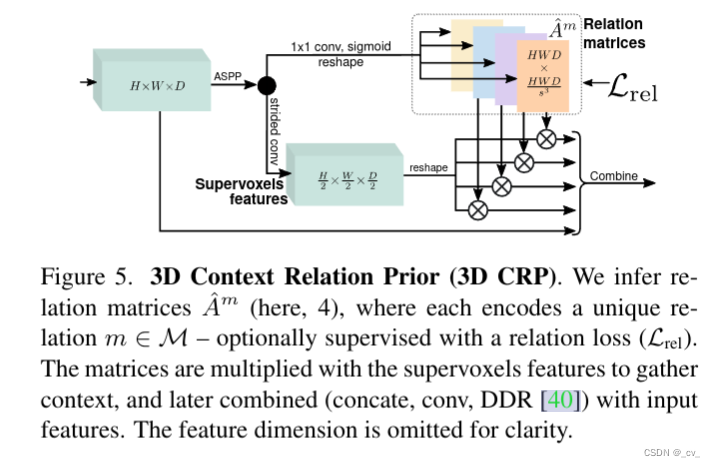
剩下的3d context relation prior也不细说,关系矩阵和超体素特征点乘也算是一种算注意力了,超体素是用来建模体素空间关系的。后面的loss设计部分大家也可以看一看的。
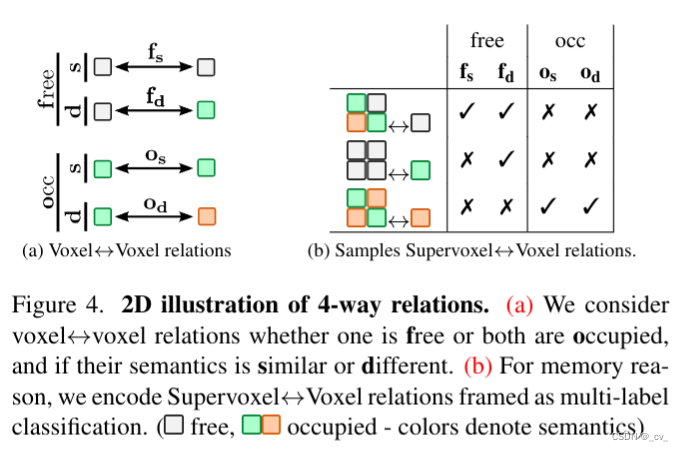
2. tri-perspective view for vision-based 3d semantic occupancy prediction [cvpr 2023]
-
点评:清华和鉴智的工作,说是首次证明基于视觉的方法在nuscenes lidar分割任务上实现了与基于lidar的方法相当的性能。当然也在semantic kitti上测了但没说。可惜的是跑起来太慢了,当然这也是所有occ算法的通病。不过有个点是,他们的工作也比较有连续性,截止到2023年12月29日在github看到他们在上个月发布了占用网格世界模型!,突出一个紧跟时事。


-
基本流程:简单和大家说一下,就是voxel太慢太复杂,bev拍扁了,tpv用三视图来做
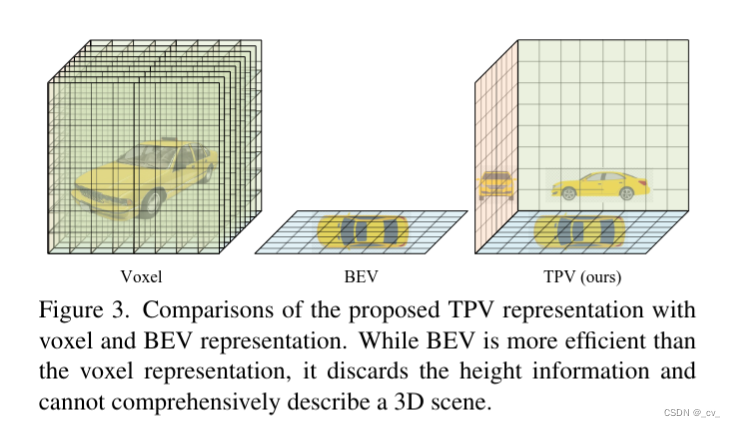
复杂的就不讲了,看paper里面的公式,1是体素表达xyz,2是bev表达xy,3 4 5 是三视图表达xy,zx,yz。s是sampling,v,b,t都是features。

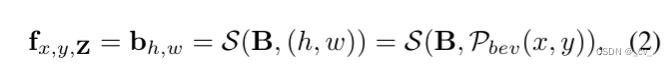
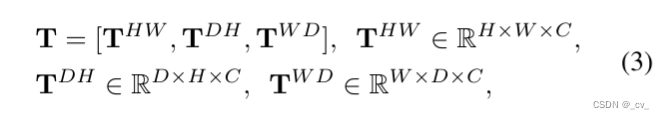
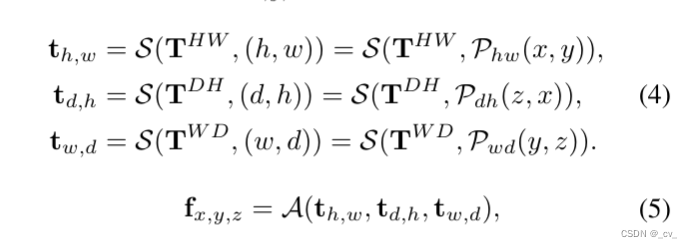
整体流程:
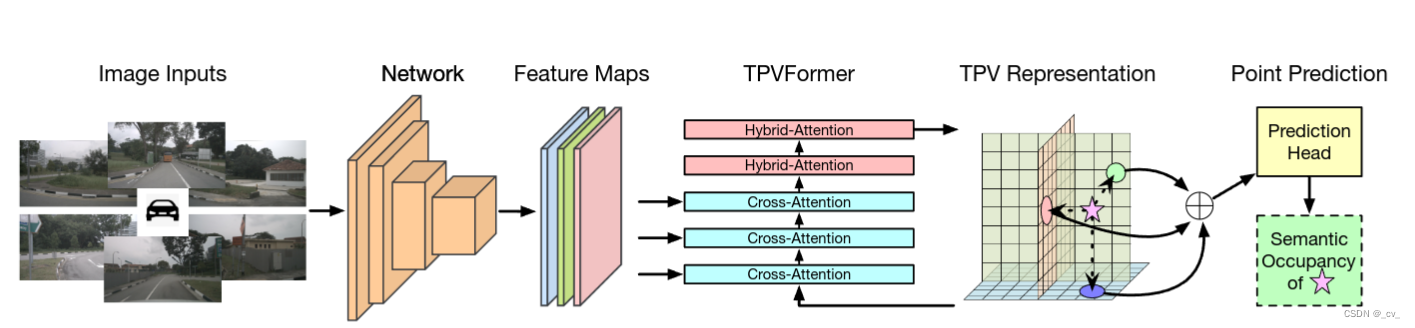
至于网络特征怎么提取,transformer怎么做注意力大家可以看文章,后面有时间应该会对文章有更细致的讲解,核心思想就是我的特征是从三个视图拿到的加起来,然后去做prediction。就是这样。
然后给大家share一下,“米式对比法”,看看就好。
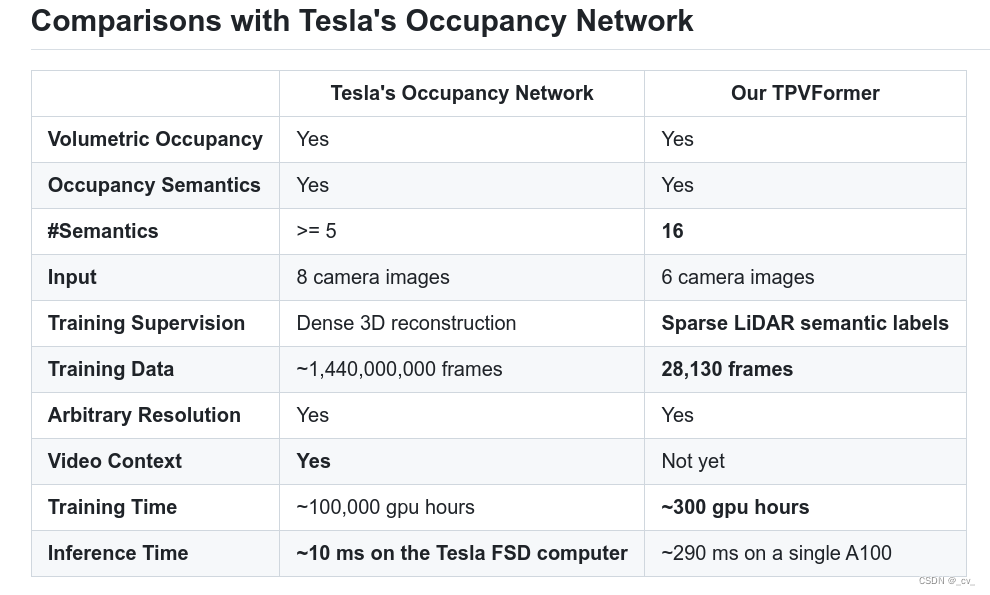
3. surroundocc: multi-camera 3d occupancy prediction for autonomous driving [iccv 2023]
-
点评:清华天大和鉴智的工作,部分是原班人马,不过这次思路完全不一样了,不搞三视图了。由于是靠后一些出的文章,所以结果当然会比tpvformer强很多。
-
基本流程:如下图多张图像经过backbone network((e.g. resnet-101)后出来的是多尺度的特征图x,然后每个体征图分别过2d-3d spatial attention模块,将2d特征转为3d,再然后将上一层3d特征进行反卷积和本层特征相加拿到最终特征后,再做occupancy prediction,这里不同尺度的预测每一个都是有监督的。

-
总体流程讲完再简单说一下关键点
2d-3d spatial attention:就是把2d特征转到3d空间下的模块。首先3d体积查询定义为q∈rc×h×w ×z,这个q就是3d reference point,然后对于每个q,会根据给定的内外参将其对应的 3d 点投影到 2d 视图(就是虚线箭头部分)。然后只使用 3d 参考点命中的点,在这些投影的 2d 位置周围采样 2d 特征(怎么采样就是下面的deformattn,qp查询是3d 参考点,p(qp,i )是2d采样,x是camera feature)。模块输出 f ∈ rc×h×w ×z 是根据可变形注意机制的采样特征的加权和。公式化如下:
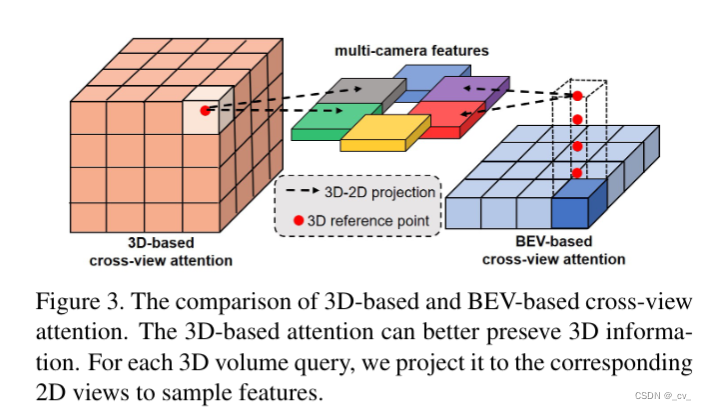
都看到这里了那就再说一下他这个bev-based cross-view attention是怎么个意思也很容易,大家都知道bev是没高度的,而xy是确定的,所以一般会在bev的z轴上采样出几个固定的高度来,拿到坐标的xyz之后再投影到图像上。

- 然后有趣的地方是:和 bevformer的时间交叉注意力有些异曲同工之妙,当然代码部分也是一样的只是换个说法。

至于multi-scale occupancy prediction这个部分上面其实已经说过了,下面就是公式化,deconv就是反卷积拿来做上采样,这算个小知识点,大家不熟悉的可以了解一下。

总结说一下,上面提到的只是关键点,其实还有很多细节的部分是没有提到的,这个大家一定要知道!!!
4. occformer: dual-path transformer for vision-based 3d semantic occupancy prediction [iccv 2023]

-
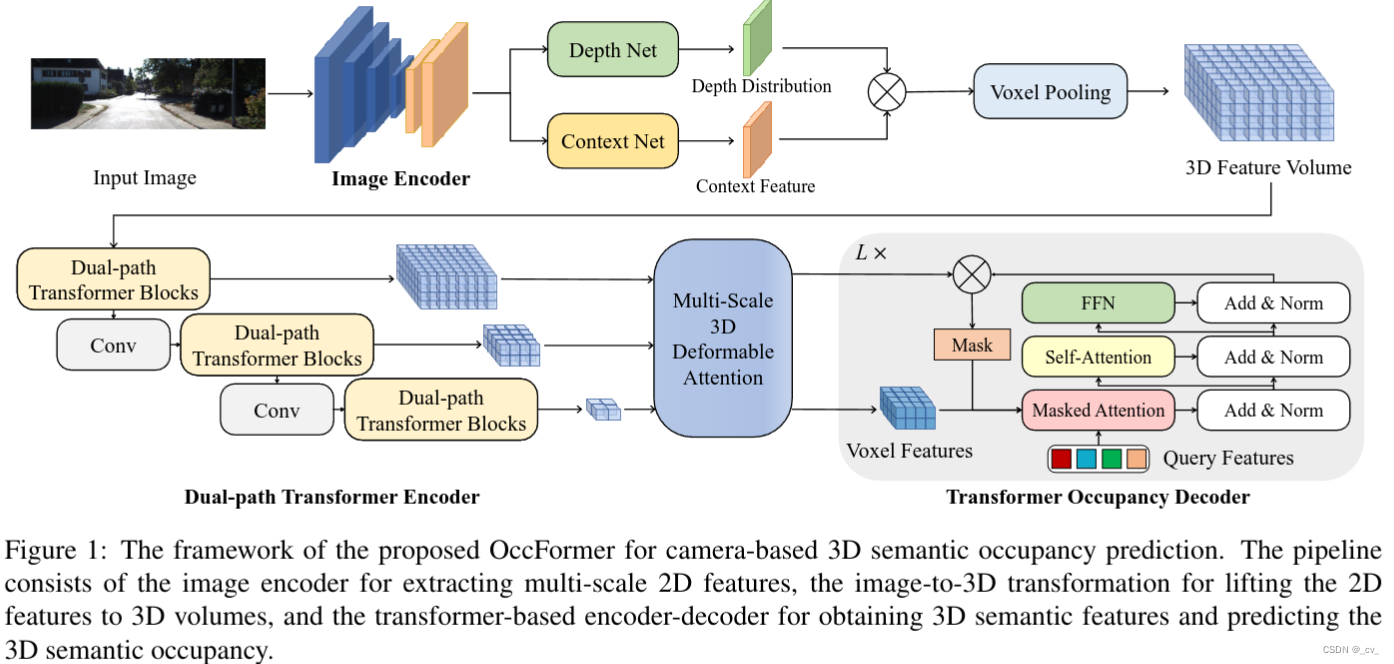
点评:这篇就比较厉害了,全是鉴智的人,而且还挂了联合创始人兼cto都大龙,按道理挂大佬名字的paper一般都不会太差,当然本身也没有太差毕竟也是iccv2023。先上流程图
-
-
本文提出了 occformer,一种用于基于相机的 3d 语义占用预测的双路径变换器网络。为了有效地处理相机生成的 3d 体素特征,提出了双路径变换器块(dual-path transformer encoder),它有效地捕获了具有局部和全局路径的细粒度细节和场景级布局。此外也是第一个使用掩码分类模型进行 3d 语义占用预测的人。鉴于固有的稀疏性和类不平衡,所提出的保留池和类引导采样显着提高了性能。occformer 在 semantickitti 测试集上实现了语义场景补全的最先进的性能,在 nuscenes 测试集上实现了基于相机的 lidar 分割。好,先简单说一下上面的depth 和context点乘这是lss的经典操作,下面的我们看重点看几个
-
dual-path transformer encoder
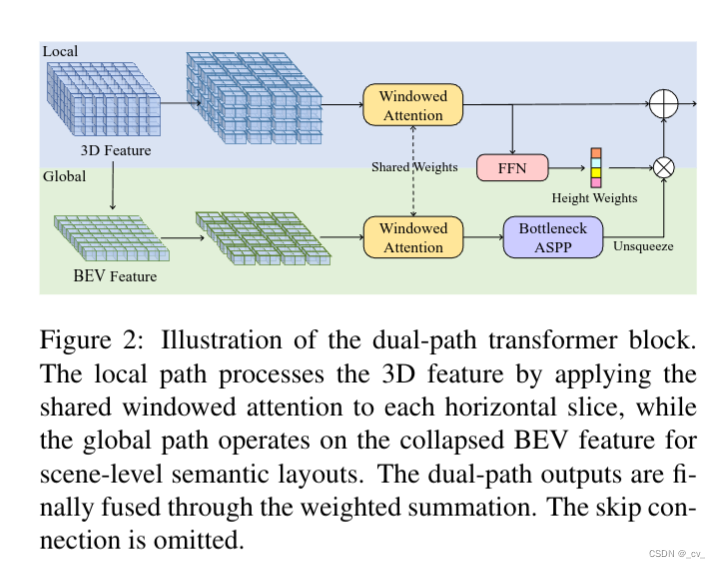
这里的局部细粒度细节和全局路径的场景级布局是怎么搞的呢?local path 主要是提取细粒度语义结构。水平方向包含了最多的变化,所以用一个共享编码器,来并行处理所有 bev 切片,同时保留大部分语义信息。具体来说,我们将高度维度合并到批次维度(batch dimension)中,并采用 windowed self-attention 作为局部特征提取器可以动态地关注具有适度计算的远程区域。(这里的窗口自注意力就是在一个固定范围内算自注意力,如果大家不了解注意力机制,这不行,这得了解,后面看什么时候我把去年做的transformer ppt放出来)global path 的目的是有效地捕捉场景级的语义布局 ,首先通过沿高度维度的平均池化来获得bev特征,利用来自 local path 的相同的windowed self-attention 来处理相邻语义的bev特征。由于发现 bev 平面上的 global self-attention 会消耗过多的内存,因此采用aspp来捕捉全局的语义。公式化输出如下

中间的multi-scale3ddeformableattention就不说了,见过很多次了无非就是2d变3d用到三线性特征采样trilinear feature sampling。接下来说一下transformer occupancy decoder ,就是transformer 的decoder,这一层特征加上上一层的特征,确实没啥好说的。至于里面提出的preserve-pooling就是个max-pooling也没啥特别只是用的比较好;class-guided sampling就是添加类别权重的超参,看起来高大上罢了。


ok,到这里就可以开始讲一讲
interesting thing
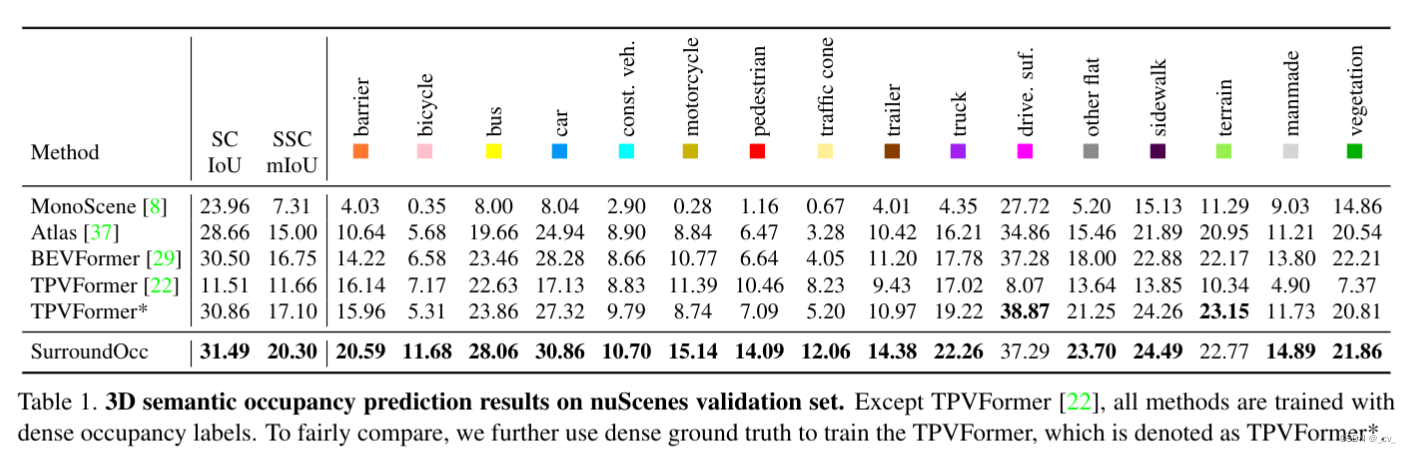
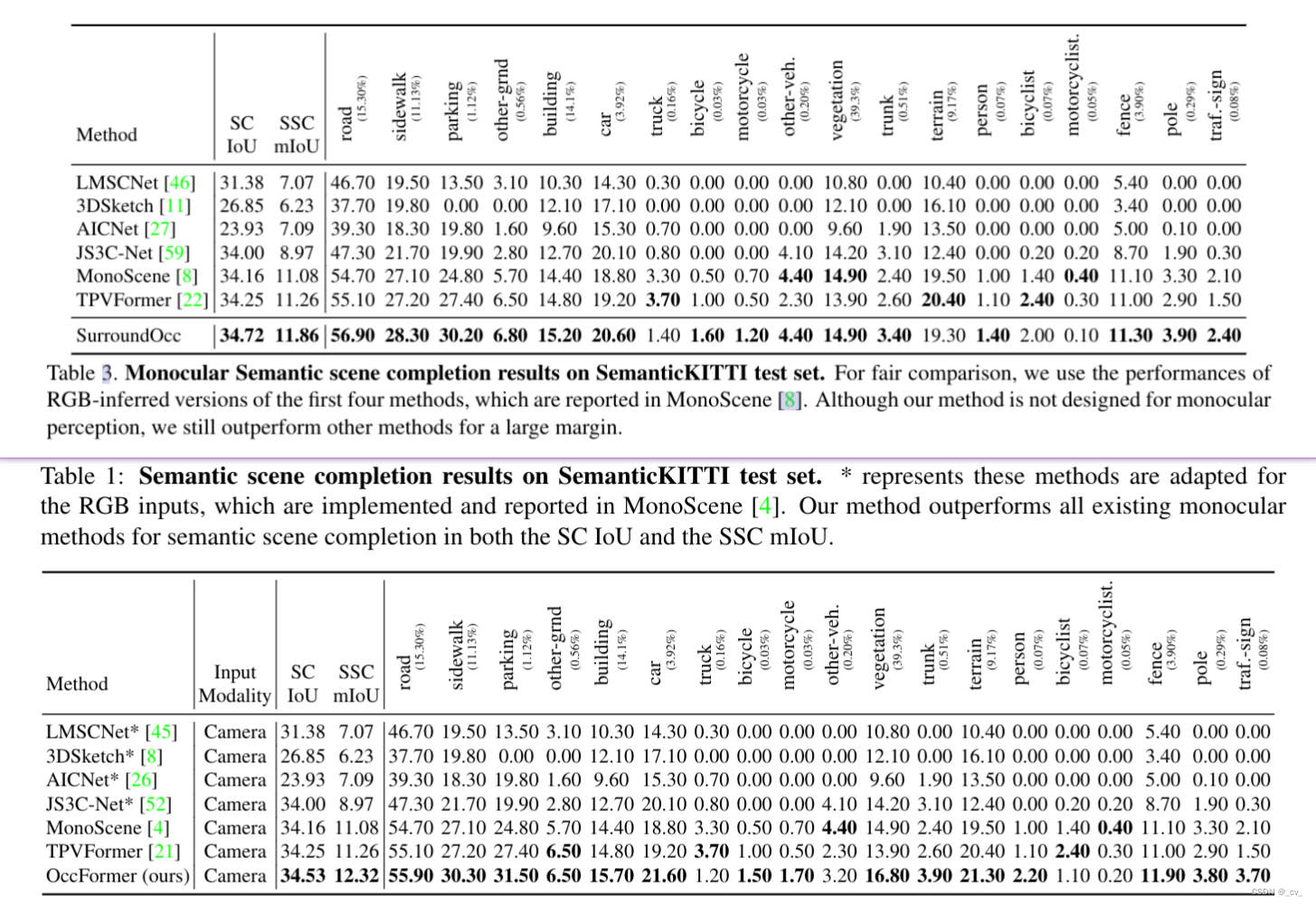
这是在tri-perspective view for vision-based 3d semantic occupancy prediction, cvpr 2023,github官方的代码仓库贴出来的信息,一般来说后出来的paper效果都应该好一些,但大家请看下面两个表格,上面的是前面讲过的surroundocc(iccv 2023),下面是我们这篇文章的occformer(iccv2023)。好像后面发出来occformer还要差一些,同时也没和自己的工作surroundocc对比(应该那时候surroundocc还没中)
(不重要的ps,如果大家以后为了能发paper只跟差的比不跟好的比那就没意思了,搞学术还是得严谨一点)
5. openoccupancy: a large scale benchmark for surrounding semantic occupancy perception
-
点评:同样是一篇挂了大佬名字,也是今年iccv 2023的paper。也同样有鉴智和清华,当然也有来自中国科学院自动化研究所和中国科学院大学的。这篇就简单说一下,因为这篇主要不是做网络而是做benchmark,而且最重要的是没什么好说的,这篇不是重点,下一篇才是重点,重点到什么程度呢?这么跟你说,这也是一篇我非常欣赏的工作。这篇讲的是现有的相关基准缺乏城市场景的多样性,它们只评估前视图预测。为了对周围的感知算法进行全面基准测试,我们提出了openopcupancy,这是第一个周围的语义占用感知基准。在 openopcupancy 基准测试中,我们扩展了具有密集语义占用注释的大规模 nuscenes 数据集。
-
人员构成大家自己看一下
-
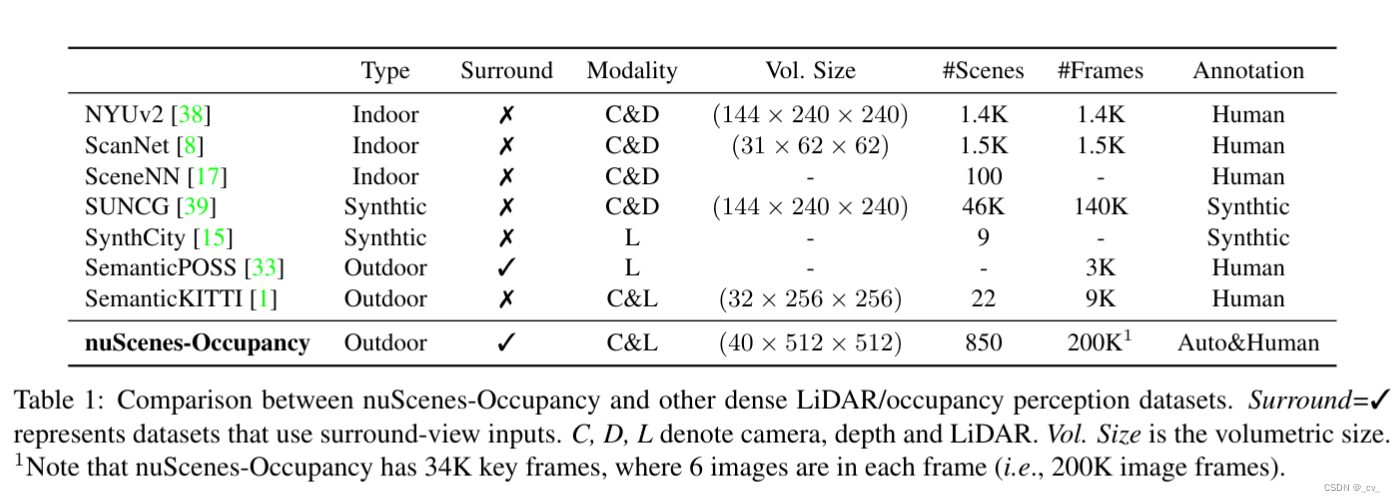
和其他数据集的对比
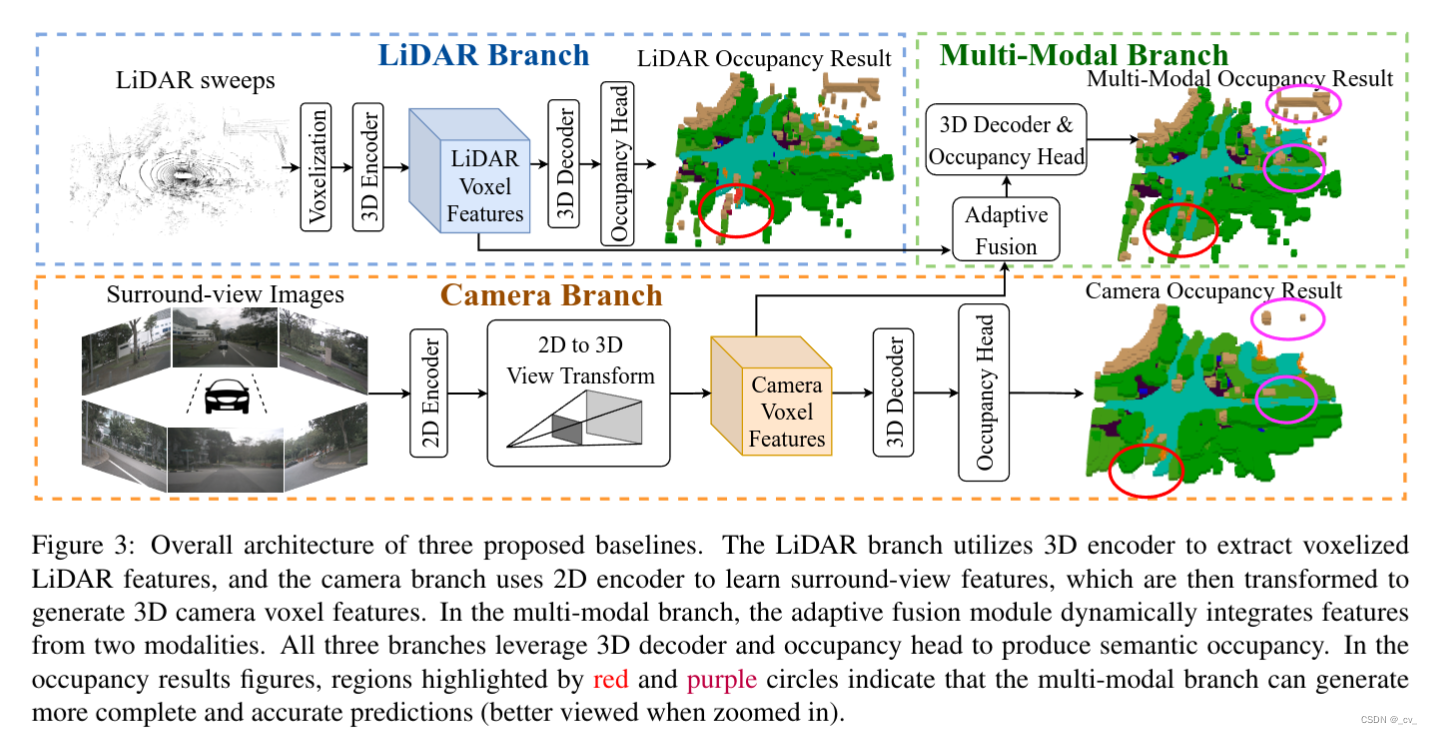
(机器翻译如下:lidar 分支利用 3d 编码器提取体素化的 lidar 特征,相机分支使用 2d 编码器来学习环绕视图特征,然后将其转换为生成 3d 相机体素特征。在多模态分支中,自适应融合模块动态集成两种模态的特征。所有三个分支都利用 3d 解码器和占用头来产生语义占用。在占用率结果中,红色和紫色圆圈突出显示的区域表明多模态分支可以生成更完整和准确的预测(放大时效果更好)) -
cascade occupancy network以及可视化效果

- share了一下别人的算法在自己的数据集上的效果,遥遥领先

结束下一篇!
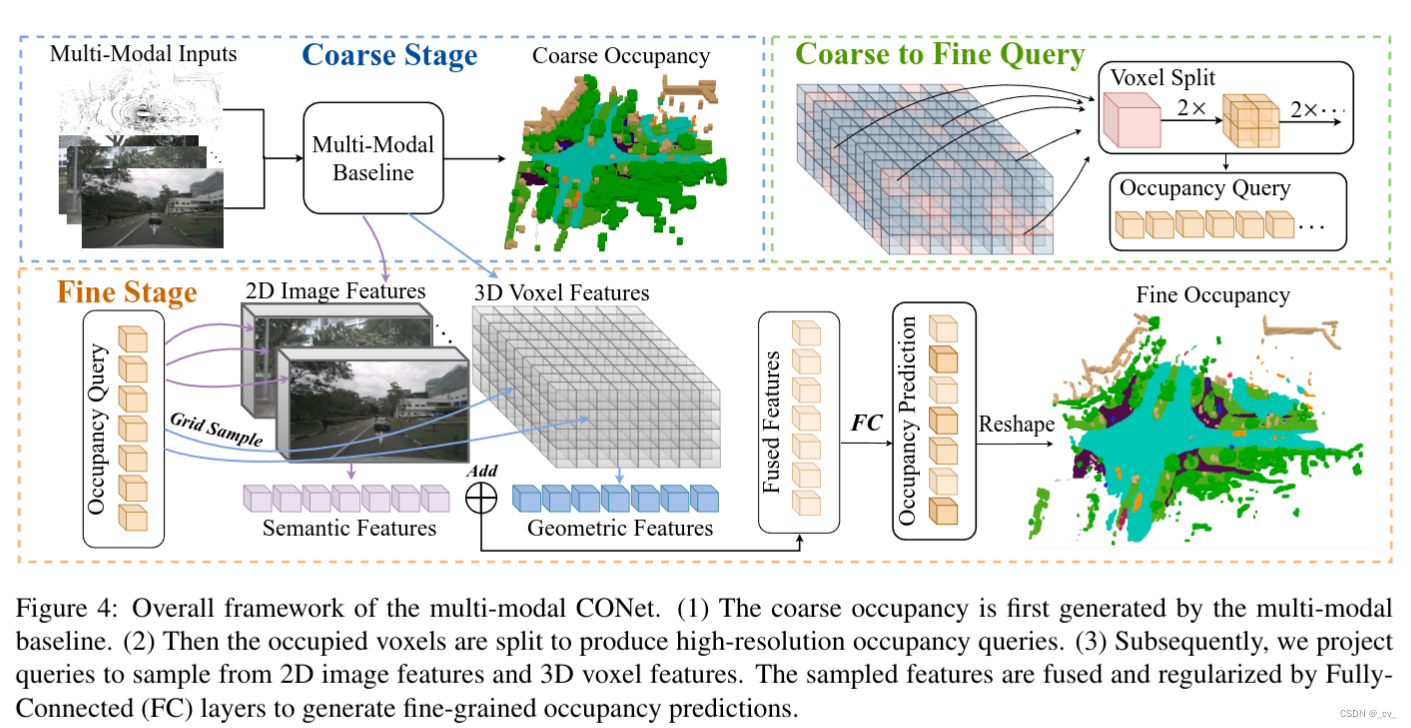
6. voxformer: sparse voxel transformer for camera-based 3d semantic scene completion [cvpr 2023 highlight]

- 点评:nvidia出品还是有点东西的,这篇文章提出了一个一种新颖的将图像提升到一个补全 3d 体素化语义场景的两阶段框架,一种新的从图像深度生成可靠查询的基于二维卷积的query proposal network,一种新的transformer,类似于掩码自动编码器(mae)但它可以补全完整的3d场景表示。更重要的voxformer在semantickitti上为基于相机的ssc拿到了sota,大家可以看一下结果先。其他工作也有和monoscene的对比,涨点多少就不说了,并且人家在训练期间将 gpu 内存减少到不到 16gb,这才真是遥遥领先!occupancy不是谁都能搞最重要的就是显存不够,卡不够,搞轻量搞实时才是王道,现在的占用网络都太重了!
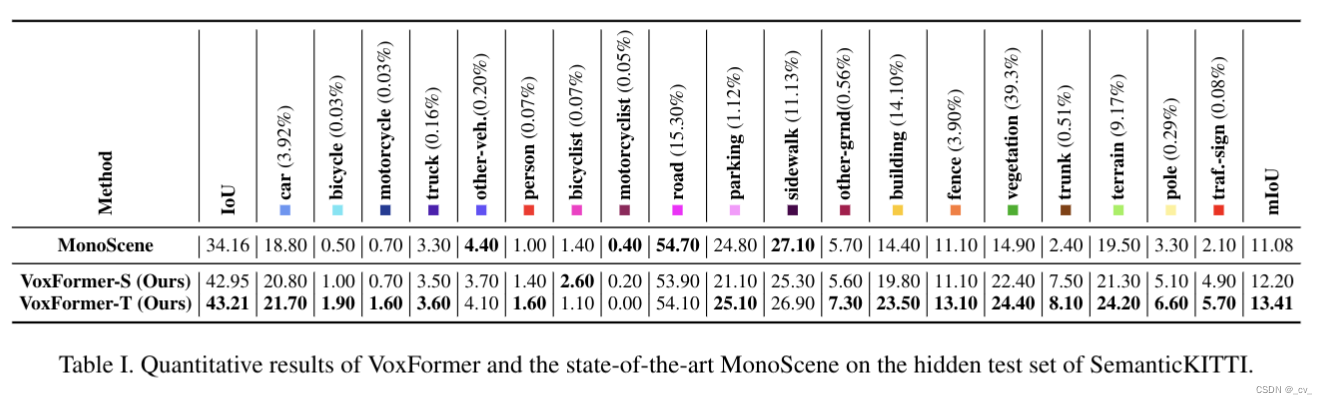
- 当然缺点也不是没有,受深度估计的影响,深度在远处的位置非常不可靠。解耦远程和短程ssc是增强远离自我车辆的ssc的潜在解决方案,这也是他们未来的工作。
- 下面就重点来看这个网络是怎么做的,之前在其他博客里面也有说过,好的paper只要图看懂了文章也就看懂了,我们从图看起,按图来简单讲一下(如果对着代码来讲那就是复杂讲一下了)
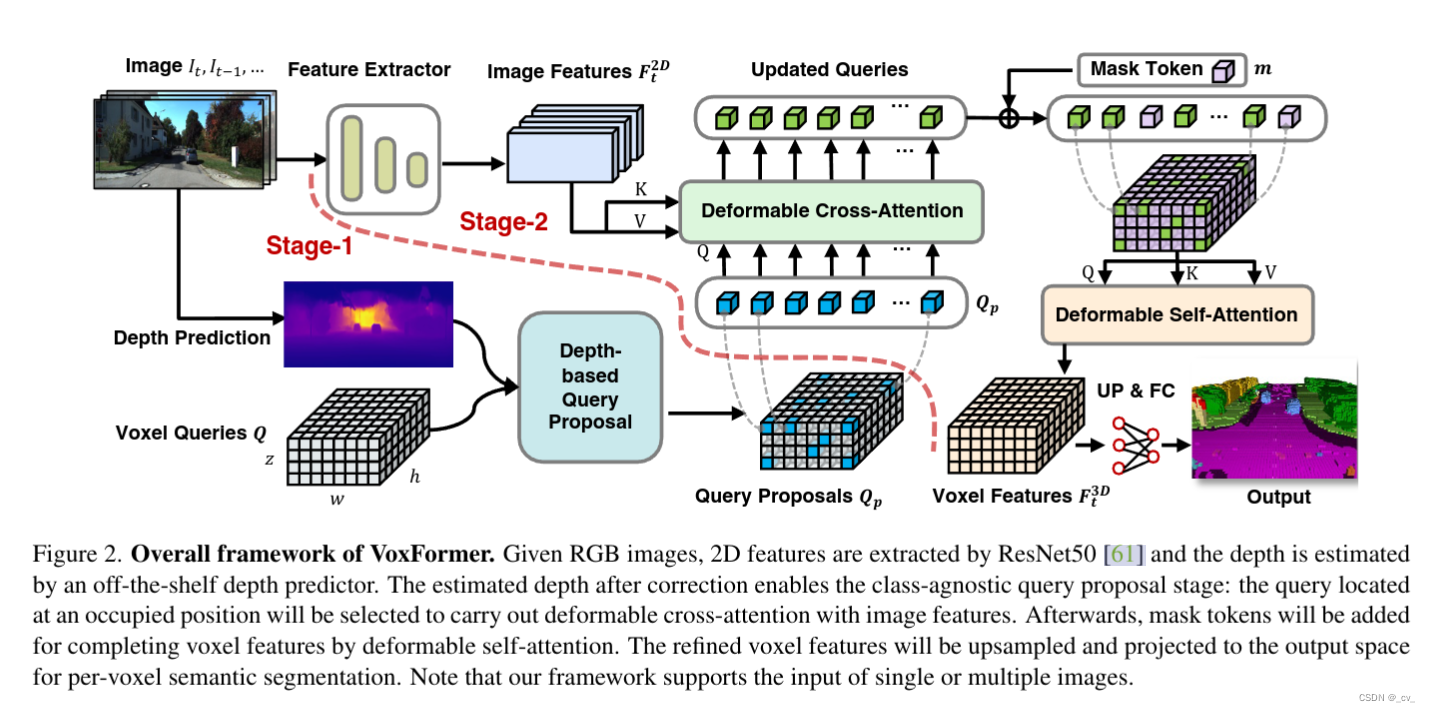
image序列过来后会先进行depth prediction,这里是直接利用现成的深度估计模型,如单眼深度或立体深度估计,直接预测每个图像像素(u, v)的深度z(u, v)。之后,深度图 z 将反投影到 3d 点云中,但由此产生的3d点云质量较低,特别是在远程区域。(因为地平线的深度非常不一致;只有少数像素决定了大区域的深度)。
depth prediction 下面有个voxel queries q,预定义的体素查询为 3d 网格形可学习参数 ,q ∈r h×w×z×d 其中 h × w × z 的空间分辨率低于输出分辨率 h × w × z 。
接着depth prediction 和voxel queries q被送到depth-based query proposal。这里有一个点,为了获得好的q,使用模型 θocc 以较低空间分辨率预测占用图来帮助校正图像深度。具体来说,首先将合成点云转换为二值体素网格映射图m(in),如果至少占用一个点,每个体素被标记为1。然后我们可以通过 m(out) = θocc(min) 预测占用率,其中 m(out) ∈ {0, 1}h×w×z 的分辨率低于输入 m(in) ∈ {0, 1}h×w ×z,因为较低的分辨率对深度误差更稳健并与体素查询的分辨率兼容。简单来说就是低分辨率更鲁棒现在就可以来proposal q了,q是怎么出呢?
q从上面的低分辨率预测占用图来选,这样的话通过删除许多空白空间和保存计算和内存,再者通过减少错误 2d 到 3d 对应关系引起的歧义来简化注意力学习。
到这里就完成了第一个阶段的class-agnostic query proposal,接下来就是第二个阶段class-specific segmentation.
resnet-50 backbone来 提取 2d features ,然后2d 的feature作为k,v,有了第一阶段的q,就可以做注意力了。
deformable cross-attention 老熟人了,2d 3d版本也都有了。

经过几层可变形交叉注意后,q将被更新。然后我们再接着看就能看到mask token了,这就是类似于掩码自动编码器(mae)的3d场景补全了。在前面虽然选择了一些体素查询来处理图像;剩余的体素将与另一个可学习的参数关联起来补全3d体素特征。为了简洁起见将这种可学习的参数命名为mask token,因为没被选择的q,就类似于从q中被屏蔽掉了。具体来说,每个mask token是一个可学习的向量,表示存在一个待预测的缺失体素,位置嵌入也被添加。mae也是如此,重建mask掉的token。
输入的token有了,接下来就是算deformbale self-attention,获得refined voxel features。


在往后就是上采样和全连接,输出预测结果。

- 部分实验对比
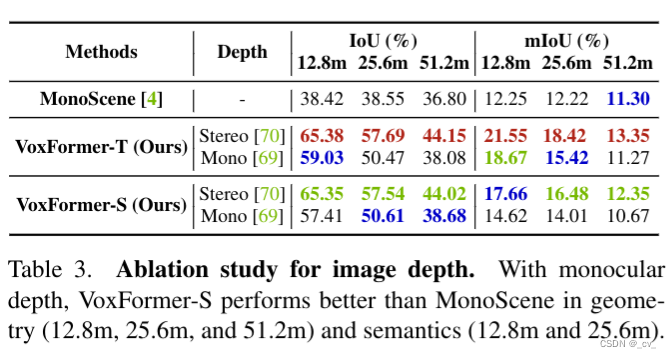
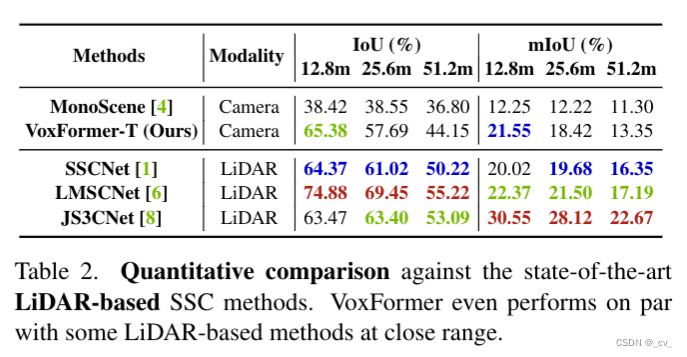
语义场景补全还是雷达比较强。主要特斯拉走纯视觉路线出的占用网格,大家也都跟着做视觉。国内感觉目前主流的贵的方案里面还是有用激光雷达,华为,理想,小鹏,小米等等。
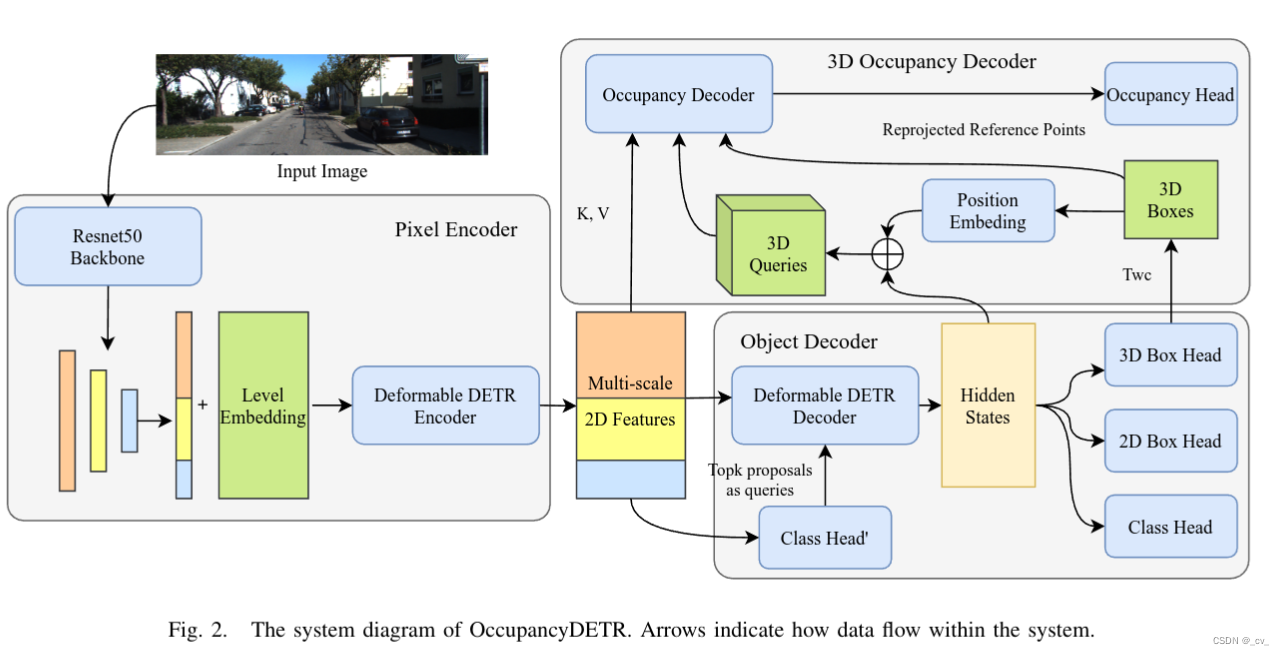
7. occupancydetr: making semantic scene completion as straightforward as object detection
- 点评:先做检测然后占用,参数不多效果不错,显存占用还行,train用24g 3090,evaluation可以用16g 3080。其实挺好的,但这些新文章后面有空再细讲吧。
8.cotr: compact occupancy transformer for vision-based 3d occupancy prediction
- 点评:最近也有陆陆续续跟arxiv上有关占用网络的文章。这篇从指标看算是不错的,也是离现在比较近的paper,但是主要没开源所以不讲,当然并不排除后面开源的可能,这里也mark一下。
stereo-based
抱歉这里把双目的语义补全单独列了出来,主要是单目可以当多目来用也还好,但双目输入来做占用网络就有些特别了,他要求是左右两个视图。而且上面也有说语义场景补全和占用网格的区别,所以可以简单看一下。
1. occdepth: a depth-aware method for 3d semantic scene completion
- 点评:旷世的工作,第一个提出stereo ssc method,叫occdepth。并且还提出了一个修改过的tartanair benchmark, 叫 semantictartanair。先看一下网络大体长什么样子
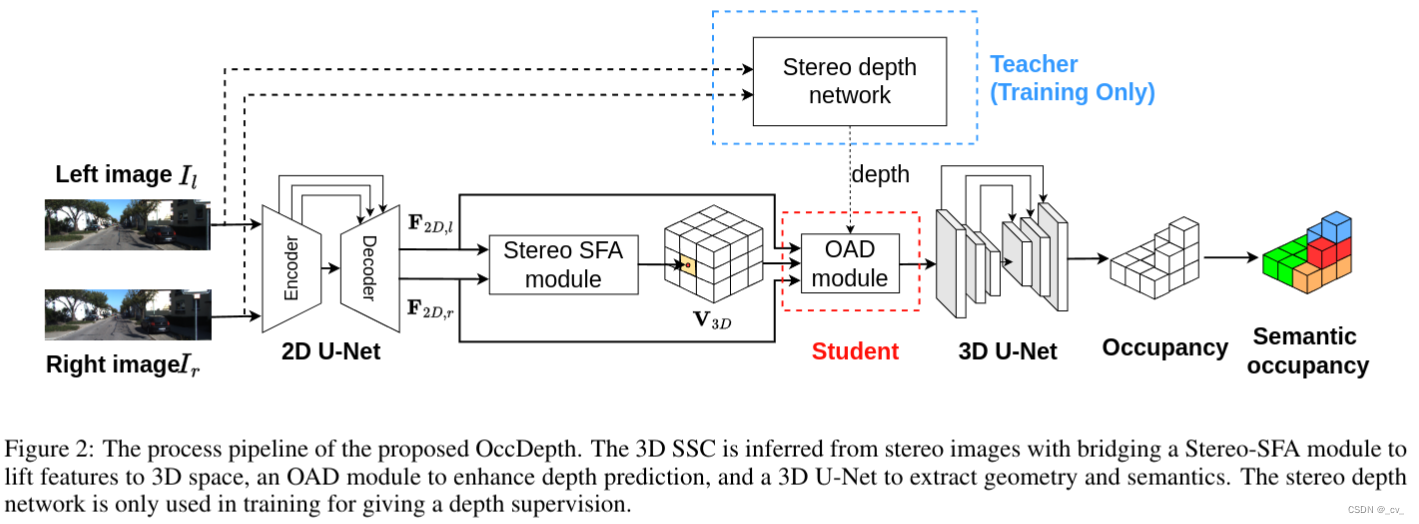
输入左右两个视图的图像过2d u-net编码成二维特征f2d,l, f2d,r∈rh×w ×c。然后将二维特征融合到三维体素中,通过立体软特征分配(stereo - sfa)模块学隐式深度信息。接下来,通过占用感知深度(oad)模块将显式深度信息添加到3d特征中。
-
stereo soft feature assignment module 如下。通过计算左右二维特征之间的相关性得到的隐式深度信息被编码为三维特征的权重。
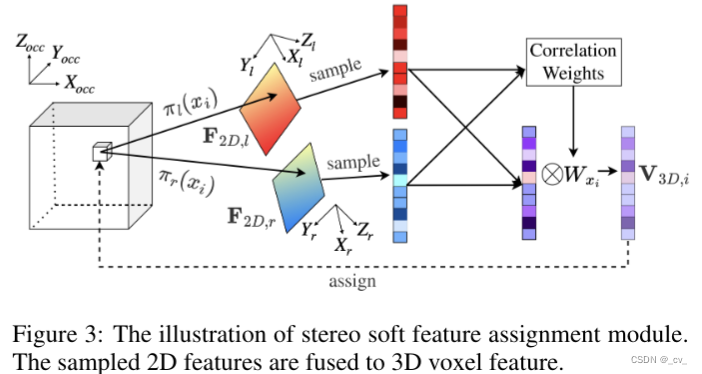
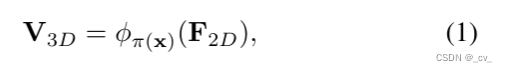
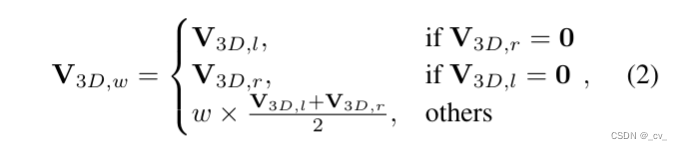
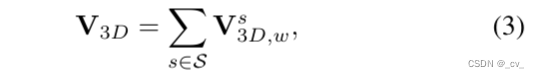
上面有三个方程,这三个方程就是stereo soft feature assignment module的过程了。首先公式一中x是voxel的中心坐标,3d-2d投影表示为π(x),φx(m)是采样在坐标x处的特征映射m。直白的解释就是从图像特征中采样出对应的3d体素特征。当投影的2d点在图像之外时,3d特征将设置为0。
公式二是用来将从左右特征图中采样出的3d特征进行加权融合。其中 w 表示由 v3d,l 和 v3d,r 之间的相关性计算的权重。在文中用的是余弦相似度来衡量特征的相关性。可以和上面的图对应上。
公式三是为了扩大感受野,用的多尺度 2d 特征图,其中 s = {1, 2, 4, 8} 是一组下采样尺度。 -
接下来是occupancy-aware depth module,下面的图为了简单起见仅展示了单图像 的处理流程。
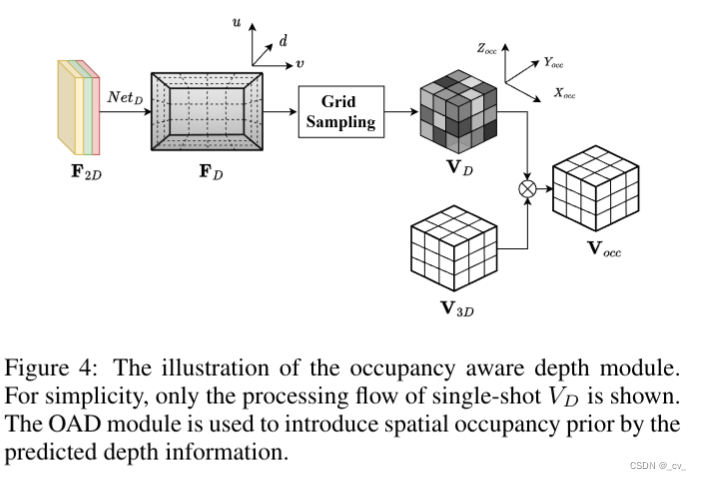
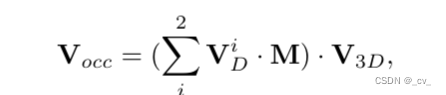
首先,单尺度图像特征f2d过来后,用一个netd来预测多视图输入图像的深度特征 fd;然后使用 softmax 将fd变换为截锥体的深度分布gd,在然后利用摄像机标定矩阵p∈r3×4,将截锥深度分布gd转换为具有可微grid sampling过程的体素空间深度分布表达vd∈rx×y ×z。
公式中中 m 是用来平均左右两个输入之间重叠区域的体素像素的掩码,重叠区域的值为 0.5,其他值为 1.0,vd 可以表示为体素空间中的占用概率先验。然后乘起来拿到感知占用的体素特征vocc。
2. stereoscene: bev-assisted stereo matching empowers 3d semantic scene completion
- 点评:是一篇2023年3月份的文章,从github来看关注不多,截止到目前没中什么会议期刊,前面讲了那么多后面就不再细讲了,除非有特别不错的paper。后面的paper更多是题外话了。
- 题外话一

在这篇paper对比的方法里提到了很多3d semantic scene completion的方法,有一些可能讲过有些没有,因为我们也不可能把所有的paper都看完,所以可以挑自己感兴趣的去看,一般文章里面都会有方法有做归纳总结,是基于什么什么的之类。
3. stereovoxelnet: real-time obstacle detection based on occupancy voxels from a stereo camera using deep neural networks
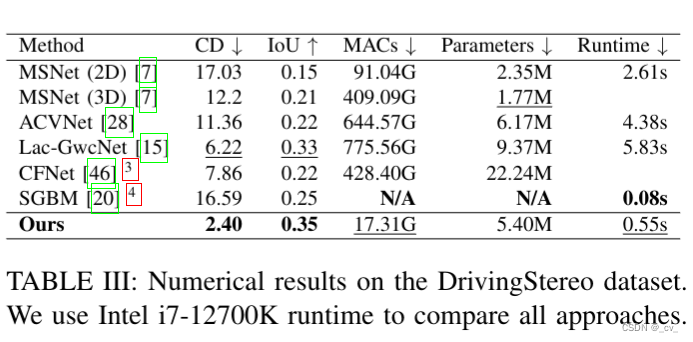
- 点评:这是一篇与机器人相关的工作,利用深度神经网络直接从立体图像中检测占用率,很轻量。说用nvidia jetson tx2可以跑到实时,但我在文章中并没有明确看到tx2运行帧率,到是有i7-12700k的。受到关注也不多
小车车长下面这样

这个东西大家看效果就知道,只有占用没有语义

cvpr 2023 3d occupancy prediction challenge
这一类也比较特殊,属于没开源但实打实可以涨点的,可以学习一下技巧。
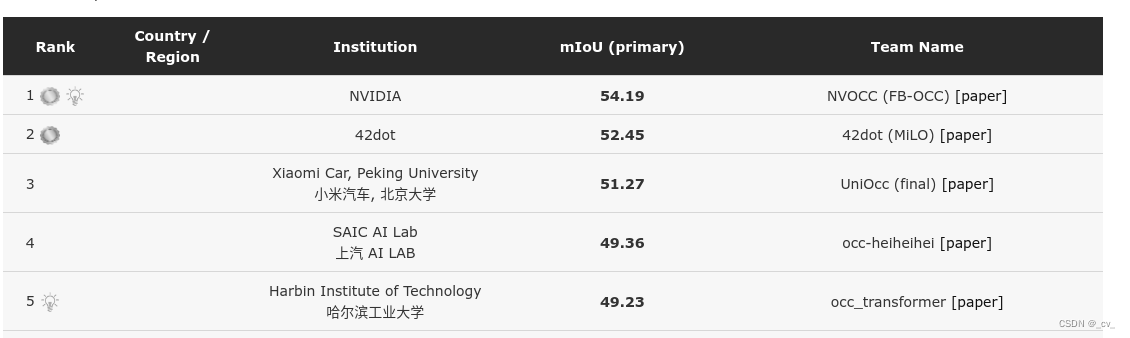
1. scene as occupancy
- 点评:两个贡献,一个网络一个benchmark(openocc provides surrounding camera views with the corresponding 3d occupancy and flow annotations.)这个上面也有出现过benchmark,baseline什么的,这个也没和大家细说。benchmark就是说,现在情况变了时代进步了社会发展了,原来的那些数据集或者说测试基准不能满足时代发展的需要了,所以我们要建立新的评价指标,所以我搞了个数据集,欢迎大家来用。那baseline就是说新的数据集和之前的不一样了,你们在原来数据集上验证的指标,得在我的数据集上再跑跑看,一看效果都不行啊(神经网络就是这样,泛化性还是不够强,有些网络在这个数据集上跑还可以换个就不行了得重新训,训完那个又不行了)。这样吧,我给个适配我数据集的简单的demo,相当于定个最低标准。
ok,benchmark就不说了,主要来看一下这个occnet。
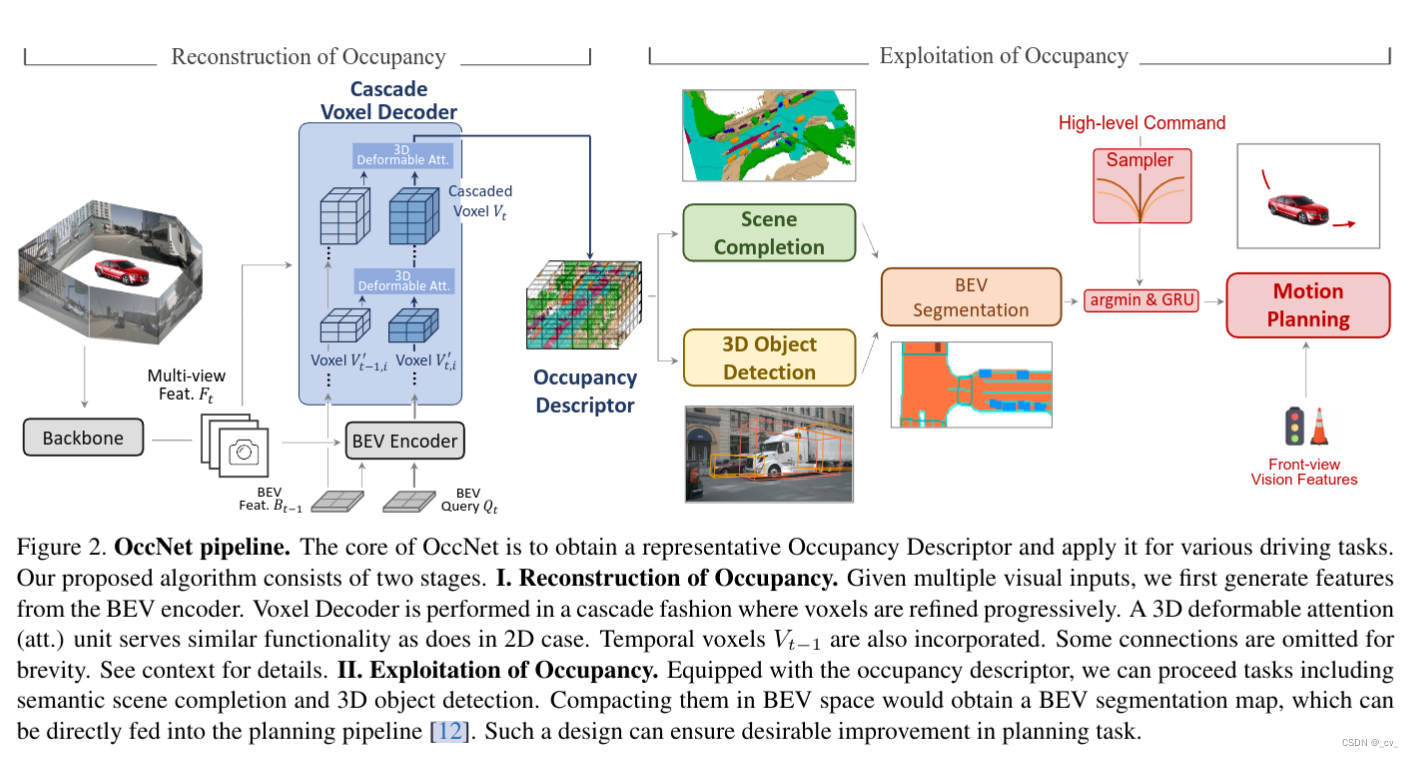
对于figure也是有原文解释的,大概的流程大家也能看出来,一个重建一个用途,篇幅有限所以只说重点cascade voxel decoder。这个decoder是一个一个级联结构,用来逐步恢复体素特征中的高度信息。
从bev特征中重建出voxel是比较关键的,直接使用bev特征或从透视图直接重构体素特征,会出现性能下降或效率下降,这一点在论文中给出了实验证明。所以将bev特征(bt∈rh×w ×cbev)重构分解为n步,称为级联结构。这里 h 和 w 是 bev 空间的 2d 空间形状,c 是特征维度,z 是体素空间的期望高度。在输入的bev特征和期望的级联体素特征之间,将不同高度的中间体素特征表示为
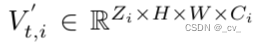 ,
,
其中zi和ci分别在{1,n}和{cbev,cvoxel}之间均匀分布。bt−1和bt两个时序上的bev特征通过前馈网络提升到v ’ t−1,i和v ’ t,i,经过第i个体素解码器,得到细化的v ’ t,i,后面的步骤遵循相同的方案。每个体素解码器包括基于体素的时间自注意力(voxel based temporal self-attention)和基于体素的空间交叉注意力模块(voxel-based spatial cross-attention),并分别使用历史 v 't−1,i 和图像特征 ft 细化 v 't,i。模型逐渐增加zi,减少ci,有效高效地学习最终的占用描述符vt。就是说z的高度是从c特征维度这里来的。而这里的时间自注意力和空间交叉注意力也见过是从前面bevformer那里来的,代码部分也是有继承bevformer。这里只是简单说一下,想要真的弄懂还是得一步一步去看代码。这里先简单说,后面如果我还有时间的话再写代码部分。
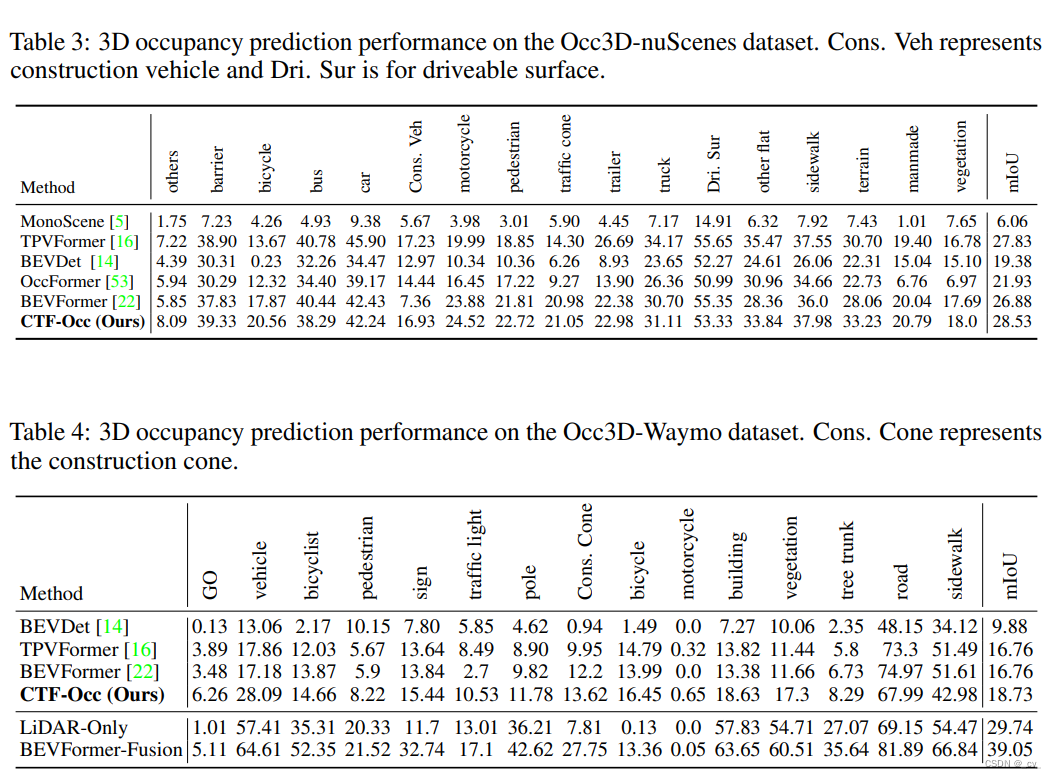
2. occ3d: a large-scale 3d occupancy prediction benchmark for autonomous driving
- 点评: benchmark,讲数据集是怎么造的,然后跑一下基线模型和其他模型的对比
对比如下:
3. fb-occ: 3d occupancy prediction based on forward-backward view transformation [paper]
-
点评:nvidia出品,确实做了不少工作,但个人觉得主要还是预训练做得好,毕竟不缺卡可以大力出奇迹,lss+bevformer说的很清楚了。有个好消息是,人家开源了https://github.com/nvlabs/fb-bev。
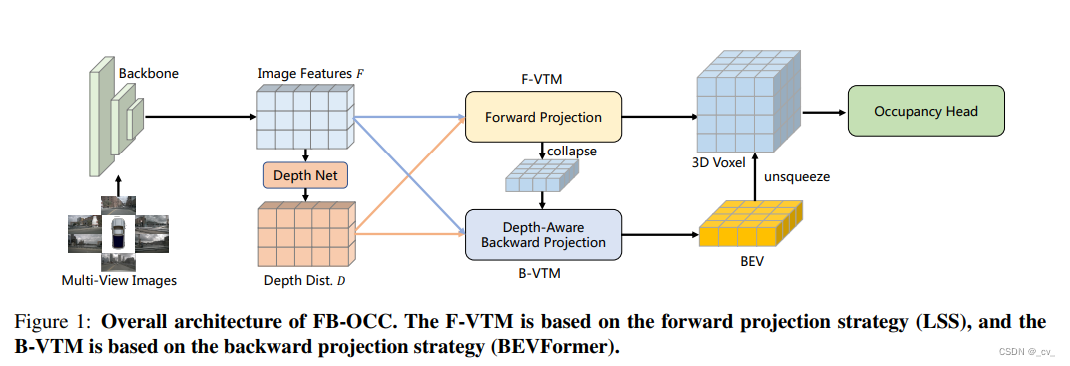
-
机器翻译如下
fb-occ,是基于一个名为fb-bev的3d物体检测方法。在这里,我们提供一个简短的介绍,以便更好地理解fb-occ。相机只能3d感知模型的核心模块是视图转换模块。这个模块包括两个突出的视图转换:前向投影(由list-splat-shoot表示)和后向投影(由bevformer表示)。fb-bev提供了一个统一的设计,利用这两种方法,提升了每种方法的优点,改善了感知结果,同时克服了它们的局限性。在fb-occ的情况下,我们使用前向投影来生成初始的3d体素表示。然后,我们将3d体素表示压缩成一个扁平化的bev特征图。bev特征图被视为bev空间内的查询,并参与图像编码器特征以获取密集的几何信息。然后将3d体素表示和优化的bev表示的融合特征输入到后续的任务头中。
在前向投影模块中,我们坚持lss的原则,以考虑每个像素深度估计的不确定性。这使我们能够根据它们对应的深度值将图像特征投影到3d空间。与lss不同,后者模拟bev特征,我们直接模拟3d体素表示,以捕获3d空间中更详细的信息。此外,我们采用bevdepth的方法,利用点云生成精确的深度地面真实值,这有助于监督我们的模型的深度预测,以提高准确性。lss倾向于产生相对稀疏的3d表示。为了解决这个问题,我们引入了一个后向投影方法来优化这些稀疏的3d表示。考虑到计算负担,我们在这个阶段使用bev表示,而不是3d体素表示。后向投影方法借鉴了bevformer。然而,与bevformer不同,后者使用随机初始化的参数作为bev查询,我们将获得的3d体素表示压缩成bev表示,从而融入更强的语义先验。此外,我们的后向投影方法在投影阶段利用深度分布,使得投影关系的建模更为精确。
在获得3d体素表示和优化的bev表示后,我们通过扩展bev特征的过程将它们结合起来,得到最终的3d体素表示。
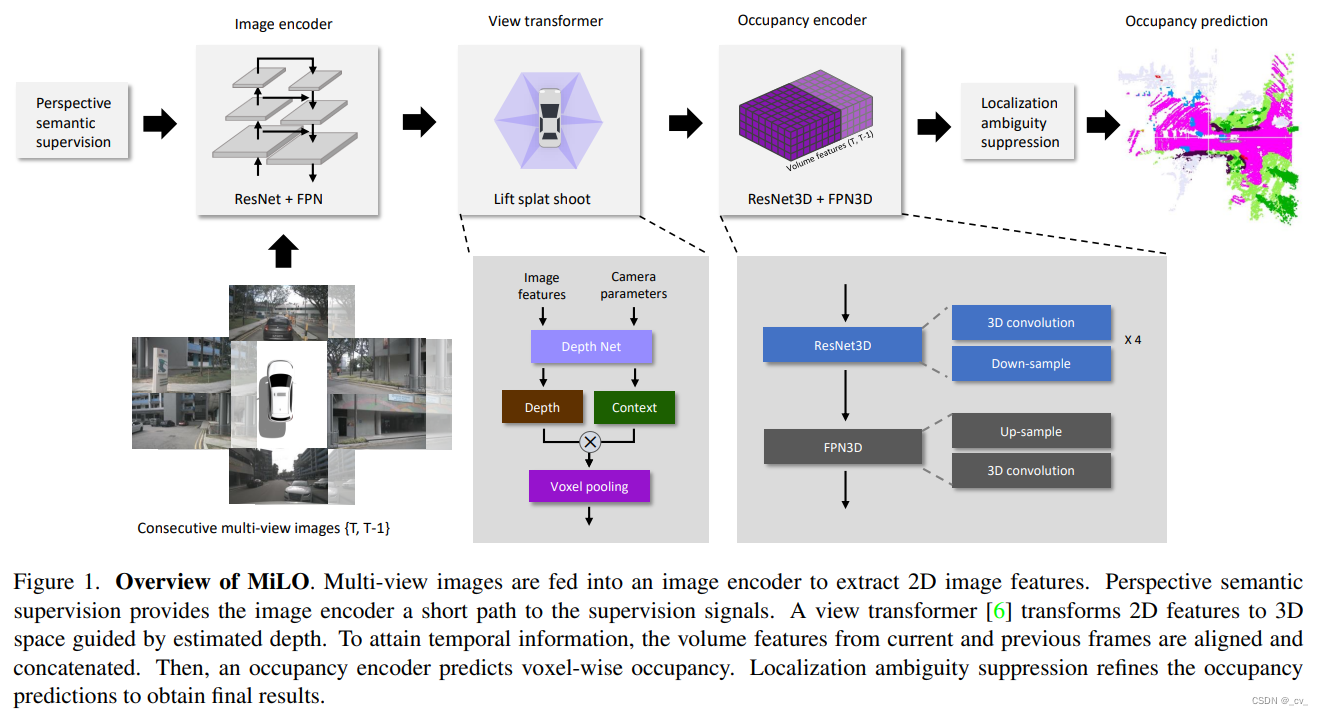
4. milo: multi-task learning with localization ambiguity suppression for occupancy prediction [paper]
- 点评:42dot.ai出品,our baseline is bevdet4d-occ。说的也很清楚
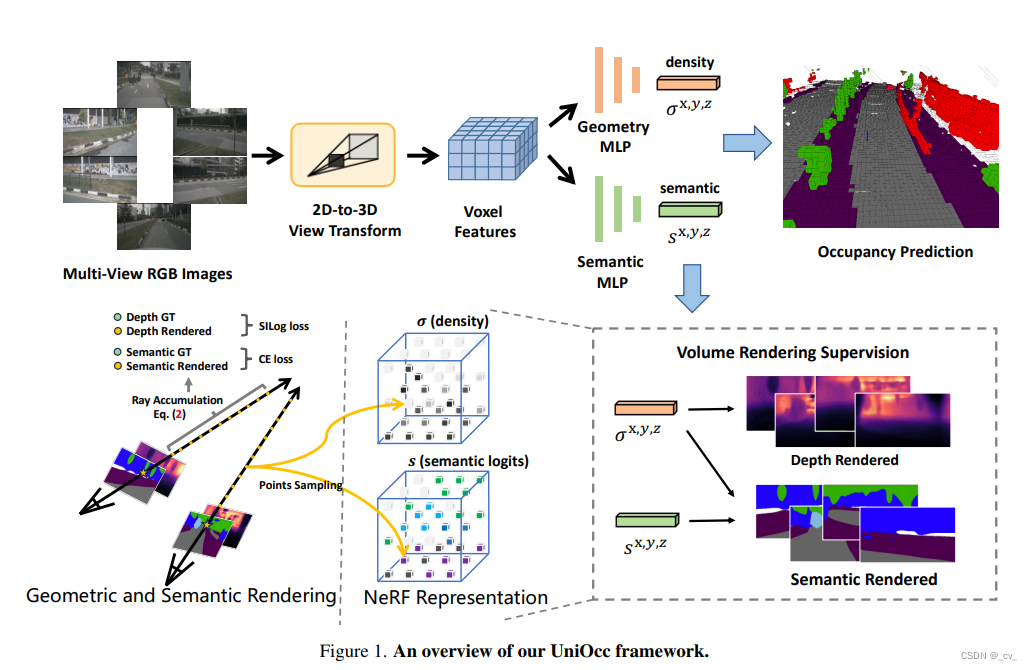
5.uniocc: unifying vision-centric 3d occupancy prediction with geometric and semantic rendering[paper]
-
点评:小米和北大的工作,用nerf渲染的结果来做语义和深度的监督信号训occupancy,挺会玩。
-
题外话 在雷总的发布会上看到了embodied ai,emmmmmm,这说明了什么呢?我也不知道哈哈哈

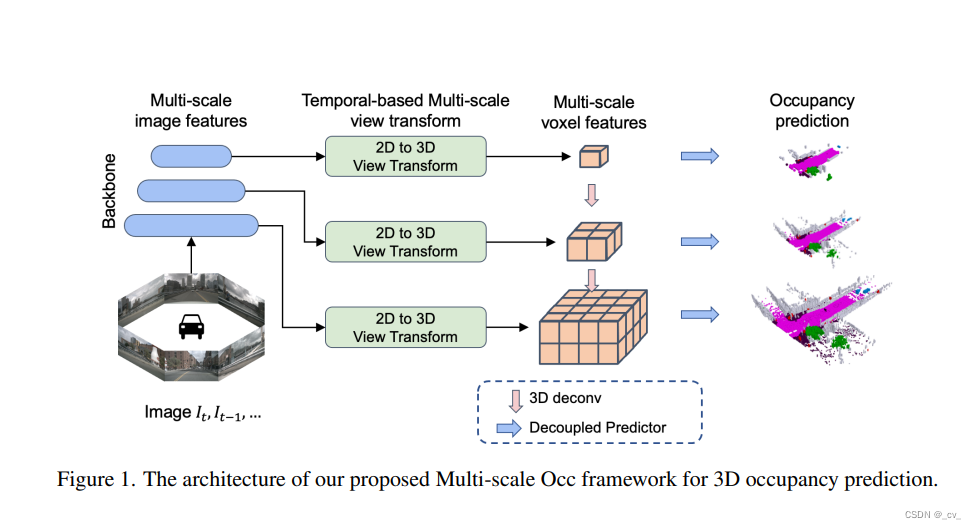
6. multi-scale occ: 4th place solution for cvpr 2023 3d occupancy prediction challenge [paper]
- 点评:无
- 机器翻译如下
我们的方法的总体架构如图1所示。给定具有t个时间戳的n个相机图像,我们首先使用2d图像编码器提取m个尺度特征。然后将图像特征提升为3d体素特征,然后在每个尺度上独立地对过去帧进行长期时间特征聚合,以构建当前帧的多尺度3d表示。为了彻底融合多尺度3d特征,我们使用轻量级的3d unet来集成局部和全局几何和语义信息。我们使用2个解耦的头在最大分辨率上分别执行占用和语义预测。在训练过程中使用多尺度监督来促进收敛。最后,应用模型集成、测试时间扩充和类阈值来进一步提高性能。
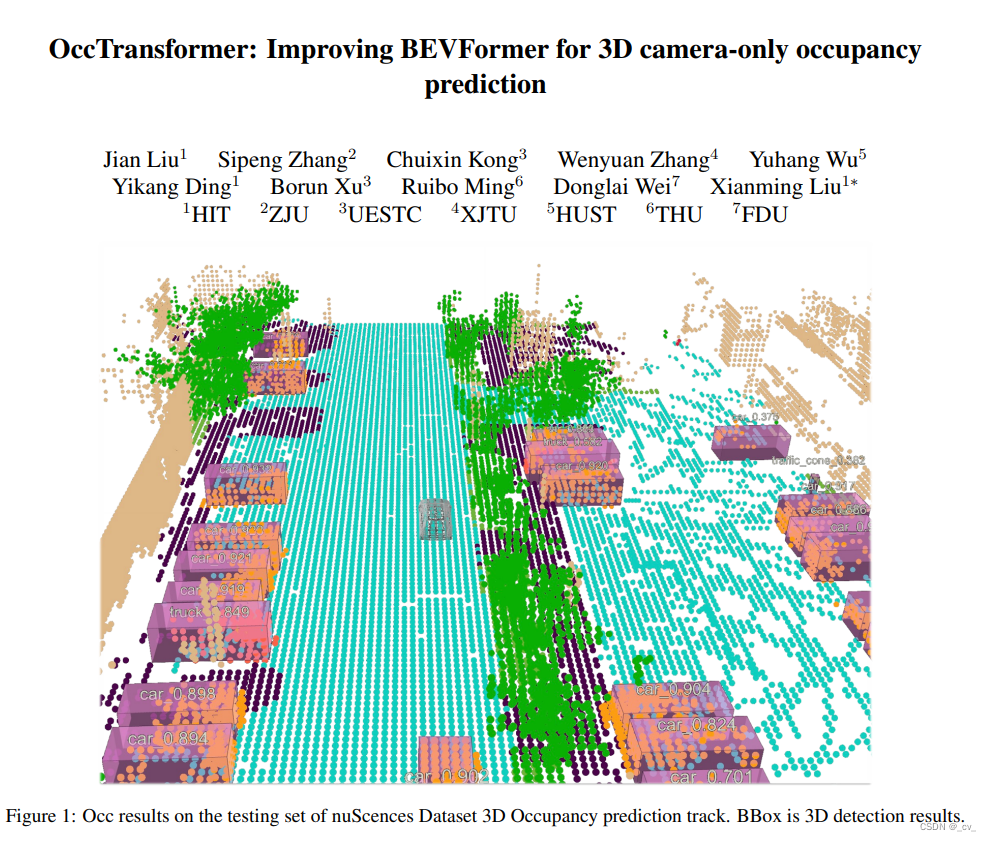
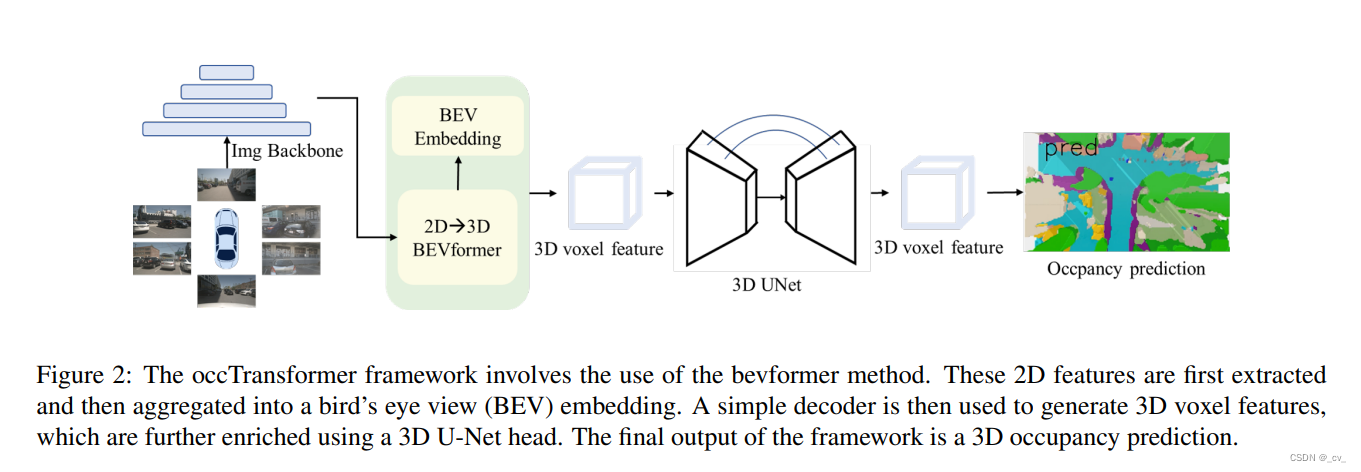
7. occtransformer: improving bevformer for 3d camera-only occupancy prediction [paper]
- 点评:结构简单,2d to 3d借鉴了bevformer。

发表评论