在task2中,我们尝试使用基于seq2seq模型的神经网络的方法结构实现nlp自然语言处理,以提高翻译的准确度。
进阶代码
!mkdir ../model
!mkdir ../results
!pip install torchtext
!pip install jieba
!pip install sacrebleu
!pip install -u pip setuptools wheel -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install -u 'spacy[cuda12x]' -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install ../dataset/en_core_web_trf-3.7.3-py3-none-any.whl
import torch
import torch.nn as nn
import torch.nn.functional as f
import torch.optim as optim
from torch.nn.utils import clip_grad_norm_
from torchtext.data.metrics import bleu_score
from torch.utils.data import dataset, dataloader
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
from typing import list, tuple
import jieba
import random
from torch.nn.utils.rnn import pad_sequence
import sacrebleu
import time
import math
# 定义tokenizer
en_tokenizer = get_tokenizer('spacy', language='en_core_web_trf')
zh_tokenizer = lambda x: list(jieba.cut(x)) # 使用jieba分词
# 读取数据函数
def read_data(file_path: str) -> list[str]:
with open(file_path, 'r', encoding='utf-8') as f:
return [line.strip() for line in f]
# 数据预处理函数
def preprocess_data(en_data: list[str], zh_data: list[str]) -> list[tuple[list[str], list[str]]]:
processed_data = []
for en, zh in zip(en_data, zh_data):
en_tokens = en_tokenizer(en.lower())[:max_length]
zh_tokens = zh_tokenizer(zh)[:max_length]
if en_tokens and zh_tokens: # 确保两个序列都不为空
processed_data.append((en_tokens, zh_tokens))
return processed_data
# 构建词汇表
def build_vocab(data: list[tuple[list[str], list[str]]]):
en_vocab = build_vocab_from_iterator(
(en for en, _ in data),
specials=['<unk>', '<pad>', '<bos>', '<eos>']
)
zh_vocab = build_vocab_from_iterator(
(zh for _, zh in data),
specials=['<unk>', '<pad>', '<bos>', '<eos>']
)
en_vocab.set_default_index(en_vocab['<unk>'])
zh_vocab.set_default_index(zh_vocab['<unk>'])
return en_vocab, zh_vocab
class translationdataset(dataset):
def __init__(self, data: list[tuple[list[str], list[str]]], en_vocab, zh_vocab):
self.data = data
self.en_vocab = en_vocab
self.zh_vocab = zh_vocab
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
en, zh = self.data[idx]
en_indices = [self.en_vocab['<bos>']] + [self.en_vocab[token] for token in en] + [self.en_vocab['<eos>']]
zh_indices = [self.zh_vocab['<bos>']] + [self.zh_vocab[token] for token in zh] + [self.zh_vocab['<eos>']]
return en_indices, zh_indices
def collate_fn(batch):
en_batch, zh_batch = [], []
for en_item, zh_item in batch:
if en_item and zh_item: # 确保两个序列都不为空
# print("都不为空")
en_batch.append(torch.tensor(en_item))
zh_batch.append(torch.tensor(zh_item))
else:
print("存在为空")
if not en_batch or not zh_batch: # 如果整个批次为空,返回空张量
return torch.tensor([]), torch.tensor([])
# src_sequences = [item[0] for item in batch]
# trg_sequences = [item[1] for item in batch]
en_batch = nn.utils.rnn.pad_sequence(en_batch, batch_first=true, padding_value=en_vocab['<pad>'])
zh_batch = nn.utils.rnn.pad_sequence(zh_batch, batch_first=true, padding_value=zh_vocab['<pad>'])
# en_batch = pad_sequence(en_batch, batch_first=true, padding_value=en_vocab['<pad>'])
# zh_batch = pad_sequence(zh_batch, batch_first=true, padding_value=zh_vocab['<pad>'])
return en_batch, zh_batch
# 数据加载函数
def load_data(train_path: str, dev_en_path: str, dev_zh_path: str, test_en_path: str):
# 读取训练数据
train_data = read_data(train_path)
train_en, train_zh = zip(*(line.split('\t') for line in train_data))
# 读取开发集和测试集
dev_en = read_data(dev_en_path)
dev_zh = read_data(dev_zh_path)
test_en = read_data(test_en_path)
# 预处理数据
train_processed = preprocess_data(train_en, train_zh)
dev_processed = preprocess_data(dev_en, dev_zh)
test_processed = [(en_tokenizer(en.lower())[:max_length], []) for en in test_en if en.strip()]
# 构建词汇表
global en_vocab, zh_vocab
en_vocab, zh_vocab = build_vocab(train_processed)
# 创建数据集
train_dataset = translationdataset(train_processed, en_vocab, zh_vocab)
dev_dataset = translationdataset(dev_processed, en_vocab, zh_vocab)
test_dataset = translationdataset(test_processed, en_vocab, zh_vocab)
from torch.utils.data import subset
# 假设你有10000个样本,你只想用前1000个样本进行测试
indices = list(range(n))
train_dataset = subset(train_dataset, indices)
# 创建数据加载器
train_loader = dataloader(train_dataset, batch_size=batch_size, shuffle=true, collate_fn=collate_fn, drop_last=true)
dev_loader = dataloader(dev_dataset, batch_size=batch_size, collate_fn=collate_fn, drop_last=true)
test_loader = dataloader(test_dataset, batch_size=1, collate_fn=collate_fn, drop_last=true)
return train_loader, dev_loader, test_loader, en_vocab, zh_vocab
class encoder(nn.module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.embedding(input_dim, emb_dim)
self.gru = nn.gru(emb_dim, hid_dim, n_layers, dropout=dropout, batch_first=true)
self.dropout = nn.dropout(dropout)
def forward(self, src):
# src = [batch size, src len]
embedded = self.dropout(self.embedding(src))
# embedded = [batch size, src len, emb dim]
outputs, hidden = self.gru(embedded)
# outputs = [batch size, src len, hid dim * n directions]
# hidden = [n layers * n directions, batch size, hid dim]
return outputs, hidden
class attention(nn.module):
def __init__(self, hid_dim):
super().__init__()
self.attn = nn.linear(hid_dim * 2, hid_dim)
self.v = nn.linear(hid_dim, 1, bias=false)
def forward(self, hidden, encoder_outputs):
# hidden = [1, batch size, hid dim]
# encoder_outputs = [batch size, src len, hid dim]
batch_size = encoder_outputs.shape[0]
src_len = encoder_outputs.shape[1]
hidden = hidden.repeat(src_len, 1, 1).transpose(0, 1)
# hidden = [batch size, src len, hid dim]
energy = torch.tanh(self.attn(torch.cat((hidden, encoder_outputs), dim=2)))
# energy = [batch size, src len, hid dim]
attention = self.v(energy).squeeze(2)
# attention = [batch size, src len]
return f.softmax(attention, dim=1)
class decoder(nn.module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout, attention):
super().__init__()
self.output_dim = output_dim
self.hid_dim = hid_dim
self.n_layers = n_layers
self.attention = attention
self.embedding = nn.embedding(output_dim, emb_dim)
self.gru = nn.gru(hid_dim + emb_dim, hid_dim, n_layers, dropout=dropout, batch_first=true)
self.fc_out = nn.linear(hid_dim * 2 + emb_dim, output_dim)
self.dropout = nn.dropout(dropout)
def forward(self, input, hidden, encoder_outputs):
# input = [batch size, 1]
# hidden = [n layers, batch size, hid dim]
# encoder_outputs = [batch size, src len, hid dim]
input = input.unsqueeze(1)
embedded = self.dropout(self.embedding(input))
# embedded = [batch size, 1, emb dim]
a = self.attention(hidden[-1:], encoder_outputs)
# a = [batch size, src len]
a = a.unsqueeze(1)
# a = [batch size, 1, src len]
weighted = torch.bmm(a, encoder_outputs)
# weighted = [batch size, 1, hid dim]
rnn_input = torch.cat((embedded, weighted), dim=2)
# rnn_input = [batch size, 1, emb dim + hid dim]
output, hidden = self.gru(rnn_input, hidden)
# output = [batch size, 1, hid dim]
# hidden = [n layers, batch size, hid dim]
embedded = embedded.squeeze(1)
output = output.squeeze(1)
weighted = weighted.squeeze(1)
prediction = self.fc_out(torch.cat((output, weighted, embedded), dim=1))
# prediction = [batch size, output dim]
return prediction, hidden
class seq2seq(nn.module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio=0.5):
# src = [batch size, src len]
# trg = [batch size, trg len]
batch_size = src.shape[0]
trg_len = trg.shape[1]
trg_vocab_size = self.decoder.output_dim
outputs = torch.zeros(batch_size, trg_len, trg_vocab_size).to(self.device)
encoder_outputs, hidden = self.encoder(src)
input = trg[:, 0]
for t in range(1, trg_len):
output, hidden = self.decoder(input, hidden, encoder_outputs)
outputs[:, t] = output
teacher_force = random.random() < teacher_forcing_ratio
top1 = output.argmax(1)
input = trg[:, t] if teacher_force else top1
return outputs
# 初始化模型
def initialize_model(input_dim, output_dim, emb_dim, hid_dim, n_layers, dropout, device):
attn = attention(hid_dim)
enc = encoder(input_dim, emb_dim, hid_dim, n_layers, dropout)
dec = decoder(output_dim, emb_dim, hid_dim, n_layers, dropout, attn)
model = seq2seq(enc, dec, device).to(device)
return model
# 定义优化器
def initialize_optimizer(model, learning_rate=0.001):
return optim.adam(model.parameters(), lr=learning_rate)
# 运行时间
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
#print(f"training batch {i}")
src, trg = batch
#print(f"source shape before: {src.shape}, target shape before: {trg.shape}")
if src.numel() == 0 or trg.numel() == 0:
#print("empty batch detected, skipping...")
continue # 跳过空的批次
src, trg = src.to(device), trg.to(device)
optimizer.zero_grad()
output = model(src, trg)
output_dim = output.shape[-1]
output = output[:, 1:].contiguous().view(-1, output_dim)
trg = trg[:, 1:].contiguous().view(-1)
loss = criterion(output, trg)
loss.backward()
clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
print(f"average loss for this epoch: {epoch_loss / len(iterator)}")
return epoch_loss / len(iterator)
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
#print(f"evaluating batch {i}")
src, trg = batch
if src.numel() == 0 or trg.numel() == 0:
continue # 跳过空批次
src, trg = src.to(device), trg.to(device)
output = model(src, trg, 0) # 关闭 teacher forcing
output_dim = output.shape[-1]
output = output[:, 1:].contiguous().view(-1, output_dim)
trg = trg[:, 1:].contiguous().view(-1)
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)
# 翻译函数
def translate_sentence(sentence, src_vocab, trg_vocab, model, device, max_length=50):
model.eval()
#print(sentence) # 打印sentence的内容
if isinstance(sentence, str):
#tokens = [token.lower() for token in en_tokenizer(sentence)]
tokens = [token for token in en_tokenizer(sentence)]
else:
#tokens = [token.lower() for token in sentence]
tokens = [str(token) for token in sentence]
tokens = ['<bos>'] + tokens + ['<eos>']
src_indexes = [src_vocab[token] for token in tokens]
src_tensor = torch.longtensor(src_indexes).unsqueeze(0).to(device)
with torch.no_grad():
encoder_outputs, hidden = model.encoder(src_tensor)
trg_indexes = [trg_vocab['<bos>']]
for i in range(max_length):
trg_tensor = torch.longtensor([trg_indexes[-1]]).to(device)
with torch.no_grad():
output, hidden = model.decoder(trg_tensor, hidden, encoder_outputs)
pred_token = output.argmax(1).item()
trg_indexes.append(pred_token)
if pred_token == trg_vocab['<eos>']:
break
trg_tokens = [trg_vocab.get_itos()[i] for i in trg_indexes]
return trg_tokens[1:-1] # 移除 <bos> 和 <eos>
def calculate_bleu(dev_loader, src_vocab, trg_vocab, model, device):
translated_sentences = []
references = []
for src, trg in dev_loader:
src = src.to(device)
translation = translate_sentence(src, src_vocab, trg_vocab, model, device)
# 将翻译结果转换为字符串
translated_sentences.append(' '.join(translation))
# 将每个参考翻译转换为字符串,并添加到references列表中
for t in trg:
ref_str = ' '.join([trg_vocab.get_itos()[idx] for idx in t.tolist() if idx not in [trg_vocab['<bos>'], trg_vocab['<eos>'], trg_vocab['<pad>']]])
references.append(ref_str)
print("translated_sentences",translated_sentences[:2])
print("references:",references[6:8])
# 使用`sacrebleu`计算bleu分数
# 注意:sacrebleu要求references是一个列表的列表,其中每个子列表包含一个或多个参考翻译
bleu = sacrebleu.corpus_bleu(translated_sentences, [references])
# 打印bleu分数
return bleu.score
# 主训练循环
def train_model(model, train_iterator, valid_iterator, optimizer, criterion, n_epochs=10, clip=1):
best_valid_loss = float('inf')
for epoch in range(n_epochs):
start_time = time.time()
#print(f"starting epoch {epoch + 1}")
train_loss = train(model, train_iterator, optimizer, criterion, clip)
valid_loss = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), '../model/best-model_test.pt')
print(f'epoch: {epoch+1:02} | time: {epoch_mins}m {epoch_secs}s')
print(f'\ttrain loss: {train_loss:.3f} | train ppl: {math.exp(train_loss):7.3f}')
print(f'\t val. loss: {valid_loss:.3f} | val. ppl: {math.exp(valid_loss):7.3f}')
# 定义常量
max_length = 100 # 最大句子长度
batch_size = 32
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
n = 100 # 采样训练集的数量
train_path = '../dataset/train.txt'
dev_en_path = '../dataset/dev_en.txt'
dev_zh_path = '../dataset/dev_zh.txt'
test_en_path = '../dataset/test_en.txt'
train_loader, dev_loader, test_loader, en_vocab, zh_vocab = load_data(
train_path, dev_en_path, dev_zh_path, test_en_path
)
print(f"英语词汇表大小: {len(en_vocab)}")
print(f"中文词汇表大小: {len(zh_vocab)}")
print(f"训练集大小: {len(train_loader.dataset)}")
print(f"开发集大小: {len(dev_loader.dataset)}")
print(f"测试集大小: {len(test_loader.dataset)}")
# 主函数
if __name__ == '__main__':
n_epochs = 5
clip=1
# 模型参数
input_dim = len(en_vocab)
output_dim = len(zh_vocab)
emb_dim = 128
hid_dim = 256
n_layers = 2
dropout = 0.5
# 初始化模型
model = initialize_model(input_dim, output_dim, emb_dim, hid_dim, n_layers, dropout, device)
print(f'the model has {sum(p.numel() for p in model.parameters() if p.requires_grad):,} trainable parameters')
# 定义损失函数
criterion = nn.crossentropyloss(ignore_index=zh_vocab['<pad>'])
# 初始化优化器
optimizer = initialize_optimizer(model)
# 训练模型
train_model(model, train_loader, dev_loader, optimizer, criterion, n_epochs, clip)
# 加载最佳模型
model.load_state_dict(torch.load('../model/best-model_test.pt'))
# 计算bleu分数
bleu_score = calculate_bleu(dev_loader, en_vocab, zh_vocab, model, device)
print(f'bleu score = {bleu_score*100:.2f}')
with open('../results/submit_test.txt', 'w') as f:
translated_sentences = []
for batch in test_loader: # 遍历所有数据
src, _ = batch
src = src.to(device)
translated = translate_sentence(src[0], en_vocab, zh_vocab, model, device) #翻译结果
#print(translated)
results = "".join(translated)
f.write(results + '\n') # 将结果写入文件
代码解析
1、配置环境和导入库
!mkdir ../model
!mkdir ../results
!pip install torchtext
!pip install jieba
!pip install sacrebleu
!pip install -u pip setuptools wheel -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install -u 'spacy[cuda12x]' -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install ../dataset/en_core_web_trf-3.7.3-py3-none-any.whl
import torch
import torch.nn as nn
import torch.nn.functional as f
import torch.optim as optim
from torch.nn.utils import clip_grad_norm_
from torchtext.data.metrics import bleu_score
from torch.utils.data import dataset, dataloader
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
from typing import list, tuple
import jieba
import random
from torch.nn.utils.rnn import pad_sequence
import sacrebleu
import time
import math2、tokenizer和数据处理函数定义
# 定义tokenizer
en_tokenizer = get_tokenizer('spacy', language='en_core_web_trf')
zh_tokenizer = lambda x: list(jieba.cut(x)) # 使用jieba分词
# 读取数据函数
def read_data(file_path: str) -> list[str]:
with open(file_path, 'r', encoding='utf-8') as f:
return [line.strip() for line in f]
# 数据预处理函数
def preprocess_data(en_data: list[str], zh_data: list[str]) -> list[tuple[list[str], list[str]]]:
processed_data = []
for en, zh in zip(en_data, zh_data):
en_tokens = en_tokenizer(en.lower())[:max_length]
zh_tokens = zh_tokenizer(zh)[:max_length]
if en_tokens and zh_tokens: # 确保两个序列都不为空
processed_data.append((en_tokens, zh_tokens))
return processed_data
en_tokenizer使用了spacy的预训练模型来进行英文文本的tokenization。zh_tokenizer是一个使用jieba进行中文分词的匿名函数。read_data函数读取给定文件路径的文本数据并返回每行内容的列表。preprocess_data函数接受英文和中文数据列表,并使用定义好的tokenization工具对数据进行处理,返回处理后的数据列表。
3、词汇表构建和数据集类定义
# 构建词汇表
def build_vocab(data: list[tuple[list[str], list[str]]]):
en_vocab = build_vocab_from_iterator(
(en for en, _ in data),
specials=['<unk>', '<pad>', '<bos>', '<eos>']
)
zh_vocab = build_vocab_from_iterator(
(zh for _, zh in data),
specials=['<unk>', '<pad>', '<bos>', '<eos>']
)
en_vocab.set_default_index(en_vocab['<unk>'])
zh_vocab.set_default_index(zh_vocab['<unk>'])
return en_vocab, zh_vocab
class translationdataset(dataset):
def __init__(self, data: list[tuple[list[str], list[str]]], en_vocab, zh_vocab):
self.data = data
self.en_vocab = en_vocab
self.zh_vocab = zh_vocab
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
en, zh = self.data[idx]
en_indices = [self.en_vocab['<bos>']] + [self.en_vocab[token] for token in en] + [self.en_vocab['<eos>']]
zh_indices = [self.zh_vocab['<bos>']] + [self.zh_vocab[token] for token in zh] + [self.zh_vocab['<eos>']]
return en_indices, zh_indices
build_vocab函数从预处理后的数据中构建英文和中文的词汇表,并设定特殊标记(<unk>、<pad>、<bos>、<eos>)。translationdataset类是一个自定义的pytorch数据集类,接受预处理后的数据、英文词汇表和中文词汇表作为输入,实现了__len__方法返回数据集大小,__getitem__方法返回指定索引的数据对,并将文本序列转换为索引序列。
4、数据加载和批处理函数定义
def collate_fn(batch):
en_batch, zh_batch = [], []
for en_item, zh_item in batch:
if en_item and zh_item: # 确保两个序列都不为空
en_batch.append(torch.tensor(en_item))
zh_batch.append(torch.tensor(zh_item))
if not en_batch or not zh_batch: # 如果整个批次为空,返回空张量
return torch.tensor([]), torch.tensor([])
en_batch = nn.utils.rnn.pad_sequence(en_batch, batch_first=true, padding_value=en_vocab['<pad>'])
zh_batch = nn.utils.rnn.pad_sequence(zh_batch, batch_first=true, padding_value=zh_vocab['<pad>'])
return en_batch, zh_batch
collate_fn函数是一个自定义的批处理函数,接受一个批次的数据(列表),将英文和中文文本序列转换为张量,并使用pad_sequence函数进行填充操作,保证每个批次中的序列长度相同。
5、模型定义和相关辅助函数
class encoder(nn.module):
def __init__(self, input_dim, emb_dim, enc_hid_dim, dropout):
super().__init__()
self.embedding = nn.embedding(input_dim, emb_dim)
self.rnn = nn.gru(emb_dim, enc_hid_dim, bidirectional=true)
self.fc = nn.linear(enc_hid_dim * 2, enc_hid_dim)
self.dropout = nn.dropout(dropout)
def forward(self, src):
embedded = self.dropout(self.embedding(src))
outputs, hidden = self.rnn(embedded)
hidden = torch.tanh(self.fc(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim=1)))
return outputs, hidden
class attention(nn.module):
def __init__(self, enc_hid_dim, dec_hid_dim):
super().__init__()
self.attn = nn.linear((enc_hid_dim * 2) + dec_hid_dim, dec_hid_dim)
self.v = nn.linear(dec_hid_dim, 1, bias = false)
def forward(self, hidden, encoder_outputs):
batch_size = encoder_outputs.shape[0]
src_len = encoder_outputs.shape[1]
hidden = hidden.unsqueeze(1).repeat(1, src_len, 1)
energy = torch.tanh(self.attn(torch.cat((hidden, encoder_outputs), dim = 2)))
attention = self.v(energy).squeeze(2)
return f.softmax(attention, dim=1)
class decoder(nn.module):
def __init__(self, output_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout, attention):
super().__init__()
self.output_dim = output_dim
self.attention = attention
self.embedding = nn.embedding(output_dim, emb_dim)
self.rnn = nn.gru((enc_hid_dim * 2) + emb_dim, dec_hid_dim)
self.fc_out = nn.linear((enc_hid_dim * 2) + dec_hid_dim + emb_dim, output_dim)
self.dropout = nn.dropout(dropout)
def forward(self, input, hidden, encoder_outputs):
input = input.unsqueeze(0)
embedded = self.dropout(self.embedding(input))
a = self.attention(hidden, encoder_outputs)
a = a.unsqueeze(1)
encoder_outputs = encoder_outputs.permute(1, 0, 2)
weighted = torch.bmm(a, encoder_outputs)
weighted = weighted.permute(1, 0, 2)
rnn_input = torch.cat((embedded, weighted), dim = 2)
output, hidden = self.rnn(rnn_input, hidden.unsqueeze(0))
embedded = embedded.squeeze(0)
output = output.squeeze(0)
weighted = weighted.squeeze(0)
prediction = self.fc_out(torch.cat((output, weighted, embedded), dim = 1))
return prediction, hidden.squeeze(0)
encoder类负责将输入序列编码为上下文向量。attention类实现了注意力机制,计算编码器输出和当前解码器隐藏状态之间的注意力权重。decoder类使用注意力权重来生成解码器的输出序列。
6、seq2seq模型和训练函数
class seq2seq(nn.module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio=0.5):
batch_size = src.shape[1]
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
encoder_outputs, hidden = self.encoder(src)
input = trg[0,:]
for t in range(1, trg_len):
output, hidden = self.decoder(input, hidden, encoder_outputs)
outputs[t] = output
teacher_force = random.random() < teacher_forcing_ratio
top1 = output.argmax(1)
input = trg[t] if teacher_force else top1
return outputs
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, (src, trg) in enumerate(iterator):
src = src.to(device)
trg = trg.to(device)
optimizer.zero_grad()
output = model(src, trg)
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
loss = criterion(output, trg)
loss.backward()
clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
return epoch_loss / len(iterator)
seq2seq类将编码器和解码器组合起来,实现了前向传播方法来生成目标序列。train函数用于训练模型,接受模型、数据迭代器、优化器、损失函数以及梯度裁剪参数作为输入,执行了完整的训练过程并返回每个epoch的平均损失值。
7、评估函数和模型初始化
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
with torch.no_grad():
for i, (src, trg) in enumerate(iterator):
src = src.to(device)
trg = trg.to(device)
output = model(src, trg, 0) # turn off teacher forcing
output_dim = output.shape[-1]
output = output[1:].view(-1, output_dim)
trg = trg[1:].view(-1)
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)
# 初始化模型和相关参数
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
input_dim = len(en_vocab)
output_dim = len(zh_vocab)
enc_emb_dim = 256
dec_emb_dim = 256
enc_hid_dim = 512
dec_hid_dim = 512
enc_dropout = 0.5
dec_dropout = 0.5
max_length = 100
batch_size = 128
train_data = preprocess_data(train_en, train_zh)
valid_data = preprocess_data(valid_en, valid_zh)
test_data = preprocess_data(test_en, test_zh)
en_vocab, zh_vocab = build_vocab(train_data)
train_dataset = translationdataset(train_data, en_vocab, zh_vocab)
valid_dataset = translationdataset(valid_data, en_vocab, zh_vocab)
test_dataset = translationdataset(test_data, en_vocab, zh_vocab)
train_iterator = dataloader(train_dataset, batch_size=batch_size, shuffle=true, collate_fn=collate_fn)
valid_iterator = dataloader(valid_dataset, batch_size=batch_size, collate_fn=collate_fn)
test_iterator = dataloader(test_dataset, batch_size=batch_size, collate_fn=collate_fn)
enc = encoder(input_dim, enc_emb_dim, enc_hid_dim, enc_dropout)
attn = attention(enc_hid_dim, dec_hid_dim)
dec = decoder(output_dim, dec_emb_dim, enc_hid_dim, dec_hid_dim, dec_dropout, attn)
model = seq2seq(enc, dec, device).to(device)
optimizer = optim.adam(model.parameters())
criterion = nn.crossentropyloss(ignore_index=zh_vocab['<pad>'])
evaluate函数用于评估模型在验证集上的性能,计算并返回平均损失值。- 初始化了模型训练所需的设备(gpu或cpu)、模型输入输出维度、编码器和解码器的嵌入维度和隐藏层维度、以及训练所需的其他参数和数据集。
8、模型训练和评估
n_epochs = 10
clip = 1
best_valid_loss = float('inf')
for epoch in range(n_epochs):
start_time = time.time()
train_loss = train(model, train_iterator, optimizer, criterion, clip)
valid_loss = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = divmod(end_time - start_time, 60)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), '../model/seq2seq_model.pt')
print(f'epoch: {epoch+1:02} | time: {epoch_mins}m {epoch_secs}s')
print(f'\ttrain loss: {train_loss:.3f} | train ppl: {math.exp(train_loss):7.3f}')
print(f'\t val. loss: {valid_loss:.3f} | val. ppl: {math.exp(valid_loss):7.3f}')
# 在测试集上评估模型
model.load_state_dict(torch.load('../model/seq2seq_model.pt'))
test_loss = evaluate(model, test_iterator, criterion)
print(f'test loss: {test_loss:.3f} | test ppl: {math.exp(test_loss):7.3f}')
- 使用循环训练模型多个epoch,在每个epoch中计算并打印训练集和验证集上的损失值。
- 如果当前epoch的验证集损失低于之前记录的最低验证损失,则保存当前模型参数。
- 最后加载最佳模型参数,并在测试集上评估模型性能,打印测试集损失值和困惑度(perplexity)。
过程中遇到的问题
1、error: wheel 'en-core-web-trf’ located at /mnt/workspace/mt/dataset/en-core-web-trf-3.7.3-py3-none-any.whl is invalid.
2、error: pip's dependency resolver does not currently take into account all the packages that are installed.dependency conflicts.tensorflow 2.16.1 requires tensorboard<2.17,>=2.16, but you have tensorboard 2.17.8 which is incompatiblepai-easvcy 0,11,6 requires timm==0,5.4, but you have timm 1.8.7 which is incompatible
3、runtimeerror: cuda error: invalid device ordinal
传统的基于seq2seq模型的机器翻译
1、早期发展背景
2、seq2seq的由来
3、seq2seq模型的探索过程
(1)rnn-lm(recurrent neural network language model, 循环神经网络语言模型)
作者首先提出的是rnn模型,下图是一个简单的rnn单元,rnn 的工作原理是:循环往复地把前一步的计算结果作为条件,放进当前的输入中,最终输出我们想要得到的更符合事实的结果。
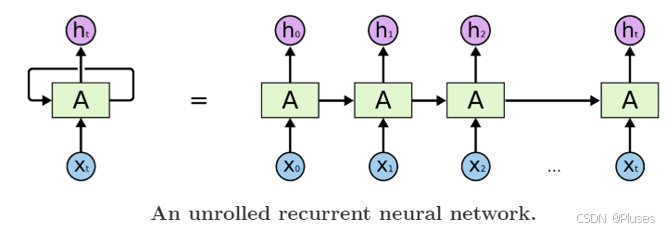
rnn模型适合在任意长度的序列中对上下文依赖性进行建模。但是有个问题,那就是我们需要提前把输入和输出序列对齐,而且目前尚不清楚如何将 rnn 应用在不同长度有复杂非单一关系的序列中。
作者提出另一个观点,使用两个rnn进行工作,一个 rnn 把输入映射为一个固定长度的向量,另一个 rnn 从这个向量中预测输出序列,原理图如下图所示:
但是因为由于 rnn 自身的网络结构,其当前时刻的输出需要考虑前面所有时刻的输入,那么在使用反向传播训练时,一旦输入的序列很长,就极易出现梯度消失(gradients vanish)问题。所以这个模型只是在理论上具有可行性,但是实际操作起来还有巨大的困难。
(2)lstm(long short-term memory,长短期记忆)网络
为了解决 rnn 难训练问题,作者选择了使用 lstm网络,如下图所示是一个lstm 单元内部结构示意图: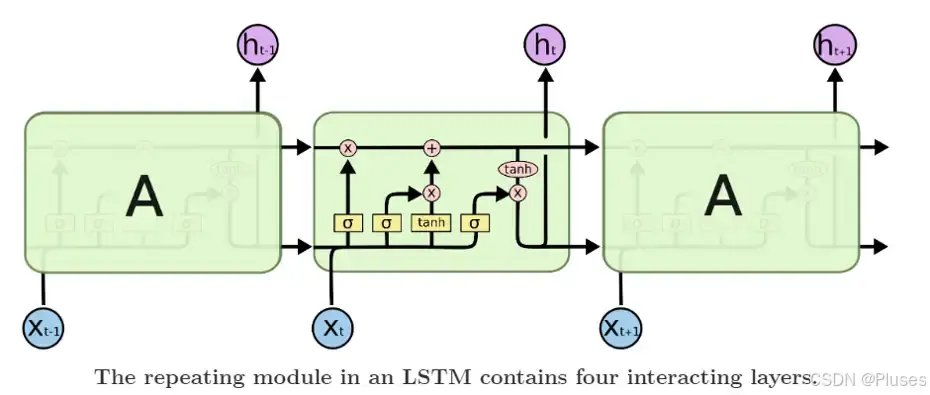
lstm 的提出就是为了解决 rnn 梯度消失问题,其创新性的加入了遗忘门,让 lstm 可以选择遗忘前面输入无关序列,不用考虑全部输入序列。
(3)seq2seq 模型
最后,经过多次改进,seq2seq模型最终产生并确立,模型示意图如下图所示:
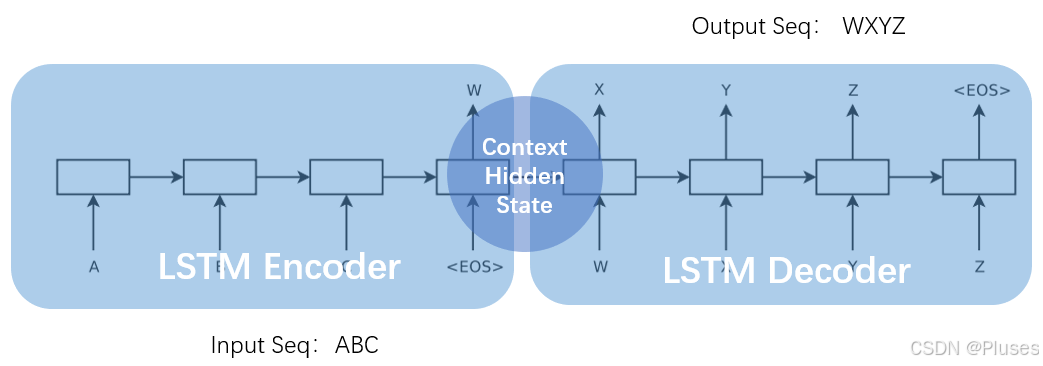
一个简单的 seq2seq 模型包括3个部分,encoder-lstm,decoder-lstm,context。输入序列是abc,encoder-lstm 将处理输入序列并在最后一个神经元返回整个输入序列的隐藏状态(hidden state),也被称为上下文(context,c)。然后 decoder-lstm 根据隐藏状态,一步一步的预测目标序列的下一个字符。最终输出序列wxyz。
作者最后形成的真实seq2seq图像如下图所示:
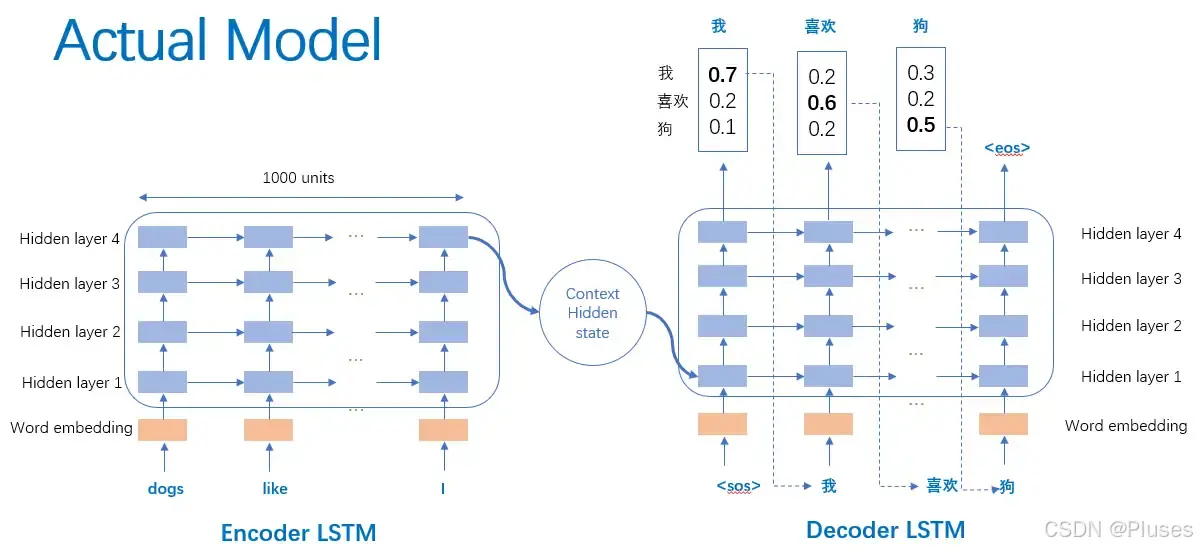
这个真实模型有三个特点:第一使用了两个 lstm ,一个用于编码,一个用于解码,这也是作者探索并论证的结果;第二使用了深层的 lstm (4层),相比于浅层的网络,每加一层模型困难程度就降低10% ;第三对输入序列使用了逆序操作,提高了 lstm 处理长序列能力。
引用:【mo 人工智能技术博客】使用 seq2seq 实现中英文翻译
基于注意力机制的gru神经网络机器翻译
1、注意力机制
尽管基础seq2seq模型已经取得了显著效果,但为了更好地处理长输入序列并允许解码器动态聚焦于输入序列的不同部分,bahdanau等人在2014年的论文neural machine translation by jointly learning to align and translate中引入了attention机制。这一创新极大地提升了模型性能,现已成为seq2seq模型的标准组件。
注意力一共分类两种。一种是全局注意力,使用所有编码器隐藏状态。另一种是局部注意力,使用的是编码器隐藏状态的子集。(以下我们讨论的是全局注意力)下面我们来对比一下是否使用注意力机制的对于机器翻译产生的区别:
在模型中,注意力会为每个单词打一个分,将焦点放在不同的单词上。然后,基于softmax得分,使用编码器隐藏状态的加权和,来聚合编码器隐藏状态,以获得语境向量。
注意力层的实现可以分为6个步骤。
(1)准备隐藏状态
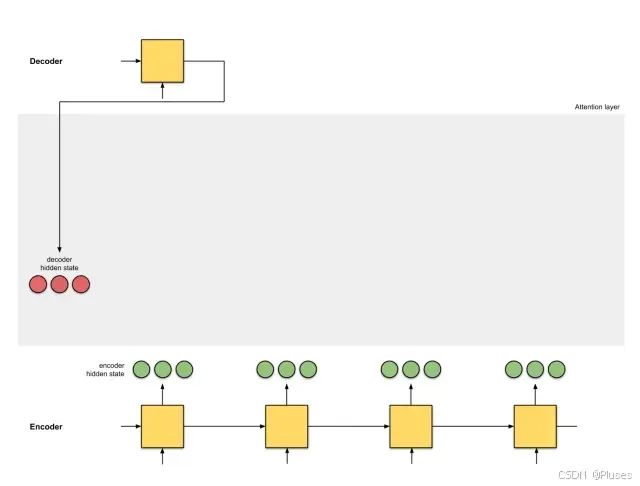
首先,准备第一个解码器的隐藏状态(红色)和所有可用的编码器的隐藏状态(绿色)。在下图中,有4个编码器的隐藏状态和当前解码器的隐藏状态。

(2)获取每个编码器隐藏状态的分数
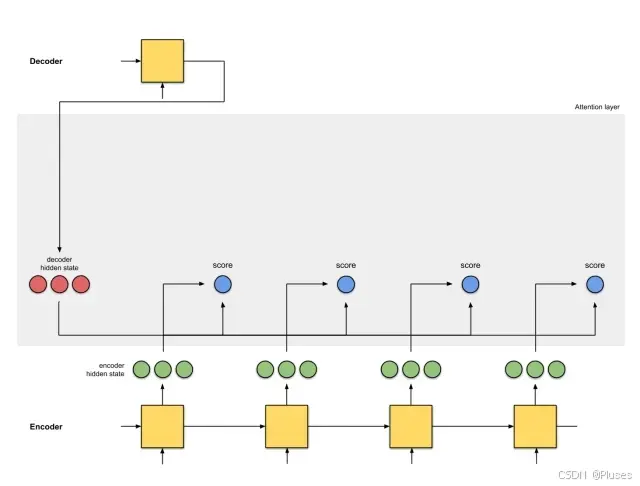
通过评分函数来获取每个编码器隐藏状态的分数(标量)。在下图中,评分函数是解码器和编码器隐藏状态之间的点积。
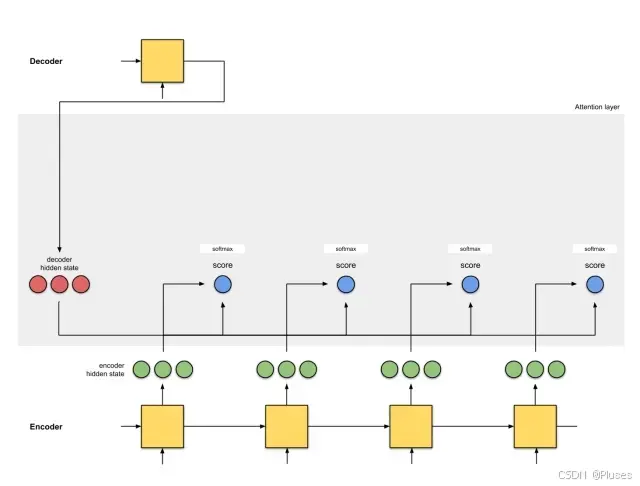
(3)通过softmax层运行所有得分
我们将得分放到softmax函数层,使softmax得分(标量)之和为1,这些得分代表注意力的分布。
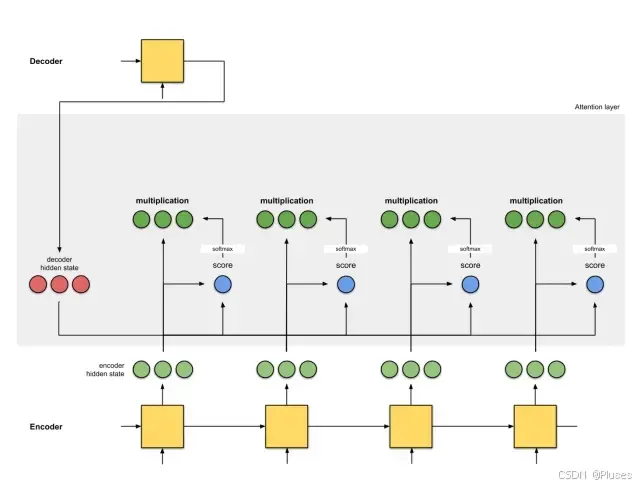
(4)将每个编码器的隐藏状态乘以其softmax得分
将每个编码器的隐藏状态与其softmaxed得分(标量)相乘,就能获得对齐向量,这就是发生对齐机制的地方。
(5)将对齐向量聚合起来
将对齐向量聚合起来,得到语境向量。
(6)将语境向量输入到解码器中
这一步怎么做,取决于模型的架构设计。
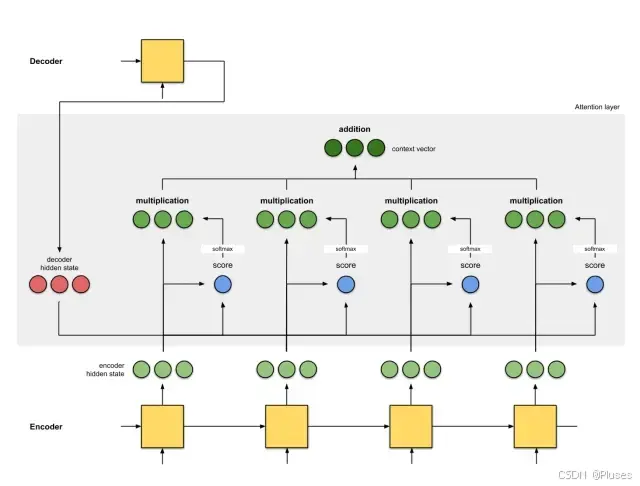
我们最终可以得到整体的运行机制如下图所示:

引用:不用看数学公式!图解谷歌神经机器翻译核心部分:注意力机制
2、gru门控循环单元
门控循环单元与普通的循环神经网络之间的关键区别在于: 前者支持隐状态的门控。 这意味着模型有专门的机制来确定应该何时更新隐状态, 以及应该何时重置隐状态。 这些机制是可学习的,例如,如果第一个词元非常重要, 模型将学会在第一次观测之后不更新隐状态。 同样,模型也可以学会跳过不相关的临时观测。 最后,模型还将学会在需要的时候重置隐状态。
3、拓展:transformer模型
2017年,vaswani等人在论文attention is all you need中提出了完全基于自注意力机制的transformer模型,进一步摒弃了循环结构,实现了并行化训练和更高效的序列建模。transformer迅速成为nlp领域的主导模型架构,包括在seq2seq任务中的广泛应用。
具体模型结构如下图所示:
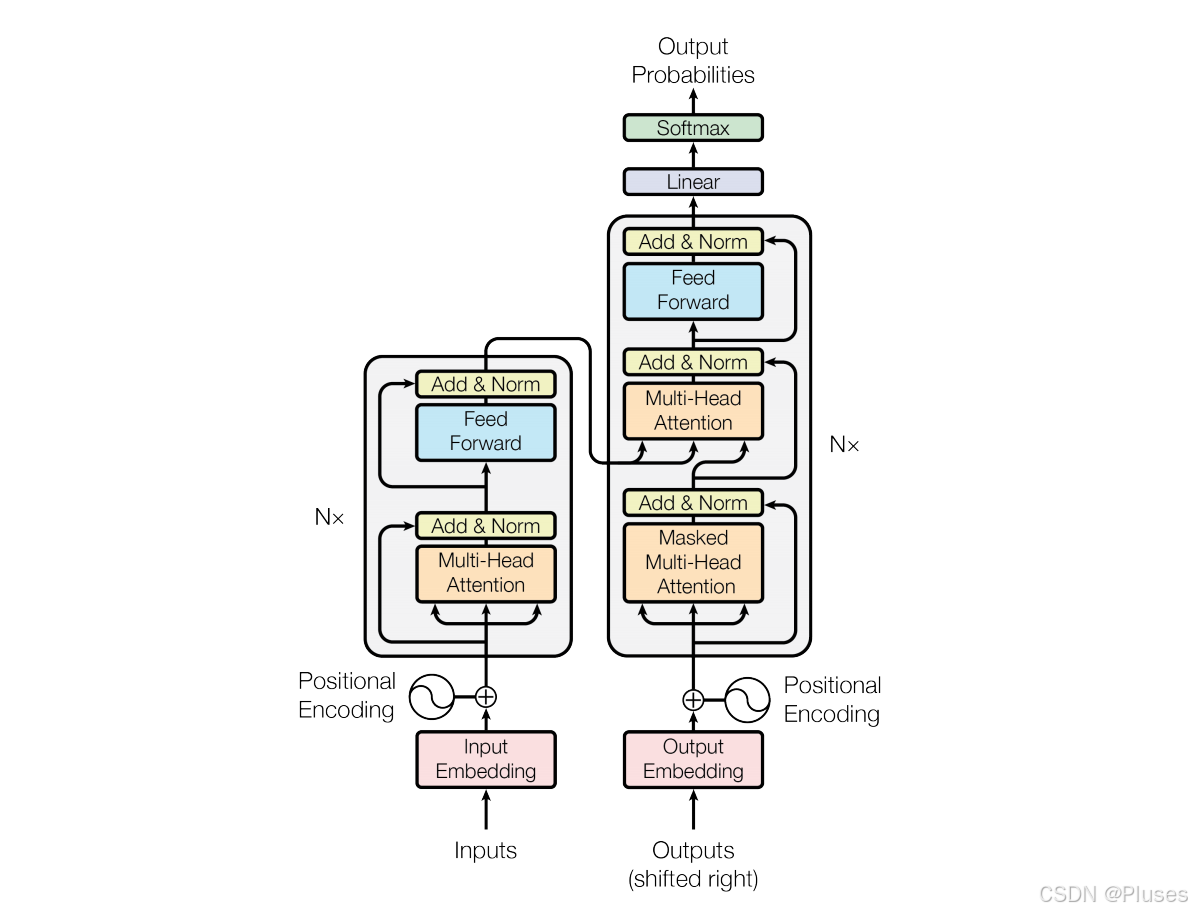
更详细的模型介绍和解释可以移步至:
the illustrated transformer https://jalammar.github.io/illustrated-transformer/
https://jalammar.github.io/illustrated-transformer/
hahaha都看到这里了,要是觉得有用的话就辛苦动动小手点个赞吧!

发表评论