众所周知,selenium是一个用于自动化web应用程序测试的工具,通过控制浏览器执行这些脚本来模拟用户的操作。但是,太容易被检测!通过selenium启动的浏览器,有很多的特征能够被检测出来,进而触发验证码、滑块等。
网上有很多的防检测方法,大都是掩耳盗铃,对于一些网站来说没什么效果。只要使用selenium启动浏览器,必定会被检测到。
通过访问 sannysoft 可以看到,使用selenium启动的网站,不管用了什么防检测,都会被检测出来。
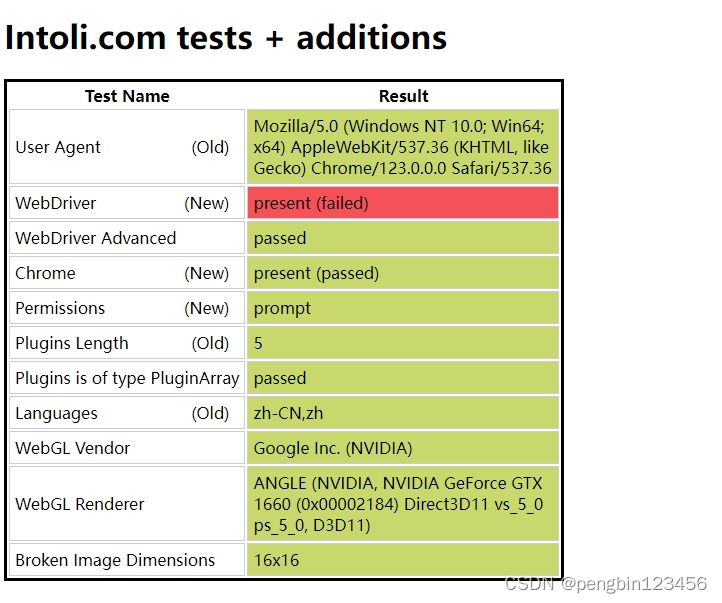
既然使用selenium启动浏览器就会被检测到,那该如何绕过检测?
没错,那就是不用selenium启动。我们可以通过手动启动浏览器,并用selenium连接此浏览器,达到完美的防检测。但是我们既然用selenium,肯定是为了自动化,不可能每次都先手动打开浏览器。
我们可以使用subprocess 来启动浏览器,再用selenium连接,来完成这一流程。
话不多说,直接进入正题:
(此次需要用到的插件,没有安装的小伙伴可以自行安装一下)
browser_path = "c:\\program files\\google\\chrome\\application\\chrome.exe"
subprocess.popen([browser_path,'--remote-debugging-port=9222'])使用subprocess命令行打开浏览器,并且添加参数,给此次启动的浏览器添加一个9222的端口。browser_path 的值是你电脑里谷歌浏览器的路径,windows一般是这个。
options = options()
options.add_experimental_option("debuggeraddress", "127.0.0.1:9222")
driver = webdriver.chrome(executable_path='c:\\program files\\google\\chrome\\application\\chromedriver.exe', options=options)
driver.get('https://bot.sannysoft.com/')然后通过selenium的设置浏览器选项,通过上面的端口,连接上浏览器。executtable_path的路径和上面一样。
最后直接访问地址,可以看到,我们这个完全和手动打开的浏览器一模一样,成功的绕过了所有检测。

最后,贴上完整代码
from selenium import webdriver
from selenium.webdriver.chrome.options import options
import subprocess
import time
browser_path = "c:\\program files\\google\\chrome\\application\\chrome.exe"
subprocess.popen([browser_path,'--remote-debugging-port=9222'])
time.sleep(3)
options = options()
options.add_experimental_option("debuggeraddress", "127.0.0.1:9222")
driver = webdriver.chrome(executable_path='c:\\program files\\google\\chrome\\application\\chromedriver.exe', options=options)
driver.get('https://bot.sannysoft.com/')大功告成!

发表评论