
目录
一、引言
pipeline(管道)是huggingface transformers库中一种极简方式使用大模型推理的抽象,将所有大模型分为音频(audio)、计算机视觉(computer vision)、自然语言处理(nlp)、多模态(multimodal)等4大类,28小类任务(tasks)。共计覆盖32万个模型
今天介绍cv计算机视觉的第三篇,图像分割(image-segmentation),在huggingface库内有800个图像分类模型。
二、图像分割(image-segmentation)
2.1 概述
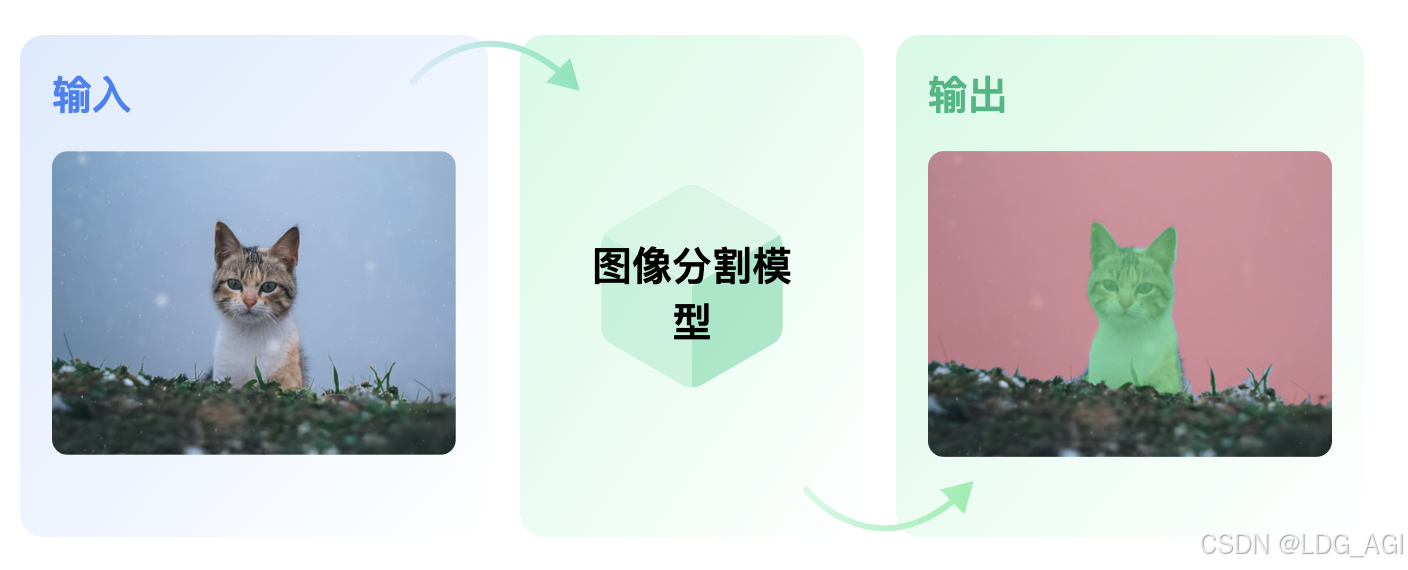
图像分割就是把图像分成若干个特定的、具有独特性质的区域并提出感兴趣目标的技术和过程。它是由图像处理到图像分析的关键步骤。现有的图像分割方法主要分以下几类:基于阈值的分割方法、基于区域的分割方法、基于边缘的分割方法以及基于特定理论的分割方法等。从数学角度来看,图像分割是将数字图像划分成互不相交的区域的过程。图像分割的过程也是一个标记过程,即把属于同一区域的像素赋予相同的编号。
2.2 技术原理
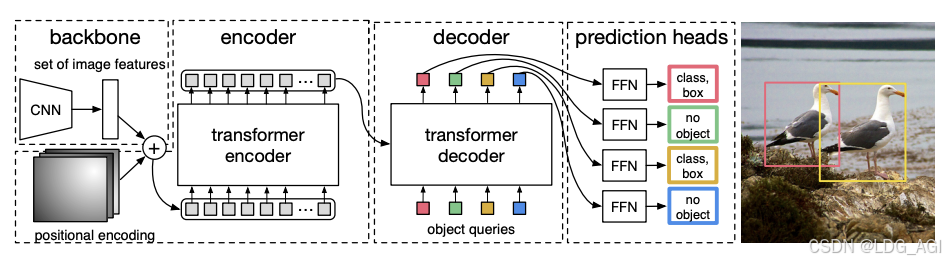
图像分割(image-segmentation)的默认模型为facebook/detr-resnet-50-panoptic,全称为:detection transformer(detr)-resnet-50-全景。其中有3个要素:
detection transformer(detr)主体结构:
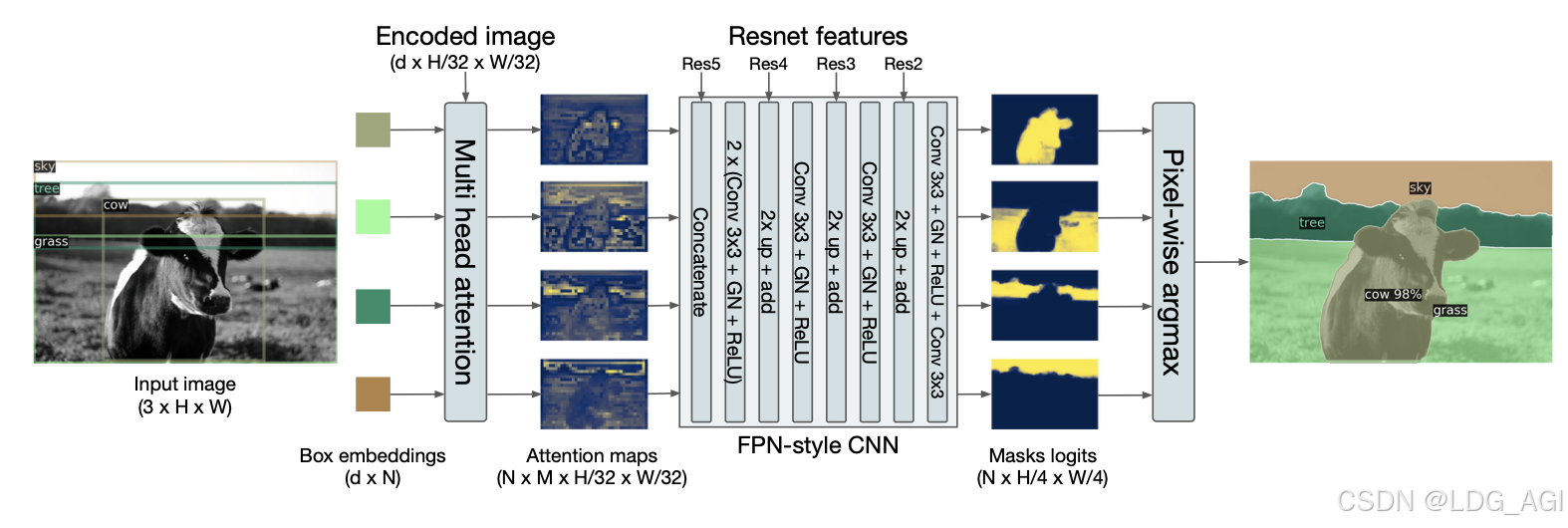
detection transformer(detr)应用于全景分割:
2.3 应用场景
2.4 pipeline参数
2.4.1 pipeline对象实例化参数
2.4.2 pipeline对象使用参数
2.4 pipeline实战
识别http链接中的物品

采用pipeline代码如下
import os
os.environ["hf_endpoint"] = "https://hf-mirror.com"
os.environ["cuda_visible_devices"] = "2"
from transformers import pipeline
image_segmentation = pipeline(task="image-segmentation",model="facebook/detr-resnet-50-panoptic")
output = image_segmentation("http://images.cocodataset.org/val2017/000000039769.jpg")
print(output)
"""
[{'score': 0.994096, 'label': 'cat', 'mask': <pil.image.image image mode=l size=640x480 at 0x7f24e13b4710>}, {'score': 0.998669, 'label': 'remote', 'mask': <pil.image.image image mode=l size=640x480 at 0x7f24e13b4950>}, {'score': 0.999476, 'label': 'remote', 'mask': <pil.image.image image mode=l size=640x480 at 0x7f24a2836250>}, {'score': 0.972207, 'label': 'couch', 'mask': <pil.image.image image mode=l size=640x480 at 0x7f24a2837210>}, {'score': 0.999423, 'label': 'cat', 'mask': <pil.image.image image mode=l size=640x480 at 0x7f24a2836290>}]
"""
output[0]["mask"].save(output[0]["label"]+".png")执行后,自动下载模型文件:
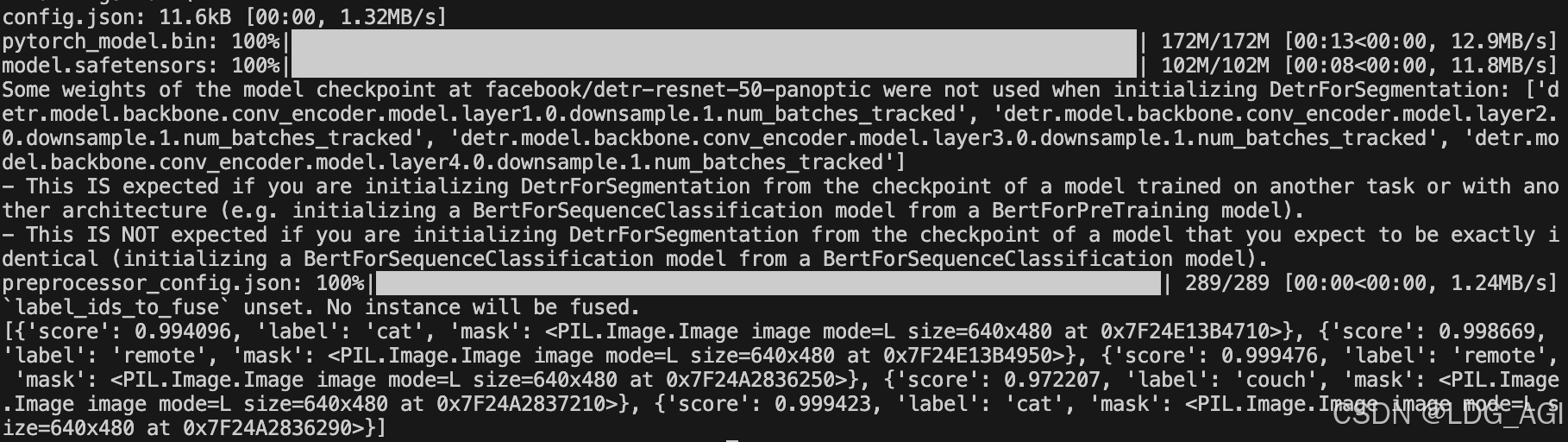
图像分割后的结果会存入字典list中,将图片image保存后,打开可见分割出的图片:

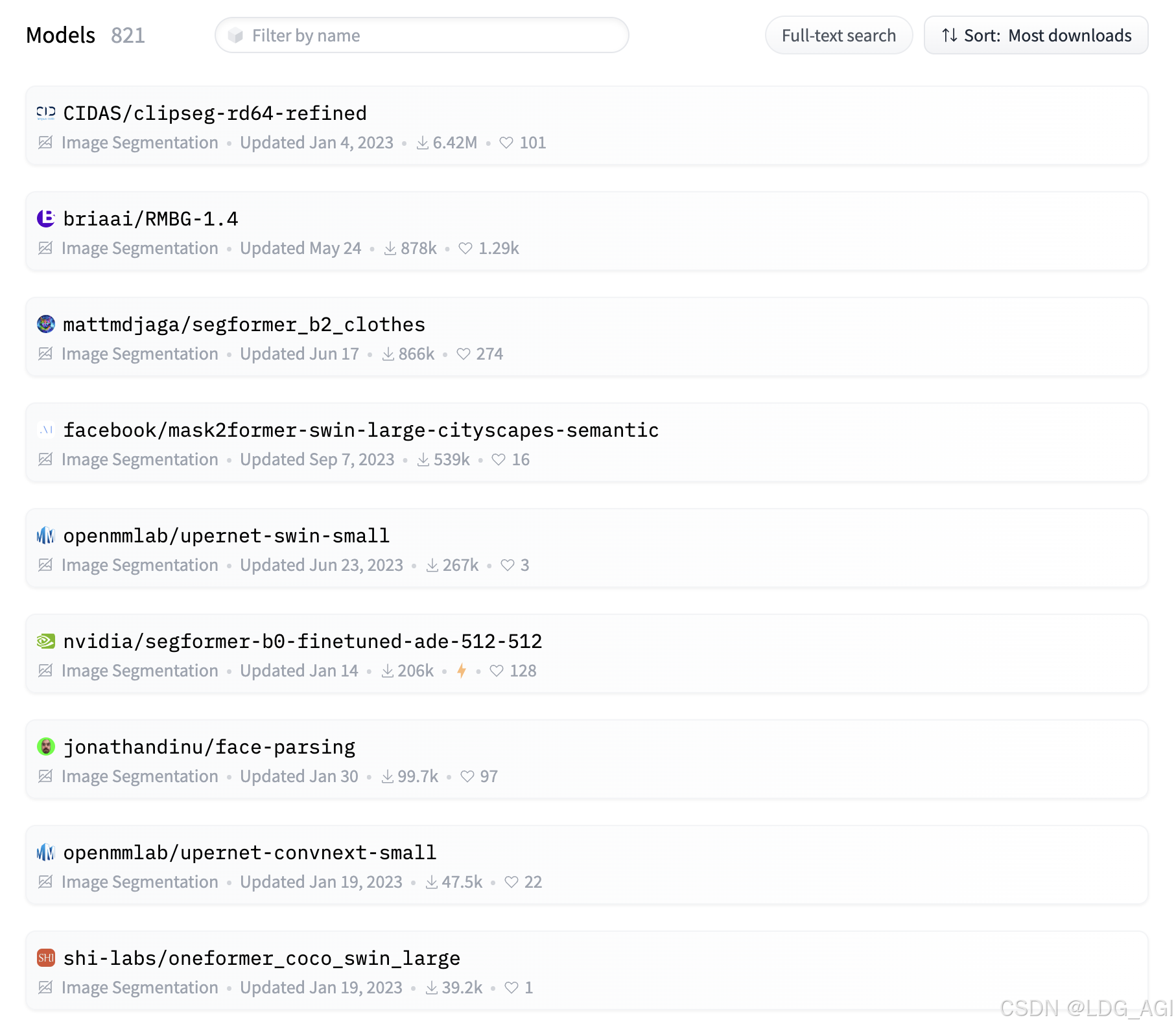
2.5 模型排名
在huggingface上,我们将图像分割(image-segmentation)模型按下载量从高到低排序:
三、总结
本文对transformers之pipeline的图像分割(image-segmentation)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipeline使用文中的2行代码极简的使用计算机视觉中的图像分割(image-segmentation)模型。
期待您的3连+关注,如何还有时间,欢迎阅读我的其他文章:
《transformers-pipeline概述》
【人工智能】transformers之pipeline(概述):30w+大模型极简应用
《transformers-pipeline 第一章:音频(audio)篇》
【人工智能】transformers之pipeline(一):音频分类(audio-classification)
【人工智能】transformers之pipeline(二):自动语音识别(automatic-speech-recognition)
【人工智能】transformers之pipeline(三):文本转音频(text-to-audio/text-to-speech)
【人工智能】transformers之pipeline(四):零样本音频分类(zero-shot-audio-classification)
《transformers-pipeline 第二章:计算机视觉(cv)篇》
【人工智能】transformers之pipeline(五):深度估计(depth-estimation)
【人工智能】transformers之pipeline(六):图像分类(image-classification)
【人工智能】transformers之pipeline(七):图像分割(image-segmentation)
【人工智能】transformers之pipeline(八):图生图(image-to-image)
【人工智能】transformers之pipeline(九):物体检测(object-detection)
【人工智能】transformers之pipeline(十):视频分类(video-classification)
【人工智能】transformers之pipeline(十一):零样本图片分类(zero-shot-image-classification)
【人工智能】transformers之pipeline(十二):零样本物体检测(zero-shot-object-detection)
《transformers-pipeline 第三章:自然语言处理(nlp)篇》
【人工智能】transformers之pipeline(十三):填充蒙版(fill-mask)
【人工智能】transformers之pipeline(十四):问答(question-answering)
【人工智能】transformers之pipeline(十五):总结(summarization)
【人工智能】transformers之pipeline(十六):表格问答(table-question-answering)
【人工智能】transformers之pipeline(十七):文本分类(text-classification)
【人工智能】transformers之pipeline(十八):文本生成(text-generation)
【人工智能】transformers之pipeline(十九):文生文(text2text-generation)
【人工智能】transformers之pipeline(二十):令牌分类(token-classification)
【人工智能】transformers之pipeline(二十一):翻译(translation)
【人工智能】transformers之pipeline(二十二):零样本文本分类(zero-shot-classification)
《transformers-pipeline 第四章:多模态(multimodal)篇》
【人工智能】transformers之pipeline(二十三):文档问答(document-question-answering)
【人工智能】transformers之pipeline(二十四):特征抽取(feature-extraction)
【人工智能】transformers之pipeline(二十五):图片特征抽取(image-feature-extraction)
【人工智能】transformers之pipeline(二十六):图片转文本(image-to-text)
【人工智能】transformers之pipeline(二十七):掩码生成(mask-generation)
【人工智能】transformers之pipeline(二十八):视觉问答(visual-question-answering)


{kind=link}
发表评论