目录
一、selenium
(一)引入
一个电影票房的网站里,响应数据是一串完全看不懂的字符串,这些字串解开之后就是左边的页面。因为解密过程有可能很痛苦,那换个角度,能否不用 requests,而让浏览器本身完成对这些数据的解密和执行,直接显示页面呢
于是有思路:让程序连接浏览器,让浏览器完成复杂操作,此时我们只接收最终结果
selenium 可以实现,它本身是一款自动化测试工具,可以打开浏览器,像人一样操作浏览器,人们可以从 selenium 中直接提取到网页上的各种信息,因为网页信息对于 selenium 来说是透明的,其本质就是运行一个浏览器
安装说明:
selenium 的环境搭建需要安装包、下载对应的浏览器驱动
对应的浏览器驱动放在 python 解释器所在的文件夹下并将名称改为 chromedriver(pycharm执行结果前面的那个路径)

(二)启动浏览器
# 导入并启动
from selenium.webdriver import chrome
# 1.创建浏览器对象
web=chrome()
# 2.打开浏览器打开网址
web.get("http://www.baidu.com")启动成功,显示正在受自动测试软件控制,使用最新版的谷歌浏览器和驱动启动后会自动关闭浏览器,暂时不确定对于获取数据会不会有影响

这样就建立了程序和浏览器的关系,可以用程序使得浏览器跑起来(对于动态加载的数据会很有效)
二、操作
(一)点击
打开网页,比如我想在这个网页点击“全国”这个按钮,可以将 xpath 复制过来
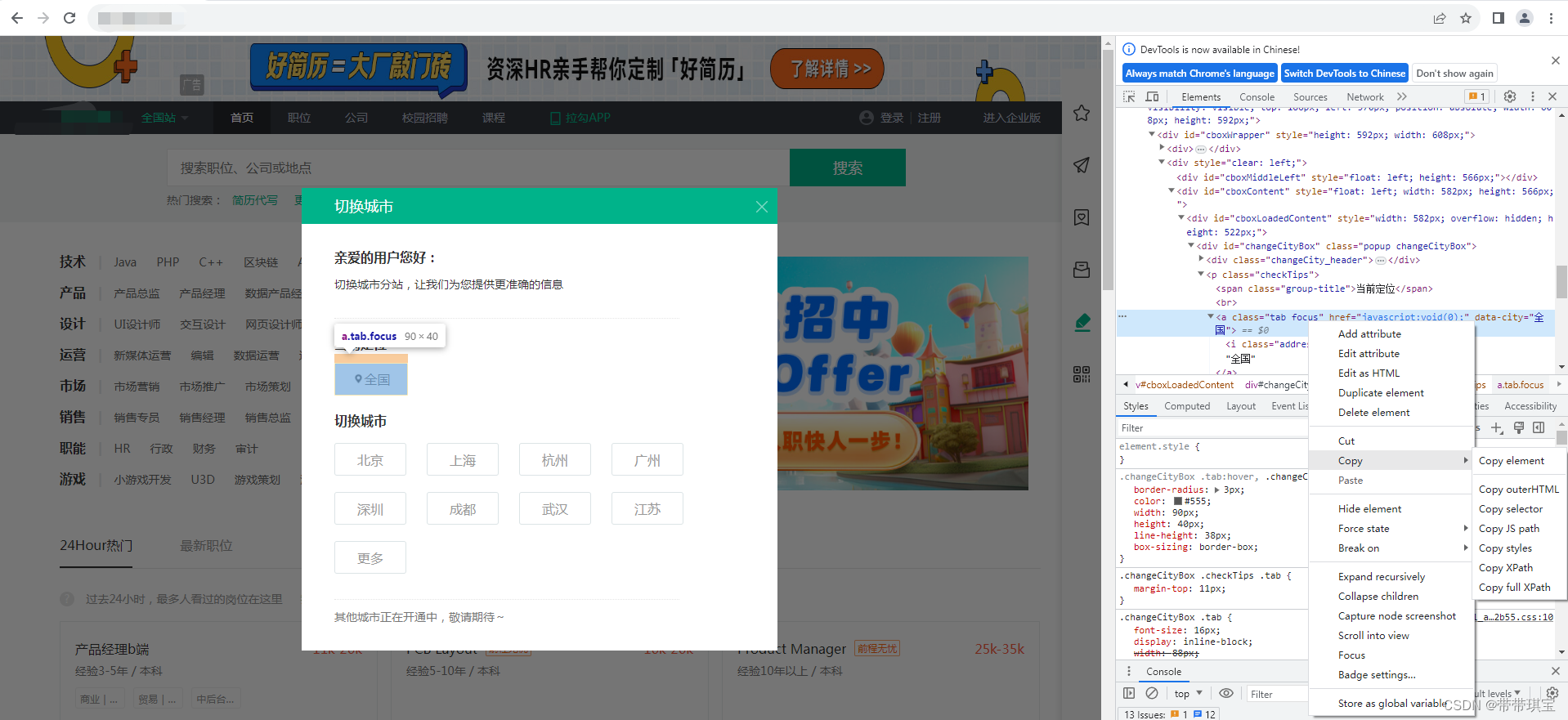
使用 find_element(有些版本是 find_element_by_xpath)
from selenium.webdriver import chrome
# 1.创建浏览器对象
web=chrome()
# 2.打开浏览器打开网址
web.get("http://lagou.com")
# 找到某个元素点击
el=web.find_element('xpath','//*[@id="changecitybox"]/p[1]/a')
# 这样子找到按钮,可以by许多东西,有s的会知道所有element
el.click() # 点击(二)输入
想要输入,需要先找到输入框,输入后使用回车键,或者点击搜索按钮(与上面一直)
1.找到输入框
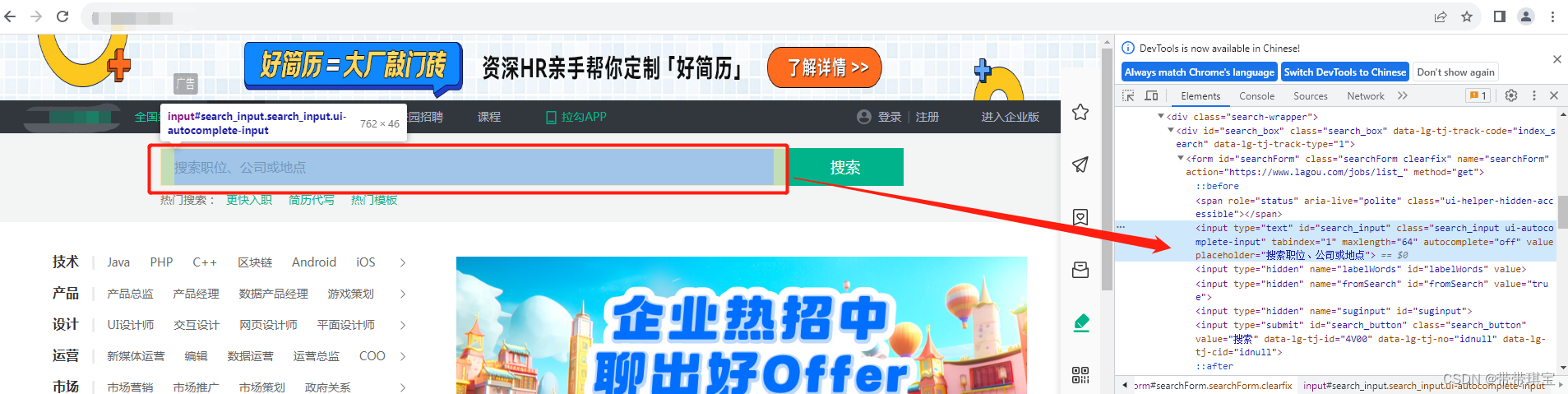
2.在输入框输入"python"
找到输入框,find_element() 后使用 send_keys() 输入
如果想按键盘的回车键,需要导包,使用keys.xxx
from selenium.webdriver.common.keys import keys
time.sleep(1)
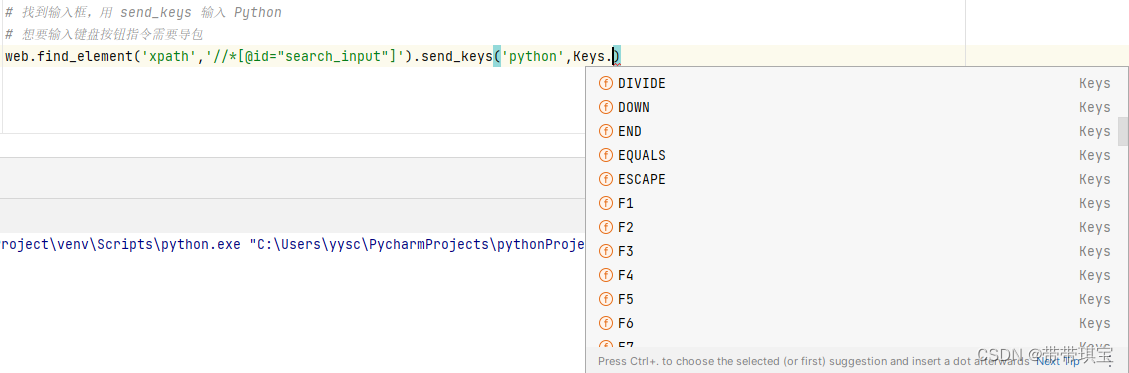
web.find_element('xpath','//*[@id="search_input"]').send_keys('python',keys.enter)keys 可以操作很多键盘的按键
 输入前注意:上面选择“全国”选项之后,若网站是动态加载的,可能加载的比程序运行的滞后,所以可能没加载出来要找的内容而导致程序报错,所以 sleep 一秒钟
输入前注意:上面选择“全国”选项之后,若网站是动态加载的,可能加载的比程序运行的滞后,所以可能没加载出来要找的内容而导致程序报错,所以 sleep 一秒钟
三、数据获取
现在其实已经获取了想要的内容,找某个元素提取内容即可,观察网页结构每个岗位信息都在这个 list 里面,循环遍历<div class="item__10rto">
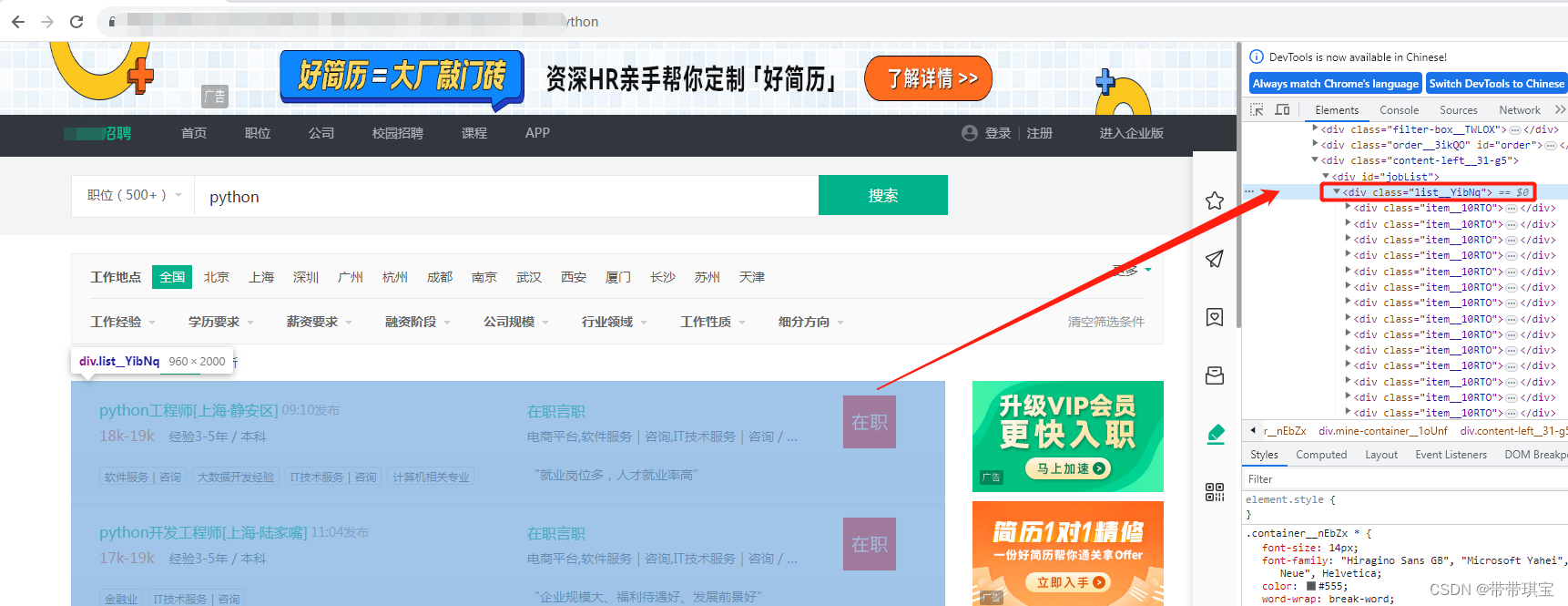
刚开始通过 tag name 查找,发现有很多个 a 标签,就混乱了,于是根据复制的 xpath 结果来查找,也是用类似的方式继续查找其他信息,这里我找到了薪资、公司名和岗位一些岗位信息
# for a in div_list:
# job_name=a.find_elements('tag name','a') # a标签
# for n in range(len(job_name)):
# print(job_name[n].text)这里主要是通过属性、标签名、xpath 的相对路径完成对数据元素的定位
time.sleep(1)
div_list=web.find_elements('xpath','//*[@id="joblist"]/div[1]/div')
for a in div_list:
job_name=a.find_element('id','openwinpostion').text
price=a.find_element('class name','money__3lkgq').text
company_name=a.find_element('xpath','./div[1]/div[2]/div/a').text
print(job_name,price,company_name)
# .表示从当前节点开始,//表示某个父节点的所有后代,*为任意节点的id属性为 "openwinpostion" 的文本
这里的一点 xpath 基础:. 表示从当前节点开始,// 表示某个父节点的所有后代,* 为任意节点的id属性为为"openwinpostion" 的文本
成功

四、特点
selenium使用便捷,易于编写,可以屏蔽许多js加密、解密问题,但是其运行速度较慢,且一些网站会针对通过 selenium 方法进行的访问做反爬,所以使用的时候并不是万能的
五、抓取拉钩实例
# 启动
from selenium.webdriver import chrome
from selenium.webdriver.common.keys import keys
import time
# 1.创建浏览器对象
web=chrome()
# 2.打开浏览器打开网址
web.get("http://lagou.com")
# 找到某个元素点击
el=web.find_element('xpath','//*[@id="changecitybox"]/p[1]/a') # 这样子找到按钮,可以by许多东西,有s的会知道所有element
el.click() # 点击
time.sleep(1)
# 找到输入框,用 send_keys 输入 python
# 想要输入键盘按钮指令需要导包
web.find_element('xpath','//*[@id="search_input"]').send_keys('python',keys.enter)
time.sleep(1)
div_list=web.find_elements('xpath','//*[@id="joblist"]/div[1]/div')
for a in div_list:
job_name=a.find_element('id','openwinpostion').text
price=a.find_element('class name','money__3lkgq').text
company_name=a.find_element('xpath','./div[1]/div[2]/div/a').text
print(job_name,price,company_name)
# .表示从当前节点开始,//表示某个父节点的所有后代,*为任意节点的id属性为 "openwinpostion" 的文本-------------------------------------------------------分割线---------------------------------------------------------------
六、其他操作
以下为 selenium 的一些补充操作
(一)窗口切换
假设在搜索 "python" 关键词后到了新页面后,想点击进入新窗口查看岗位描述,此时会开启一个新窗口
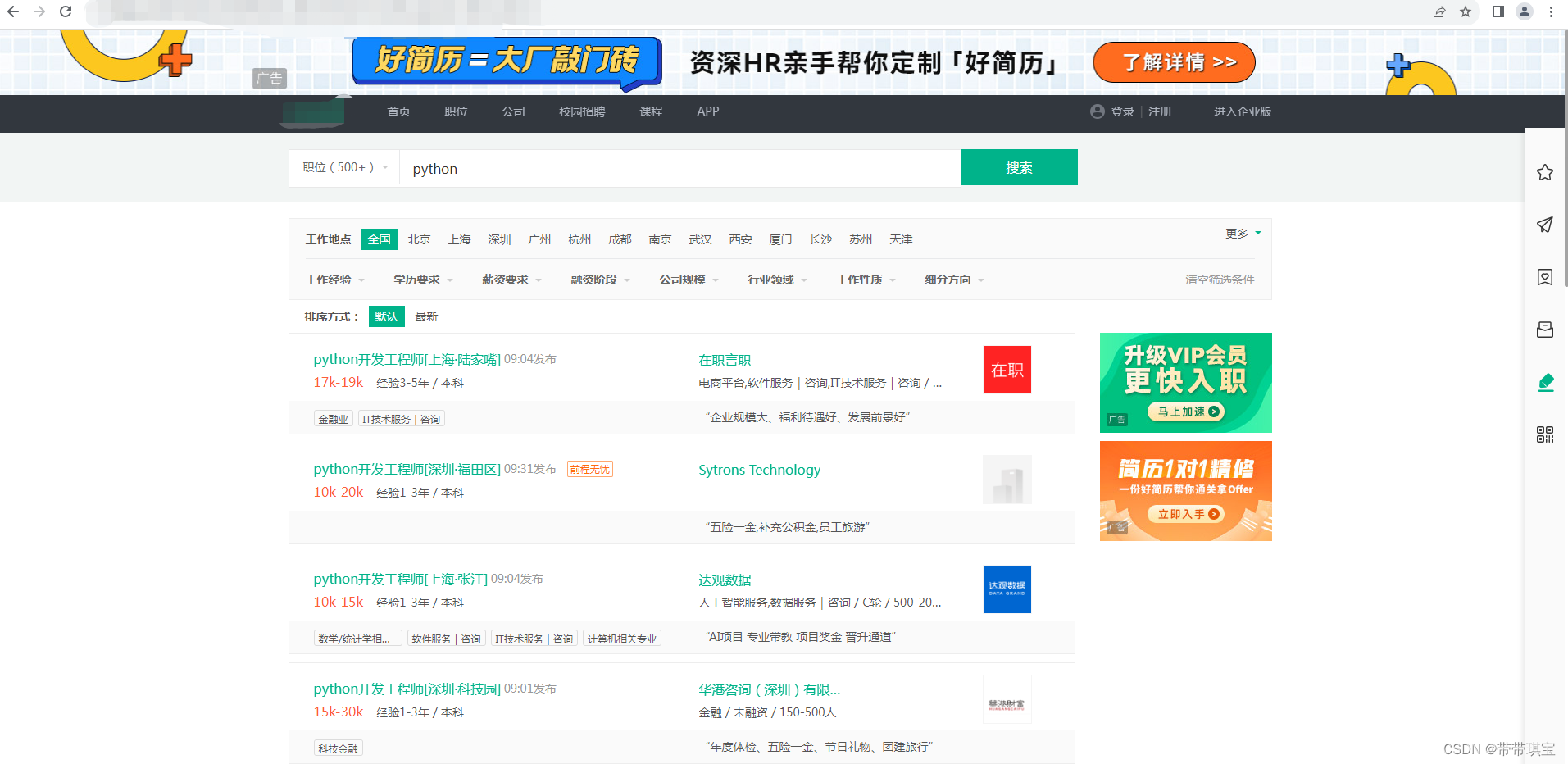
注意:不同于人类视角,对于 selenium 而言,打开窗口之后其视角仍然是上一个窗口,并没有新页面的内容
那如何对新窗口的内容进行提取呢,要做的就是窗口切换
web.switch_to.window(web.window_handles[-1]) # 转移到选项卡为-1窗口上面这句代码是核心,若没有进行切换程序将直接报错,因为程序连接的是原来的窗口
这样 selenium 就会调整到新窗口上,此时可以直接提取新窗口内容了
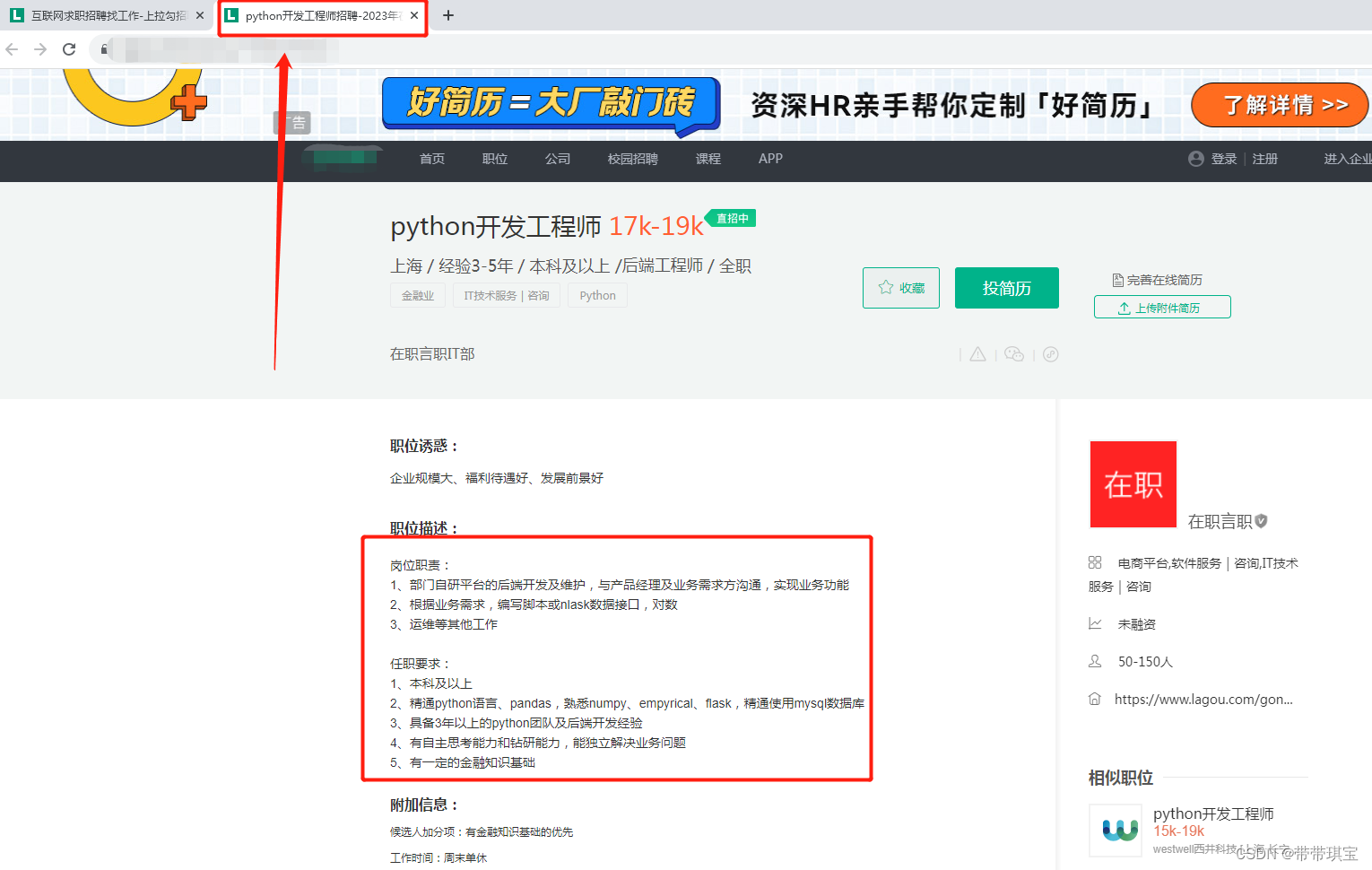
job_detail=web.find_element('xpath','//*[@id="job_detail"]/dd[2]/div').text
print(job_detail)成功

处理完后可以将新窗口关闭,记得将 selenium 视角变更回来(也可使用 switch_to_default_content() 换到最开始切换前的窗口),此时可以尝试打印原窗口的内容,说明视角已经切换回来了
web.close()
web.switch_to.window(web.window_handles[0]) 如果在页面中遇到了 iframe ,想要提取里面的内容必须先拿到 iframe 然后切换视角到 iframe ,然后再拿到数据,用下面这个函数即可
切换到 iframe 后进行 find 就是以 iframe 里面为准了
代码
from selenium.webdriver import chrome
from selenium.webdriver.common.keys import keys
import time
# 创建浏览器对象
web = chrome()
# 打开浏览器打开网址
web.get("http://lagou.com")
# 找到某个元素点击
el = web.find_element('xpath', '//*[@id="changecitybox"]/p[1]/a')
el.click() # 点击
time.sleep(1)
web.find_element('xpath', '//*[@id="search_input"]').send_keys('python', keys.enter)
time.sleep(1)
web.find_element('xpath', '//*[@id="openwinpostion"]').click()
time.sleep(1)
web.switch_to.window(web.window_handles[-1]) # 转移到选项卡为-1窗口
job_detail = web.find_element('xpath', '//*[@id="job_detail"]/dd[2]/div').text
print(job_detail)
web.close()
web.switch_to.window(web.window_handles[0])
print(web.find_element('xpath', '//*[@id="openwinpostion"]'))(二)操作下拉列表/无头浏览器
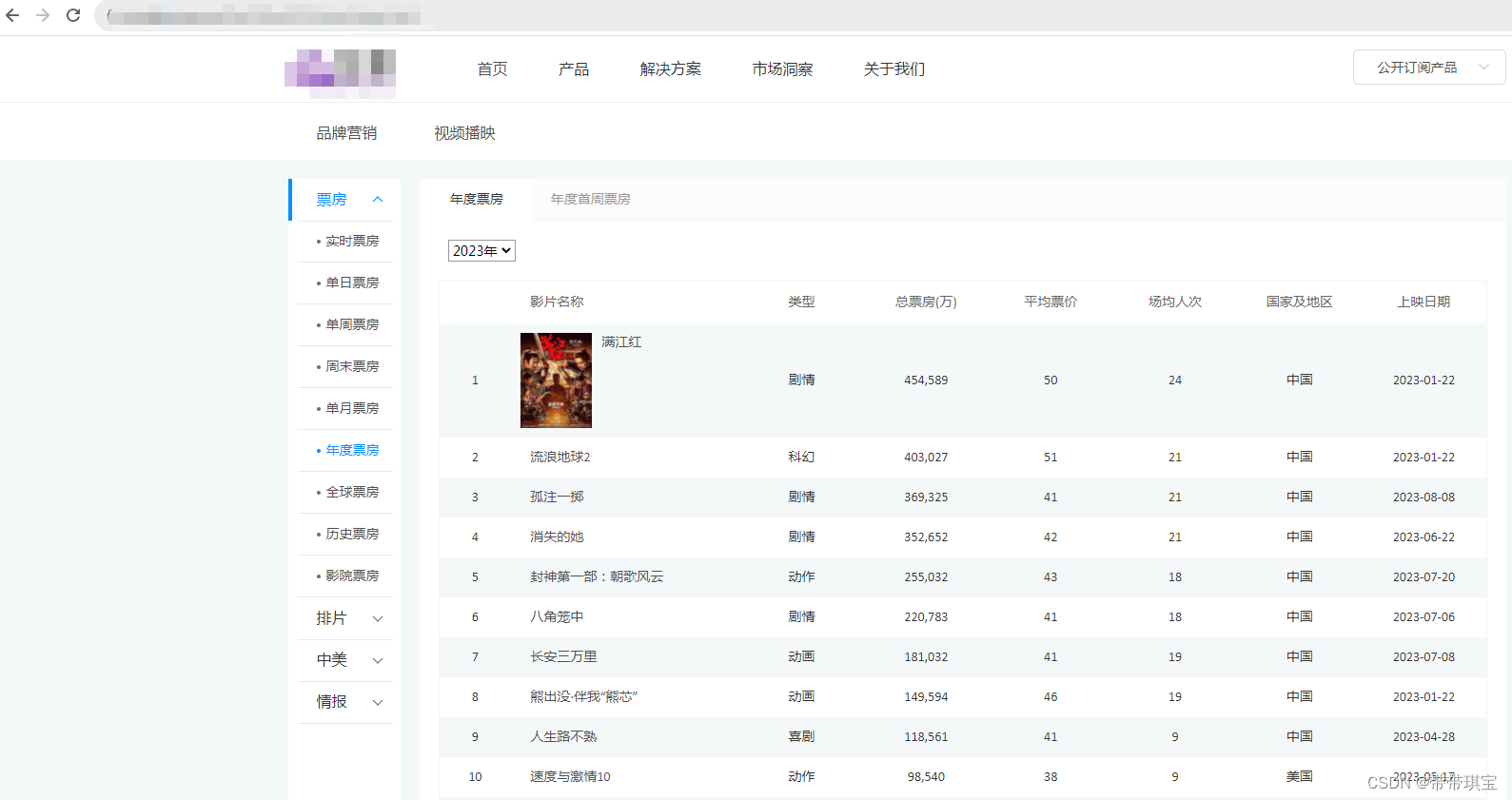
回到原来的那个票房网页
from selenium.webdriver import chrome
web = chrome()
web.get("https://www.endata.com.cn/boxoffice/bo/year/index.html")打开浏览器,这里可以选择年份(需要点击),这是通过网页的 select 标签存放的
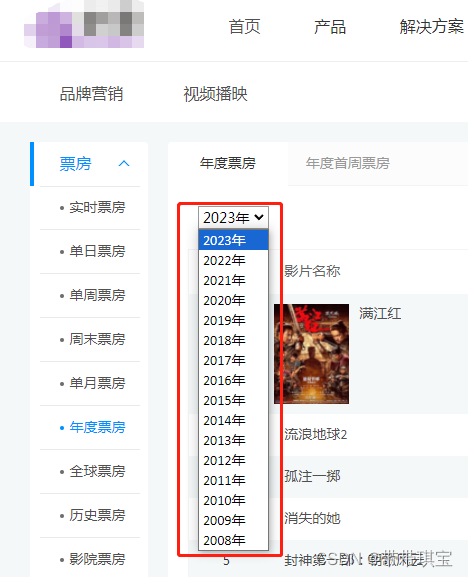
这个列表这个是通过 css 动态加载的,不需要鼠标点击就能出现
如何处理下拉框对年份进行筛选:先定位到下拉框,使用 selenium 拿到该节点
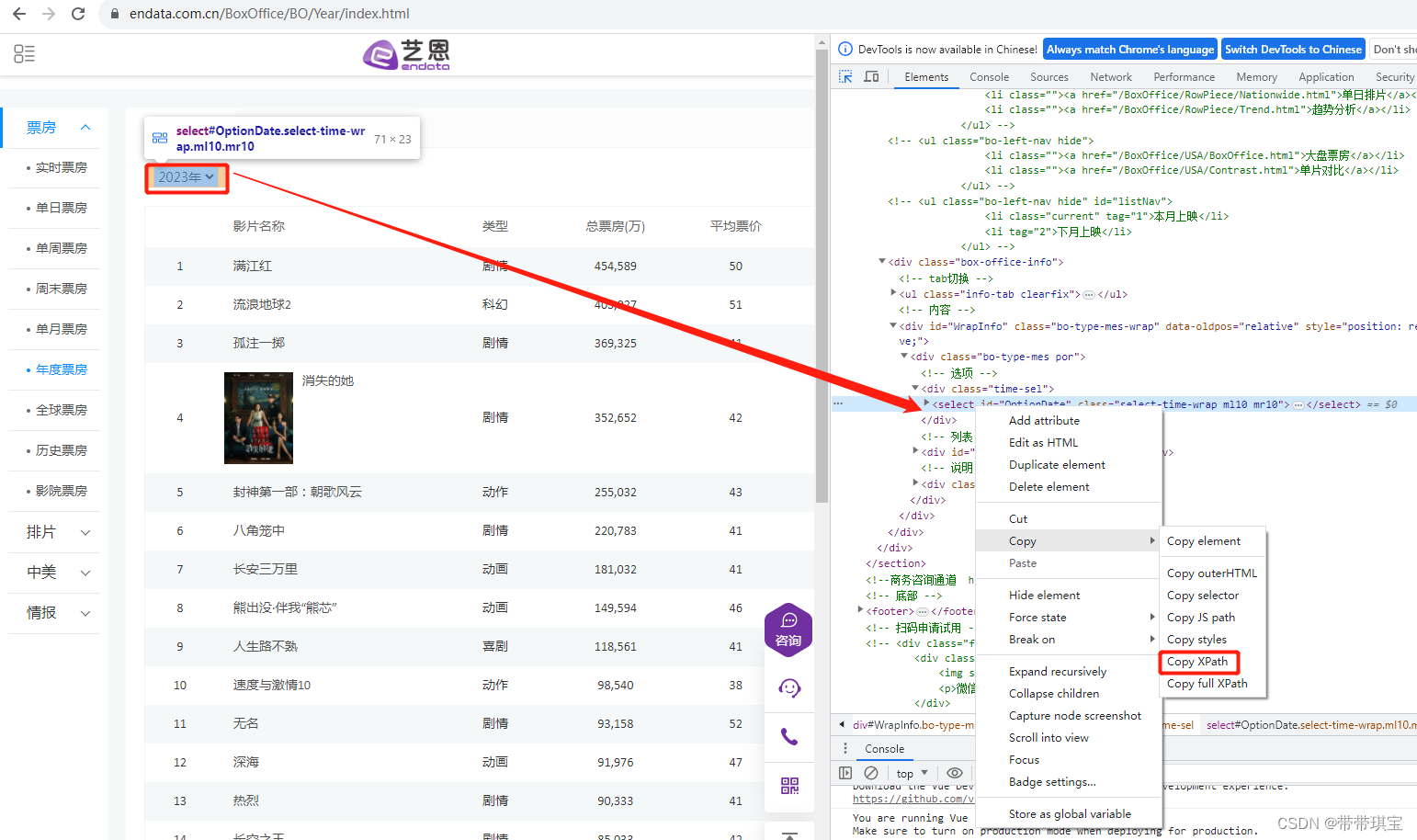
在拿到该节点之后由于是一个下拉列表,需要对元素包装一下,包装成一个下拉菜单,这样就可以调整 select 的位置了。
sel=select(sel_el) # 把元素放进去包装成 select 类型的东西
print(sel,type(sel),id(sel))
<selenium.webdriver.support.select.select object at 0x00000269efa82910> <class 'selenium.webdriver.support.select.select'> 2654015596816
# 是一个select类型的对象
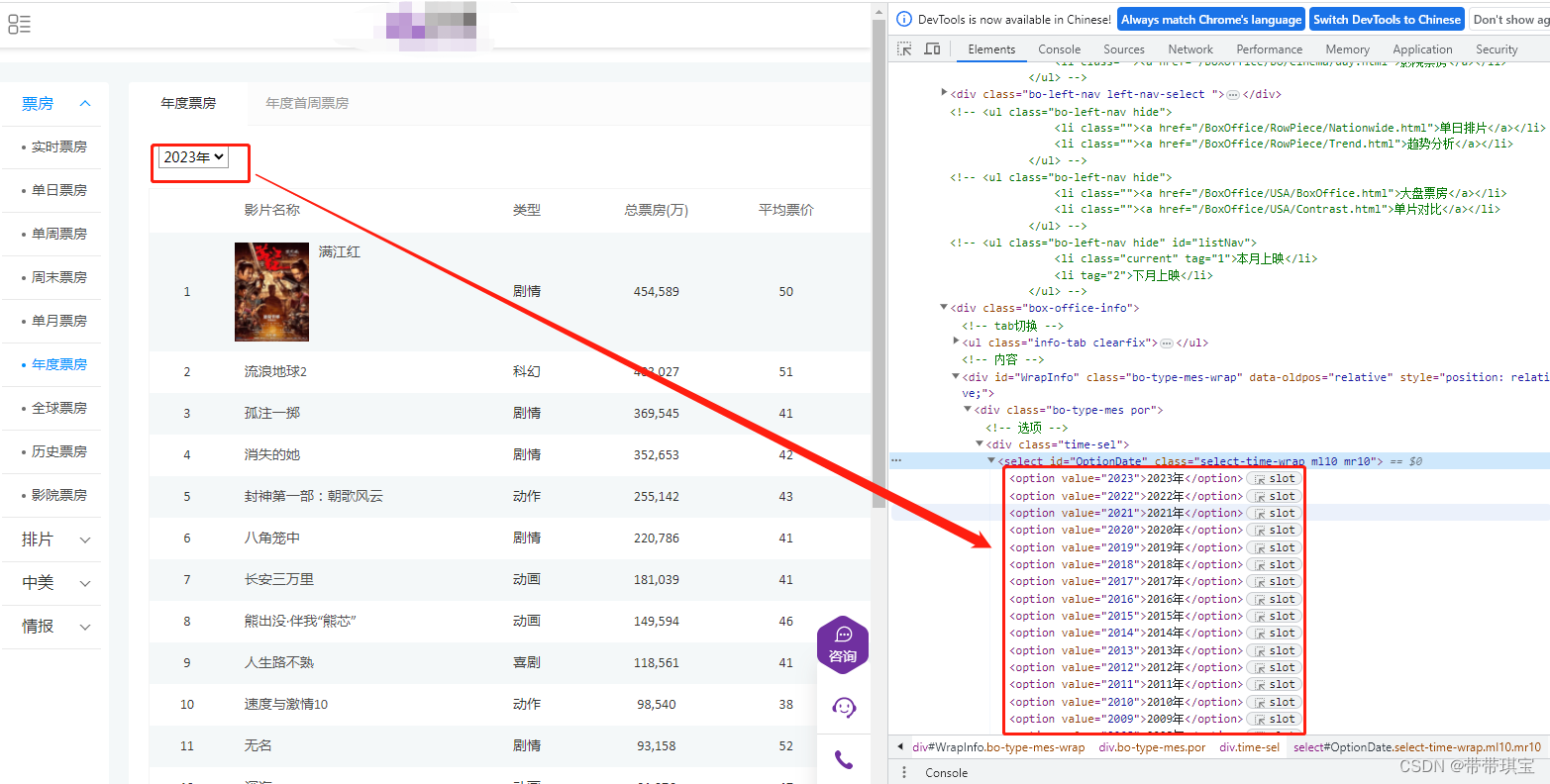
如图不同年份之间的选项是以不同的 option 存储的,我想随意切换所有选项如何做?几乎固定的操作:
# 让浏览器调整选项让浏览器调整选项
for i in range(len(sel.options)): # 下拉框的所有选项的长度,i是下拉框每个选项索引位置
sel.select_by_index(i) # 按照索引进行切换
# time.sleep(3)
movie_table=web.find_element('xpath','//*[@id="tablelist"]/table')
print(movie_table.text)代码解释:根据下拉框选项的长度循环,按索引进行选择,找到数据,打印
除了刚刚的索引,可以根据以下三种方法进行下拉框选择,区分三个 by:

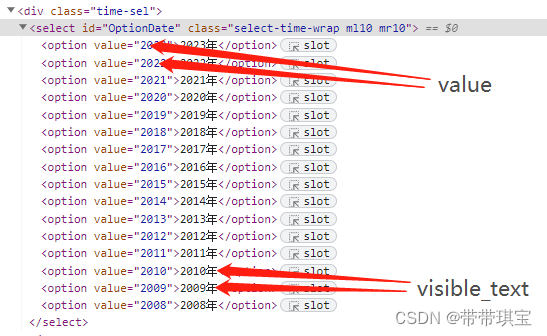
无头浏览器就是让浏览器在后台默默运行,如果不想看到浏览器运行界面,可以对生成的web对象做配置
from selenium.webdriver.chrome.options import options
# 设置参数
opt=options()
opt.add_argument("--headless") # 无头
opt.add_argument("--disable-gpu") #不用显卡
web = chrome(options=opt) # 参数配置到浏览器中代码
from selenium.webdriver import chrome
from selenium.webdriver.support.select import select
import time
from selenium.webdriver.chrome.options import options
# 设置参数
opt=options()
opt.add_argument("--headless") # 无头
opt.add_argument("--disable-gpu") #不用显卡
web = chrome(options=opt)
web.get("https://www.endata.com.cn/boxoffice/bo/year/index.html")
# 定位到下拉列表,拿到节点
sel_el=web.find_element('xpath','//*[@id="optiondate"]')
time.sleep(1)
sel=select(sel_el) # 把元素放进去包装成 select 类型的东西
# 让浏览器调整选项让浏览器调整选项
for i in range(len(sel.options)): # 下拉框的所有选项的长度,i是下拉框每个选项索引位置
sel.select_by_index(i) # 按照索引进行切换
# time.sleep(3)
movie_table=web.find_element('xpath','//*[@id="tablelist"]/table')
print(movie_table.text)

发表评论