zookeeper应用的开发主要通过java客户端api去连接和操作zookeeper集群。可供选择的java客户端api有:
- zookeeper官方的java客户端api。
- 第三方的java客户端api,比如curator。
接下来我们将逐一学习一下这两个java客户端是如何操作zookeeper的。
1. zookeeper官方的java客户端
1.1 简介
zookeeper官方的客户端api提供了基本的操作。例如,创建会话、创建节点、读取节点、更新数据、删除节点和检查节点是否存在等。不过,对于实际开发来说,zookeeper官方api有一些不足之处,具体如下:
- zookeeper的watcher监听是一次性的,每次触发之后都需要重新进行注册。
- 会话超时之后没有实现重连机制。
- 异常处理烦琐,zookeeper提供了很多异常,对于开发人员来说可能根本不知道应该如何处理这些抛出的异常。
- 仅提供了简单的byte[]数组类型的接口,没有提供java pojo级别的序列化数据处理接口。
- 创建节点时如果抛出异常,需要自行检查节点是否存在。
- 无法实现级联删除。
总之,zookeeper官方api功能比较简单,在实际开发过程中比较笨重,一般不推荐使用。
1.2 基础使用
使用zookeeper原生客户端,需要引入zookeeper客户端的依赖。
<dependency>
<groupid>org.apache.zookeeper</groupid>
<artifactid>zookeeper</artifactid>
<version>3.8.3</version>
</dependency>注意:保持与服务端版本一致,不然会有很多兼容性的问题。
1.2.1 连接zk集群
1.2.2 操作节点
以下是zookeeper原生客户端操作服务端的一些主要api:
- create(path, data, acl,createmode): 创建一个给定路径的 znode,并在 znode 保存 data[]的 数据,createmode指定 znode 的类型。
- delete(path, version):如果给定 path 上的 znode 的版本和给定的 version 匹配, 删除 znode。
- exists(path, watch):判断给定 path 上的 znode 是否存在,并在 znode 设置一个 watch。
- getdata(path, watch):返回给定 path 上的 znode 数据,并在 znode 设置一个 watch。
- setdata(path, data, version):如果给定 path 上的 znode 的版本和给定的 version 匹配,设置znode 数据。
- getchildren(path, watch):返回给定 path 上的 znode 的孩子 znode 名字,并在 znode 设置一个 watch。
- sync(path):把客户端 session 连接节点和 leader 节点进行同步。
api特点:
- 所有获取 znode 数据的 api 都可以设置一个 watch 用来监控 znode 的变化。
- 所有更新 znode 数据的 api 都有两个版本: 无条件更新版本和条件更新版本。如果 version 为 -1,更新为无条件更新。否则只有给定的 version 和 znode 当前的 version 一样,才会进行更新,这样的更新是条件更新。
- 所有的方法都有同步和异步两个版本。同步版本的方法发送请求给 zookeeper 并等待服务器的响 应。异步版本把请求放入客户端的请求队列,然后马上返回。异步版本通过 callback 来接受来 自服务端的响应。
接下来,我们利用这些api对zk的节点进行简单的操作
1.2.2.1 创建持久节点
代码:
public class zkclientdemo {
private final static string cluster_connect_str="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";
public static void main(string[] args) throws exception {
//创建zookeeper对象
zookeeper zookeeper = zookeeperfacotry.create(cluster_connect_str);
//连接
system.out.println(zookeeper.getstate());
stat stat = zookeeper.exists("/order",false);
if(null ==stat){
//创建持久节点
zookeeper.create("/order","001".getbytes(),
zoodefs.ids.open_acl_unsafe, createmode.persistent);
}
system.out.println("执行完了");
}运行的结果:
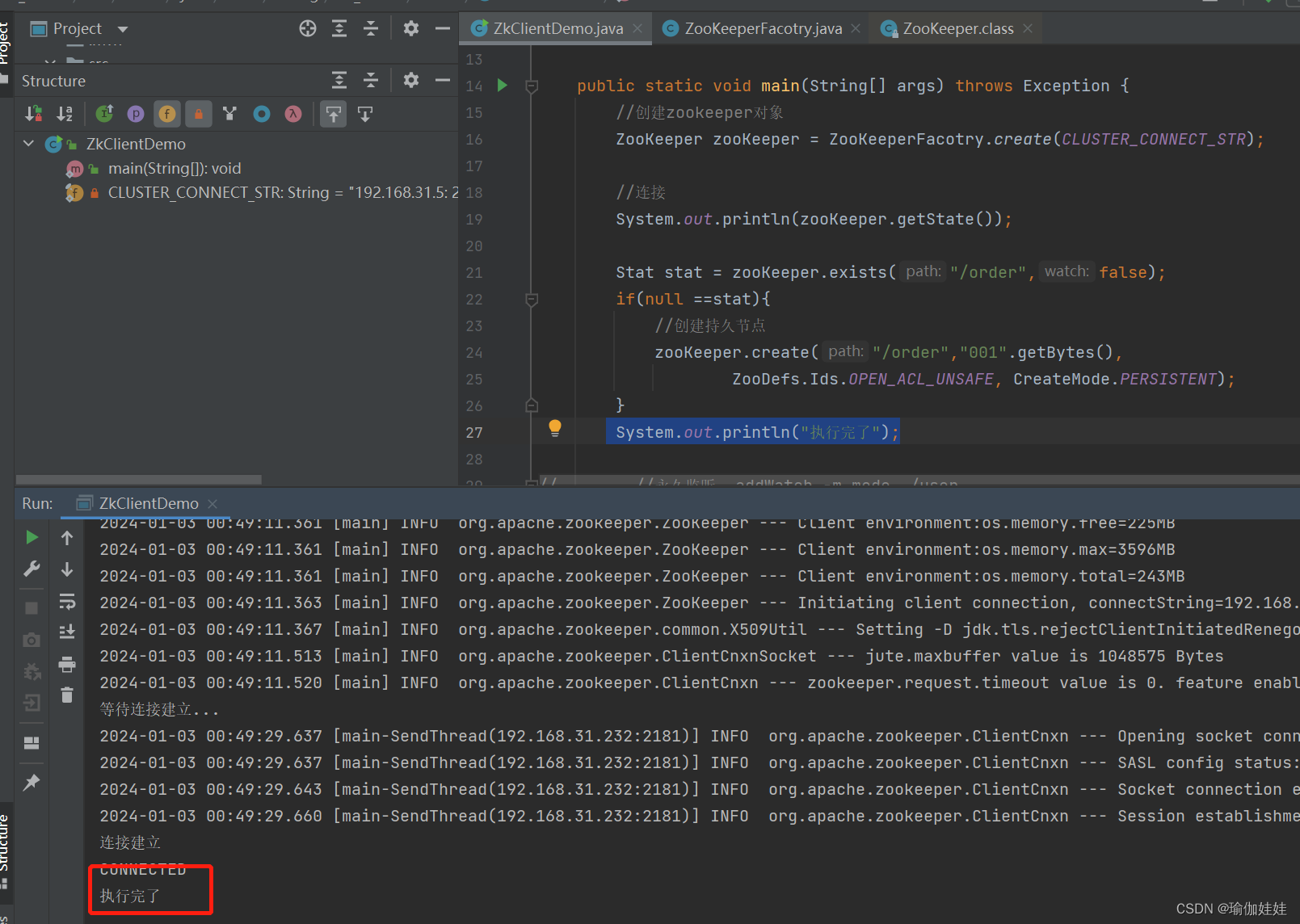
我们在服务器的客户端查看一下数据:
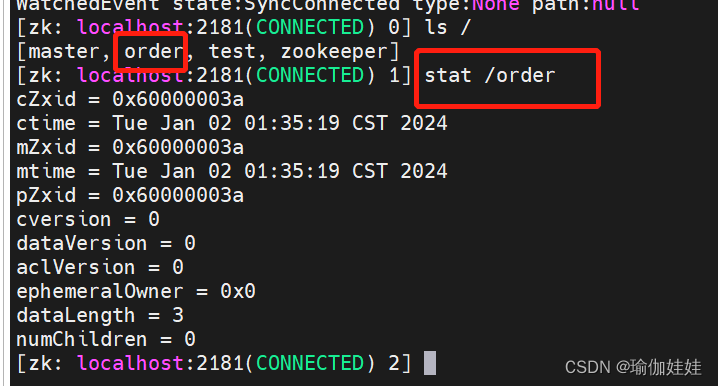
有数据,创建成功了。
1.2.2.2 永久监听节点
代码:
public class zkclientdemo {
private final static string cluster_connect_str="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";
public static void main(string[] args) throws exception {
//创建zookeeper对象
zookeeper zookeeper = zookeeperfacotry.create(cluster_connect_str);
//连接
system.out.println(zookeeper.getstate());
stat stat = zookeeper.exists("/order",false);
//永久监听 addwatch -m mode
zookeeper.addwatch("/order",new watcher() {
@override
public void process(watchedevent event) {
system.out.println(event);
//todo
}
},addwatchmode.persistent);
thread.sleep(integer.max_value);
}启动程序后,在服务器的客户端修改监听的节点。
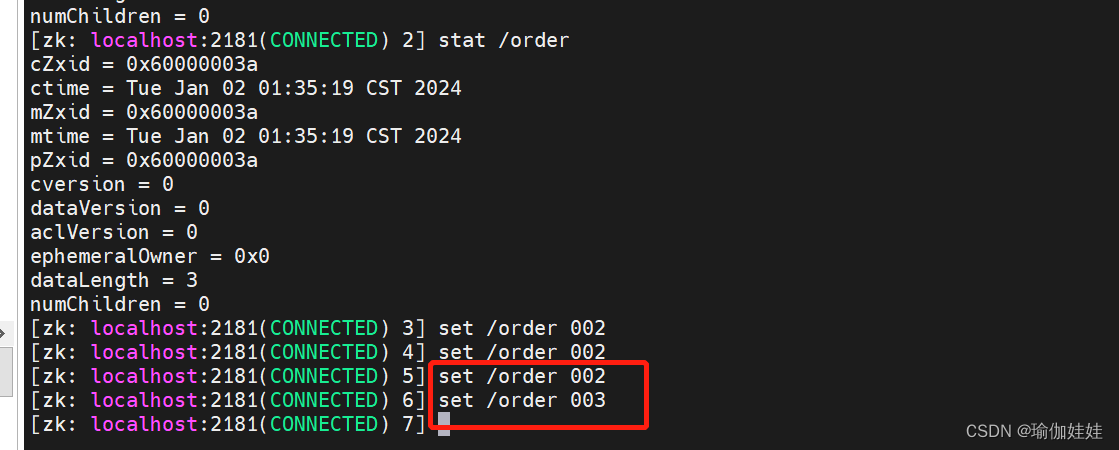 程序监听到 /order这个节点被修改了。
程序监听到 /order这个节点被修改了。
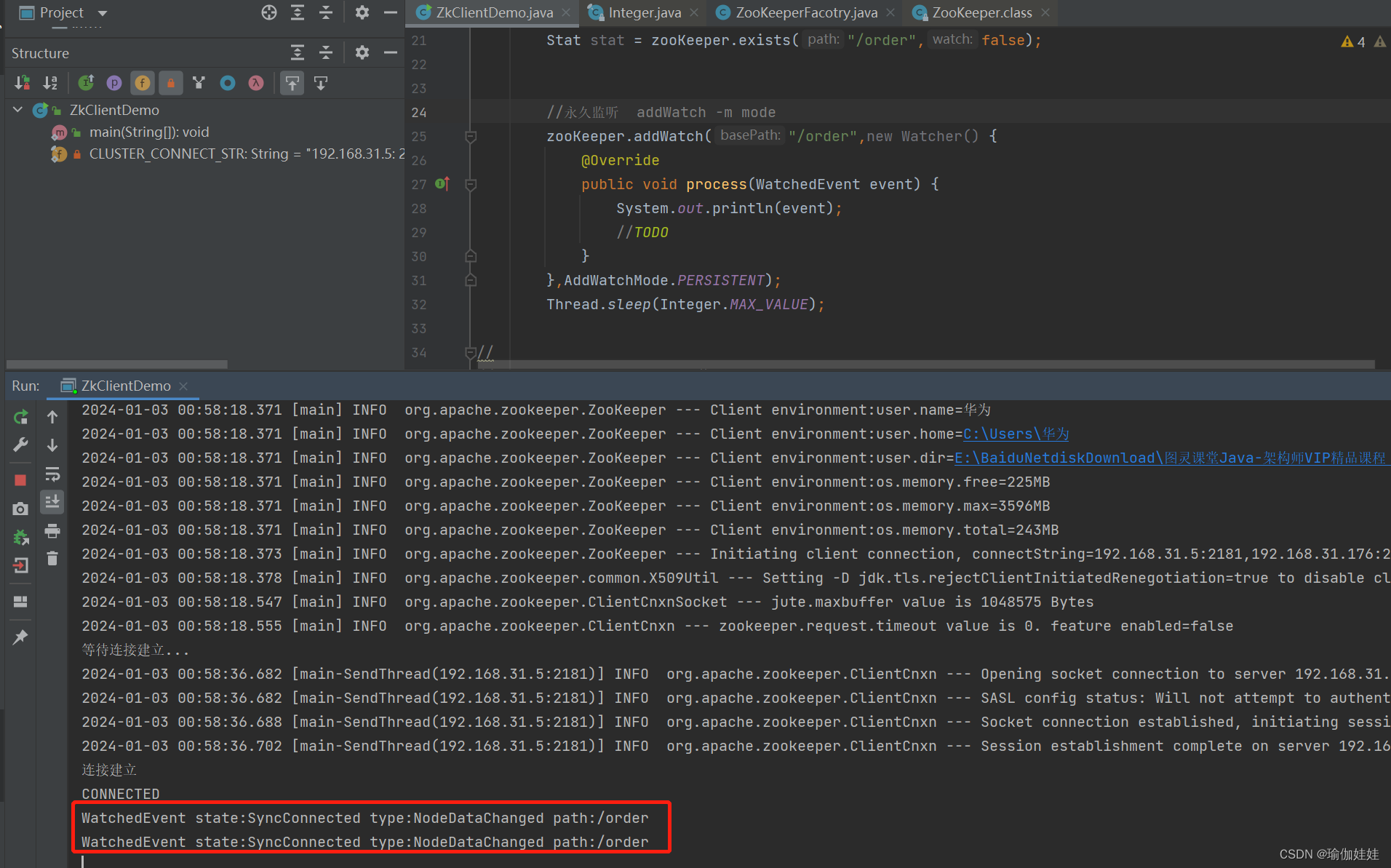
1.2.2.3 根据版本更新
代码:
public class zkclientdemo {
private final static string cluster_connect_str="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";
public static void main(string[] args) throws exception {
//创建zookeeper对象
zookeeper zookeeper = zookeeperfacotry.create(cluster_connect_str);
//连接
system.out.println(zookeeper.getstate());
stat stat = zookeeper.exists("/order",false);
stat = new stat();
byte[] data = zookeeper.getdata("/order", false, stat);
system.out.println(" data: "+new string(data));
// -1: 无条件更新
//zookeeper.setdata("/user", "third".getbytes(), -1);
// 带版本条件更新
int version = stat.getversion();
zookeeper.setdata("/order", "updatebyversion".getbytes(), version);
thread.sleep(integer.max_value);
}
}第一次打印的数据结果:
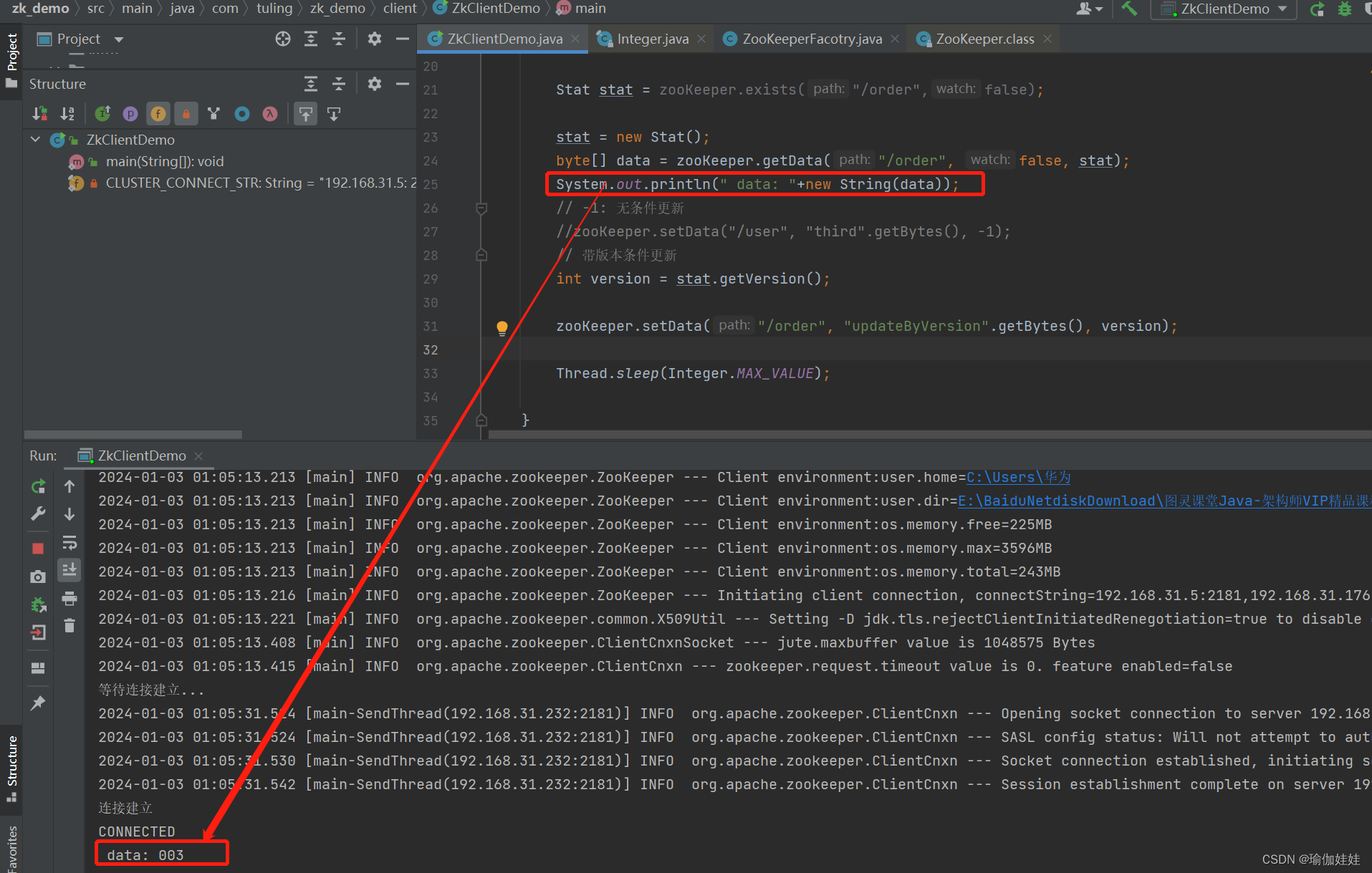
待程序执行完,在服务器客户端查询的结果:更具版本更新数据成功了。

对于zookeeper java原生客户端的使用,就简单介绍这么多,不在过多赘述,只是为了是让大家感受一下,原生客户端的使用。实际开发中并不推荐使用zk的原生客户端,过于笨重。
2. 开源的第三方客户端:curator
2.1 简介
官网:https://curator.apache.org/
curator是netflix公司开源的一套zookeeper客户端框架,和zkclient一样它解决了非常底层的细节开发工作,包括连接、重连、反复注册watcher的问题以及nodeexistsexception异常等。
curator是apache基金会的顶级项目之一,curator具有更加完善的文档,另外还提供了一套易用性和可读性更强的fluent风格的客户端api框架。
curator还为zookeeper客户端框架提供了一些比较普遍的、开箱即用的、分布式开发用的解决方案,例如recipe、共享锁服务、master选举机制和分布式计算器等,帮助开发者避免了“重复造轮子”的无效开发工作。
在实际的开发场景中,使用curator客户端就足以应付日常的zookeeper集群操作的需求。
2.2 基础使用
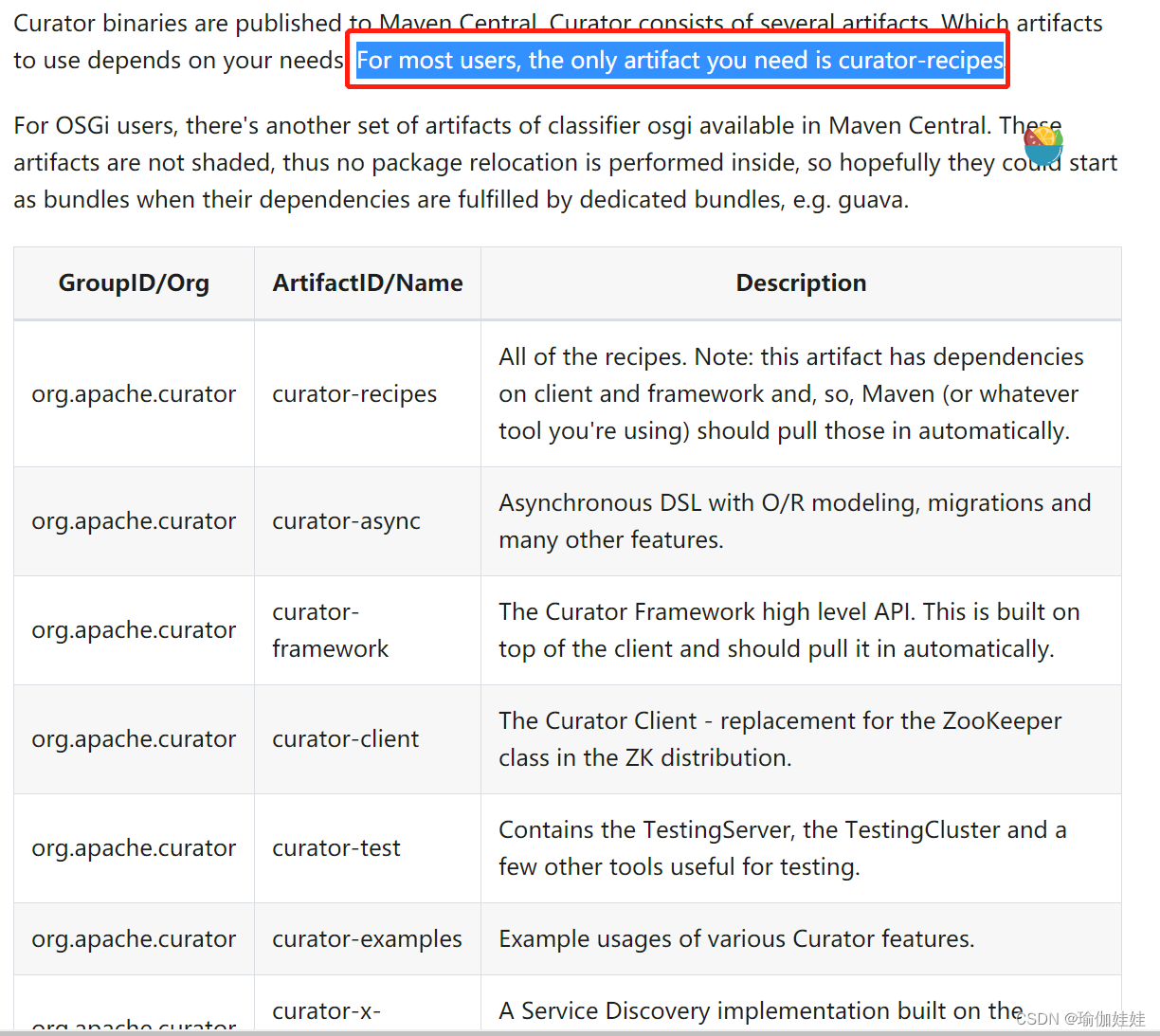
使用curator我们需要引入依赖,官网上介绍到,curator有多个 artifacts,使用者根据自己的需求,进行引入依赖。对于大多数使用者来说,引入curator-recipes就足够了。
2.2.1 连接zk集群
连接zk集群,我们需要创建一个客户端示例,然后启动客户端。创建客户端实例的方法有两种。
2.2.2 节点操作
描述一个节点要包括节点的类型,即临时节点还是持久节点、节点的数据信息、节点是否是有序节点等属性和性质。接下来,我们逐一看一下利用curator如何操作一个节点的。
2.2.2.1 创建节点
那么如何用curator来创建一个节点呢?
在 curator 中,可以使用 create 函数创建数据节点,并通过 withmode 函数指定节点类型(持久化节点,临时节点,顺序节点,临时顺序节点,持久化顺序节点等),默认是持久化节点,之后调用forpath 函数来指定节点的路径和数据信息。
2.2.2.2 更新节点
那么我们如何更新一个节点呢?
我们通过客户端实例的 setdata() 方法更新 zookeeper 服务上的数据节点,在setdata 方法的后边,通过 forpath 函数来指定更新的数据节点路径以及要更新的数据。
2.2.2.3 查看节点
那么我们如何查看一个节点呢?
我们通过客户端实例的 getdata() 方法更新 zookeeper 服务上的数据节点,在getdata 方法的后边,通过 forpath 函数来指定查看的节点路径。
2.2.2.4 删除节点
那么我们如何删除一个节点呢?
我们通过客户端实例的 delete() 方法删除 zookeeper 服务上的数据节点,在delete方法的后边,通过 forpath 函数来指定删除的节点路径。
2.2.2.4 监听
curator caches:curator 引入了 cache 来实现对 zookeeper 服务端事件监听,cache 事件监听可以理解为一个本地缓存视图与远程 zookeeper 视图的对比过程。cache 提供了反复注册的功能。cache 分为两类注册类型:节点监听和子节点监听。
2.2.2.4.1 监听节点数据变化
2.2.2.4.2 监听一级子节点
2.2.2.4.3 监听所有子节点
3. 总结
以上是对zookeeper java客户端对zookeeper的基本操作,到此zookeeper java客户端的介绍到此为止,更详细的实践应用,后续会出一些zk常用场景是如何实现的文章。


发表评论