哈希表理论基础
常见的三种哈希结构
数组
set (集合)
map(映射)
set

map
总结一下,当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法。
但是哈希法也是牺牲了空间换取了时间,因为我们要使用额外的数组,set或者是map来存放数据,才能实现快速的查找。
如果在做面试题目的时候遇到需要判断一个元素是否出现过的场景也应该第一时间想到哈希法!
242.有效的字母异位词
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
注意:若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词。
示例 1:
输入: s = “anagram”, t = “nagaram”
输出: true
示例 2:
输入: s = “rat”, t = “car”
输出: false
思路:因为做过一次还是有印象,但是还是不够熟练,看了卡哥的解析文档,又重新写了一遍。
public boolean isanagram(string s, string t) {
//创建一个长度为26的数组
int[] records = new int[26];
//将s中存在的元素数量存入数组
for(int i=0;i<s.length();i++){
records[s.charat(i)-'a']++;
}
//若t中存在相同的元素则数量--
for(int j=0;j<t.length();j++){
records[t.charat(j)-'a']--;
}
//数组中元素都为0则 为字母异位词
for(int record:records){
if(record!=0){
return false;
}
}
return true;
}
349. 两个数组的交集
给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。
示例 1:
输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2]
示例 2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[9,4]
解释:[4,9] 也是可通过的
输出结果中的每个元素一定是唯一的,也就是说输出的结果的去重的, 同时可以不考虑输出结果的顺序
所以使用std::unordered_set的底层实现是哈希表, 使用unordered_set 读写效率是最高的,并不需要对数据进行排序,而且还不要让数据重复,所以选择unordered_set。

使用set–不然数据重复
public int[] intersection(int[] nums1, int[] nums2) {
if(nums1==null||nums1.length==0||nums2==null||nums2.length==0){
return new int[0];
}
set<integer> set1 = new hashset<>();
set<integer> resset1 = new hashset<>();
for(int i:nums1){
set1.add(i);
}
for(int j : nums2){
if(set1.contains(j)){
resset1.add(j);
}
}
int[] arr = new int[resset1.size()];
int j =0;
for(int i :resset1){
arr[j++]=i;
}
return arr;
}
使用数组:
数组上还是不够熟练,因为数组中有重复元素,所以不能只用一个数组。
public int[] intersection(int[] nums1, int[] nums2) {
if(nums1==null||nums1.length==0||nums2==null||nums2.length==0){
return new int[0];
}
int[] hash1 = new int[1002];
int[] hash2 = new int[1002];
for(int i:nums1){
hash1[i]++;
}
for(int j :nums2){
hash2[j]++;
}
list<integer> reslist = new arraylist<>();
for(int i=0;i<1002;i++){
if(hash1[i]>0&&hash2[i]>0){
reslist.add(i);
}
}
int[] res = new int[reslist.size()];
int index=0;
for(int i : reslist){
res[index++]=i;
}
return res;
}
202. 快乐数
编写一个算法来判断一个数 n 是不是快乐数。
「快乐数」定义为:对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和,然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。如果 可以变为 1,那么这个数就是快乐数。
如果 n 是快乐数就返回 true ;不是,则返回 false 。
示例:
输入:19
输出:true
解释:
1^2 + 9^2 = 82
8^2 + 2^2 = 68
6^2 + 8^2 = 100
1^2 + 0^2 + 0^2 = 1
题目中说了会 无限循环,那么也就是说求和的过程中,sum会重复出现,这对解题很重要!
正如:关于哈希表,你该了解这些! (opens new window)中所说,当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法了。
所以这道题目使用哈希法,来判断这个sum是否重复出现,如果重复了就是return false, 否则一直找到sum为1为止。
判断sum是否重复出现就可以使用unordered_set。
public boolean ishappy(int n) {
set<integer> record = new hashset<>();
while(n!=1 && !record.contains(n)){
record.add(n);
n=getnextnumber(n);
}
return n==1;
}
public int getnextnumber(int n ){
int res = 0;
while(n>0){
int temp = n%10;
res += temp * temp;
n = n/10;
}
return res;
}
1. 两数之和
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。
示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
思路:首先手写暴力通过
public int[] twosum(int[] nums, int target) {
int[] res = new int[2];
for(int i =0;i<nums.length;i++){
for(int j = i+1;j<nums.length;j++){
if(nums[i]+nums[j]==target){
res[0]=i;
res[1]=j;
}
}
}
return res;
}
什么时候使用哈希法,当我们需要查询一个元素是否出现过,或者一个元素是否在集合里的时候,就要第一时间想到哈希法。
再来看一下使用数组和set来做哈希法的局限。
- 数组的大小是受限制的,而且如果元素很少,而哈希值太大会造成内存空间的浪费。
- set是一个集合,里面放的元素只能是一个key,而两数之和这道题目,不仅要判断y是否存在而且还要记录y的下标位置,因为要返回x 和 y的下标。所以set 也不能用。
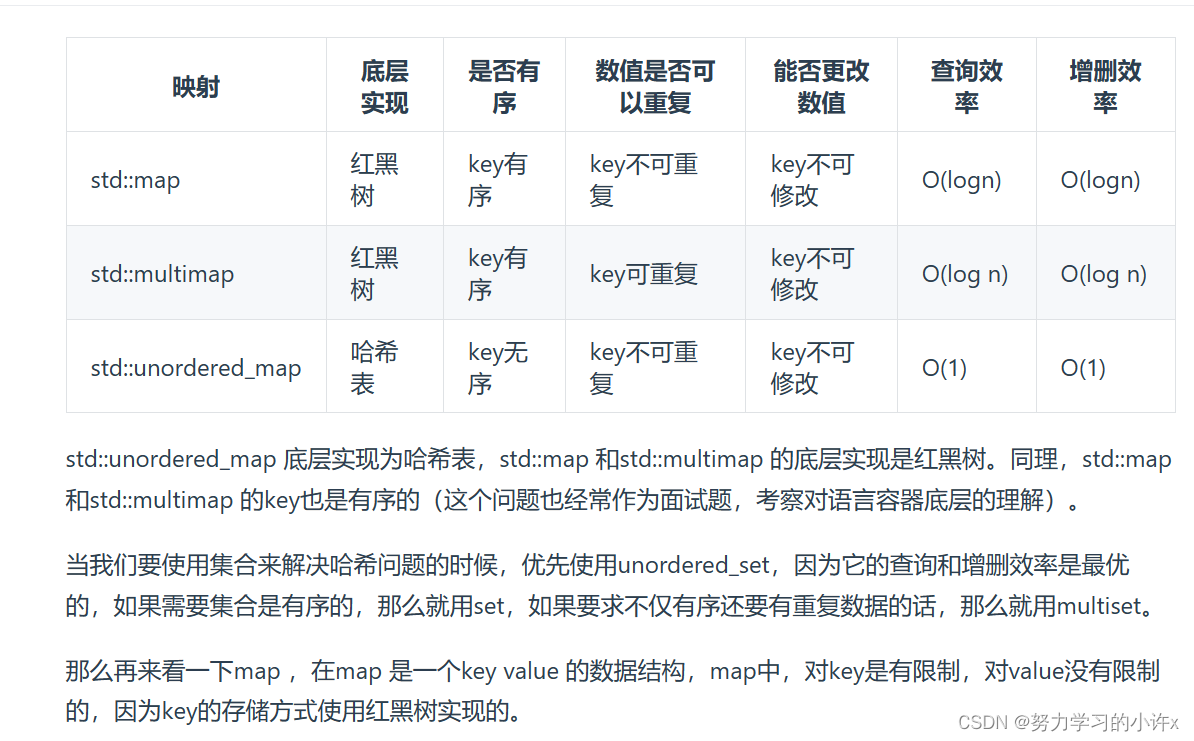
std::unordered_map 底层实现为哈希表,std::map 和std::multimap 的底层实现是红黑树。
同理,std::map 和std::multimap 的key也是有序的(这个问题也经常作为面试题,考察对语言容器底层的理解)
这道题目中并不需要key有序,选择std::unordered_map 效率更高!
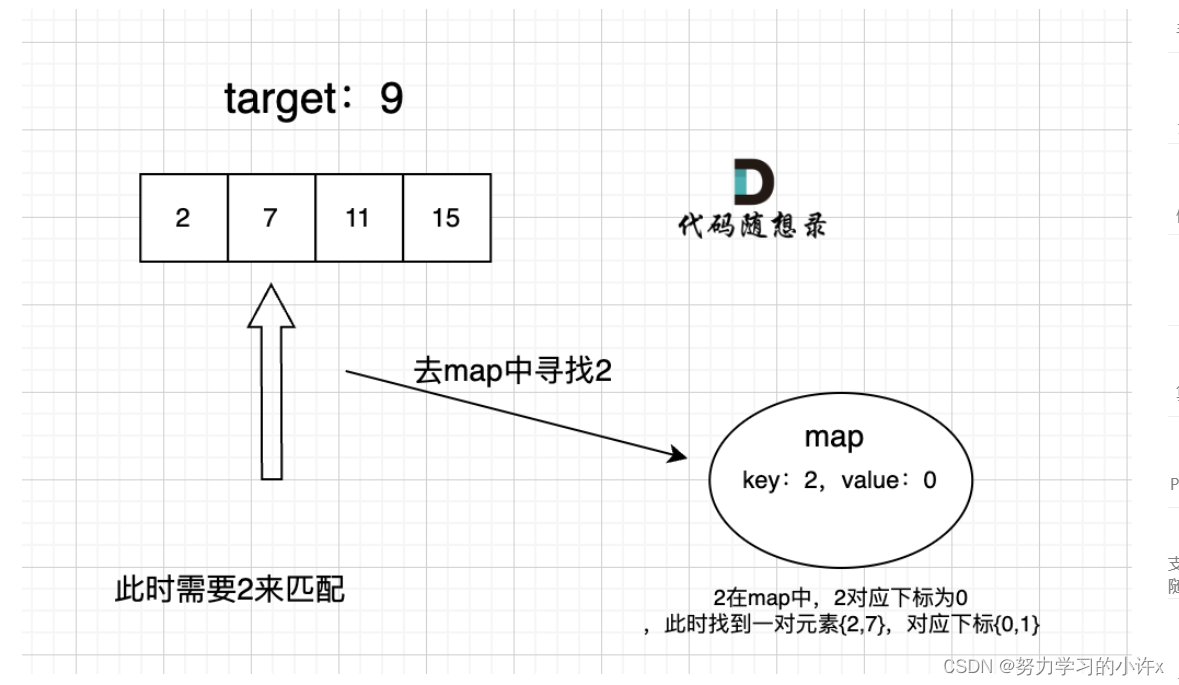
map目的用来存放我们访问过的元素,因为遍历数组的时候,需要记录我们之前遍历过哪些元素和对应的下标,这样才能找到与当前元素相匹配的(也就是相加等于target)
接下来是map中key和value分别表示什么。
这道题 我们需要 给出一个元素,判断这个元素是否出现过,如果出现过,返回这个元素的下标。
那么判断元素是否出现,这个元素就要作为key,所以数组中的元素作为key,有key对应的就是value,value用来存下标。
所以 map中的存储结构为 {key:数据元素,value:数组元素对应的下标}。
在遍历数组的时候,只需要向map去查询是否有和目前遍历元素匹配的数值,如果有,就找到的匹配对,如果没有,就把目前遍历的元素放进map中,因为map存放的就是我们访问过的元素。

本题其实有四个重点:
- 为什么会想到用哈希表:当需要查询一个元素是否出现过,或者一个元素是否在集合里的时候,就要第一时间想到哈希法
- 哈希表为什么用map:不仅要知道元素有没有遍历过,还要知道这个元素对应的下标,需要使用 key value结构来存放,key来存元素,value来存下标,那么使用map正合适。
- 本题map是用来存什么的:map目的用来存放我们访问过的元素,因为遍历数组的时候,需要记录我们之前遍历过哪些元素和对应的下标,这样才能找到与当前元素相匹配的(也就是相加等于target)
- map中的key和value用来存什么的:那么判断元素是否出现,这个元素就要作为key,所以数组中的元素作为key,有key对应的就是value,value用来存下标。
所以 map中的存储结构为 {key:数据元素,value:数组元素对应的下标}。
在遍历数组的时候,只需要向map去查询是否有和目前遍历元素匹配的数值,如果有,就找到的匹配对,如果没有,就把目前遍历的元素放进map中,因为map存放的就是我们访问过的元素。
public int[] twosum(int[] nums, int target) {
int[] res = new int[2];
if(nums==null || nums.length==0){
return res;
}
map<integer,integer> map = new hashmap<>();
for(int i =0;i<nums.length;i++){
int temp = target - nums[i];
if(map.containskey(temp)){
res[1]=i;
res[0]=map.get(temp);
}
// <元素,下标>
map.put(nums[i],i);
}
return res;
}
快乐数、两数相加都不太熟悉,要再做一次!


![[动态规划]第一章](https://images.3wcode.com/3wcode/20240802/s_0_202408022259304284.png)


发表评论