【数学建模】评价类模型:优劣解距离法
目录
1:前言
-
层次分析法(ahp)的局限性:决策层不能多,否则导致判断矩阵和一致性矩阵差异很大;若题中给出明确的数据,层次分析法显得主观臆断

-
三点解释:
-
比较的对象一般要远大于两个
-
比较的指标也往往不只是一个方面的,例如成绩、工时数、课外竞赛得分
-
有很多指标不存在理论上的最大值和最小值,例如衡量经济增长水平的指标:gdp增速
-
2:算法
1. 将原始矩阵正向化(统一为极大型)
-
常见的四种指标:
-
极大型(成绩、gdp增速)
-
极小型(费用、坏品率、污染程度)
-
中间型(越接近某个值越好)[水质评估时的ph值]
-
区间型指标(落在某个区间最好)[体温]
-
-
极小型指标转化为极大型指标:
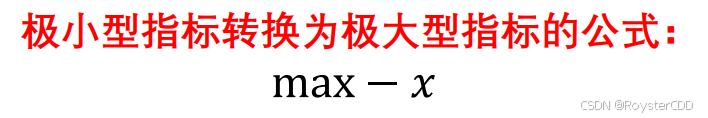
-
设 \{xi\} 是一组中间型指标序列,中间型指标转化为极大型指标:
 -
-
-
设 \{xi\} 是一组中间型指标序列,且最佳的区间为 [a,b],区间型指标转化为极大型指标:

2. 正向矩阵标准化(消除量纲)
-
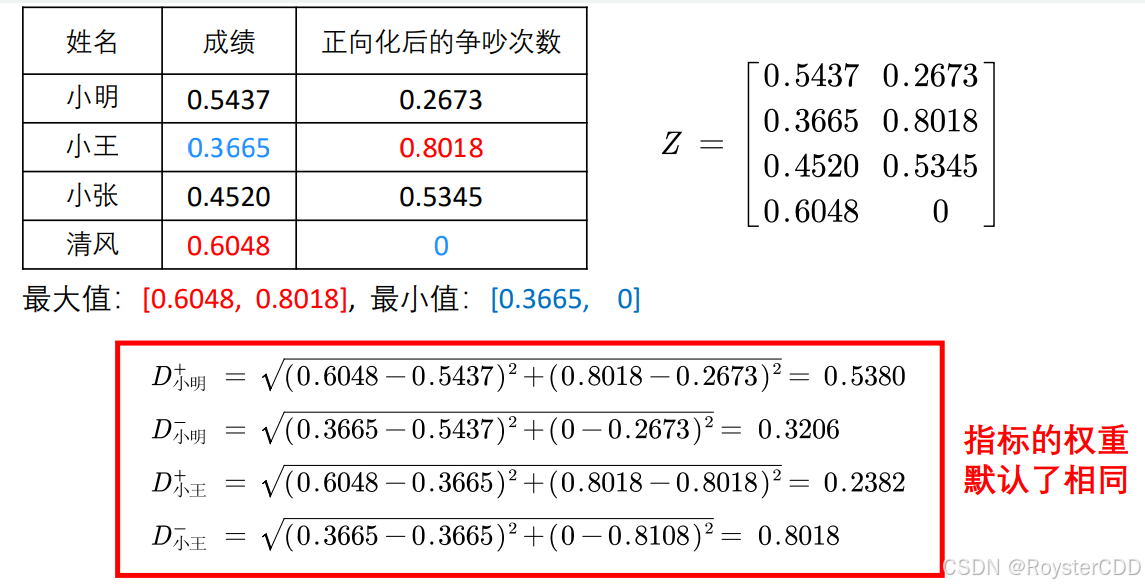
指标正向化后,不同指标间还存在不同的量纲,因此还需要标准化处理
x=[89,1;60,3;74,2;99,0] [n,m]=size(x)%n是x的行数,m是x的列数 x./repmat(sum(x.*x).^0.5,n,1)%所有元素除以矩阵中所有元素的平方和开根
3. 计算得分并归一化
-
\frac{x-x_{min}}{x_{max}-x_{min}}=\frac{x-x_{min}}{(x_{max}-x)+(x-x_{min})}=\frac{d_i^-}{d_i^+-d_i^-}

3:例题
-
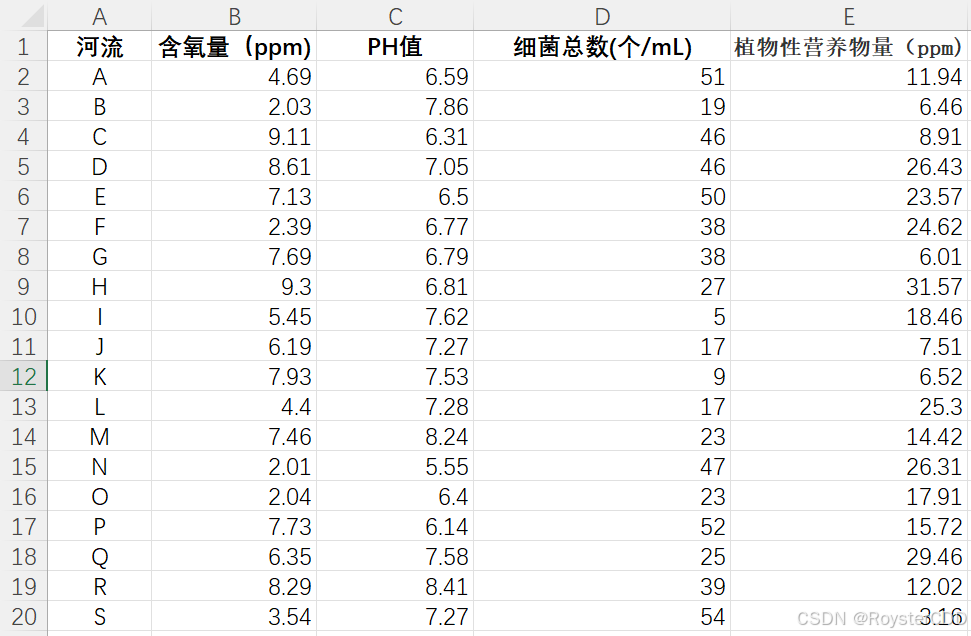
评价下表中 20 条河流的水质情况
-
保存数据:将 excel 中的数据导入到 matlab,并保存为 .mat 文件,以后直接 load
-
在工作区中 ctrl+n 新建一个变量,然后双击点开,把我们要的 excel 中的数据复制粘贴进去,并修改命名
-
右键→另存为 (.mat 为后缀的数据)
-
代码:load xxx.mat
-
%% 第一步:载入数据
clear;clc
load data_water_quality.mat
%% 第二步:对矩阵进行正向化处理
[n,m] = size(x); %将x的行和列的数量分别赋给n和m
disp(['共有' num2str(n) '个评价对象, ' num2str(m) '个评价指标'])
decide = input(['是否对评价指标进行正向化处理:>']);
if decide == 1
position = input('请输入需要正向化处理的指标所在的列:>'); %[2,3,4]
type = input('请输入需要处理的这些列的指标类型:>'); %[2,1,3](1 极小型,2 中间型,3 区间型)
for i = 1 : size(position,2) %size(position,2)得到postion的列数(即指标的个数,最大循环次数)
x(:,position(i)) = a02_positivization(x(:,position(i)),type(i),position(i));
end
disp('正向化后的矩阵 x = ')
disp(x)
end
%% 第三步:对正向化后的矩阵进行标准化
z = x ./ repmat(sum(x.*x) .^ 0.5, n, 1);
disp('标准化后的矩阵为 z = ')
disp(z)
%% 第四步:计算与最大值的距离和最小值的距离,并算出得分
d_max = sum([(z - repmat(max(z),n,1)) .^ 2 ],2) .^ 0.5; % d+ 与最大值的距离向量
d_min = sum([(z - repmat(min(z),n,1)) .^ 2 ],2) .^ 0.5; % d- 与最小值的距离向量
s = d_min ./ (d_max+d_min); %得到未归一化下的得分
disp('最后的得分为:')
stand_s = s / sum(s); %对s进行归一化处理得到最终结果
[sort_result,index] = sort(stand_s ,'descend') % 将sorted_s降序处理,且将其降序排序后下标保存到index
4:拓展
-
基于熵权法对topsis模型的修正(写学术论文别用,比赛可用)
-
依据的原理:指标的变异程度(方差)小,所反映的信息量也越少,其对应的权值也应该越低。(客观=数据本身就可以告诉我们权重)
-
原理解释:

-
计算步骤:
-
判断输入的矩阵是否存在负数,若存在负数重新标准化到非负区间(即对topsis模型中的矩阵正向化、标准化)
-
计算第j项指标下第i个样本的比重,并将其看作相对熵计算中用到的概率
-
计算每个指标的信息熵,并计算信息效用值,并归一化得到每个指标的熵权
-
%% 第一步:将数据导入工作区
%clear;clc
load data_water_quality.mat
%% 第二步:矩阵正向化处理
[n,m] = size(x);
disp(['共有' num2str(n) '个评价对象, ' num2str(m) '个评价指标']) %字符串拼接,也可以用strcat来实现效果
judge = input(['这' num2str(m) '个指标是否需要经过正向化处理:>']);%用0或1作为正向化处理的标签
if judge == 1
position = input('输入要正向化处理的指标所在列:>'); %[2,3,4]
type = input('输入所需正向化处理列的指标类型:>');%(1:极小型,2:中间型,3:区间型)
for i = 1 : size(position,2) %用size(...,2)函数得到行向量的列数,即最大循环次数
x(:,position(i)) = a02_positivization(x(:,position(i)),type(i),position(i));
end
disp('正向化后的矩阵 x = ')
disp(x)
end
%% 第三步:对正向化后的矩阵进行标准化处理
z = x ./ repmat(sum(x.*x) .^ 0.5, n, 1); % 向量中每个元素除以每一列的平方和的开根
disp('标准化矩阵 z = ')
disp(z) % 得到标准化矩阵z
%% 第四步:判断是否需要增加权重
judge = input('请输入是否需要增加权重:>');% 0表示否,1表示确定用judge接收
if judge == 1
judge = input('是否采用熵权法:>');% 0表示否,1表示确定用judge接收
if judge == 1
if sum(sum(z<0))>0 % 若原标准化矩阵z中存在负数,需要对x重新标准化
disp('原标准化矩阵z中存在负数,所以需要对x重新标准化')
for i = 1:n % n是矩阵x的行数
for j = 1:m % m是矩阵x的列数
z(i,j) = [x(i,j) - min(x(:,j))] / [max(x(:,j)) - min(x(:,j))]; %topsis算法中的灵魂公式
end
end
disp('x重新进行标准化得到的标准化矩阵z为:>')
disp(z)
end
weight = a02_entropy_weight(z);% 调用外部函数
disp('熵权法确定的权重为:>')
disp(weight)
else
disp(['需依此输入对应指标数个数的权重,一一对应!']);
weight = input(['你需要输入' num2str(m) '个权数' '并以行向量的形式输入这' num2str(m) '个权重:>']);
yes = 0; % 判断输入格式是否正确,需用浮点数比较
while yes == 0
if abs(sum(weight) -1)<0.000001 && size(weight,1) == 1 && size(weight,2) == m % matlab中浮点数的比较
yes =1;
else
weight = input('输入有误,重新键入权重行向量:>');
end
end
end
else
weight = ones(1,m) ./ m ; %如果不需要加权重就默认权重都相同,即都为1/m
end
%% 第四步:计算与最大值的距离和最小值的距离,并算出得分
d_max = sum([(z - repmat(max(z),n,1)) .^ 2 ] .* repmat(weight,n,1) ,2) .^ 0.5; % d+ 与最大值的距离向量
d_min = sum([(z - repmat(min(z),n,1)) .^ 2 ] .* repmat(weight,n,1) ,2) .^ 0.5; % d- 与最小值的距离向量
s = d_min ./ (d_max+d_min); % 得到未归一化下的得分
% 未归一化下的得分放进论文中我反而觉得更妥当一点
[sorted_nostand_s]=sort(s,'descend')
disp('最后的得分为:')
stand_s = s / sum(s) % 对s进行归一化处理得到最终结果
[sorted_s,index] = sort(stand_s ,'descend') %将sorted_s降序处理,且将其降序处理后结果的下标保存至向量index
% index 是最终的排名结果
format long
disp(weight)-
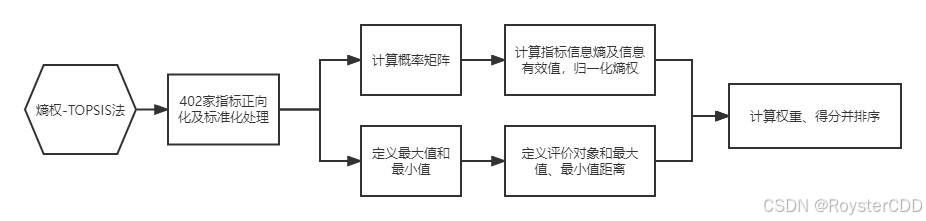
基于熵权-topsis 流程图



发表评论