1、背景
随着深度神经网络的迅速发展,它在图像、文本和语音等领域已经广泛应用。然而,对于同样常见的表格数据,深度神经网络似乎尚未取得其他领域那样的巨大成功。在以kaggle为代表的数据挖掘竞赛中,处理表格数据的任务仍然主要由决策树模型承担,像xgboost和lightgbm这样的提升树模型已经成为了主流选择。

那么为什么人们选择树形模型?主要是因为决策树模型在表格数据处理中具有以下优势:
- 决策流形的边界可以被视为超平面。
- 可以根据决策树的推断过程进行追溯。
- 训练速度较快。
而深度神经网络的优势在于:
- 它可以对表格数据进行编码,从而获得一种能够表征表格数据的方法。
- 可以减少对特征工程的依赖。
- 可以通过在线学习的方式来更新模型。
然而,传统的深度神经网络模型往往会出现过度参数化的问题,在处理表格数据集时表现并不理想。因此,如果能够设计一种模型,既继承了树模型的优点,又兼具深度神经网络的特点,那么这样的模型无疑将成为处理表格数据的一大利器。而论文中介绍的tabnet就巧妙地设计出了这样一种模型。tabnet在保留了深度神经网络的端到端和表征学习特性的基础上,还具有树模型的可解释性和稀疏特征选择的优点。
2、利用dnn构造类决策树
要使深度神经网络(dnn)具有类似于树模型的决策流形,我们首先需要解决一个关键问题:如何构建出与树模型具有相似决策流形的神经网络结构?下图展示了一个简单示例的决策树流形。
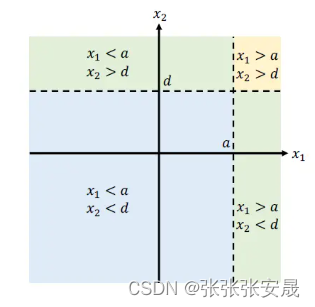
在这个示例中,有两个特征输入:x1和x2。决策树根据阈值a和d将它们分别划分,从而形成了图中所示的决策流形。那么,如何利用神经网络来构建出类似的决策流形呢?该论文提出了一种方法,如下图所示。
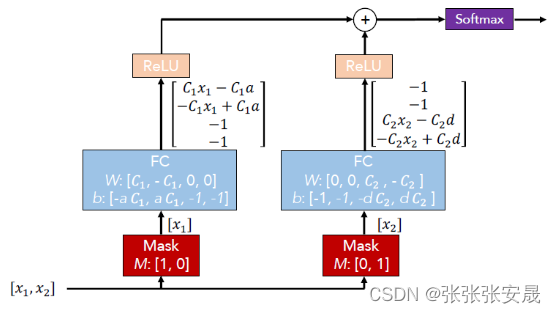
输入是特征向量[x1, x2],首先经过两个mask层单独筛选出x1和x2,然后通过一个专门设定过权重w和偏差b的全连接层,将两个fc层的输出经过relu激活函数相加,最后通过softmax激活函数输出。与决策树的流程对比,我们可以发现这个神经网络的每一层都对应着决策树的相应步骤:
- mask层对应决策树中的特征选择,这一点很容易理解;
- fc层+relu对应阈值判断,通过特定的fc层+relu后,保证输出向量中只有一个正值,其余为0,这对应决策树的条件判断;
- 最后将所有条件判断的结果相加,再通过softmax得到最终输出。
这个神经网络实际上可以被视为一个加性模型(additive model)。它由两个mask+fc+relu组合相加构成,而每个组合实际上就是一个基本决策树。这两棵树分别选择x1和x2作为划分特征,然后输出各自的结果。最后,模型将这两个结果相加作为最终输出。这个输出向量可以理解为一个权重向量,其中每个维度代表某个条件判断对最终决策的影响权重。
因此,可以将这个神经网络视为一个“软”版本的决策树加性模型。
3、encoder架构
上文介绍的神经网络架构比较简单,mask矩阵是人为设置好的,特征计算也只是一个简单的fc层,而tabnet对这些都做了改进,tabnet的encoder结构如下所示。
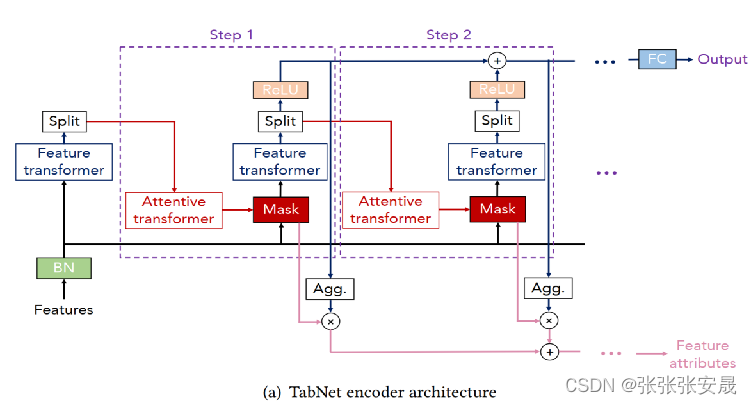
encouder架构两个最重要的部分,attentive transformer和feature transformer分别负责特征选择和特征处理。
3.1、 feature selection
tabnet的特征选择过程主要为每个step学习到一个mask来实现对当前决策步的特征选择。选择哪些特征由决策步的attentive transformer来实现。

attentive transformer学习mask的公式如下:
![m[i]=sparsemax(p[i-1]\cdot h_i(a[i-1]))](https://images.3wcode.com/3wcode/20240802/b_0_202408020512012433.jpg)
其中各个符号的含义如下:
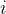 :表示当前step。
:表示当前step。
![a[i-1]](https://images.3wcode.com/3wcode/20240802/b_0_202408020512034945.jpg) :前一个step划分来的特征信息
:前一个step划分来的特征信息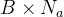 。
。
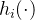 :代表fc+bn层。
:代表fc+bn层。
![p[i-1]](https://images.3wcode.com/3wcode/20240802/b_0_202408020512053758.jpg) :代表prior scales项,通过
:代表prior scales项,通过![p[i]=\prod_{j=1}^{i}(\gamma -m[j])](https://images.3wcode.com/3wcode/20240802/b_0_202408020512062600.jpg) 计算。
计算。
sparsemax:softmax的变体,可以得到更稀疏的输出结果(取值集中在0和1附近,中间值较少)。
整个特征选择的过程可以用张量流动的顺序来进行说明:
- 首先,上一个决策步的feature transformer输出张量被送入split模块。
- split模块对步骤1中的张量进行切分,并得到a[i-1]。
- a[i-1]经过hi层,其中hi层表示一个全连接层(fc层)和一个批量归一化层(bn层)。
- hi层的输出与上一个决策步的先验尺度p[i-1]相乘。
- 然后通过sparsemax生成所需的m[i],从而完成特征选择。
- m[i]更新p[i]。这里p[i]表示过去的决策步中特征的使用情况。当γ=1时,表示强制每个特征只能在一个决策步中出现。p[0]初始化为全1。在自监督学习中,如果某些特征未被使用,可以将其在p[0]中置为0。
- 将m[i]和特征元素相乘,实现当前决策步的特征选择。
- 将选择后的特征输入当前决策步的feature transformer,并开启新的决策步循环。
根据张量流动的过程,我们了解了特征选择的过程是怎样的,那么attentive transformer为什么能实现特征选择呢?
attentive transformer模块包括三个子模块:fc+bn、prior scales和sparsemax。
fc+bn模块的作用是通过全连接层(fc)和批量归一化层(bn)实现特征的线性组合,从而抽取出更高维更抽象的特征。
prior scales模块根据先前的决策步的情况,提供当前决策步在选择特征时的先验知识。通常情况下,如果过去的决策步中使用了更多的特征,那么当前决策步中的权重就会相应减小。因此,这一步可以根据历史出现的情况,调整当前所需的特征的权重。
sparsemax模块的作用是实现特征的稀疏化选择,与softmax不同,sparsemax能够确保每个样本的每个特征的权重都落在[0, 1]的范围内,并且每个样本的所有特征的权重之和为1。这样可以实现实例级别的特征选择。相比之下,softmax通常会在样本的每个特征上分配一个非零的权重,导致所有特征都有一定的影响,而sparsemax能够更加稀疏地选择特征,使得部分特征权重为0,从而实现更加精细的特征选择。
3.2、feature process
经过mask过滤后的特征被送进了feature transformer进行特征处理。处理完成的特征被split模块切分成两部分,一部分用于当前决策步的输出,另一部分则作为下一决策步的输入信息。

feature transformer层由两个部分组成。
前半部分层的参数是共享的,它们是在所有step上共同训练的,作用是提取出特征的共性,这种设计参数更新量更少,学习更加鲁棒。
后半部分则没有共享,在每一个step上是分开训练的作用是提取出各个sep决策中的特征特征,参数独立使得每个step决策中可能具有不同的特征处理能力,特征处理更加有效。
这样做是考虑到对于每一个step,输入的是同样的features(mask层只是屏蔽了一些feature,并没有改变其它feature),因此可以先用同样的层来做特征计算的共性部分,之后再通过不同的层做每一个step的特性部分。另外,可以看到层中用到了残差连接,乘 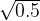 是为了防止模型的方差发生剧烈变化,从而稳定训练过程。
是为了防止模型的方差发生剧烈变化,从而稳定训练过程。
除了上述内容外,作者在文中还提到了"ghost bn"的概念。这个概念旨在提高大批量训练的性能。在这种设置下,除了作用于模型输入特征的第一层bn外,所有的bn层都采用了ghost bn。
ghost bn的提出是为了解决在大批量训练下减少泛化差距的问题。它涉及两个相关参数:虚拟批量大小(virtual batch size)和动量(momentum)。作者观察到,在输入特征方面,低方差平均的好处,因此没有使用ghost bn。
3.3、可解释性输出
结合tabnet的网络结构,以及中间的feature transformer和attentive transformer,可以很明显地看到其和mlp等神经网络结构的差异,在mlp网络中各层内对于输入特征是无区别的进行对待,在tabnet中通过学习得到mask矩阵来体现各个特征在不同step中的重要性,那么tabnet是怎么样来计算特征的重要性呢。
假设对于样本 ,在第个step内,经过feature transformer后,其中的一个输出记为:
,在第个step内,经过feature transformer后,其中的一个输出记为: ![d_{b}[i]](https://images.3wcode.com/3wcode/20240802/b_0_202408020512093798.jpg) ,在上述叙述中,我们知道
,在上述叙述中,我们知道![d[i]](https://images.3wcode.com/3wcode/20240802/b_0_202408020512102953.jpg) 的维度为
的维度为 (不看batchsize维度) ,因此
(不看batchsize维度) ,因此![d_{b}[i]\in r^{n_{d}}](https://images.3wcode.com/3wcode/20240802/b_0_202408020512093798.jpg%5cin%20r%5e%7bn_%7bd%7d%7d) ,同时,最终的输出output是需要经过relu之后才能将多个step内的输出求和之后经过fc映射才能得到, 因此当
,同时,最终的输出output是需要经过relu之后才能将多个step内的输出求和之后经过fc映射才能得到, 因此当 时对于最终的输出是无贡献的,
时对于最终的输出是无贡献的,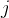 为中的一个维度,因此可以定义如下公式来样本在第个step内的贡献:
为中的一个维度,因此可以定义如下公式来样本在第个step内的贡献:
![\eta _{b}[i]=\sum ^{n_d}_{j=1}relu(d_{b,j}[i])](https://images.3wcode.com/3wcode/20240802/b_0_202408020512183877.jpg)
直观上,当![\eta _{b}[i]](https://images.3wcode.com/3wcode/20240802/b_0_202408020512187234.jpg) 越大,最终对于模型分的贡献也越明显(不是说output就越大,而是可以对output的影响更明显),因此可以作为的权重,用于对step=的mask进行加权,而mask中内的权重参数对应了特征的重要性,因此可以利用如下公式来定义样本的各个特征的重要性值:
越大,最终对于模型分的贡献也越明显(不是说output就越大,而是可以对output的影响更明显),因此可以作为的权重,用于对step=的mask进行加权,而mask中内的权重参数对应了特征的重要性,因此可以利用如下公式来定义样本的各个特征的重要性值:
![m_{agg-b,j}=\sum ^{n}_{i=1}\eta _{b}[i]\cdot m_{b,j}[i]](https://images.3wcode.com/3wcode/20240802/b_0_202408020512224358.jpg)
如果需要得到归一化的特征的重要性值(除于所有特征的重要性之和),可以对上述公式进行改造为:
![m_{agg-b,j}=\frac{\sum ^{n}_{i=1}\eta _{b}[i]\cdot m_{b,j}[i]}{\sum ^{d}_{j=1}\sum ^{n}_{i=1}\eta _{b}[i]\cdot m_{b,j}[i]}](https://images.3wcode.com/3wcode/20240802/b_0_202408020512236459.jpg)
4、decoder架构
文中还提出了一个decoder架构来重构encoder所学习到的特征,decoder同样由决策步构成,每个决策步为feature transformer加fc层。最终所有的输出相加得到最终重建的特征。
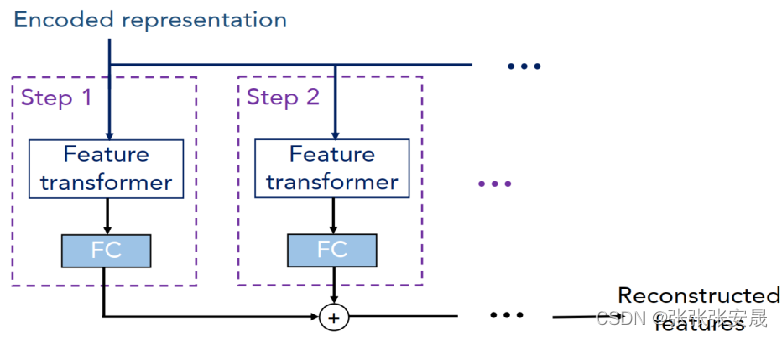
这里的encoded representation就是encoder中没有经过fc层的加和向量,将它作为decoder的输入,decoder同样利用了feature transformer层,只不过这次的目的是将representation向量重构为feature,然后类似地经过若干个step的加和,得到最后的重构feature。
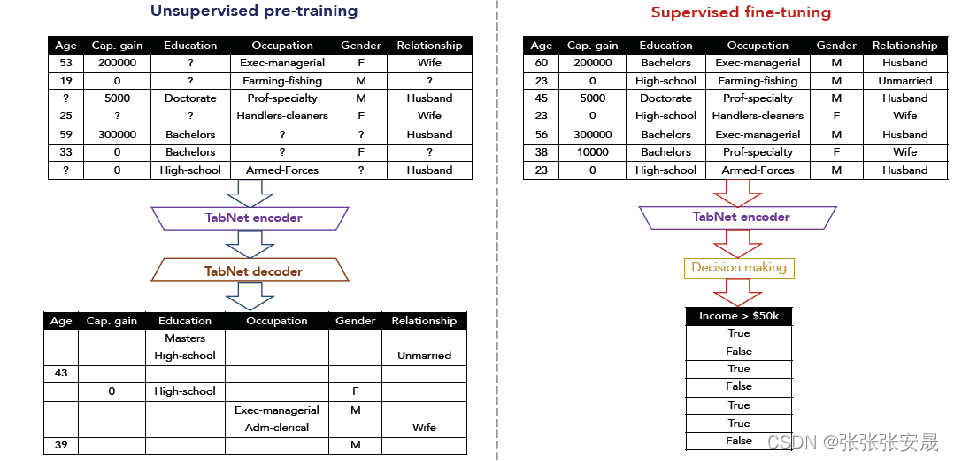
自监督的目标是随机丢掉部分样本的部分特征,并且对他们进行预测。自监督学习是一种无监督学习的变体,其核心思想是通过利用数据自身的结构来进行学习。其基本思想是先人为地对数据进行一定的变换或者处理,然后通过模型来预测这些变换或者处理的结果。在自监督学习中,常见的一种方式是通过掩盖(mask)或者隐藏数据中的一部分信息,然后要求模型去预测这些被隐藏的信息。
通过这样的方式,模型被迫学习数据中的内在结构和规律,从而得到一种对数据进行编码或者压缩的方式。这种编码或者压缩的方式通常能够捕捉到数据的关键特征,从而能够在后续的任务中取得较好的效果。例如,在图像领域,经过自监督学习得到的编码模型可以用于图像分类、目标检测等任务;在自然语言处理领域,经过自监督学习得到的编码模型可以用于语言建模、文本分类等任务。
5、实验
为了证明tabnet确实具有上文中提到的种种优点,这篇文章在不同的数据集上进行了各种类型的实验,这里只介绍一部分,其它实验以及具体实验细节可以看论文原文,写得也很详细。
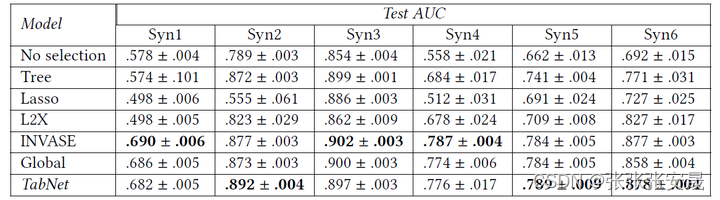
1、人工构建数据集
第一个实验考察的是tabnet能够根据不同样本来选择相应特征的能力,用的是6个人工构建的数据集syn1-6,它们的feature大多是无用的,只有一小部分关键feature是与label相关的。对于syn1-3,这些关键feature对数据集上的所有样本都是一样的,例如对于syn2数据集,是关键feature,因此只需要全局的特征选择方法就可以得到最优解;而syn4-6则更困难一些,样本的关键feature并不相同,它们取决于另外一个指示feature(indicator),例如对于syn4数据集,是指示feature,的取值,决定了和哪一组是关键feature,显然,对于这样的数据集,简单的全局特征选择并不是最优的。
下表展示的是tabnet与一些baseline模型的在测试集上的auc均值+标准差,可以看出tabnet表现不错,在syn4-6数据集上,相较于全局特征选择方法(global)有所改善
2、真实数据集
forest cover type:这个数据集是一个分类任务——根据cartographic变量来对森林覆盖类型进行分类,实验的baseline采用了如xgboost等目前主流的树模型、可以自动构造高阶特征的autoint、以及automl tables这种用了神经网络结构搜索 (neural architecture search)的强力模型(node hours的数量反映了模型的复杂性),对比结果如下:

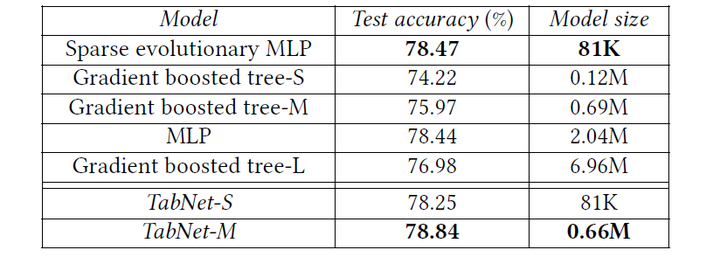
higgs boson:这是一个物理领域的数据集,任务是将产生希格斯玻色子的信号与背景信号分辨开来,由于这个数据集很大,因此dnn比树模型的表现更好,下面是对比结果,其中sparse evolutionary mlp应用了目前最好的evolutionary sparsification算法,能够有效减小原始mlp模型的大小,不过可以看出,和它大小相近的tabnet-s的性能也只是稍弱一点,这说明轻量级的tabnet表现依旧很好。
6、python实现
在代码实现上,调用了pytorch的tabnet实现,其中所用数据集为forest cover type数据集。tabnet参数设置参考论文的部分参数设置,因为pytorch版本封装的太完整了,魔改不是很方便。如果想了解清晰的实现,可以去看看谷歌实验室的源码和keras版的实现。
import pandas as pd
from pytorch_tabnet.tab_model import tabnetclassifier
from sklearn.metrics import accuracy_score
import xgboost as xgb
import lightgbm as lgb
import catboost as cb
import torch
train_df = pd.read_csv("./data/covertype/train.csv")
val_df = pd.read_csv("./data/covertype/val.csv")
test_df = pd.read_csv("./data/covertype/test.csv")
x_train, y_train = train_df.iloc[:, :-1], train_df.iloc[:, -1]-1
x_val, y_val = val_df.iloc[:, :-1], val_df.iloc[:, -1]-1
x_test, y_test = test_df.iloc[:, :-1], test_df.iloc[:, -1]-1
xgb_clf = xgb.xgbclassifier()
xgb_clf.fit(x_train, y_train)
xgb_y_pred = xgb_clf.predict(x_test)
xgb_test_accuracy = accuracy_score(y_test, xgb_y_pred)
print("xgboost test accuracy:", xgb_test_accuracy)
lgb_clf = lgb.lgbmclassifier()
lgb_clf.fit(x_train, y_train)
lgb_y_pred = lgb_clf.predict(x_test)
lgb_test_accuracy = accuracy_score(y_test, lgb_y_pred)
print("lightgbm test accuracy:", lgb_test_accuracy)
cb_clf = cb.catboostclassifier()
cb_clf.fit(x_train, y_train)
cb_y_pred = cb_clf.predict(x_test)
cb_test_accuracy = accuracy_score(y_test, cb_y_pred)
print("catboost test accuracy:", cb_test_accuracy)
tabnet_params = dict(
n_d = 16, # 可以理解为用来决定输出的隐藏层神经元个数。n_d越大,拟合能力越强,也容易过拟合
n_a = 16, # 可以理解为用来决定下一决策步特征选择的隐藏层神经元个数
n_steps = 4, # 决策步的个数。可理解为决策树中分裂结点的次数
gamma = 1.5, # 决定历史所用特征在当前决策步的特征选择阶段的权重,gamma=1时,表示每个特征在所有决策步中至多仅出现1次
lambda_sparse = 1e-6, # 稀疏正则项权重,用来对特征选择阶段的特征稀疏性添加约束,越大则特征选择越稀疏
optimizer_fn = torch.optim.adam,
optimizer_params = dict(lr = 1e-2, weight_decay = 1e-5),
momentum = 0.95,
mask_type = "entmax",
seed = 0
)
clf = tabnetclassifier()
clf.fit(
x_train.values, y_train.values,
eval_set=[(x_val.values, y_val.values)],
eval_name=['val'],
eval_metric=['accuracy'],
max_epochs=500,
patience=50,
batch_size=4096,
virtual_batch_size=1024,
)
tabnet_y_pred = clf.predict(x_test.values)
tabnet_test_accuracy = accuracy_score(y_test.values, tabnet_y_pred)
print("tabnet test accuracy:", tabnet_test_accuracy)
with open("model_evaluations.txt", "a") as file:
file.write("xgboost test accuracy: {}\n".format(xgb_test_accuracy))
file.write("lightgbm test accuracy: {}\n".format(lgb_test_accuracy))
file.write("catboost test accuracy: {}\n".format(cb_test_accuracy))
file.write("tabnet test accuracy: {}\n".format(tabnet_test_accuracy))
file.write("\n")参考文章

发表评论