1、常见dsl代码整理
| 分类 | 格式 | 含义 | 示例 |
|---|---|---|---|
| api/方法 | select | 查询字段 | select('id1', 'id2') |
| where | 对数据过滤 | where('avg_score>3') | |
| groupby | 对数据分组 | groupby('userid') | |
| orderby | 对数据排序 | orderby('cnt', ascending=false) | |
| limit | 取前几条数据 | orderby('cnt', ascending=false).limit(1) | |
| agg | 聚合操作,里面可以写多个聚合表达式 | agg(f.round(f.avg('score'), 2).alias('avg_score')) | |
| show | 打印数据 | init_df.show() | |
| printschema | 打印数据的schema信息,也就是元数据信息 | init_df.printschema() | |
| alias | 对字段取别名 | f.count('movieid').alias('cnt') | |
| join | 关联2个dataframe | etl_df.join(avg_score_dsl_df, 'movieid') | |
| withcolumn | 基于目前的数据产生一个新列 | init_df.withcolumn('word',f.explode(f.split('value', ' '))) | |
| dropduplicates | 删除重复数据 | init_df.dropduplicates(subset=["id","name"]) | |
| dropna | 删除缺失值 | init_df.dropna(thresh=2,subset=["name","age","address"]) | |
| fillna | 替换缺失值 | init_df.fillna(value={"id":111,"name":"未知姓名","age":100,"address":"北京"}) | |
| first | 取dataframe中的第一行数据 | ||
| over | 创建一个窗口列 | ||
| 窗口 | partitionby | 对数据分区 | |
| orderby | 对数据排序 | orderby(f.desc('pv')) | |
| 函数 | row_number | 行号。从1开始编号 | |
| desc | 降序排序 | ||
| avg | 计算均值 | ||
| count | 计数 | ||
| round | 保留小数位 | ||
| col | 将字段包装成column对象,一般用于对新列的包装 | ||
1- 什么使用使用select(),什么时候使用groupby()+agg()/select()实现聚合?:如果不需要对数据分组,那么可以直接使用select()实现聚合;如果有分组操作,需要使用groupby()+agg()/select(),推荐使用agg() 2- first(): 如果某个dataframe中只有一行数据,并且不使用join来对比数据,那么一般需要使用first()明确指定和第一行进行比较 3- f.col(): 对于在计算过程中临时产生的字段,需要使用f.col()封装成column对象,然后去使用
-
api/方法:是由dataframe来调用
-
函数:需要先通过import pyspark.sql.functions as f导入,使用f调用。spark sql内置提供的函数spark sql, built-in functions
-
窗口:需要先通过from pyspark.sql import window导入
2、电影分析案例
需求说明:
数据集的介绍:
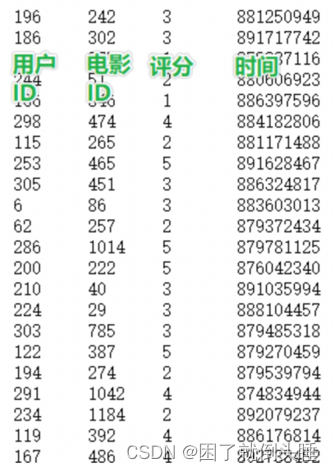
数据说明 : userid,movieid,score,datestr
字段的分隔符号为: \t
需求分析:
-
需求一: 查询用户平均分
-
需求二: 查询每部电影的平均分
-
需求三: 查询大于平均分的电影的数量
-
需求四: 查询高分电影中(电影平均分大于3)打分次数最多的用户, 并且求出此人所有的打分记录中, 打的平均分是多少
-
需求五: 查询每个用户的平均打分, 最低打分, 最高打分(课后作业)
-
需求六: 查询被评分超过100次的电影的平均分 排名 top10(课后作业)
一三四需求实现代码:
# 导包
import os
from pyspark.sql import sparksession,functions as f
# 绑定指定的python解释器
os.environ['spark_home'] = '/export/server/spark'
os.environ['pyspark_python'] = '/root/anaconda3/bin/python3'
os.environ['pyspark_driver_python'] = '/root/anaconda3/bin/python3'
def demo1_get_user_avg_score():
# 方式1: sql方式
spark.sql(
'select userid,round(avg(score),3) as user_avg_score from movie group by userid'
).show()
# 方式2: dsl方式
etldf.groupby('userid').agg(
f.round(f.avg('score'), 3).alias('user_avg_score')
).show()
def demo2_get_lag_avg_movie_cnt():
# 方式1: sql
spark.sql(
"""
select count(1) as cnt from (
select movieid,avg(score) as movie_avg_score from movie group by movieid
having movie_avg_score > (select avg(score) as all_avg_score from movie)
) t
"""
).show()
# 方式2: dsl
# col():把临时结果作为新列使用 first():取第一个值
etldf.groupby('movieid').agg(
f.avg('score').alias('movie_avg_score')
).where(
f.col('movie_avg_score') > etldf.select(f.avg('score').alias('all_avg_score')).first()['all_avg_score']
).agg(
f.count('movieid').alias('cnt')
).show()
def demo3_get_top1_user_avg_sql():
# 方式1: sql
# ①先查询高分电影:
spark.sql(
"select movieid,avg(score) as movie_avg_score from movie group by movieid having movie_avg_score > 3"
).createtempview('hight_score_tb')
# ②再求打分次数最多的用户(先不考虑并列,只取最大1个)
spark.sql(
"select userid,count(1) as cnt from hight_score_tb h join movie m on h.movieid = m.movieid group by userid order by cnt desc limit 1"
).createtempview('top1_user_tb')
# ③最后求此人所有打分的平均分
spark.sql(
"select avg(score) as top1_user_avg from movie where userid = (select userid from top1_user_tb)"
).show()
def demo3_get_top1_user_avg_dsl():
# ①先查询高分电影:
hight_score_df = etldf.groupby('movieid').agg(
f.avg('score').alias('movie_avg_score')
).where('movie_avg_score>3')
# ②再求打分次数最多的用户(先不考虑并列,只取最大1个)
top1_user_df = hight_score_df.join(etldf, on=hight_score_df['movieid'] == etldf['movieid']) \
.groupby('userid').agg(f.count('userid').alias('cnt')) \
.orderby('cnt', ascending=false).limit(1)
# ③最后求此人所有打分的平均分
etldf.where(
etldf['userid'] == top1_user_df.first()['userid']
).agg(
f.avg('score').alias('top1_user_avg')
).show()
# 创建main函数
if __name__ == '__main__':
# 1.创建sparkcontext对象
spark = sparksession.builder.appname('pyspark_demo').master('local[*]').getorcreate()
# 2.数据输入
df = spark.read.csv(
schema='userid string,movieid string,score int,datestr string',
sep='\t',
path='file:///export/data/spark_project/spark_sql/data/u.data'
)
print(df.count())
# 3.数据处理(切分,转换,分组聚合)
etldf = df.dropduplicates().dropna()
print(etldf.count())
# 4.数据分析
# 方便后续所有sql方式使用,提前创建临时视图作为表
etldf.createtempview('movie')
# 需求1: 查询用户的平均分
# demo1_get_user_avg_score()
# 需求3: 查询大于平均分的电影的数量
# demo2_get_lag_avg_movie_cnt()
# 需求4: 查询高分电影(平均分>3)中,打分次数最多的用户,并求出此人所有打分的平均分
# 方式1: sql
demo3_get_top1_user_avg_sql()
# 方式2: dsl
demo3_get_top1_user_avg_dsl()
# 5.数据输出
# 6.关闭资源
spark.stop()
附录: 问题
可能出现的错误一:
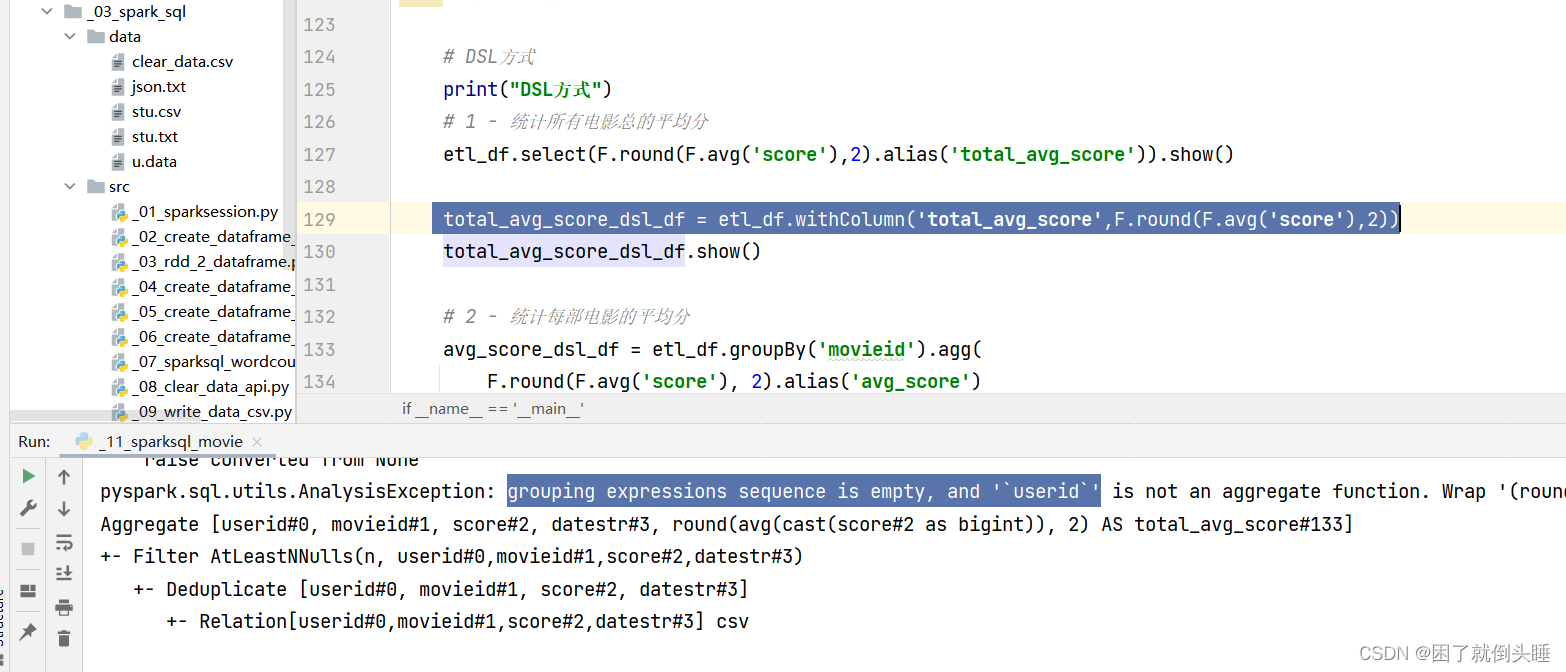
原因: 是使用withcolumn产生新列,但是表达式中有聚合的操作。缺少groupby调用
可能出现的错误二:
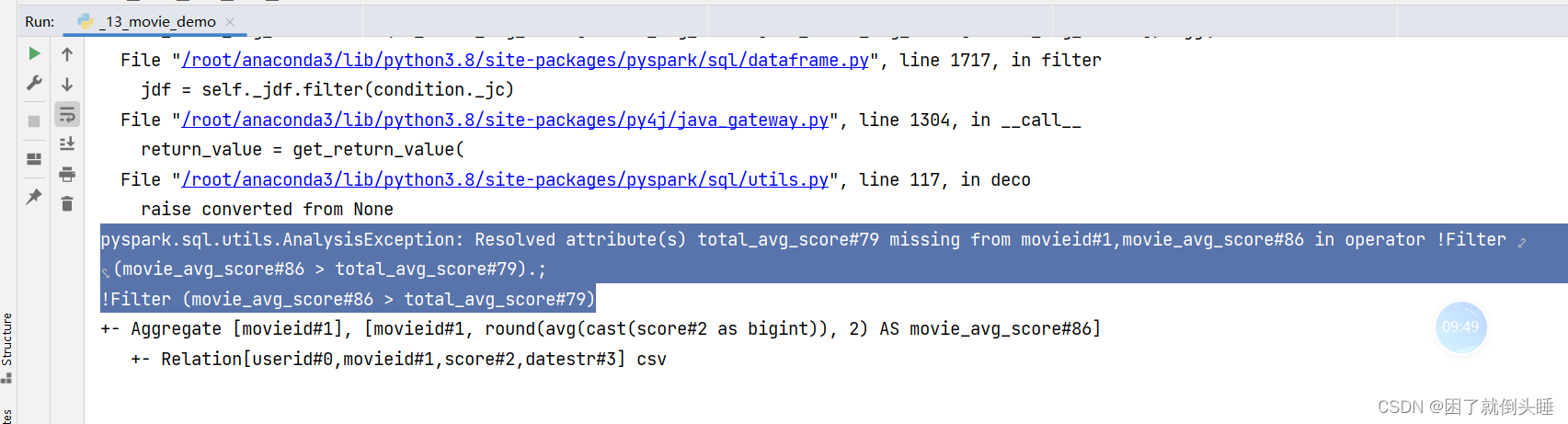
错误原因:dataframe结果是单行的情况,列值获取错误

解决办法:
将df_total_avg_score['total_avg_score']改成df_total_avg_score.first()['total_avg_score']
可能遇到的错误三:
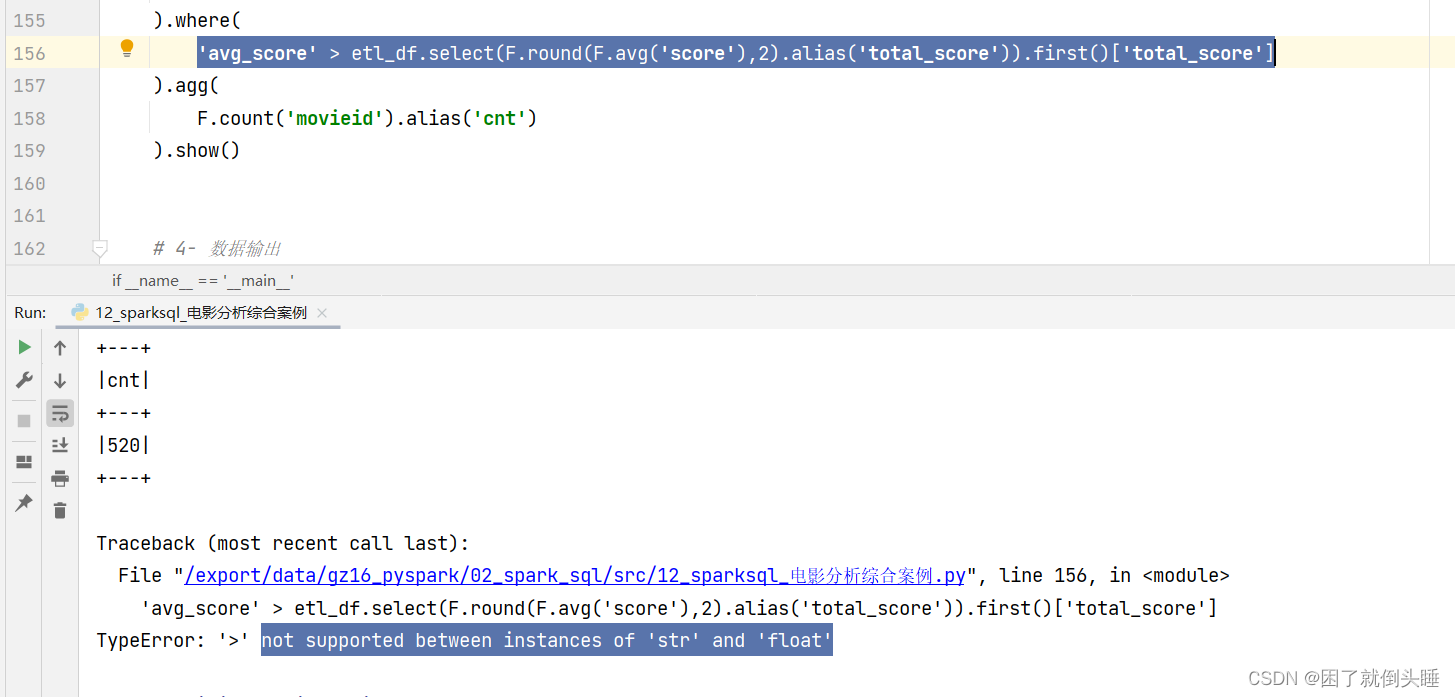
原因:对于在计算过程中临时产生的字段,需要使用f.col封装成column对象
解决办法:f.col('avg_score')



发表评论