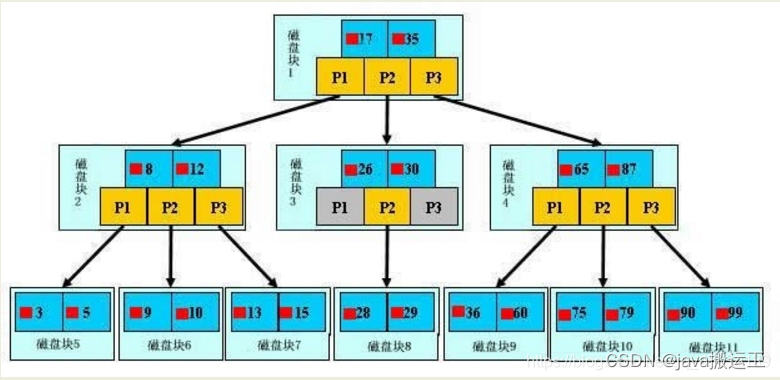
b树定义
- 每个节点最多有m-1个关键字(可以存有的键值对,m表示树的高度)
- 根节点最少可以只有1个关键字
- 非根节点至少有m/2个关键字
- 每个节点中的关键字都按照从小到大的顺序排列,每个关键字的左子树中的所有关键字都小于它,而右子树中的所有关键字都大于它
- 所有叶子节点都位于同一层,或者说根节点到每个叶子节点的长度都相同
- 每个节点都存有索引和数据,也就是对应的key和value
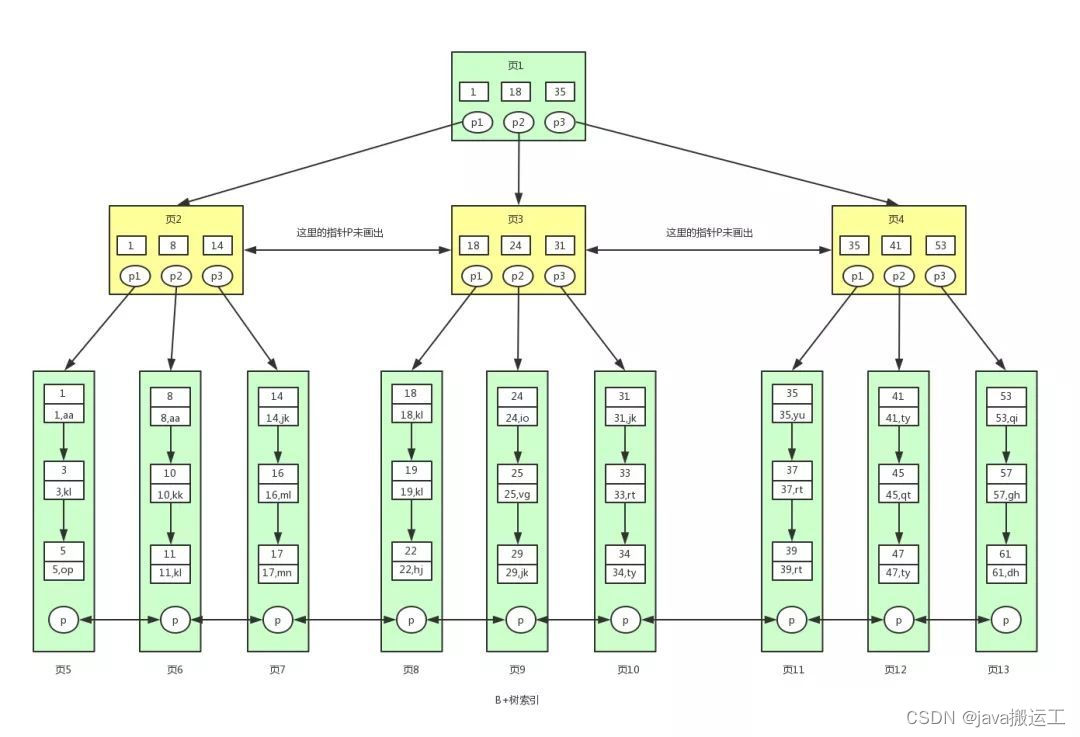
b+树定义
- 根节点至少一个元素
- 非根节点元素范围:m/2 <= k <= m-1
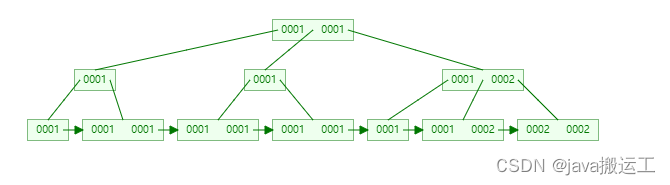
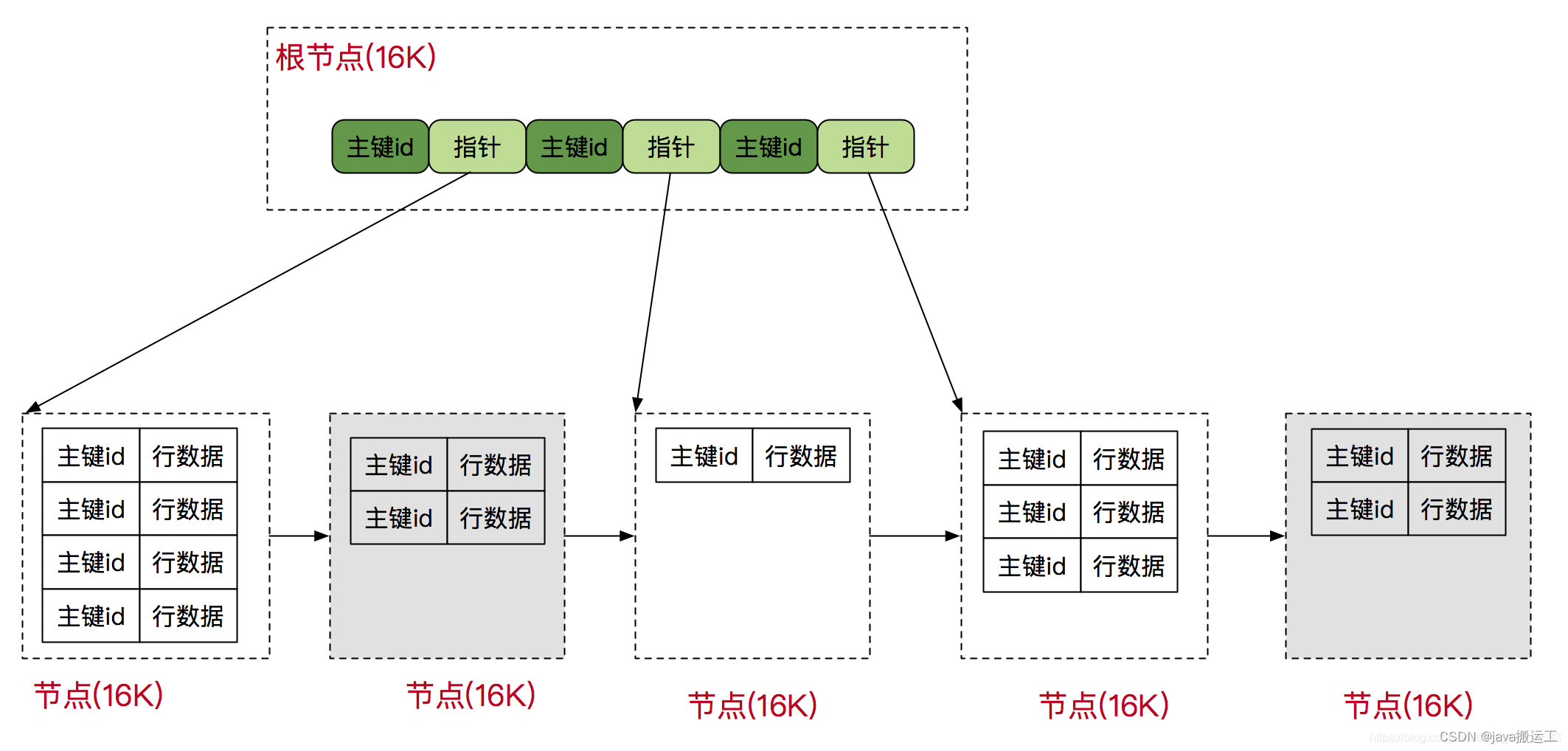
- b+树有两种类型的节点:内部结点(也称索引结点)和叶子结点。内部节点就是非叶子节点,内部节点不存储数据,只存储索引,数据都存储在叶子节点。
- 内部结点中的key都按照从小到大的顺序排列,对于内部结点中的一个key,左树中的所有key都小于它,右子树中的key都大于等于它。叶子结点中的记录也按照key的大小排列。
- 每个叶子结点都存有相邻叶子结点的指针,叶子结点本身依关键字的大小自小而大顺序链接。
- 父节点存有右孩子的第一个元素的索引。
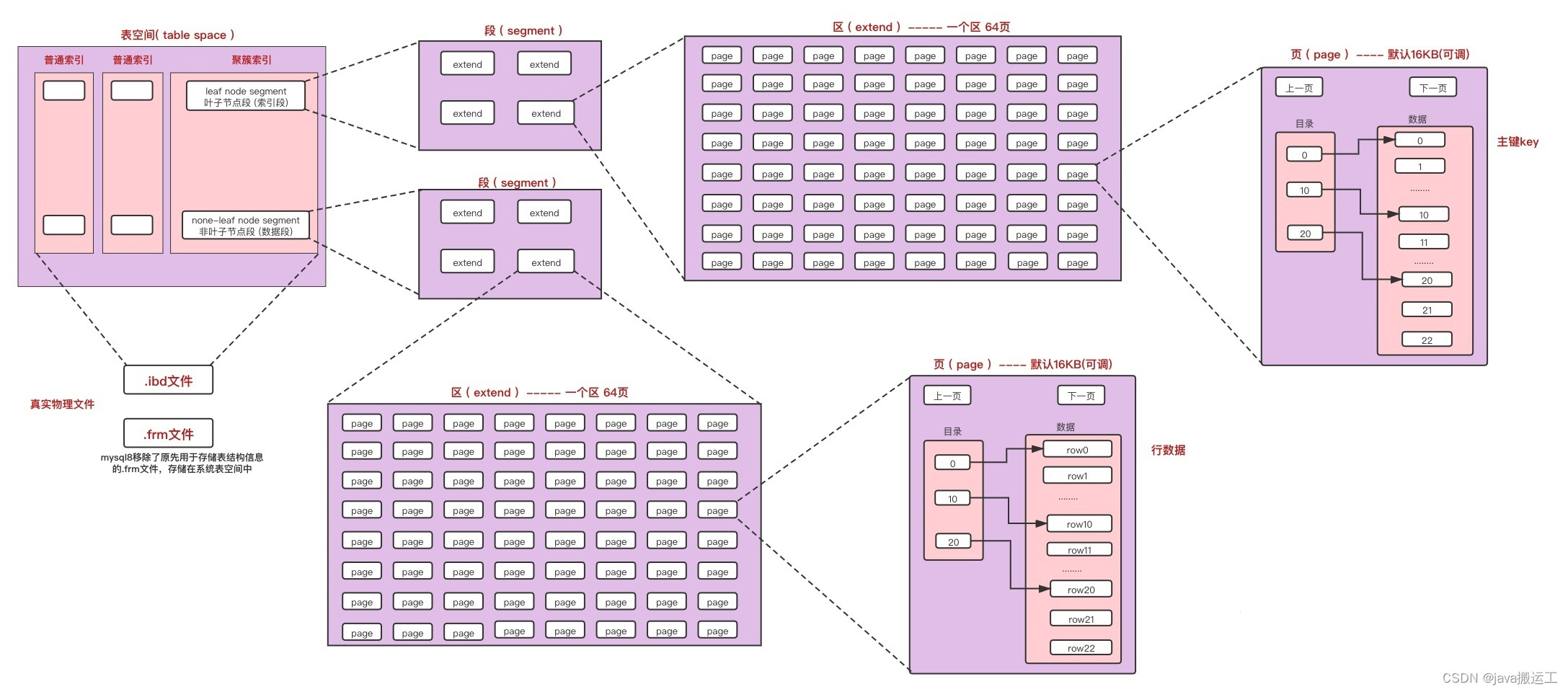
b树和b+树的区别
1、磁盘读写代价更低
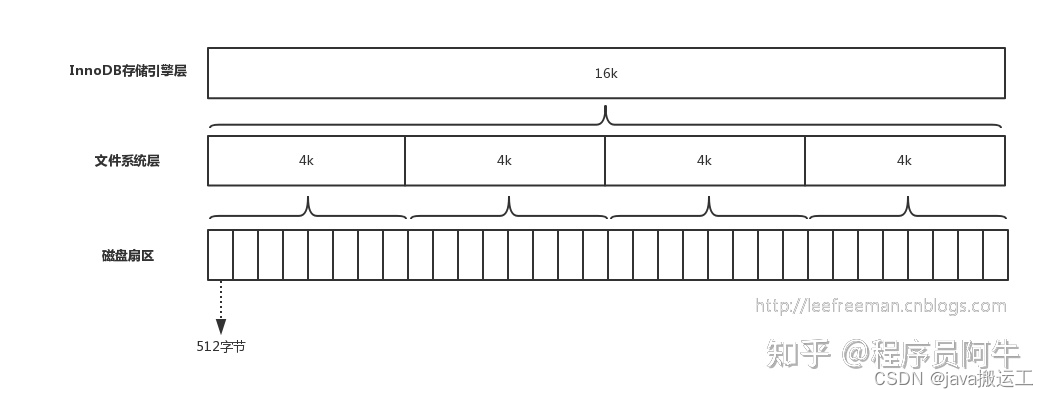
一般来说b+tree比btree更适合实现外存的索引结构,因为存储引擎的设计专家巧妙的利用了外存(磁盘)的存储结构,即磁盘的最小存储单位是扇区(sector),而操作系统的块(block)通常是整数倍的sector,操作系统以页(page)为单位管理内存,一页(page)通常默认为4k,数据库的页通常设置为操作系统页的整数倍,因此索引结构的节点被设计为一个页的大小,然后利用外存的“预读取”原则,每次读取的时候,把整个节点的数据读取到内存中,然后在内存中查找,已知内存的读取速度是外存读取i/o速度的几百倍,那么提升查找速度的关键就在于尽可能少的磁盘i/o,那么可以知道,每个节点中的key个数越多,那么树的高度越小,需要i/o的次数越少,因此一般来说b+tree比btree更快,因为b+tree的非叶节点中不存储data,就可以存储更多的key。
2、查询速度更稳定
由于b+tree非叶子节点不存储数据(data),因此所有的数据都要查询至叶子节点,而叶子节点的高度都是相同的,因此所有数据的查询速度都是一样的。
3、所有的叶子节点形成了一个有序链表,更加便于查找。(范围查找比b树有优势)
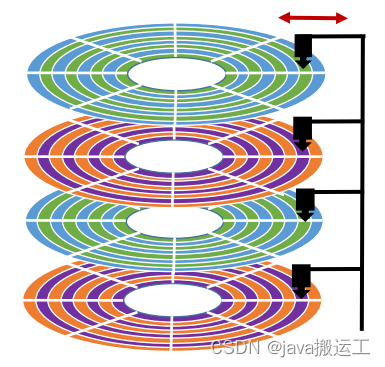
磁盘寻址毫秒级别,内存是纳秒级别。(秒,毫秒,微秒,纳秒)
磁盘读:寻道时间(磁头沿径向移动,移到要读取的扇区所在磁道的上方)+ 旋转延迟时间(盘片旋转,使得要读取的扇区转到读写磁头的下方)+ 传输时间(读写数据时间)
连续i/o:本次 i/o 给出的初始扇区地址和上一次 i/o 的结束扇区地址是完全连续或者相隔不多的。做连续 i/o 的时候,磁头几乎不用换道,或者换道的时间很短;而对于随机 i/o,如果这个 i/o 很多的话,会导致磁头不停地换道,造成效率的极大降低
磁盘io与预读:当一次io时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内。每一次io读取的数据我们称之为一页(page)
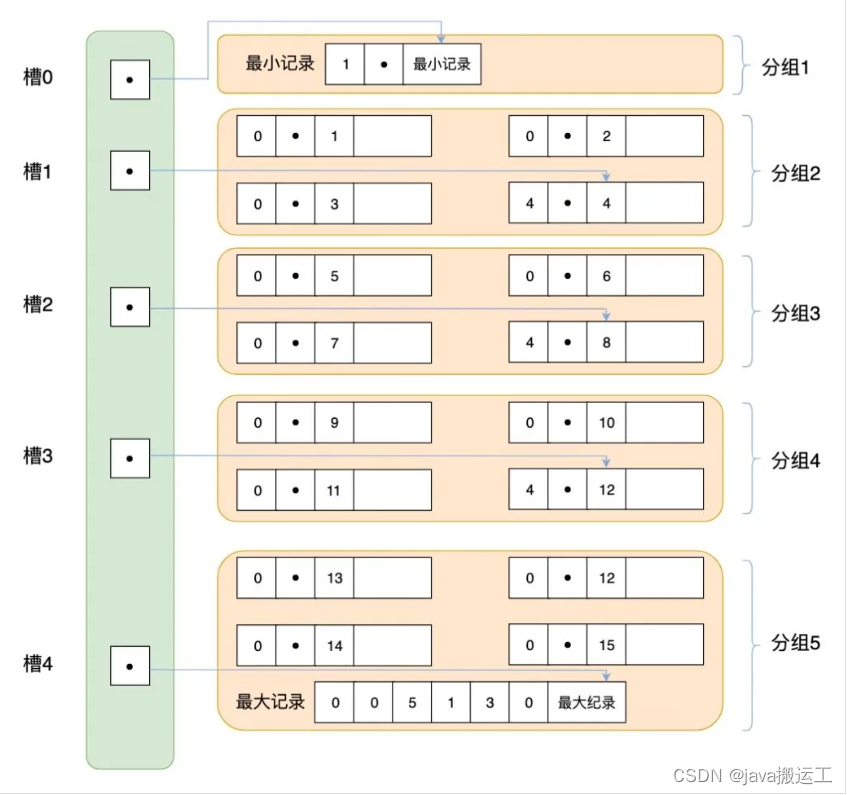
b+树数据存储
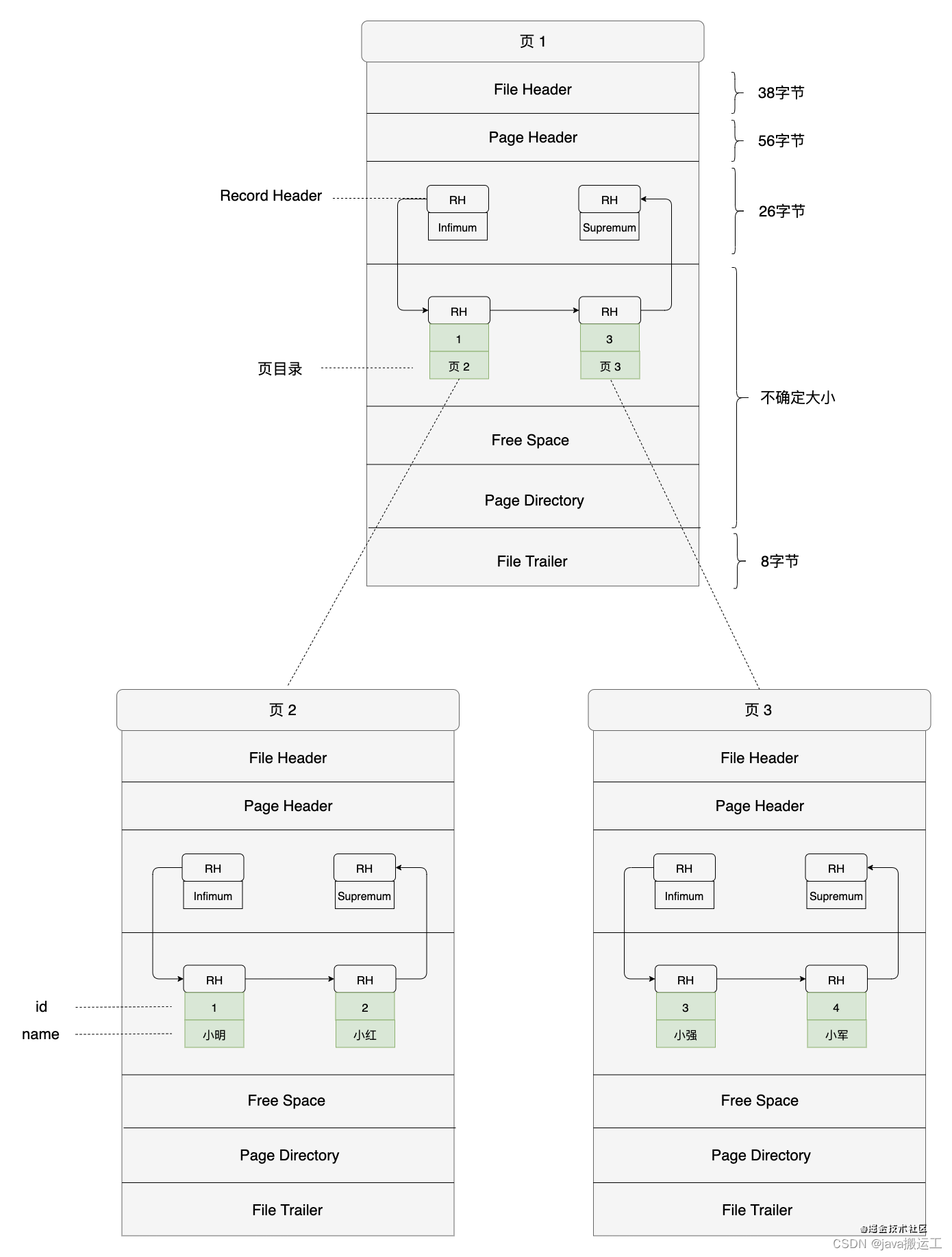
非叶子节点能存多少数据
- 页默认16kb
- file header、page header等一共占102个字节
- infimum + supremum分别占13个字节
- 记录头占5个字节
- id占为int,占4个字节
- 页目录的偏移量占4个字节
叶子节点能存多少数据
- 变长列表占1个字节
- null标志位忽略
- 记录头占5个字节
- id占为int,占4个字节
- name为varchar,编码为utf8,为了好算,所有行记录我都只用两个中文,那就是 2 * 3b = 6个字节
- 事务id列占6个字节
- 回滚指针列占7个字节
附:
3层b+树可以存多少数据
b+树的每个节点可以存16kb数据,这里我们假设我们的一行数据大小是1k,那么我们一个节点就可以存16行数据。
非叶子节点存放的是主键值与指针,所以这里假设主键类型为bigint,占用8byte,指针可以设置为占用6byte,总共就为14byte,这样就可以算出一个节点大概可以存放多少个指针了(指针指向下一层节点),大概为16kb/14byte=1170个。2层b+树的话,可以存放1170*16=18720行数据。3层b+树的话,可以存放1170*1170*16=21902400行数据,也就差不多2000w条数据了。
参考文章


发表评论