本文分享自华为云社区《线程锁导致的kafka客户端超时问题》,作者: 张俭 。
问题背景
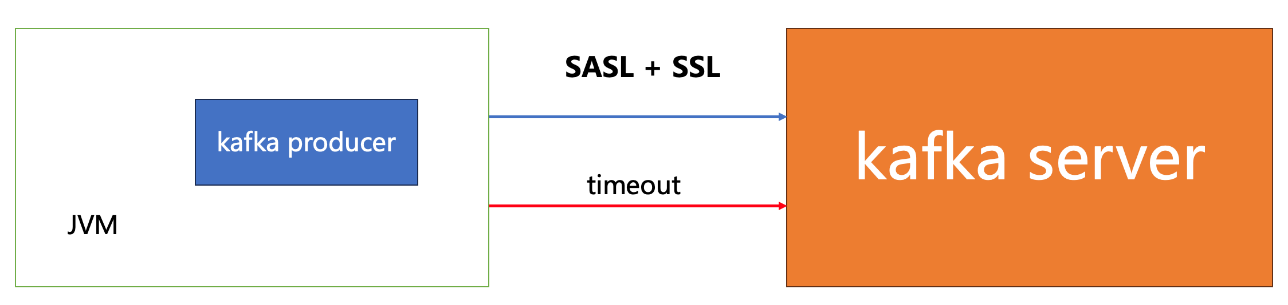
有一个环境的kafka client发送数据有部分超时,拓扑图也非常简单
定位历程
我们先对客户端的环境及jvm情况进行了排查,从jvm所在的虚拟机到kafka server的网络正常,垃圾回收(gc)时间也在预期范围内,没有出现异常。
紧接着,我们把目光转向了kafka 服务器,进行了一些基础的检查,同时也查看了kafka处理请求的超时日志,其中我们关心的metadata和produce请求都没有超时。
问题就此陷入了僵局,虽然也搜到了一些kafka server会对连上来的client反解导致超时的问题( kafka-8562: saslchannelbuilder - avoid (reverse) dns lookup while building underlying ssltransportlayer by dpoldrugo · pull request #10059 · apache/kafka · github),但通过一些简单的分析,我们确定这并非是问题所在。
同时,我们在环境上也发现一些异常情况,当时觉得不是核心问题/解释不通,没有深入去看
- 问题jvm线程数较高,已经超过10000,这个线程数量虽然确实较高,但并不会对1个4u的容器产生什么实质性的影响。
- 负责指标上报的线程cpu较高,大约占用了1/4 ~ 1/2 的cpu核,这个对于4u的容器来看问题也不大
当排查陷入僵局,我们开始考虑其他可能的调查手段。我们尝试抓包来找线索,这里的抓包是sasl鉴权+ssl加密的,非常难读,只能靠长度和响应时间勉强来推断报文的内容。
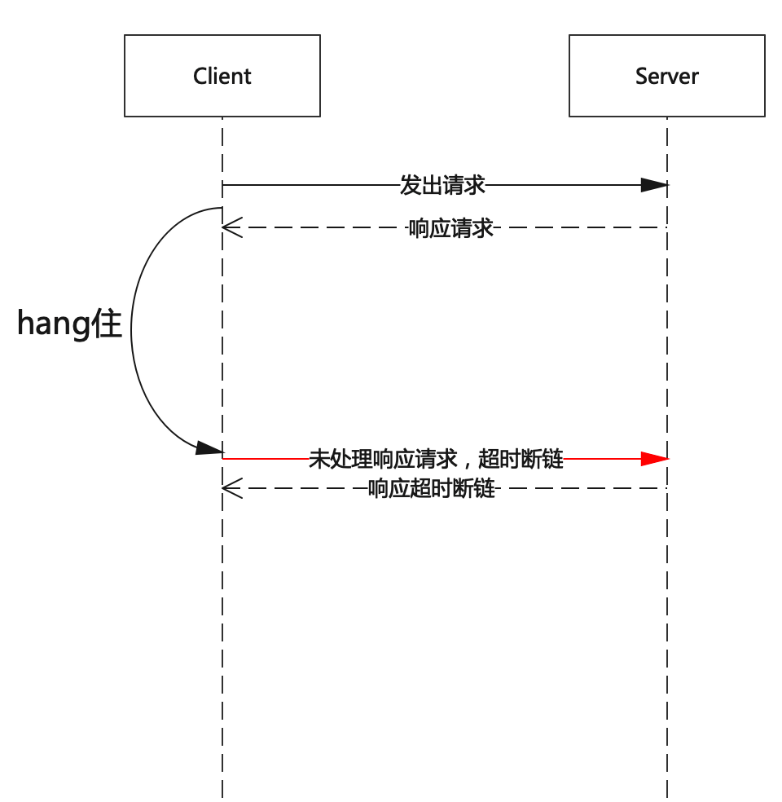
在这个过程中,我们发现了一个非常重要的线索,客户端竟然发起了超时断链,并且超时的那条消息,实际服务端是有响应回复的。
随后我们将kafka client的trace级别日志打开,这里不禁感叹kafka client日志打的相对较少,发现的确有log.debug(“disconnecting from node {} due to request timeout.”, nodeid);的日志打印。
与网络相关的流程:
try {
// 这里发出了请求
client.send(request, time.milliseconds());
while (client.active()) {
list<clientresponse> responses = client.poll(long.max_value, time.milliseconds());
for (clientresponse response : responses) {
if (response.requestheader().correlationid() == request.correlationid()) {
if (response.wasdisconnected()) {
throw new ioexception("connection to " + response.destination() + " was disconnected before the response was read");
}
if (response.versionmismatch() != null) {
throw response.versionmismatch();
}
return response;
}
}
}
throw new ioexception("client was shutdown before response was read");
} catch (disconnectexception e) {
if (client.active())
throw e;
else
throw new ioexception("client was shutdown before response was read");
}这个poll方法,不是简单的poll方法,而在poll方法中会进行超时判断,查看poll方法中调用的handletimedoutrequests方法
@override
public list<clientresponse> poll(long timeout, long now) {
ensureactive();
if (!abortedsends.isempty()) {
// if there are aborted sends because of unsupported version exceptions or disconnects,
// handle them immediately without waiting for selector#poll.
list<clientresponse> responses = new arraylist<>();
handleabortedsends(responses);
completeresponses(responses);
return responses;
}
long metadatatimeout = metadataupdater.maybeupdate(now);
try {
this.selector.poll(utils.min(timeout, metadatatimeout, defaultrequesttimeoutms));
} catch (ioexception e) {
log.error("unexpected error during i/o", e);
}
// process completed actions
long updatednow = this.time.milliseconds();
list<clientresponse> responses = new arraylist<>();
handlecompletedsends(responses, updatednow);
handlecompletedreceives(responses, updatednow);
handledisconnections(responses, updatednow);
handleconnections();
handleinitiateapiversionrequests(updatednow);
// 关键的超时判断
handletimedoutrequests(responses, updatednow);
completeresponses(responses);
return responses;
}由此我们推断,问题可能在于客户端hang住了一段时间,从而导致超时断链。我们通过工具arthas深入跟踪了kafka的相关代码,甚至发现一些简单的操作(如a.field)也需要数秒的时间。这进一步确认了我们的猜想:问题可能出在jvm。jvm可能在某个时刻出现问题,导致系统hang住,但这并非由gc引起。
为了解决这个问题,我们又检查了监控线程cpu较高的问题。我们发现线程的执行热点是从"sun.management.threadimpl"中的"getthreadinfo"方法。
"metrics-1@746" prio=5 tid=0xf nid=na runnable
java.lang.thread.state: runnable
at sun.management.threadimpl.getthreadinfo(native method)
at sun.management.threadimpl.getthreadinfo(threadimpl.java:185)
at sun.management.threadimpl.getthreadinfo(threadimpl.java:149)进一步发现,在某些版本的jdk8中,读取线程信息是需要加锁的。
至此,问题的根源已经清晰明了:过高的线程数以及线程监控时jvm全局锁的存在导致了这个问题。您可以使用如下的demo来复现这个问题
import java.lang.management.managementfactory;
import java.lang.management.threadinfo;
import java.lang.management.threadmxbean;
import java.util.concurrent.executors;
import java.util.concurrent.scheduledexecutorservice;
import java.util.concurrent.timeunit;
public class threadlocksimple {
public static void main(string[] args) {
for (int i = 0; i < 15_000; i++) {
new thread(new runnable() {
@override
public void run() {
try {
thread.sleep(200_000);
} catch (interruptedexception e) {
throw new runtimeexception(e);
}
}
}).start();
}
scheduledexecutorservice executorservice = executors.newsinglethreadscheduledexecutor();
executorservice.scheduleatfixedrate(new runnable() {
@override
public void run() {
system.out.println("take " + " " + system.currenttimemillis());
}
}, 1, 1, timeunit.seconds);
threadmxbean threadmxbean = managementfactory.getthreadmxbean();
scheduledexecutorservice metricsservice = executors.newsinglethreadscheduledexecutor();
metricsservice.scheduleatfixedrate(new runnable() {
@override
public void run() {
long start = system.currenttimemillis();
threadinfo[] threadinfolist = threadmxbean.getthreadinfo(threadmxbean.getallthreadids());
system.out.println("threads count " + threadinfolist.length + " cost :" + (system.currenttimemillis() - start));
}
}, 1, 1, timeunit.seconds);
}
}为了解决这个问题,我们有以下几个可能的方案:
- 将不合理的线程数往下降,可能存在线程泄露的场景
- 升级jdk到jdk11或者jdk17(推荐)
- 将thread相关的监控临时关闭
这个问题的解决方案应根据实际情况进行选择,希望对你有所帮助。



发表评论