一、简介
apache kafka是用scala语言开发的。scala是一种运行在java虚拟机(jvm)上的多范式编程语言,它结合了面向对象编程和函数式编程的特性。
由于scala能够与java很好地集成,并且能够充分利用java生态系统的优势,因此被广泛用于构建高性能、可扩展的分布式系统,
其中包括apache kafka这样的流式数据平台。 scala语言的特性使得kafka在性能和开发效率上都能取得良好的平衡。
kafka消息中间件是由apache软件基金会开发和维护的开源流式数据平台。它最初是为linkedin开发的,后来成为了一个独立的项目。
kafka旨在处理大规模的实时数据流,具有高吞吐量、持久性、可扩展性和容错性等特点。
kafka的核心概念包括:
- 消息(message):kafka通过主题(topic)来组织消息。消息可以是任何形式的数据,通常是键值对的形式。
- 主题(topic):主题是消息的逻辑分类,每条消息都属于一个主题。生产者将消息发布到特定的主题,而消费者则从感兴趣的主题订阅消息。
- 生产者(producer):生产者负责将消息发布到kafka的主题中。
- 消费者(consumer):消费者订阅一个或多个主题,并从中接收消息。
- 代理(broker):kafka集群由多个代理组成,每个代理都是一个独立的kafka服务器节点,负责存储和处理消息。
- 分区(partition):每个主题可以分为一个或多个分区,每个分区是有序的消息序列。分区使得kafka可以水平扩展,并允许消息并行处理。
- 复制(replication):kafka通过复制机制确保数据的持久性和容错性。每个分区可以配置多个副本,其中一个是领导者(leader),
其余是追随者(follower)。领导者负责处理读写请求,而追随者则复制领导者的数据以提供容错性。 - zookeeper:zookeeper是kafka用于集群管理和协调的关键组件。它负责管理kafka集群的状态、配置信息和领导者选举等任务。
kafka被广泛应用于实时数据管道、日志聚合、事件驱动架构等场景,其高性能和可靠性使其成为许多企业的首选消息中间件解决方案之一。
二、安装jdk
安装适合自己系统的jdk
yum install -y java-1.8.0-openjdk.x86_64 #这里要注意自己的系统架构
验证jdk是否安装成功,使用如下命令,如果正常输出java版本信息,则安装成功。
java -version
三、安装kafka
1. 下载kafka安装包
下载地址:https://kafka.apache.org/downloads
如果只是使用的话,下载二进制文件就行,不用选择source,在这里我选择下载kafka_2.13-3.5.2.tgz,scala版本为2.13,kafka版本为3.5.2。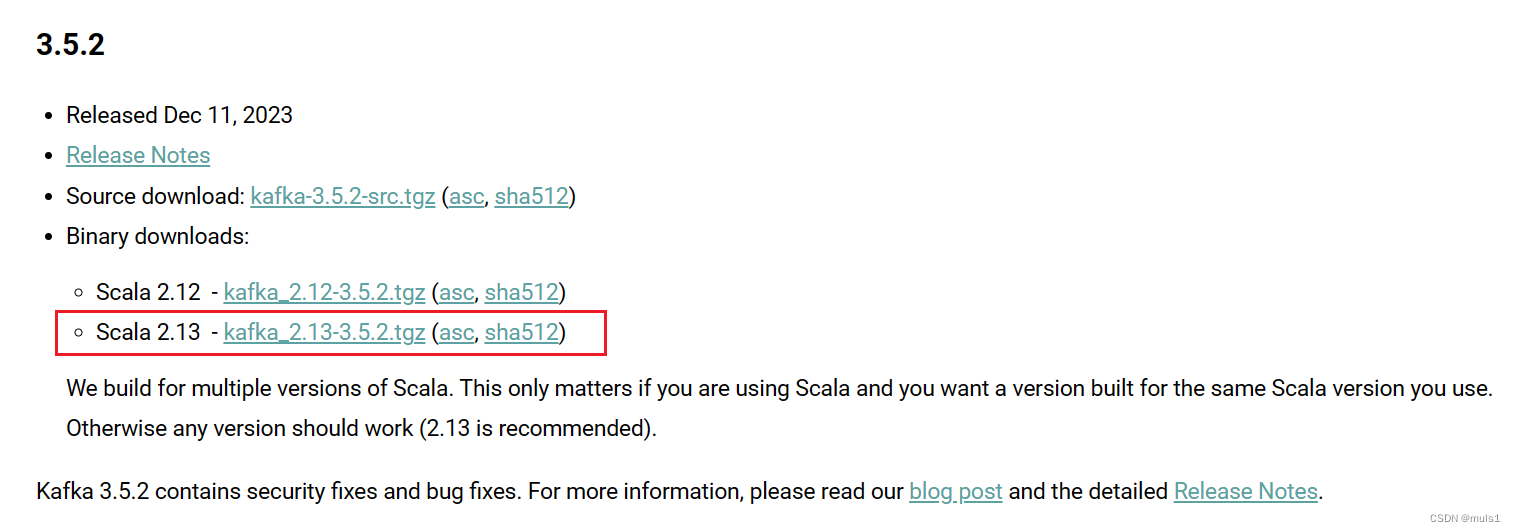
2. 上传到服务器,并解压到指定目录。
tar -zxvf kafka_2.13-3.5.2.tgz -c /elitel/app/kafka_2.13-3.5.2
3. 创建目录用于存放数据
mkdir -p /elitel/app/kafka_2.13-3.5.2/data
mkdir -p /elitel/app/kafka_2.13-3.5.2/data/kafka
mkdir -p /elitel/app/kafka_2.13-3.5.2/data/zk
4. 修改配置文件
修改kafka的配置文件,修改如下:
vim /elitel/app/kafka_2.13-3.5.2/config/server.properties
# 代理节点id,不能重复,我们这里不配置集群,就默认为0就行
broker.id=0
# kafka数据目录,日志目录也在这个目录下
log.dirs=/elitel/app/kafka_2.13-3.5.2/data/kafka
# 监听主机地址以及端口
listeners=plaintext://本机ip:9092
# 配置zk地址
zookeeper.connect=127.0.0.1:2181
修改zookeeper的配置文件,修改如下:
vim /elitel/app/kafka_2.13-3.5.2/config/zookeeper.properties
# 配置zk数据目录,日志目录也在这个目录下
datadir=/elitel/app/kafka_2.13-3.5.2/data/zk
# 配置zk端口
clientport=2181
# 一个客户端能够连接到同一个服务器上的最大连接数,根据ip来区分。如果设置为0,表示没有任何限制。设置该值一方面是为了防止dos攻击。
maxclientcnxns=100
5. 启动kafka和zookeeper(待测试)
(1) 编写启动脚本
vim /elitel/app/kafka_2.13-3.5.2/start.sh
#!/bin/bash
echo "正在启动 zookeeper..."
/elitel/app/kafka_2.13-3.5.2/bin/zookeeper-server-start.sh -daemon /elitel/app/kafka_2.13-3.5.2/config/zookeeper.properties &
sleep 3
# 检查 zookeeper 进程是否运行的脚本
# 使用 ps 命令检查是否有 java 进程,并且包含 zookeeper 的关键字
if ps ax | grep -v grep | grep "java.*zookeeper" > /dev/null
then
echo "zookeeper 启动成功!"
echo "starting kafka..."
/elitel/app/kafka_2.13-3.5.2/bin/kafka-server-start.sh -daemon /elitel/app/kafka_2.13-3.5.2/config/server.properties --override delete.topic.enable=true
sleep 3
if ps ax | grep -v grep | grep "java.*kafka_2.13-3.5" > /dev/null
then
echo "kafka 启动成功"
else
echo "kafka 进程未找到,可能尚未启动"
fi
else
echo "zookeeper 进程未找到,可能尚未启动"
fi
(2) 启动kafka和zookeeper
chmod +x /elitel/app/kafka_2.13-3.5.2/start.sh
/elitel/app/kafka_2.13-3.5.2/start.sh
6. 关闭kafka和zookeeper
(1) 编写停止脚本
vim /elitel/app/kafka_2.13-3.5.2/stop.sh
#!/bin/bash
echo "正在停止..."
/elitel/app/kafka_2.13-3.5.2/bin/zookeeper-server-stop.sh
sleep 2
/elitel/app/kafka_2.13-3.5.2/bin/kafka-server-stop.sh
sleep 2
if ps ax | grep -v grep | grep "java.*zookeeper" > /dev/null
then
echo "zookeeper 停止失败!"
else
echo "zookeeper 停止成功"
fi
if ps ax | grep -v grep | grep "java.*kafka_2.13-3.5" > /dev/null
then
echo "kafka 停止失败!"
else
echo "kafka 停止成功"
fi
(2) 停止kafka和zookeeper
chmod +x /elitel/app/kafka_2.13-3.5.2/stop.sh
/elitel/app/kafka_2.13-3.5.2/stop.sh
四、安装kafka可视化管理工具
在这里我选择kafkaui-lite,下载下方的二进制安装包就行
https://gitee.com/freakchicken/kafka-ui-lite/releases/tag/v1.2.11

1. 上传到服务器,并解压到指定目录。
tar -zxvf kafka-ui-lite-1.2.11.tar.gz -c /elitel/app/kafka-ui-lite-1.2.11
2. 修改配置文件
如果想修改元数据库为mysql, 修改conf/application.properties中的以下配置
在这里我们直接使用linux自带的sqlite数据库
server.port=19092
spring.datasource.driver-class-name=org.sqlite.jdbc
spring.datasource.url=jdbc:sqlite::resource:data.db
spring.datasource.username=
spring.datasource.password=
查看系统有无sqlite
rpm -qa | grep sqlite
有sqlite就会有如下输出
sqlite-3.7.17-8.el7_7.1.x86_64
如果使用mysql数据库就需要执行sql目录下的sql脚本
[root@localhost sql]# pwd
/elitel/app/kafka-ui-lite-1.2.11/sql
[root@localhost sql]# ll
总用量 8
-rw-r--r--. 1 root root 1540 4月 13 2021 ddl_mysql.sql
-rw-r--r--. 1 root root 1077 4月 13 2021 ddl_sqlite.sql
3. 启动kafka-ui-lite
进入到安装目录下,执行如下命令
# 前台启动
sh bin/kafkaui.sh start
# 后台启动
sh bin/kafkaui.sh -d start
# 关闭后台启动的进程
sh bin/kafkaui.sh stop
4.日志会输出到如下目录
/elitel/app/kafka-ui-lite-1.2.11/logs
五、开启端口
# 开启kafka服务端口
firewall-cmd --zone=public --add-port=9092/tcp --permanent
# 开启kafka-ui-lite可视化管理工具端口
firewall-cmd --zone=public --add-port=19092/tcp --permanent
# 重新加载防火墙
firewall-cmd --reload
六、kafka-ui-lite可视化管理工具登录
访问地址:http://192.168.1.100:19092
1. 添加配置
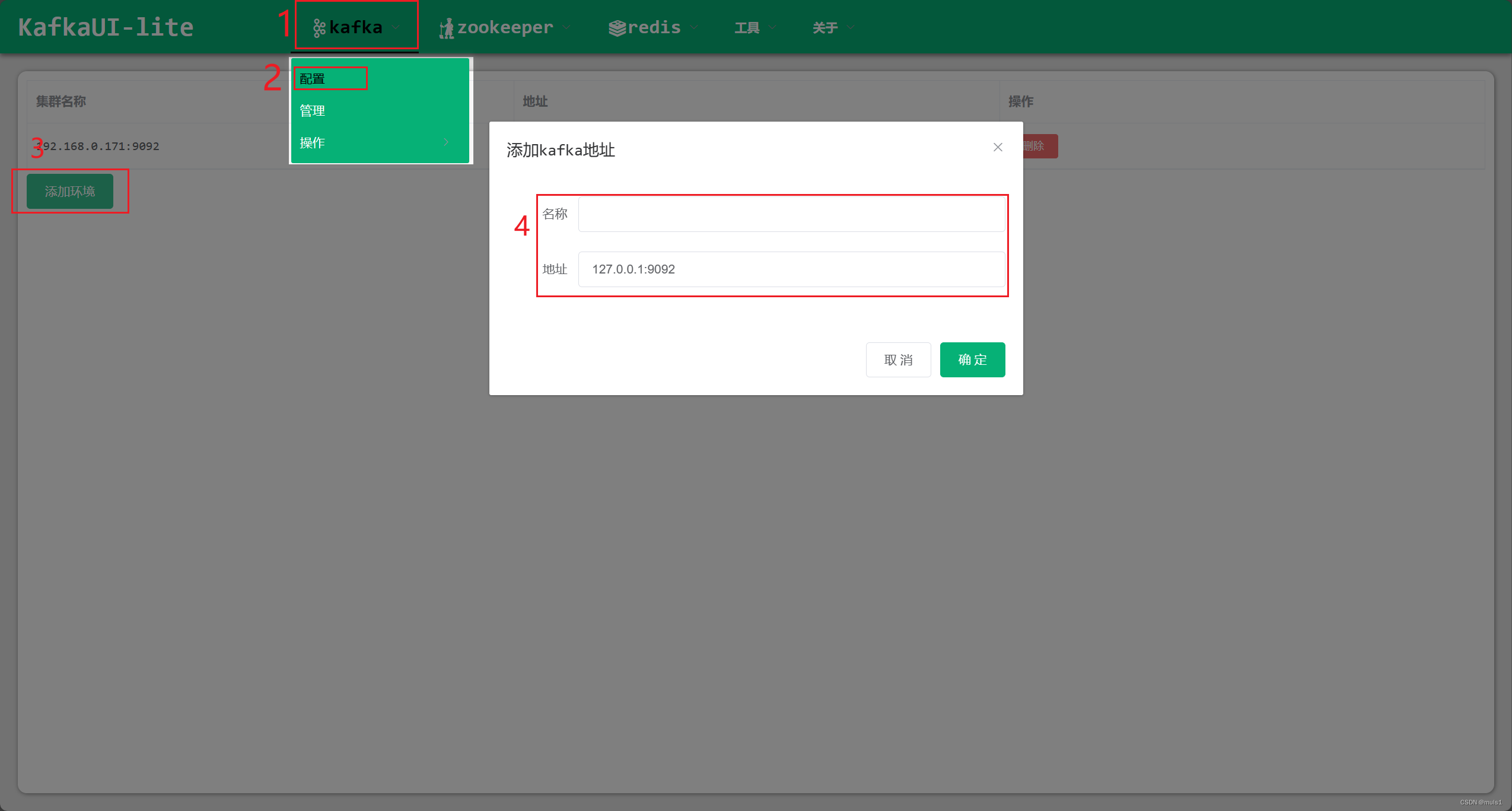
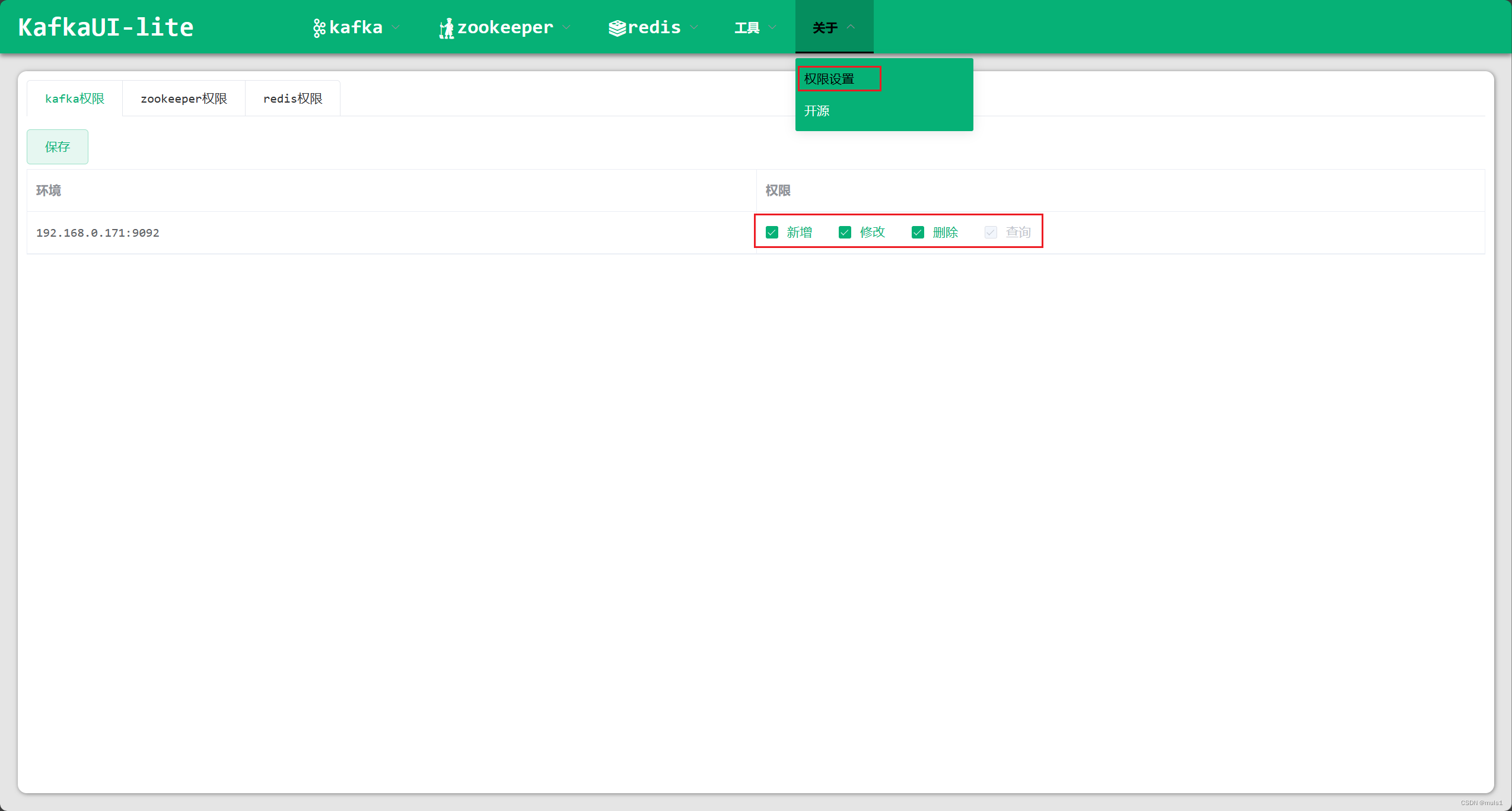
2. 开启权限
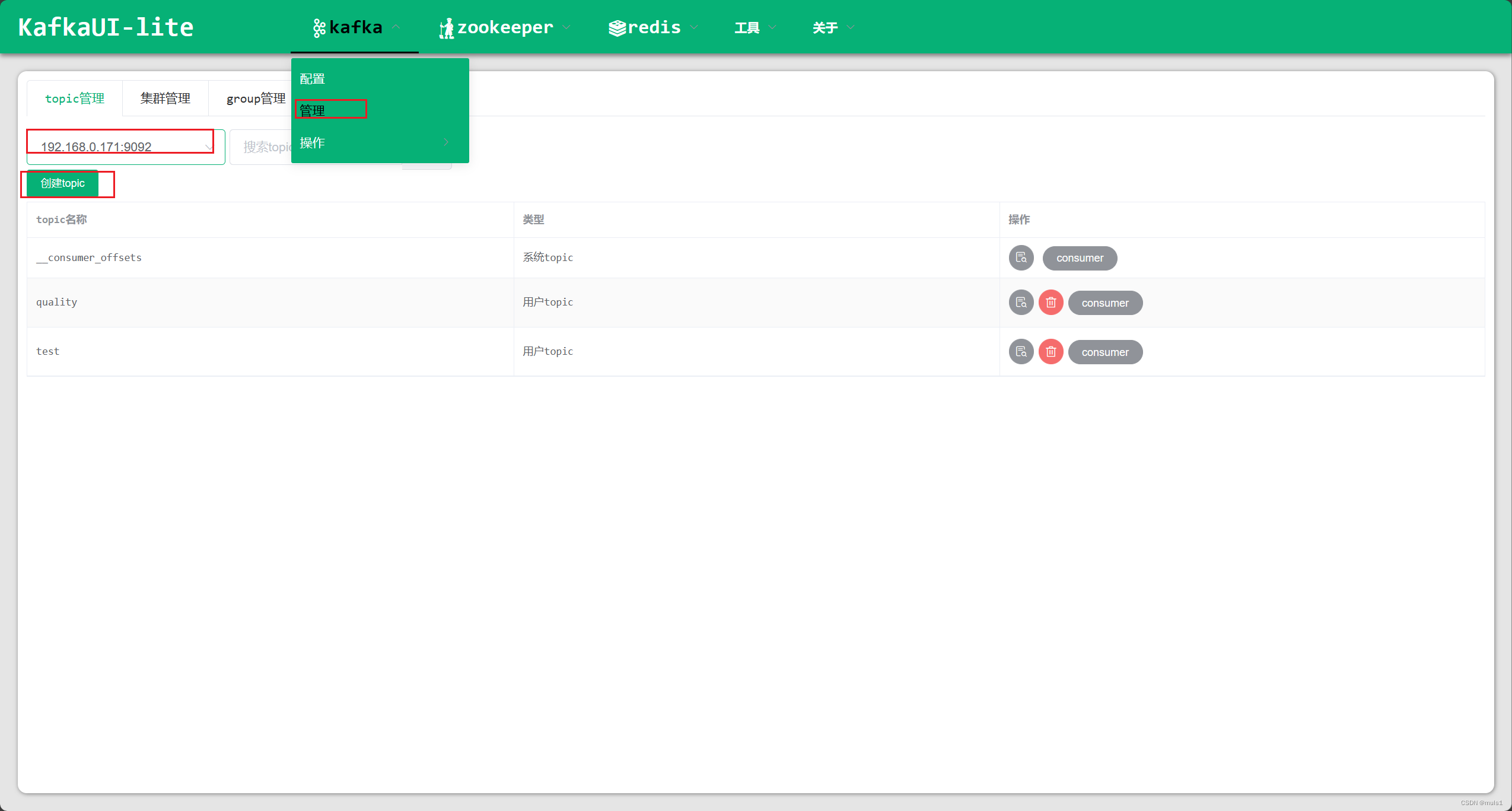
3. 添加topic
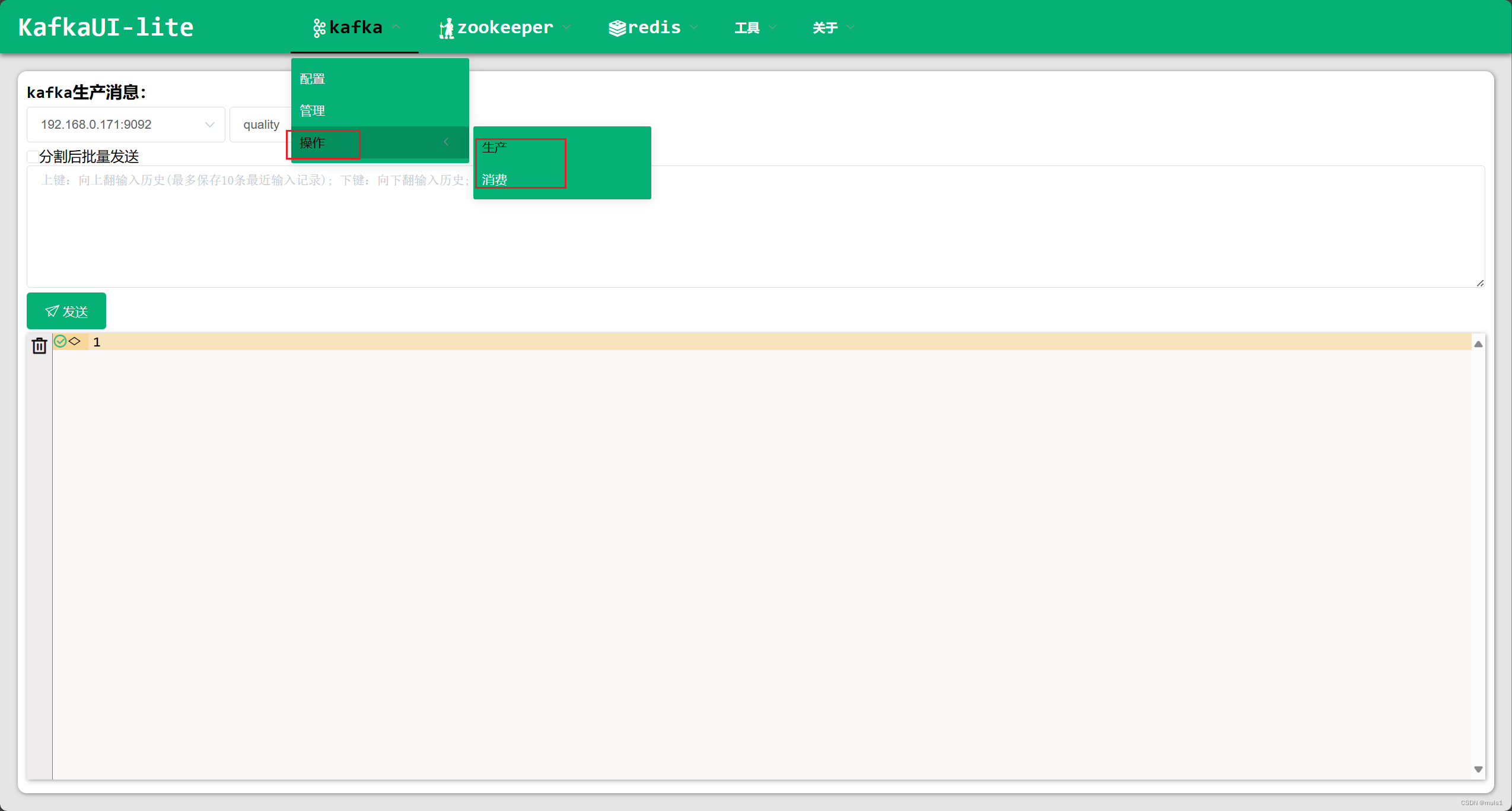
4. 生产、消费消息
![[手把手教学]实现STM32控制的语音识别的智能家居控制系统](/images/newimg/nimg4.png)
发表评论