前段时间做了yolov5的部署,就想训练yolov8并且部署在linux平台上,中间也踩了很多坑,花了两天时间终于部署完成了,在这里浅浅记录一下。
一、yolov8训练
yolov8是yolov5的作者写的,源码:https://github.com/ultralytics/ultralytics,但是新版的改动较yolov5较大,因为集成化程度较高,所以无法通过yolov5那样直接修改参数实现,一般都通过终端执行yolo命令来部署训练。至于环境配置,如果你之前搭建过yolov5的环境,那么yolov8环境搭建起来就很简单啦,只需要卸载torch,然后更新到支持gpu推理的版本即可,如果你的cuda版本太低的话,需要卸载原有的cuda版本,对于环境安装,这里不做过多讲述。
这里着重需要讲的是,对于opencv的dnn模块来说,目前还不支持动态的batch_size,所以在训练好了自己的网络模型后,在转onnx的时候需要注意以下几点:
1)关闭参数dynamic
这个参数代表了需不需要或者输出图像的batch可变,模型的输入输出有时是可变,因此可通过该参数设置。但是opencv目前是不支持动态推理的,所以dynamic需要设置为false。如果不设置为false,在读取模型的时候会报错。
2)关闭参数do_constant folding
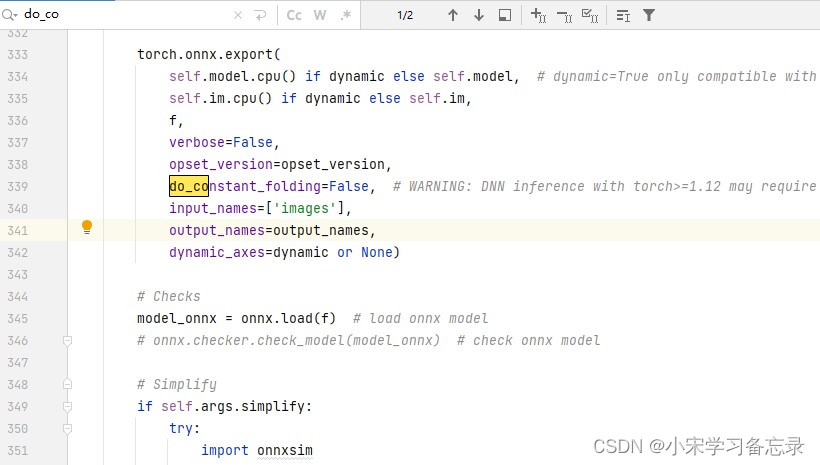
因为你要训练yolov8,那么就需要高版本的torch,如果torch版本高于2.0以上的话,不关闭此参数,也存在opencv读取不通过的情况,具体设置为:在yolov8的ultralytics文件夹下,找到engine文件夹,点击exporter.py,然后ctrl+f搜索变量do_constant folding,然后将其值改为false。如下:
3)设置opset =12
将onnx的算子集版本设置为12,默认支持11,最好设置为12
讲完这几点之后,那么只需要在pytorch环境下的终端中输入如下代码:
yolo export model=path/to/model.pt format=onnx dynamic=false opset=12其中model就是你训练好的pth文件的路径,然后在终端执行即可,至此onnx的转换就完成啦。转换完成就可以在netron中查看一下自己的输出对不对,如下所示:
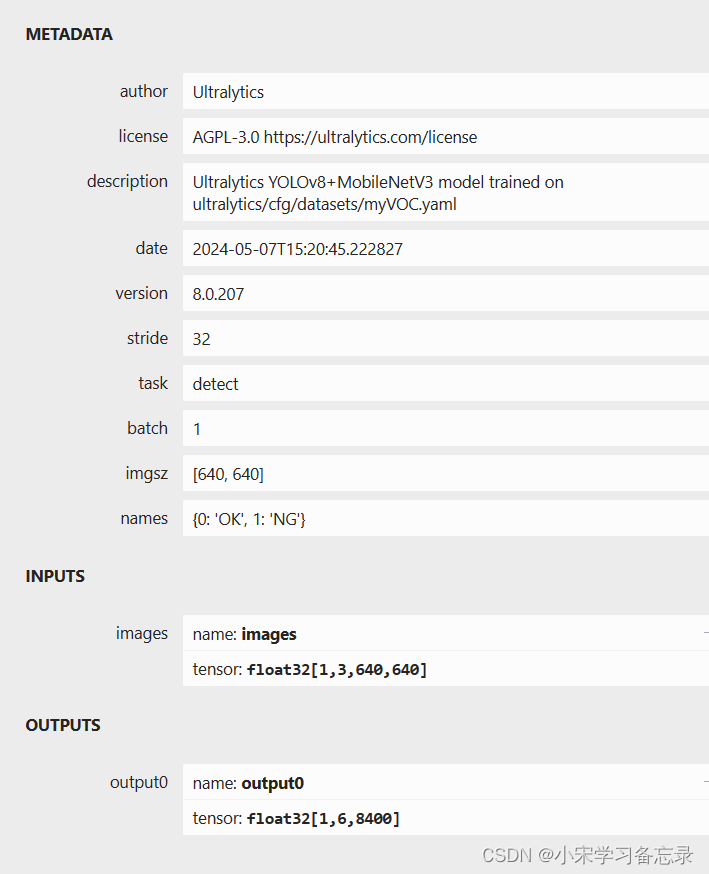
如果输入是1x3x640x640,输出是[1,84,8400](针对coco数据集)那就是对的, 因为yolov8的输出变了,将yolov5之前的置信度参数整合到了其他地方,因此这里无类别概率一项。至此转换为onnx就完成了,下一步就是基于opencv的推理了。
二、推理onnx模型
(1)部署opencv
又到了老生常谈的问题,是的,opencv4.7.0以下版本不支持yolov8推理,重要的事情说三遍:
opencv4.7.0以下版本不支持yolov8推理
opencv4.7.0以下版本不支持yolov8推理
opencv4.7.0以下版本不支持yolov8推理
但是,我的ubuntu上4.7.0版本也读取模型失败,因此我换了4.8.1之后,问题解决,为了大家省事,直接上4.8.1版本:安装和之前是一样的,如果还未安装,请移至本人博客: 中有详细介绍opencv的安装,也可以在网盘里自行下载提取码:wert。
(2)yolov8.h文件
#ifndef yolov8_h
#define yolov8_h
#pragma once
#include<iostream>
#include<opencv2/opencv.hpp>
#include "yolov8_utils.h"
using namespace cv;
using namespace cv::dnn;
class yolov8 {
public:
yolov8() {
}
~yolov8() {}
bool readmodel(cv::dnn::net& net, std::string& netpath, bool iscuda);
bool detect(cv::mat& srcimg, cv::dnn::net& net, std::vector<outputparams>& output);
void drawpred(cv::mat& img,
std::vector<outputparams> result,
std::vector<std::string> classnames,
std::vector<cv::scalar> color,
bool isvideo = false
);
void letterbox(const cv::mat& image, cv::mat& outimage,
cv::vec4d& params, //[ratio_x,ratio_y,dw,dh]
const cv::size& newshape = cv::size(640, 640),
bool autoshape = false,
bool scalefill = false,
bool scaleup = true,
int stride = 32,
const cv::scalar& color = cv::scalar(114, 114, 114));
int _netwidth = 640; //onnx图片输入宽度
int _netheight = 640; //onnx图片输入高度
//类别名,自己的模型需要修改此项
std::vector<std::string> _classname = { "ok","ng"};
private:
float _classthreshold = 0.25;
float _nmsthreshold = 0.45;
};
#endif // yolov8_h
代码中的类别名根据自己的网络来修改,其他均不变,类似于yolov5
(3)yolov8.cpp
#include"yolov8.h"
//using namespace std;
//using namespace cv;
//using namespace cv::dnn;
bool yolov8::readmodel(cv::dnn::net& net, std::string& netpath, bool iscuda = false) {
try {
net = cv::dnn::readnetfromonnx(netpath);
#if cv_version_major==4 &&cv_version_minor==7&&cv_version_revision==0
net.enablewinograd(false); //bug of opencv4.7.x in avx only platform ,https://github.com/opencv/opencv/pull/23112 and https://github.com/opencv/opencv/issues/23080
//net.enablewinograd(true); //if your cpu supports avx2, you can set it true to speed up
#endif
}
catch (const std::exception&) {
return false;
}
if (iscuda) {
//cuda
net.setpreferablebackend(cv::dnn::dnn_backend_cuda);
net.setpreferabletarget(cv::dnn::dnn_target_cuda); //or dnn_target_cuda_fp16
}
else {
//cpu
std::cout << "inference device: cpu" << std::endl;
net.setpreferablebackend(cv::dnn::dnn_backend_default);
net.setpreferabletarget(cv::dnn::dnn_target_cpu);
}
return true;
}
void yolov8::letterbox(const cv::mat& image, cv::mat& outimage, cv::vec4d& params, const cv::size& newshape,
bool autoshape, bool scalefill, bool scaleup, int stride, const cv::scalar& color)
{
if (false) {
int maxlen = max(image.rows, image.cols);
outimage = cv::mat::zeros(cv::size(maxlen, maxlen), cv_8uc3);
image.copyto(outimage(cv::rect(0, 0, image.cols, image.rows)));
params[0] = 1;
params[1] = 1;
params[3] = 0;
params[2] = 0;
}
cv::size shape = image.size();
float r = std::min((float)newshape.height / (float)shape.height,
(float)newshape.width / (float)shape.width);
if (!scaleup)
r = std::min(r, 1.0f);
float ratio[2]{ r, r };
int new_un_pad[2] = { (int)std::round((float)shape.width * r),(int)std::round((float)shape.height * r) };
auto dw = (float)(newshape.width - new_un_pad[0]);
auto dh = (float)(newshape.height - new_un_pad[1]);
if (autoshape)
{
dw = (float)((int)dw % stride);
dh = (float)((int)dh % stride);
}
else if (scalefill)
{
dw = 0.0f;
dh = 0.0f;
new_un_pad[0] = newshape.width;
new_un_pad[1] = newshape.height;
ratio[0] = (float)newshape.width / (float)shape.width;
ratio[1] = (float)newshape.height / (float)shape.height;
}
dw /= 2.0f;
dh /= 2.0f;
if (shape.width != new_un_pad[0] && shape.height != new_un_pad[1])
{
cv::resize(image, outimage, cv::size(new_un_pad[0], new_un_pad[1]));
}
else {
outimage = image.clone();
}
int top = int(std::round(dh - 0.1f));
int bottom = int(std::round(dh + 0.1f));
int left = int(std::round(dw - 0.1f));
int right = int(std::round(dw + 0.1f));
params[0] = ratio[0];
params[1] = ratio[1];
params[2] = left;
params[3] = top;
cv::copymakeborder(outimage, outimage, top, bottom, left, right, cv::border_constant, color);
}
bool yolov8::detect(cv::mat& srcimg, cv::dnn::net& net, std::vector<outputparams>& output) {
cv::mat blob;
output.clear();
int col = srcimg.cols;
int row = srcimg.rows;
cv::mat netinputimg;
cv::vec4d params;
letterbox(srcimg, netinputimg, params, cv::size(_netwidth, _netheight));
cv::dnn::blobfromimage(netinputimg, blob, 1 / 255.0, cv::size(_netwidth, _netheight), cv::scalar(0, 0, 0), true, false);
//**************************************************************************************************************************************************/
//如果在其他设置没有问题的情况下但是结果偏差很大,可以尝试下用下面两句语句
// if there is no problem with other settings, but results are a lot different from python-onnx , you can try to use the following two sentences
//
//$ cv::dnn::blobfromimage(netinputimg, blob, 1 / 255.0, cv::size(_netwidth, _netheight), cv::scalar(104, 117, 123), true, false);
//$ cv::dnn::blobfromimage(netinputimg, blob, 1 / 255.0, cv::size(_netwidth, _netheight), cv::scalar(114, 114,114), true, false);
//****************************************************************************************************************************************************/
net.setinput(blob);
std::vector<cv::mat> net_output_img;
net.enablewinograd(false);
net.forward(net_output_img, net.getunconnectedoutlayersnames()); //get outputs
//net.forward(net_output_img, "output0"); //获取output的输出
std::vector<int> class_ids;// res-class_id
std::vector<float> confidences;// res-conf
std::vector<cv::rect> boxes;// res-box
cv::mat output0=cv::mat( cv::size(net_output_img[0].size[2], net_output_img[0].size[1]), cv_32f, (float*)net_output_img[0].data).t(); //[bs,116,8400]=>[bs,8400,116]
int net_width = output0.cols;
int rows = output0.rows;
int socre_array_length = net_width - 4;
float* pdata = (float*)output0.data;
for (int r = 0; r < rows; ++r) {
cv::mat scores(1, socre_array_length, cv_32fc1, pdata + 4);
cv::point classidpoint;
double max_class_socre;
minmaxloc(scores, 0, &max_class_socre, 0, &classidpoint);
max_class_socre = (float)max_class_socre;
if (max_class_socre >= _classthreshold) {
//rect [x,y,w,h]
float x = (pdata[0] - params[2]) / params[0];
float y = (pdata[1] - params[3]) / params[1];
float w = pdata[2] / params[0];
float h = pdata[3] / params[1];
int left = max(int(x - 0.5 * w + 0.5), 0);
int top = max(int(y - 0.5 * h + 0.5), 0);
class_ids.push_back(classidpoint.x);
confidences.push_back(max_class_socre);
boxes.push_back(cv::rect(left, top, int(w + 0.5), int(h + 0.5)));
}
pdata += net_width;//next line
}
//nms
std::vector<int> nms_result;
cv::dnn::nmsboxes(boxes, confidences, _classthreshold, _nmsthreshold, nms_result);
std::vector<std::vector<float>> temp_mask_proposals;
cv::rect holeimgrect(0, 0, srcimg.cols, srcimg.rows);
for (int i = 0; i < nms_result.size(); ++i) {
int idx = nms_result[i];
outputparams result;
result.id = class_ids[idx];
result.confidence = confidences[idx];
result.box = boxes[idx] & holeimgrect;
output.push_back(result);
}
if (output.size())
return true;
else
return false;
}
void yolov8::drawpred(cv::mat& img, std::vector<outputparams> result, std::vector<std::string> classnames, std::vector<cv::scalar> color, bool isvideo) {
cv::mat mask = img.clone();
for (int i = 0; i < result.size(); i++) {
int left=0, top=0;
int color_num = i;
if (result[i].box.area() > 0) {
rectangle(img, result[i].box, color[result[i].id], 2, 8);
left = result[i].box.x;
top = result[i].box.y;
}
if (result[i].rotatedbox.size.width * result[i].rotatedbox.size.height > 0) {
drawrotatedbox(img, result[i].rotatedbox, color[result[i].id], 2);
left = result[i].rotatedbox.center.x;
top = result[i].rotatedbox.center.y;
}
if (result[i].boxmask.rows && result[i].boxmask.cols > 0)
mask(result[i].box).setto(color[result[i].id], result[i].boxmask);
std::string label = classnames[result[i].id] + ":" + std::to_string(result[i].confidence);
int baseline;
cv::size labelsize = cv::gettextsize(label, cv::font_hershey_simplex, 0.5, 1, &baseline);
top = max(top, labelsize.height);
//rectangle(frame, cv::point(left, top - int(1.5 * labelsize.height)), cv::point(left + int(1.5 * labelsize.width), top + baseline), cv::scalar(0, 255, 0), filled);
puttext(img, label, cv::point(left, top), cv::font_hershey_simplex, 1, color[result[i].id], 2);
}
cv::addweighted(img, 0.5, mask, 0.5, 0, img); //add mask to src
cv::imshow("1", img);
if (!isvideo)
cv::waitkey();
//destroyallwindows();
}如果模型加载成功的话,那么运行代码是完全没有问题的,如果报错,那就是你的模型问题,没有按照第一节的设置来弄。
(4)main函数
main函数中就很简单了,只需要先实例化一个yolov8的对象,然后先调用detect函数,在调用drawpred函数,最后就可以看到预测结果了,当然作者是基于qt开发的,不局限于平台,都可以的。
int main()
{
yolov8 yolov8;
net net;
std::string model_path = "./models/yolov8n.onnx"; //onnx的路径,填绝对路径
if (yolov8.readmodel(net, model_path, false)) {
std::cout << "read net ok!" << std::endl;
}
else {
return -1;
}
//生成随机颜色
std::vector<cv::scalar> color;
srand(time(0));
for (int i = 0; i < 80; i++) {
int b = rand() % 256;
int g = rand() % 256;
int r = rand() % 256;
color.push_back(cv::scalar(b, g, r));
}
std::vector<outputparams> result;
if (yolov8.detect(img, net, result)) {
drawpred(img, result, yolov8._classname, color);
}
else {
std::cout << "detect failed!" << std::endl;
}
system("pause");
return 0;
}部署到这里就完成啦,其实大家如果之前部署过yolov5的话,对于yolov8变化不大,部署起来也很简单,希望能帮到大家,写的比较仓促,错误之处希望大家及时批评指正!!!

发表评论