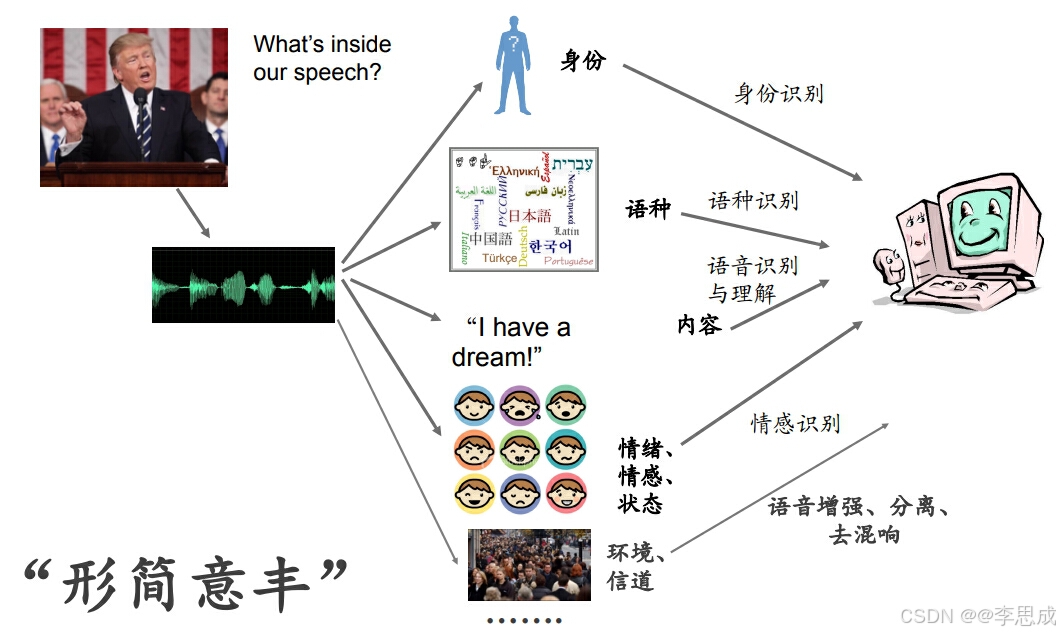
语音识别概述
一.什么是语音?
语音是语言的声学表现形式,是人类自然的交流工具。
图片来源:https://www.shenlanxueyuan.com/course/381
二.语音识别的定义
语音识别(automatic speech recognition, asr 或 speech to text, stt)是将语音转换为文本的任务。其主要目标是解决机器“听清”问题,处理声学和(部分)语言上的混淆,确保每个人的语音都能被正确识别为文本。
1.主要解决的问题:
- 将语音转换成文本。
- 解决机器“听清”问题。
- 处理声学和部分语言上的混淆。
- 确保不同人的语音都能被正确识别。
2.不解决的问题:
- 说话人识别。
- 副语言信息的分析与识别(如发音、质量、韵律、情感)。
- 语言理解。
3.评估标准:
-
accuracy(准确率):
- 音素错误率(phone error rate, per)
- 词错误率(word error rate, wer)
- 字错误率(character error rate, cer)
- 句错误率(sentence error rate, ser)
-
efficiency(效率):
- 实时率(real-time factor, rtf)
4.错误率计算实例:
ref: the cat in the hat
hyp: cat is on the green hat
del sub ins ins
在这个例子中:
- 第一行为正确的抄本(ref)。
- 第二行为识别结果(hyp)。
- 错误类型:第一列为删除错误(del),第三列为替换错误(sub),第四列和第六列为插入错误(ins)。
错误率计算公式:error rate=100×(1s+1d+2i)/5=80
计算过程中关注三种错误:插入错误、替换错误和删除错误。实际计算时,错误率有可能超过100%。
5.语音识别系统分类:
- 说话人:特定人、非特定人
- 语种:单一语种、多语种
- 词汇量:大词汇量、中词汇量、小词汇量
- 设备:云端、端侧
- 距离:近距离、远距离
三.语音识别的重要性
语音识别(asr,automatic speech recognition)是一项极具挑战性的技术,被誉为“镶嵌在人工智能皇冠上的明珠”。它在现代技术和应用中占有重要地位,主要体现在以下几个方面:
1. 快速、便捷、无接触的优点
- 快速:语音输入的速度通常比键盘输入更快,使信息传递更加高效。
- 便捷:用户只需说话,无需学习复杂的输入方法,使用门槛低。
- 无接触(hands-free):特别适用于开车、做家务等需要双手操作的场景,提升了用户的便利性和安全性。
2. 音频内容分析与理解的基础
- 文字转写:语音识别是将音频内容转化为文本的第一步,这一过程是进一步分析与理解音频内容的基础。
- 文本分析:转写后的文本可以进行情感分析、主题识别等处理。
- 数据存档:转写文本便于存储和检索,提升了数据的可用性。
3. aiot和智能服务的入口
-
aiot(人工智能物联网):语音识别是aiot设备的主要交互方式,用户可以通过语音控制智能家居、可穿戴设备等。
- 智能家居:语音助手控制灯光、温度、家电等。
- 可穿戴设备:语音识别用于健康监测、运动记录等。
-
智能服务:语音识别在智能客服、自动翻译等领域有广泛应用。
- 智能客服:自动应答用户问题,提高客服效率。
- 自动翻译:实时翻译语音内容,打破语言障碍。
4. 满足自然人机交互和内容理解与生成的需求
-
自然人机交互:语音识别使人机交互更加自然,用户可以通过语音指令与设备进行交流,提升用户体验。
- 虚拟助手:如siri、alexa、google assistant等通过语音识别实现自然对话。
- 导航系统:通过语音输入目的地,提高驾驶安全性。
-
内容理解与生成:语音识别技术与自然语言处理(nlp)结合,实现内容的理解与生成。
- 语音搜索:用户通过语音进行信息搜索,快速获取答案。
- 语音生成:将文本转化为自然语音,实现双向交流。
5. 技术与应用的广泛性
- 医疗领域:医生通过语音输入病历,提高工作效率,减少误诊。
- 教育领域:语音识别用于语言学习、课堂记录等,提高学习效果。
- 安防领域:通过语音识别进行身份验证和监控,提高安全性。
四.语音交互
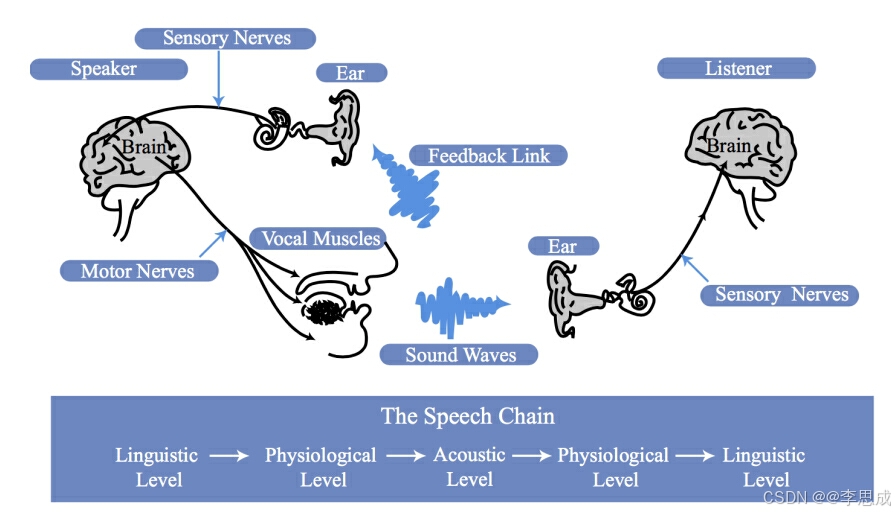
图片来源:http://techchannel.att.com/play-video.cfm/2011/8/10/at&t-archives-the-speech-chain
五.语音生成
语音生成(speech production)是指通过大脑指挥神经系统发出肌肉命令,进而控制发音器官运动,最终产生声音的过程。
1.语音生成过程
-
大脑指挥:大脑发出神经信号,控制肌肉运动。
-
神经肌肉命令:神经系统将命令传递到发音器官。
-
发音器官运动:发音器官(如声带、口腔、鼻腔等)根据神经信号进行运动,产生声音。
2.发音的基本原理
- 声门运动:声门的快速打开与关闭产生不同的声音。
- 基本频率:声门震动的快慢决定声音的基本频率。
- 口腔、鼻腔、舌头的位置及嘴型:这些因素共同决定声音的内容。
- 肺部空气压力:肺部压缩空气的力量决定音量。
2.声音类型
-
浊音(voiced sounds):由声带震动引起,波形具有明显的周期性,人们可以感受到稳定的高音。
-
清音(unvoiced sounds):声带不震动,波形类似白噪声,人们无法感受到稳定的高音。
3.语音单元
-
音素(phonemes):
- 音素是语言中语音的最小单元,分为辅音(consonants)和元音(vowels)。
- 音素的数量因语言而异。
- 同位异音(allophone):音素的声学实现受到上下文影响,一个音素可能有不同的实现。
-
词素(morpheme):语言中最小的具有语义的结构单元。
-
音节(syllable):
- 由元音和辅音结合构成。
- 音节头(声母):元音之前的辅音。
- 韵母:音节头后的元音及随后的辅音。
- 音节核:韵母中的元音。
- 音节尾:随后的辅音。
- 在中文中,一个汉字的读音为一个带调音节(如普通话约1300多个带调音节,去掉声调后约400个基础音节)。
4.声学特征
-
共振峰(formants):
- 在声音的频谱中,能量相对集中的区域。
- 共振峰决定音质,反映声道的物理特征,不同元音会产生不同种类的共振。
-
协同发音(coarticulation):
- 发音过程中,每个音素会受到前后音素的影响。
- 协同发音使得音素的声学实现与上下文强相关,因此语音识别中常建立上下文相关模型。
5.音素抄本
音素抄本(phonetic transcription)是一段语音对应的音素列表,可以带或不带边界。音素抄本提供时间信息,可以通过人工标注或自动对齐获得。它在语音识别的声学建模中非常重要。
六.语音感知
语音感知(speech perception)是指人耳将外界声音信号传递到大脑,并由大脑进行处理和理解的过程。该过程包括外耳、中耳和内耳的协同工作,以及声音的物理特性与人耳听觉特性之间的关系。
1.人耳结构
-
外耳:
- 功能:声源定位,对声音进行放大。
- 组成:耳廓和外耳道。
-
中耳:
- 功能:进行声阻抗变换,放大声压,保护内耳。
- 组成:鼓膜和听小骨(锤骨、砧骨、镫骨)。
-
内耳:
- 功能:将声压刺激转化为神经冲动,发送到大脑。
- 组成:耳蜗和听神经。
2.物理特性与听觉特性
语音感知涉及声音的物理量和感知量之间的关系。下表总结了这些关系:
| 物理量 (physical quantity) | 感知量 (perceptual quantity) |
|---|---|
| 声强 (intensity) | 响度 (loudness) |
| 基频 (fundamental frequency) | 音高或音调 (pitch) |
| 频谱形状 (spectral shape) | 音色或音品 (timbre) |
| 起始/结束时间 (onset/offset time) | 时间感知 (timing) |
| 双耳听觉的相位差 (phase difference in binaural hearing) | 定位 (location) |
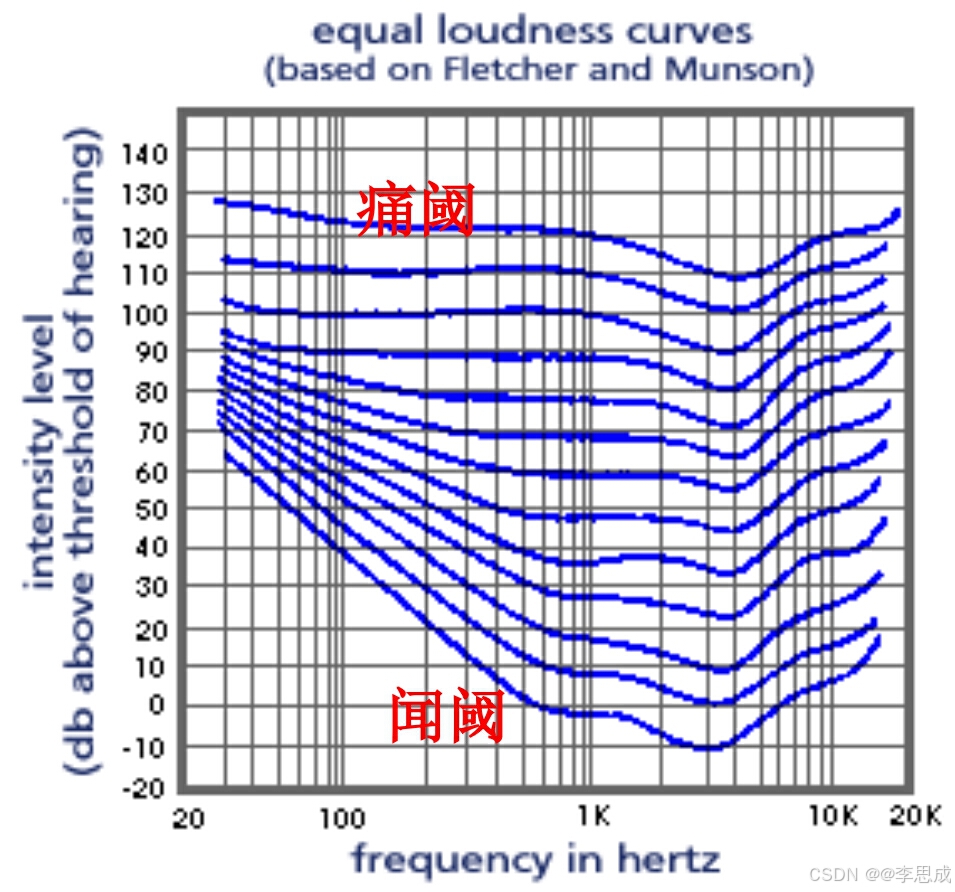
3.声音三要素
-
响度(loudness):
- 响度是人主观感受到的声音强度,与声音的频率成分有关。
- 闻阈:人耳刚好能听见的最小响度。
- 痛阈:声音使人耳感到疼痛时的响度。
图片来源:https://www.shenlanxueyuan.com/course/381
-
音高或音调(pitch):
-
音调是人耳对声音频率的感知,是非线性的,近似对数函数。
-
音调和频率的近似关系:𝑇𝑚𝑒𝑙=2595log10(1+𝑓7000)。
𝑓为物理频率,𝑇𝑚𝑒𝑙为音调,单位是美(mel)
-
-
音色或音品(timbre):
- 音色由声音波形的谐波频谱和包络决定。
- 基音:声音波形的基频产生的最清楚的音。
- 泛音:各次谐波的微小震动产生的音。
- 纯音:单一频率的音。
- 复音:具有谐波的音。
- 不同声源的音色特征由声音波形各次谐波的比例和随时间的衰减大小决定。
4.掩蔽效应
掩蔽效应(masking)是指一个较强声音掩蔽附近较弱声音,使其不易被察觉的现象。分为两种情况:
-
同时掩蔽(simultaneous masking):一个强纯音会掩蔽其附近频率同时发生的弱纯音。
-
异时掩蔽(temporal masking):在时间上相邻的声音之间的掩蔽现象。
掩蔽阈值是时间、频率和声压级的函数。
七.语音识别的挑战性
语音识别(automatic speech recognition, asr)是一个非常具有挑战性的任务,其在众多方面表现出强大的可变性。以下是影响语音识别性能的主要因素及其可变性:
1.主要影响因素及其可变性
| 因素 | 可变性描述 |
|---|---|
| 规模 | 词表大小、复杂度/困惑度、书面化或口语化 |
| 说话人 | 是否特定说话人、适应特定说话人的特性 |
| 声学环境 | 噪声、干扰人声、信道条件(麦克风、传输空间、空间声学) |
| 讲话风格 | 连续或孤立词、有计划或即兴对话、大声或轻声细语 |
| 口音/方言 | 是否能识别各种口音 |
| 语种 | 中文、英文、超过5000种语言、语言混杂 |
| 信道特性 | 不同麦克风、不同采样率、传输编码等 |
| 环境影响 | 距离衰减、噪声、混响、干扰人声 |
2.语音识别中的变异性
-
说话人之间的变异性:不同说话人的口音、语速、发音方式、语调等各不相同。适应多种说话人的特性是语音识别的一个重要挑战。
-
说话人之内的变异性:同一个人在不同时间、不同情绪状态、不同健康状态下,语音特性也会有所不同。不同讲话方式(如大声、轻声、低语)对语音识别系统的要求也各不相同。
-
信道变异性:不同麦克风的性能、采样率和传输编码会影响语音信号的质量。在不同传输条件下,信号可能会受到干扰或衰减。
-
环境变异性:环境噪声、回声、混响以及干扰人声等都会影响语音信号的清晰度。距离衰减效应,尤其在远讲场景下,语音信号会显著衰减。
3.特殊场景挑战
chime-5场景: 多说话人完全自由对话。现实生活中的家居声学场景。远讲情况下的语音识别。说话人移动及语音交叠。
八.语音识别的发展历史
1.早期阶段(1950-1960年代)
在语音识别研究的初期,研究人员主要集中于提出一些基础的方法和引入关键的思想与概念。由于受限于方法、计算能力和数据量,这一阶段的研究主要针对小词表的语音识别,且缺乏大规模测试。主要特点包括:
- 初步探索:提出个别方法和概念。
- 小词表研究:主要集中在小范围词汇的语音识别。
- 技术限制:计算能力和数据量的限制使得研究进展缓慢。
2.现代语音识别的诞生(1970-1980年代)
这个阶段标志着语音识别从基础研究进入了统计学习时代,几乎忽略了语音学和语言学的专家知识,转而使用数据驱动的方法。关键技术和方法在此期间得以发展,包括:
- 统计学习方法:将语音识别视为统计学习任务。
- 关键技术:引入了em算法、n-gram等。
- 中大词表尝试:开始尝试中大词表的语音识别系统。
3.平稳发展期(1990-2000年代)
在这一阶段,gmm-hmm(高斯混合模型-隐马尔科夫模型)框架成为主导,语音识别系统得以进一步发展。主要进展包括:
- gmm-hmm框架:成为语音识别的主流框架。
- 上下文相关建模:声学建模开始考虑基于上下文相关的模型。
- n-gram语言模型:使用大量文本统计概率关系。
- 数据和任务复杂度增加:数据量和任务复杂度逐步增加。
- 判别式学习:引入区分性训练技术推动进步。
尽管技术不断进步,但语音识别的准确率在这一时期鲜有显著提升。
3.深度学习时代(2006年至今)
2006年是语音识别历史上的一个重要转折点,标志着深度学习技术的引入和广泛应用。在此之后,语音识别的准确率显著提升,主要特点包括:
- 深度神经网络(dnns):深度学习模型的应用大幅提升了语音识别的性能。
- 大规模数据和计算能力:利用更大的数据集和更强的计算能力进行训练。
- 持续改进:技术不断进步,推动语音识别系统向更高的准确率和更广泛的应用场景发展。
九.现代语音识别框架
现代语音识别框架主要分为两类:统计模型和端到端系统。
1.统计模型
统计模型的核心思想是通过计算最有可能的单词序列来进行语音识别。假设有一个声学特征向量(观测向量)的序列 x,表示一个单词序列 w,那么最有可能的单词序列可以通过以下公式计算得出:
w
^
=
arg
max
w
p
(
w
∣
x
)
\hat{w} = \arg\max_w p(w|x)
w^=argwmaxp(w∣x)
应用贝叶斯定理,这一公式可以进一步推导为:
p
(
w
∣
x
)
=
p
(
x
∣
w
)
p
(
w
)
p
(
x
)
∝
p
(
x
∣
w
)
p
(
w
)
p(w|x) = \frac{p(x|w)p(w)}{p(x)} \propto p(x|w)p(w)
p(w∣x)=p(x)p(x∣w)p(w)∝p(x∣w)p(w)
其中:
- p(x∣w) 是 声学模型,用于计算给定单词序列 w 下的声学特征向量 x的概率。
- p(w) 是 语言模型,用于计算单词序列 w的先验概率。
通过组合声学模型和语言模型,统计模型可以通过给定的声学特征向量 x获取最有可能的词序列。
现代的统计模型通常使用三大组件:
-
声学模型:用于计算声学特征向量的概率分布。
-
语言模型:用于计算单词序列的先验概率。
-
发音词典:提供单词与其发音之间的映射。
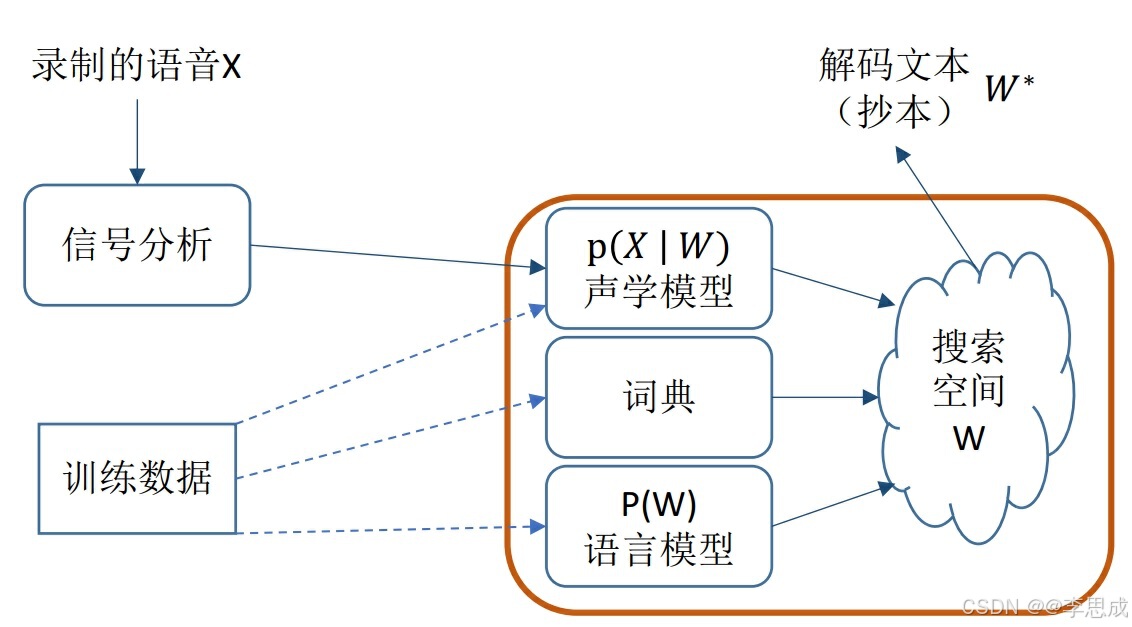
图片来源:https://www.shenlanxueyuan.com/course/381
2.端到端系统
端到端系统使用一个神经网络直接将输入的声学特征向量 x映射为词序列。这种方法简化了传统统计模型的复杂架构,避免了多个组件的独立优化和组合,具有以下特点:
- 直接映射:通过神经网络直接将声学特征向量转换为单词序列。
- 简化架构:省去声学模型、语言模型和发音词典的独立建模和组合。
- 统一训练:在一个训练过程中同时优化声学和语言模型的参数。
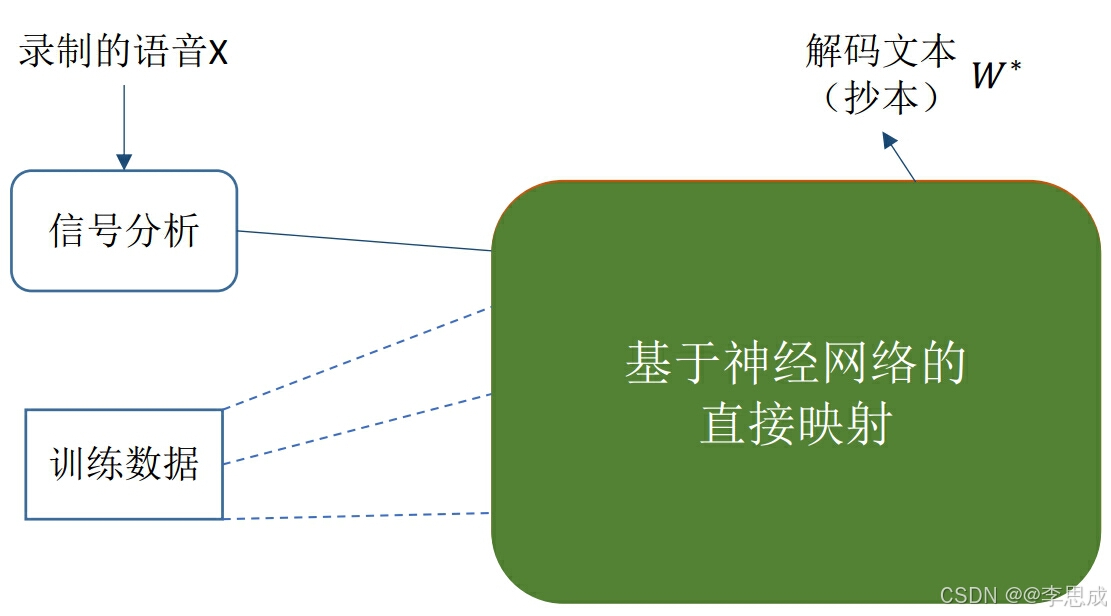
图片来源:https://www.shenlanxueyuan.com/course/381
十.语料库与工具包
1.英文数据
- timit:用于音素识别,由 ldc 管理版权。
- wsj:新闻播报语料库,由 ldc 管理版权。
- switchboard:电话对话语料库,由 ldc 管理版权。
- librispeech:有声读物语料库,包含 1000 小时的开源数据。 librispeech
- ami:会议语料库,开源数据。 ami
- ted-lium:ted 演讲语料库,开源数据。 ted-lium
- chime-4:平板远讲语料库,需要申请。
- chime-5/6:聚会聊天语料库,需要申请。
2.中文数据
- thchs-30:30 小时的开源语料库。 thchs-30
- hkust:150 小时的电话对话语料库,由 ldc 管理版权。
- aishell-1:178 小时的开源语料库。 aishell-1
- aishell-2:1000 小时的开源语料库,需申请。 aishell-2
- aidatatang_200zh:200 小时的开源语料库。 aidatatang_200zh
- magicdata:755 小时的开源语料库。 magicdata

发表评论