
目录
客户端环境准备:
尚硅谷资料包i中的文件复制到非中文路径
![]()
添加环境变量:
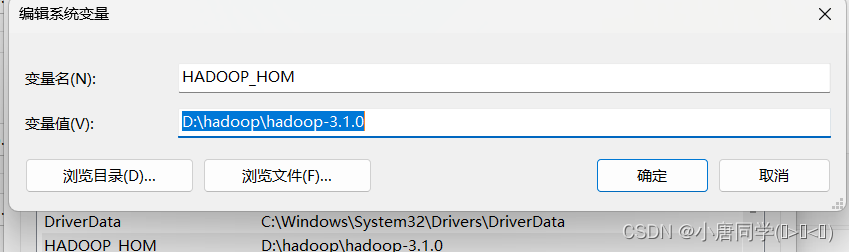
配置path环境变量:
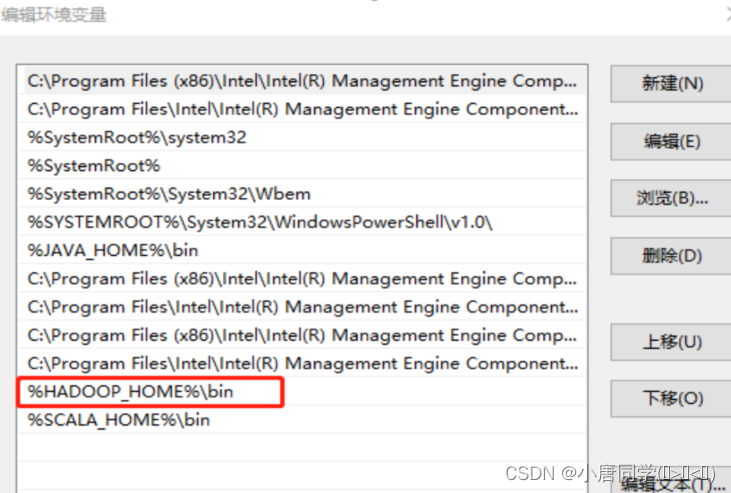
验证hadoop环境变量是否正常。双击winutils.exe,如果报如下错误。说明缺少微软运行库(正版系统往往有这个问题)。再资料包里面有对应的微软运行库安装包双击安装即可
idea操作:
新建maven项目工程
让后设置换你的maven库(换成你本机上的阿里,不然有些依赖你是下载不下来的,而且下载慢)
导入maven依赖
<?xml version="1.0" encoding="utf-8"?>
<project xmlns="http://maven.apache.org/pom/4.0.0"
xmlns:xsi="http://www.w3.org/2001/xmlschema-instance"
xsi:schemalocation="http://maven.apache.org/pom/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelversion>4.0.0</modelversion>
<groupid>org.example</groupid>
<artifactid>hdfsclient</artifactid>
<version>1.0-snapshot</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupid>org.apache.hadoop</groupid>
<artifactid>hadoop-client</artifactid>
<version>3.1.3</version>
</dependency>
<dependency>
<groupid>junit</groupid>
<artifactid>junit</artifactid>
<version>4.12</version>
</dependency>
<dependency>
<groupid>org.slf4j</groupid>
<artifactid>slf4j-log4j12</artifactid>
<version>1.7.30</version>
</dependency>
</dependencies>
</project>在项目的src/main/resources目录(该目录主要放置配置文件 ,页面文件 、静态资源文件)下,新建一个文件,命名为“log4j.properties”,该文件与日志相关,在文件中填入
log4j.rootlogger=info, stdout
log4j.appender.stdout=org.apache.log4j.consoleappender
log4j.appender.stdout.layout=org.apache.log4j.patternlayout
log4j.appender.stdout.layout.conversionpattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.fileappender
log4j.appender.logfile.file=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.patternlayout
log4j.appender.logfile.layout.conversionpattern=%d %p [%c] - %m%n创建包名:
com.xxx.hdfs
创建hdfsclient类
hdfs的api案例操作:
现在本人已经完成了部分api操作,先描述一下hdfsclient类的分布
因为hdfs的api操作会有很多冗余代码,所以我们对他进行了封装,
封装代码:
封装代码1:
这个代码主要是java连接集群,获取集群的配置文件,并且获取客户端连接对象,使用注解@before (不懂注解的可以看我的另一篇文章 点击直接跳转,在这不多做解释 )便于后续的使用
封装代码2:
这个代码主要用于关闭资源,就是把一个简单的close 进行了封装 使用注解 @after 同上不做解释,需要的话跳转另一篇文章
实现操作:
1.创建目录:
使用注解@test进行测试,调用的还是linux中的mkdir 让客户端连接对象进行调用(**注意 这里 客户端连接对象要在类的上方使用private进行定义,方便在下方方法中的调用)
@test
public void testmkdir() throws exception{
//此时window与namenode 节点的虚拟机已经连接成功 执行命令,创建文件夹
fs.mkdirs(new path("/xiyou"));
}2.上传文件
通过客户端远程访问hdfs 上传文件
copyfromlocalfile方法用于上传数据 参数1: 删除原数据 参数2: 是否允许覆盖(原文件存在) 参数3: 原数据路径(本地路径) 参数4:目的地路径
@test
public void testput() throws ioexception {
//参数1: 删除原数据 参数2: 是否允许覆盖(原文件存在) 参数3: 原数据路径(本地路径) 参数4:目的地路径
fs.copyfromlocalfile(false,true,new path("d:\\hadoop3.1.3.txt\\"),new path("hdfs://hadoop102/xiyou/huaguoshan"));
}3.文件下载
hdfs下载到window本地
copytolocalfile方法用于下载文件 参数解析 1:原文件是否删除 2.原文件hdfs的路径 3.目标地址路径 4. false 是开启crc校验 true 是不开启
@test
public void testget() throws exception {
// 参数解析 1:原文件是否删除 2.原文件hdfs的路径 3.目标地址路径 4. false 是开启crc校验 true 是不开启
fs.copytolocalfile(false,new path("hdfs://hadoop102/jinguo/shuguo.txt"),new path("d:\\jinchao"),false);
}4.文件的删除
文件的删除分为:删除非空目录,删除空目录
delete方法删除文件,当问及那非空的时候必须递归删除
fs.delete(new path("hdfs://hadoop102/xiyou"),true);delete删除空目录的时候可以不是递归删除
fs.delete(new path("/xiyou"));
整体代码:
@test
public void testrm() throws exception {
// 1. 要删除的路径 2 是否递归路径
fs.delete(new path("hdfs://hadoop102/xiyou"),true);
// 删除空目录 不需要递归
fs.delete(new path("/xiyou"));
// 删除非空目录 必须递归删除
}5.文件的移动
文件移动分为很多,根据参数的不同,做出不同的操作,都是调用rename方法
代码注释有详细解释
@test
public void testmv() throws ioexception {
// 对文件的移动 1.原文件路径 2.目标路径
// fs.rename(new path("/jinguo/shuguo.txt"),new path("/output"));
// 修改文件的名称
// fs.rename(new path("/output/shuguo.txt"),new path("/output/reshuguo.txt"));
//修改名称并且移动位置
// fs.rename(new path("/output/reshuguo.txt"),new path("/jinguo/shuguo.txt"));
// 目录更名
fs.rename(new path("/outputtwo"),new path("/output2"));
}6.查看hdfs上文件详情
查看hdfs上文件详情 比如
文件名称 权限 长度 块信息
@test
public void testlistfiles() throws ioexception {
//参数 1.需要查看文件的路径 2.是否递归
//返回迭代器 递归 相当于栈 后进先出 递归是从底层向上进行遍历 针对的是文件不是目录
// filestatus 返回的是数组
//listfiles 返回的是迭代器
remoteiterator<locatedfilestatus> listfiles = fs.listfiles(new path("/"), true);
while(listfiles.hasnext()) {
locatedfilestatus filestatus = listfiles.next();
system.out.println("======"+filestatus.getpath()+"=====");
system.out.println(filestatus.getpermission());
system.out.println(filestatus.getowner());
system.out.println(filestatus.getgroup());
system.out.println(filestatus.getlen());
system.out.println(filestatus.getmodificationtime());
system.out.println(filestatus.getreplication());
system.out.println(filestatus.getblocksize());
system.out.println(filestatus.getpath().getname());
//查看块的存储信息--(备份)存储在那几个服务器上
blocklocation[] blocklocations = filestatus.getblocklocations();
system.out.println(arrays.tostring(blocklocations));
}
}调用方法的解释:

先解释参数: 1.需要查看文件的路径 2.是否递归
返回值:返回的形式是迭代器(迭代器是一种设计模式,官方话不多数,说一下自己的理解可能不贴切---个人认为迭代器就像把数据封装成一个数据库一样,包含各种属性,每一条信息就是一个元组)
获取迭代器后就是迭代器的操作了
7.文件和文件夹的判断
文件和文件夹的判断也分为两种,一种是可迭代的,一种是不可迭代的
个人感觉还是使用迭代器进行递归判断操作方便一点
下边有两种 一种利用迭代器进行递归判断,一种是非递归判断
@test
public void testfile() throws ioexception {
//可迭代判断
remoteiterator<locatedfilestatus> locatedfilestatusremoteiterator = fs.listfiles(new path("/"), true);
while(locatedfilestatusremoteiterator.hasnext())
{
locatedfilestatus next = locatedfilestatusremoteiterator.next();
if (next.isfile()) {
system.out.println("这是文件"+next.getpath().getname());
}
else
{
system.out.println("这是目录"+next.getpath().getname());
}
}
// 不可迭代判断
// filestatus[] filestatuses = fs.liststatus(new path("/"));
// for (filestatus filestatus : filestatuses) {
// if (filestatus.isfile()) { //判断filestatus是否是文件
//
// system.out.println("这是文件"+filestatus.getpath().getname());
//
// }
// else
// {
// system.out.println("这是目录"+filestatus.getpath().getname());
// }

发表评论