1. spark 概述
1.1. 什么是 spark(官网:http://spark.apache.org)
spark 中文官网:http://spark.apachecn.org
spark 是一种快速、通用、可扩展的大数据分析引擎,2009 年诞生于加州大学伯克利分校amplab,2010 年开源,2013 年 6 月成为 apache 孵化项目,2014 年 2 月成为 apache
顶级项目。目前,spark 生态系统已经发展成为一个包含多个子项目的集合,其中包含sparksql、spark streaming、graphx、mllib 等子项目,spark 是基于内存计算的大数
据并行计算框架。spark 基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将 spark 部署在大量廉价硬件之上,形成集群
1.2. spark 和 hadoop 的比较
mapreduce 读 – 处理 - 写磁盘 – 读 - 处理 - 写
spark 读 - 处理 - 处理 --(需要的时候)写磁盘 - 写
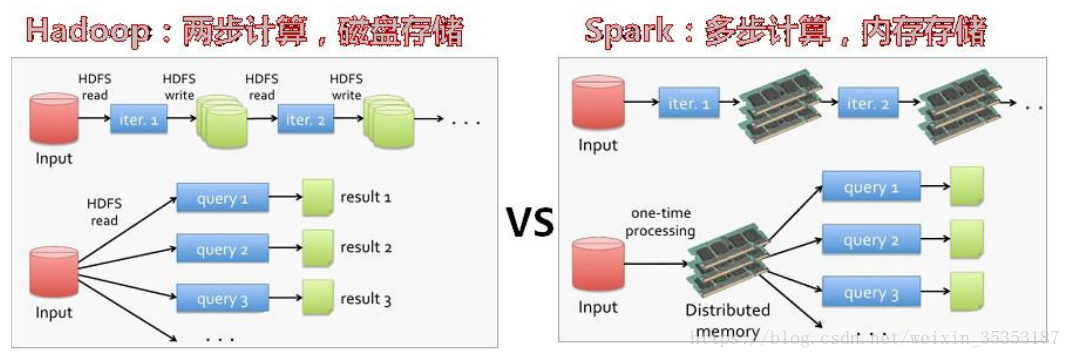
spark 是在借鉴了 mapreduce 之上发展而来的,继承了其分布式并行计算的优点并改进了 mapreduce 明显的缺陷,(spark 与 hadoop 的差异)具体如下:
首先,spark 把中间数据放到内存中,迭代运算效率高。mapreduce 中计算结果需要落地,保存到磁盘上,这样势必会影响整体速度,而 spark 支持 dag 图的分布式并行计算的编程框架,减少了迭代过程中数据的落地,提高了处理效率。(延迟加载)
其次,spark 容错性高。spark 引进了弹性分布式数据集 rdd (resilient distributeddataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即允许基于数据衍生过程)对它们进行重建。另外在rdd 计算时可以通过 checkpoint 来实现容错。
最后,spark 更加通用。mapreduce 只提供了 map 和 reduce 两种操作,spark 提供的数据集操作类型有很多,大致分为:transformations 和 actions 两大类。transformations包括 map、filter、flatmap、sample、groupbykey、reducebykey、union、join、cogroup、mapvalues、sort 等多种操作类型,同时还提供 count, actions 包括 collect、reduce、lookup 和 save 等操作
支持的运算平台,支持的开发语言更多。
spark 4 种开发语言:
scala,java,python,r
总结:spark 是 mapreduce 的替代方案,而且兼容 hdfs、hive,可融入 hadoop 的生态系统,以弥补 mapreduce 的不足。
1.3. spark 特点
1.3.1. 快
与 hadoop 的 mapreduce 相比,spark 基于内存的运算要快 100 倍以上,基于硬盘的运算也要快 10 倍以上。spark 实现了高效的 dag 执行引擎,可以通过基于内存来高效处理数据流。
官网截图:

1.3.2. 易用
spark 支持 java、python 和 scala 和 r 的 api,还支持超过 80 种高级算法,使用户可以快速构建不同的应用。而且 spark 支持交互式的 python 和 scala 的 shell,可以非常方便地在这些 shell 中使用 spark 集群来验证解决问题的方法

1.3.3. 通用
一站式解决方案 离线处理 实时处理(streaming) sql,spark 提供了统一的解决方案。spark 可以用于批处理、交互式查询(spark sql)、实时流处理(spark streaming)、机器学习(spark mllib)和图计算(graphx)。这些不同类型的处理都可以在同一个应用中无缝使用。spark 统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。
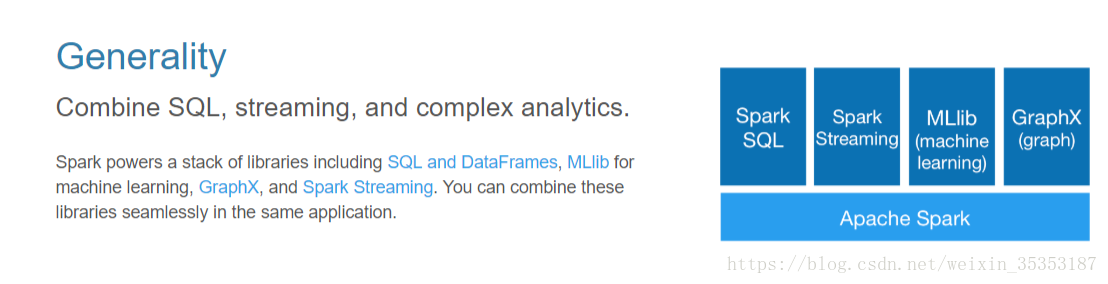
1.3.4. 兼容性
spark可以非常方便地与其他的开源产品进行融合。比如,spark可以使用hadoop的yarn和 apache mesos 作为它的资源管理和调度器,并且可以处理所有 hadoop 支持的数据,包括 hdfs、hbase 和 cassandra 等。这对于已经部署 hadoop 集群的用户特别重要,因为不需要做任何数据迁移就可以使用 spark 的强大处理能力。spark 也可以不依赖于第三方的资源管理和调度器,它实现了 standalone 作为其内置的资源管理和调度框架,这样进一步降低了 spark 的使用门槛,使得所有人都可以非常容易地部署和使用 spark。此外,spark 还提供了在 ec2 上部署 standalone 的 spark 集群的工具。

1.4 spark 的部署模式:
1, local 本地模式,只要机器上有 spark 的安装包, 仅仅是用于测试不写 master – master local 一个线程 local[2] local[*] 模拟使用多个线程
2, standalone spark 自带的集群模式 --master spark://hdp-01:7077
3, yarn 把 spark 任务,运行在 yarn --master yarn
4, mesos 把 spark 任务,运行在 mesos 资源调度平台上 --master mesos






发表评论