本文综合整理单目3d目标检测的方法模型,包括:基于几何约束的直接回归方法,基于深度信息的方法,基于点云信息的方法。万字长文,慢慢阅读~
直接回归方法 涉及到模型包括:monocon、monodle、monoflex、cupnet、smoke等。
基于深度信息的方法 涉及到模型包括:mf3d、monogrnet、d4lcn、monopsr等。
基于点云信息的方法 涉及到模型包括:pseudo lidar、dd3d、caddn等。
目录
一、单目3d目标检测概述
1.1 简介
3d目标检测,只用一个相机实现。输入是图像数据,输出是物体的三维尺寸、三维位置、朝向等3d信息。

1.2 单目相机特征
通过传感器采样和量化,将3d世界中的物体变换到2d空间,用单个或多个通道的二维图像来描绘物体的形状、颜色、纹理和轮廓等信息,这些信息可用于检测物体。
1.3 为什么用单目做3d目标检测
由于2d相机比复杂的3d采集传感器更便宜且更灵活,基于单目图像的方法已得到广泛研究。二维图像以像素的形式提供了对象丰富的颜色和纹理信息。
激光雷达相对高昂的造价和对各种复杂天气情况的敏感性,推动着研究人员开始更多地探索基于视觉的3d目标检测,其在近几年成为越来越热门的研究方向。
基于单目视觉的方法则要求更加严苛,即只有单个相机的图像作为输入,结合相机标定得到物体的三维检测。
这类方法难度较大,但成本极低、便于推广使用,一旦攻克此问题,将彻底颠覆自动驾驶行业的格局。因此,研究此类问题是极具应用价值和学术挑战性的。
1.4 3d边框表示方式
3d边框表示目标的位置、尺寸和方向,是3d目标检测算法的输出。物体是否被遮挡、截断或具有不规则的形状,都用一个紧密边界的立方体包围住被检测到的目标。
3d边框编码方式主要有3种,分别是8角点法、4角2高法、7参数法(常用),如下图所示。
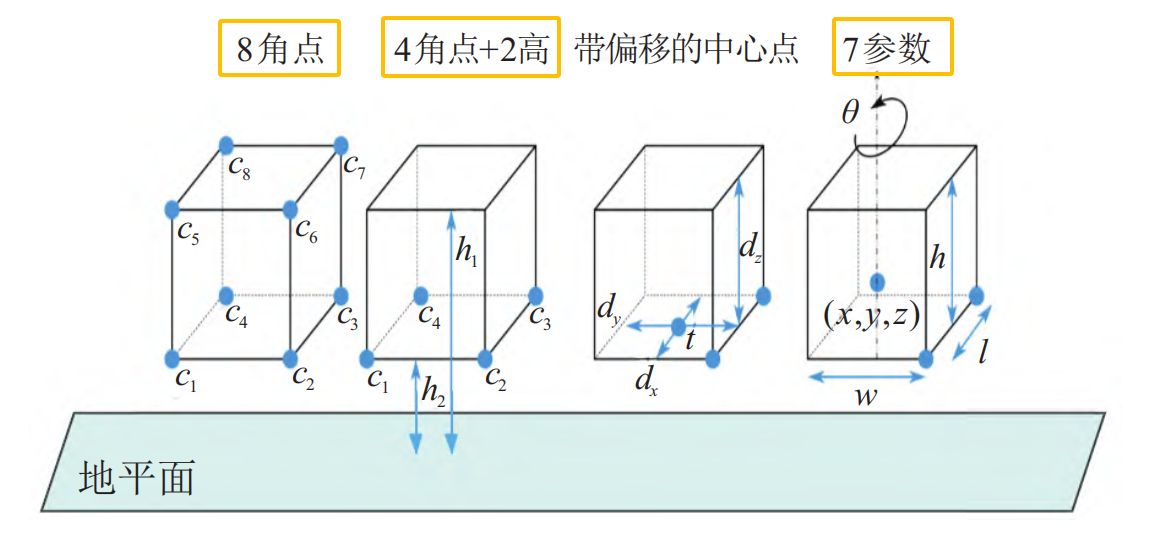
7参数法:由7个坐标参数来表示。它包括边框的中心位置(x, y, z),边框在三维空间中的尺寸(l, w, h)以及表示角度的偏航角θ。
8角点法:8角点法将3d边框通过连接8个角点(c1, c2, . . . , c8)来形成。每一个角点由三维坐标(x, y, z)表示,总计24维向量。
4角2高法:为了保持地面目标的物理约束,3d框的上角需要保持与下角对齐,提出了一种4角2高编码的方法。
4 个角点 (c1, c2, c3, c4) 表示3d边框底面的4个顶点,每个角点用2d坐标(x, y)表示。
两个高度值(h1, h2)表示从地平面到底部和顶部角的偏移量。根据4个角点计算出4个可能的方向,并选择最近的一个作为方向向量。
1.5 挑战
由于是单张图像,是2d维度的,没有深度信息;3d框的中心点在图像中位置,模型难以精准预测出来。
2d图像的缺点是缺乏深度信息,这对于准确的物体大小和位置估计(尤其是在弱光条件下)以及检测远处和被遮挡的物体,难以检测。
二、直接回归的方法
基于直接回归的方法。主要有monocon、monodle、monoflex、cupnet、smoke、 monopair、 deviant等算法。
这些算法主要利用几何先验知识,和深度估计的不确定性建模来提高算法性能。
anchor based(基于锚框)
deep3dbbox算法,利用2d检测框和几何投影,并预测物体3d位姿和尺寸,通过求解目标中心到相机中心的平移矩阵,使预测的3d检测框重投影中心坐标与2d检测框中心坐标的误差最小。
monodis算法,利用解耦的回归损失代替之前同时回归中心点、尺寸和角度的损失函数,该损失函数将回归部分分成k 组,通过单独回归参数组来解决不同参数之间的依赖关系,有效避免了各参数间误差传递的干扰,使得训练更加稳定。
预先对全部场景给出了各类目标的锚框,即anchor-based。这种方法在一定程度上能够解决目标尺度不一和遮挡问题,提高检测精度,但缺乏效率性且很难枚举所有的方向,或为旋转的目标拟合一个轴对齐的包围框,泛化能力欠缺些。
anchor free(不用锚框)
anchor free 抛弃了需要生成的复杂锚框, 而是通过直接预测目标的角点或中心点等方法来形成检测框。
rtm3d算法,直接预测3d框的8个顶点和1个中心点,然后通过使用透视投影的几何约束估计3d边框。
smoke算法,舍弃了对2d边界框的回归,通过将单个关键点估计与回归的三维变量,来预测每个检测目标的3d框。设计了基于关键点的3d检测分支并去除了2d检测分支。
monoflex算法,设计了解耦截断目标和正常目标的预测方法,通过组合基于关键点的深度和直接回归深度进行精确的实例度估计。
gupnet算法,利用几何不确定性投影模块解决几何投影过程的误差放大问题,并提出了分层任务学习来解决多任务下参数的学习问题。
monodle算法,进行了一系列的 实验,发现了定位误差是影响单目3d目标检测模型性能的关键因素。因此,monodle改进了中心点的取法,采用了从3d投影中心而不是2d边界框中心获取中心点的方法, 以提高模型性能。此外,在实例深度估计任务上,monodle采用了不确定性原理对实例深度进行估计。
monocon算法,在monodle算法的基础上添加了辅助学习模块,提升了模型的泛化能力。
deviant算法,提出深度等变性网络来解决现有神经网络模块在处理3d空间中的任意平移时缺乏等变性的问题。
这一类基于直接回归的方法,仅使用单目图像完成模型训练与推理。
下面选一些实时性好的模型,进行详细讲解。
2.1 smoke【cvpr2020】
smoke是一种实时单目 3d 物体检测器,它提出了一个基于关键点预测的,一阶段单目3d检测框架,去掉了2d框预测部分,直接预测目标的3d属性信息。

输入单张图像。
输出其中每个目标的类别、3d边界框用7个参数表示(h、w、l、x、y、z、θ)
- (h、w、l) 表示目标的高度、宽度和长度;
- (x、y、z) 表示目标中心点在相机坐标系下的坐标;
- θ 表示目标的航向角。

论文名称:smoke: single-stage monocular 3d object detection via keypoint estimation
论文地址:https://arxiv.org/pdf/2002.10111.pdf
开源地址:github - lzccccc/smoke: smoke: single-stage monocular 3d object detection via keypoint estimation
smoke 整体框架,如下图所示。输入图像经过dla-34 backbone进行特征提取。检测头主要包含两个分支:关键点分支和3d边界框回归分支。
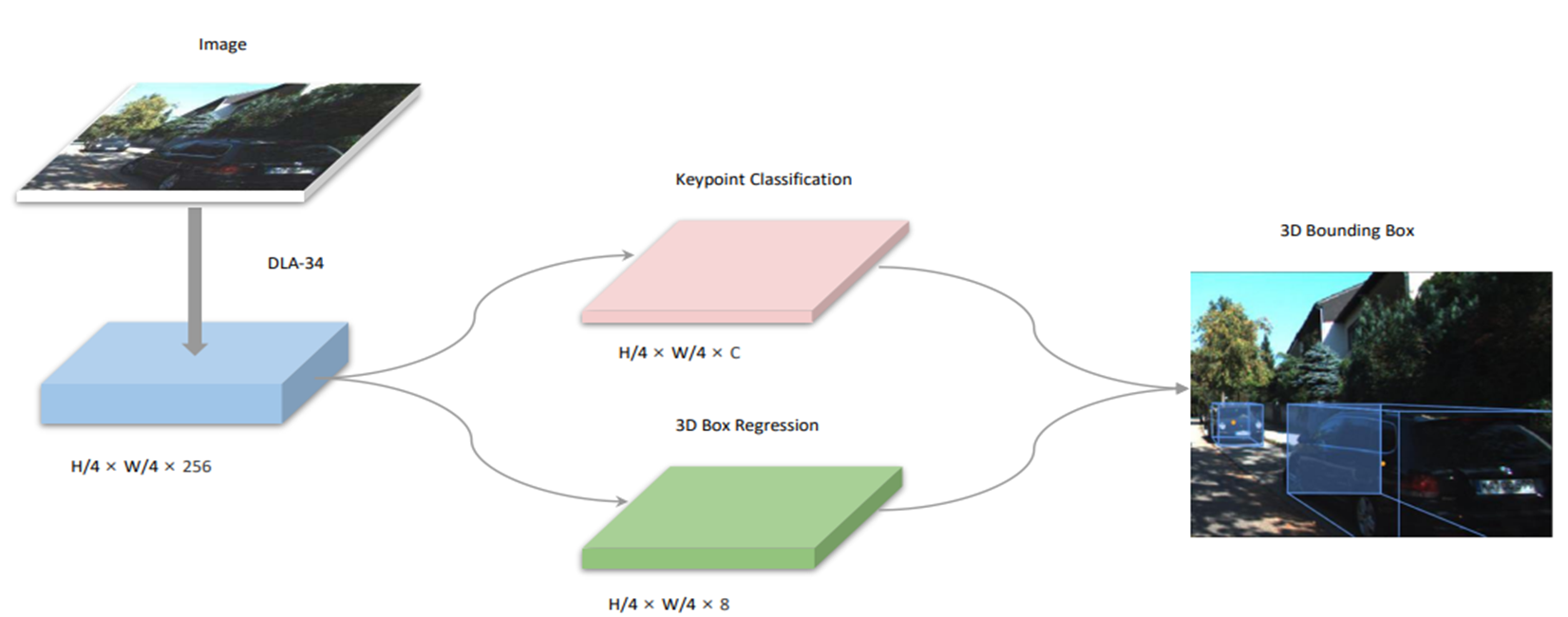
smoke的backbone(主干网络):
- deep layer aggregation,dla-34网络(基础)
- deformable convolutional ,可变形卷积(改进点)
- group normbalization,组归一化(改进点)
检测头部分:
- 关键点检测分支
- 3d边界框回归分支
在关键点分支中,图像中的每一个目标用一个关键点进行表示。 这里的关键点被定义为目标3d框的中心点在图像平面上的投影点,而不是目标的2d框中心点。

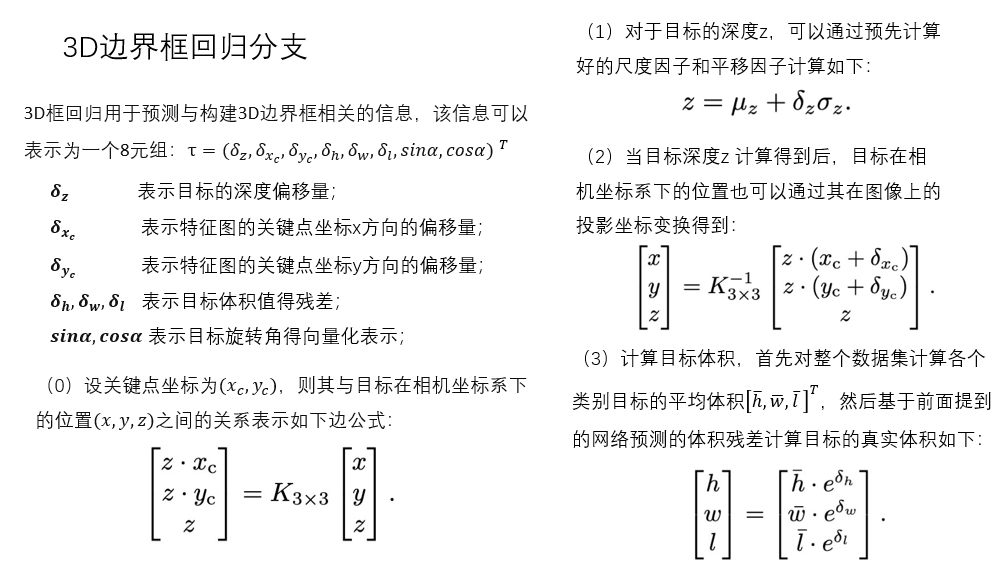
3d边界框回归分支中,

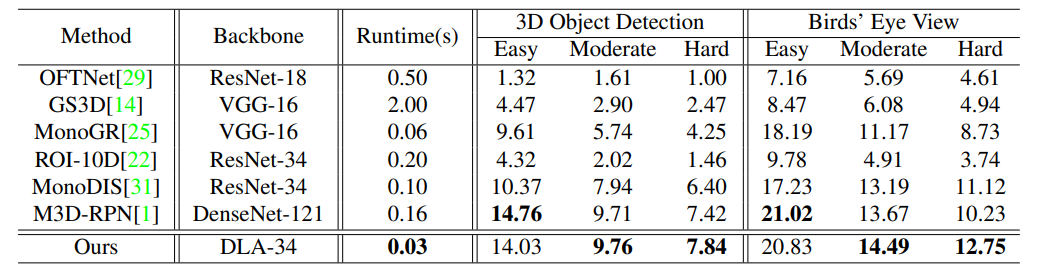
在kitti 数据集test中测试,car类别的模型精度。
模型效果:



这里只是简单讲了一下,详细讲解看我这篇博客:
【论文解读】smoke 单目相机 3d目标检测(cvpr2020)_相机smoke-csdn博客

环境搭建和模型训练参考这篇博客:单目3d目标检测——smoke 环境搭建|模型训练_一颗小树x的博客-csdn博客
模型推理和可视化参考这篇博客:单目3d目标检测——smoke 模型推理 | 可视化结果-csdn博客
2.2 monodle(cvpr2021)
monodle作为一个延续centernet框架的单目3d检测器,在不依赖dcn的情况下获得了较好的性能,可以作为baseline。
monodle和smoke有些像,都是单目实现3d目标检测,通过几何约束和回归3d框信息,得到3d框的中心点、尺寸、朝向,但是它反驳了smoke提出的2d检测对3d检测没有帮助的论点。

开源地址:https://github.com/xinzhuma/monodle
论文地址:【cvpr2021】delving into localization errors for monocular 3d object detection
论文核心观点,主要包括为三点:
- 2d box中心点与投影下来的3d box中心点,存在不可忽视的差异,优先使用3d box投影下来的中心点。
- 较远目标,会带偏模型训练;在训练时,可以过滤这些过远的物体标签。
- 提出了一种面向 3d iou 的损失,用于对象的大小估计,不受“定位误差”的影响。
monodle是基于centernet框架,实现单目3d检测的。模型结构如下:
backbone:dla34
neck:dlaup
2d 框检测:3个分支
- 分支一 通过输出heatmap,预测2d框中心点的粗略坐标,以及类别分数。(centernet用的是标签中2d框中心作为gt值来监督,monodle采用了3d投影坐标作为粗坐标的监督)
- 分支二 预测的2d框中心点粗坐标与真实坐标之间的偏移。
- 分支三 预测2d框的size。
3d detection:4个分支
- 分支一 预测2d框中心点粗坐标的深度值。
- 分支二 预测2d框中心点粗坐标与真实的3d投影坐标之间的偏移。
- 分支三 预测3d框的size。
- 分支四 预测偏航角。
模型结构如下图所示:
monodle的损失由7部分组成,
- 分类损失:focal loss
- 2d 中心点损失:l1 loss
- 2d size损失:l1 loss
- 3d 深度估计损失:
- 3d 中心点损失:l1 loss
- 3d heading angle:multi-bin loss
- 3d size:普通的l1 loss & monodle提出的 iou loss
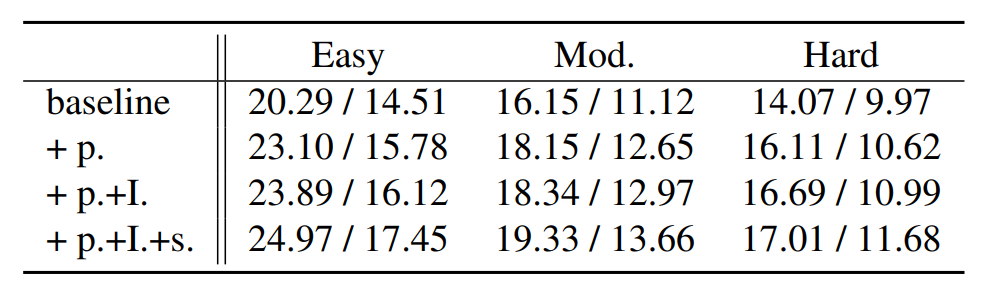
在kitti验证集做实验,评价指标为car类别的ap40(bev / 3d)
- p 表示使用3d 投影中心作为粗中心坐标的监督
- i 表示使用对3d size估计的iou oriented optimization
- s 表示忽略远距离目标
模型预测效果:

用蓝色、绿色和红色的方框来表示汽车、行人和骑自行车的人。激光雷达信号仅用于可视化。

这里只是简单讲了一下,详细讲解看我这篇博客:【论文解读】单目3d目标检测 monodle(cvpr2021)-csdn博客

monodle 模型训练 | 模型推理参考这篇博客:
单目3d目标检测——monodle 模型训练 | 模型推理-csdn博客
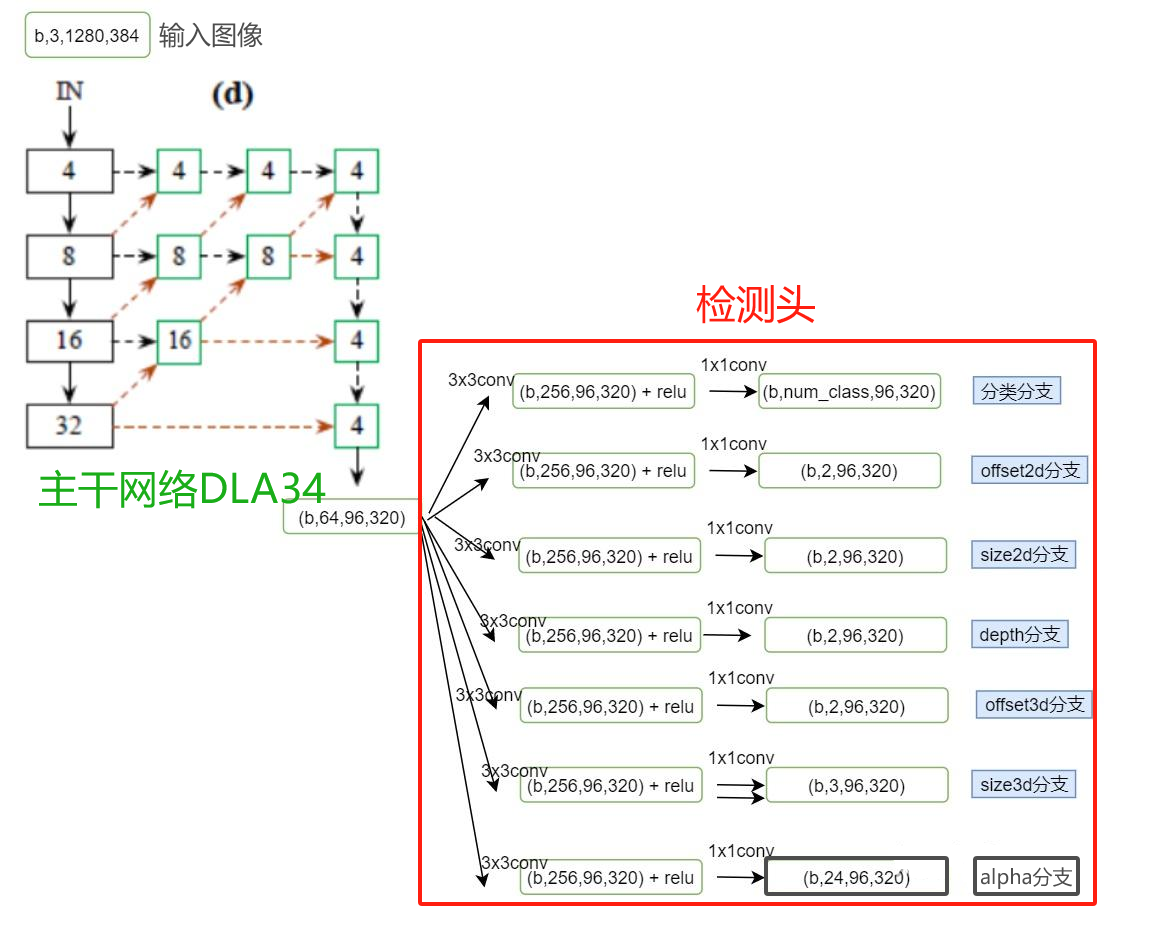
2.3 monocon(aaai2022)
monocon是一个延续centernet框架的单目3d检测器,在不依赖dcn的情况下获得了较好的性能,并且融入了辅助学习,提升模型性能。
曾经在kitti 单目3d目标检测上,霸榜了一段时间。

monocon和monodle很像,在它基础上添加了一些辅助分支检测头,促进网络学习特征的能力。
开源地址(官方):https://github.com/xianpeng919/monocon
开源地址(pytorhc):https://github.com/2gunsu/monocon-pytorch
论文地址:learning auxiliary monocular contexts helps monocular 3d object detection
论文核心观点,主要包括为两点:
- 带注释的3d 边界框,可以产生大量可用的良好投影的 2d 监督信号。
- 使用辅助学习,促进网络学习特征的能力。
monocon是基于centernet框架,实现单目3d检测的。模型结构如下:
backbone:dla34
neck:dlaup
常规3d框检测头:5个分支
- 分支一 通过输出heatmap,预测2d框中心点的粗略坐标,以及类别分数。
- 分支二 预测2d框中心点粗坐标与真实的3d投影坐标之间的偏移。
- 分支三 预测2d框中心点粗坐标的深度值,和其不确定性。
- 分支四 预测3d框的尺寸。
- 分支五 预测观测角。
辅助训练头:5个分支
- 分支一 8个投影角点和3d框的投影中心。
- 分支二 8个投影角点到2d框中心的offsets。
- 分支三 2d框的尺寸。
- 分支四 2d框中心量化误差建模。
- 分支五 8个投影角点量化误差建模。
模型结构如下图所示:

monocon的损失由10部分组成,
常规3d框检测头:5个分支
- 分支一 heatmap 类别分数,使用focalloss。2d 中心点损失,使用l1 loss。
- 分支二 2d框中心点粗坐标与真实的3d投影坐标之间的偏移,使用l1 loss。
- 分支三 2d框中心点粗坐标的深度值,和其不确定性,使用laplacian aleatoric uncertainty loss。(monopair & monodle & monoflex & gupnet)
- 分支四 预测3d框的尺寸,使用dimension-aware l1 loss(monodle)。
- 分支五 预测观测角,multi-bin loss,其中分类部分使用 crossentropyloss,回归部分使用 l1 loss。
辅助训练头:5个分支
- 分支一 8个投影角点和3d框的投影中心,使用focalloss。
- 分支二 8个投影角点到2d框中心的offsets,使用l1 loss。
- 分支三 2d框的尺寸,使用l1 loss。
- 分支四 2d框中心量化误差建模。
- 分支五 8个投影角点量化误差建模。
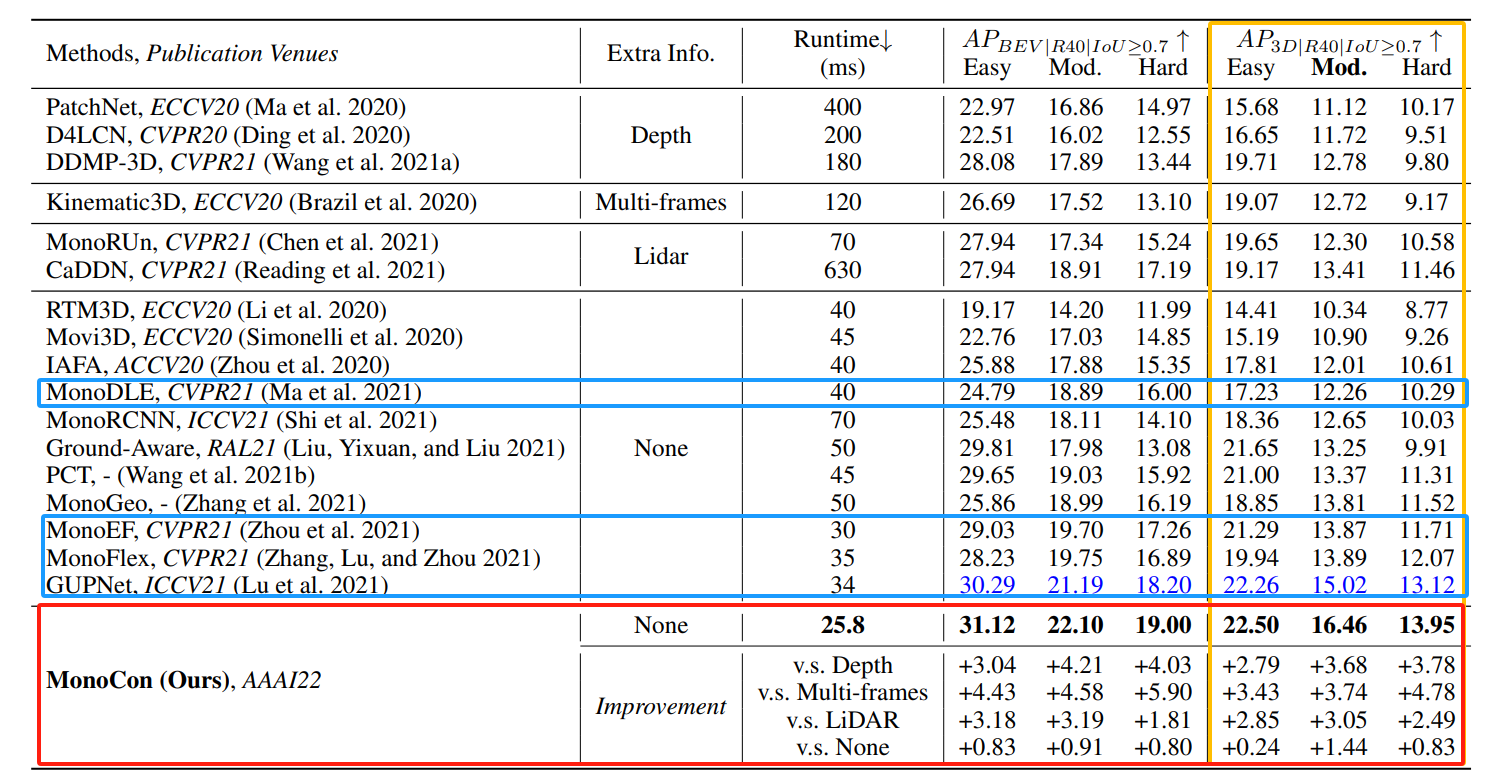
论文于kitti 官方测试集中“汽车类别”的最先进方法进行比较,使用单个2080ti gpu显卡测试的。
下表中由bev和3d的测试结果,monocon运行时间和精度都是top 级别的。
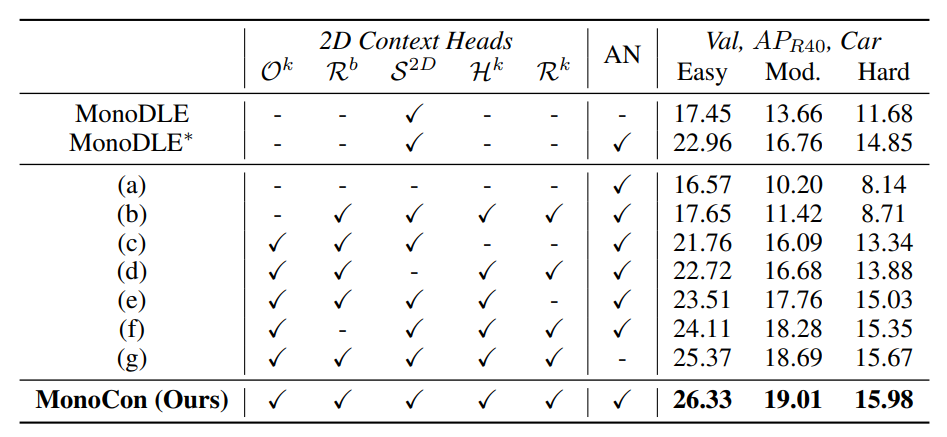
作者基于monodle进行了对比实验,分析5个辅助训练分支,和把bn归一化换为an归一化,对模型精度的影响。
模型预测效果:

下面是单目3d目标检测的效果,激光雷达点云数据仅用于可视化。

在前视图图像中,预测结果以蓝色显示,而地面实况以橙色显示。
分别显示2d框、3d框、bev的检测效果:



这里只是简单讲了一下,详细讲解看我这篇博客:【论文解读】单目3d目标检测 monocon(aaai2022)-csdn博客

monocon 模型训练和模型推理参考这篇博客:单目3d目标检测——monocon 模型训练 | 模型推理-csdn博客
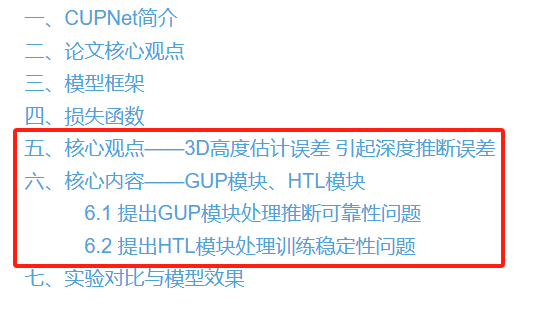
2.4 cupnet(iccv 2021)
cupnet是基于几何约束和回归方式输出3d框信息,在不依赖dcn的情况下获得了较好的性能。

它也是一款两阶段的单目3d检测器,先回归2d框信息,在roi区域进一步提取特征,生成3d框信息。
论文地址:geometry uncertainty projection network for monocular 3d object detection
论文核心观点,主要包括为两点:
- 1、物体高度估计误差,对深度计算有着较大的影响。
- 2、模型训练的稳定性。在模型训练初期,物体高度的预测往往存在较大偏差,也因此导致了深度估算偏差较大。较大误差往往导致网络训练困难,从而影响整体网络性能。
- 3、推断可靠性问题。如果物体的高度预测存在较大偏差,相应计算出的深度值也会存在较大误差。
cupnet是一个两阶段的框架,实现单目3d检测的。模型结构如下:
backbone:dla34
neck:dlaup
第一部分 2d 检测:3个分支
- 分支一 通过输出heatmap,预测所有类别的中心点(默认类别为3)。
- 分支二 预测的2d框中心点的偏移。
- 分支三 预测2d框的size。
第二部分 3d 检测:4个分支
- 分支一 预测偏航角。
- 分支二 预测3d框的size。
- 分支三 预测中心点的深度值,和和其不确定性(深度学习偏差)。
- 分支四 预测2d框中心点与真实的3d投影坐标之间的偏移。
模型结构如下图所示:(基于centernet的2d检测+roi特征提取+基础3d检测头)
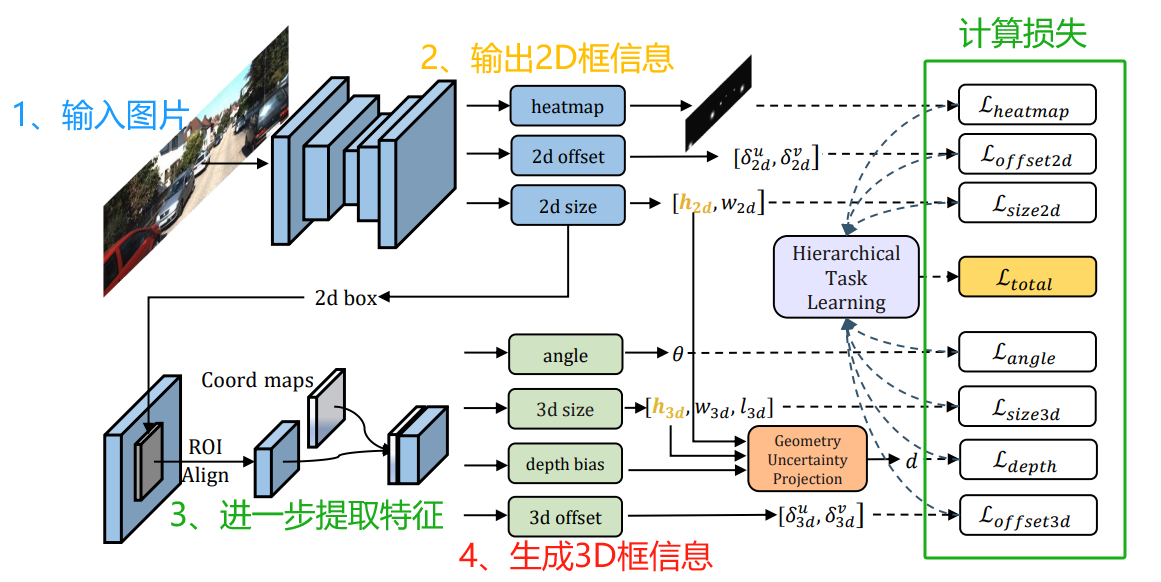
整体的模型结构,可分为4步:
- 输入图像,经过主干网络提取特征。
- 基于centernet的2d框预测部分,用于输出热力图,信息包括:2d中心点、偏移量、2d框的尺寸。
- 提取出roi的特征。
- 利用所提取的roi特征,输入到不同的网络头,以获得物体3d框信息,包括:偏转角度、尺寸、深度值、物体3d框中心在图像投影点的偏移量。
在第四步时,首先估计出3d框除了“深度值”以外的所有参数,然后2d框与3d框的高度将被输入到gup模块中,提取出最终的depth。
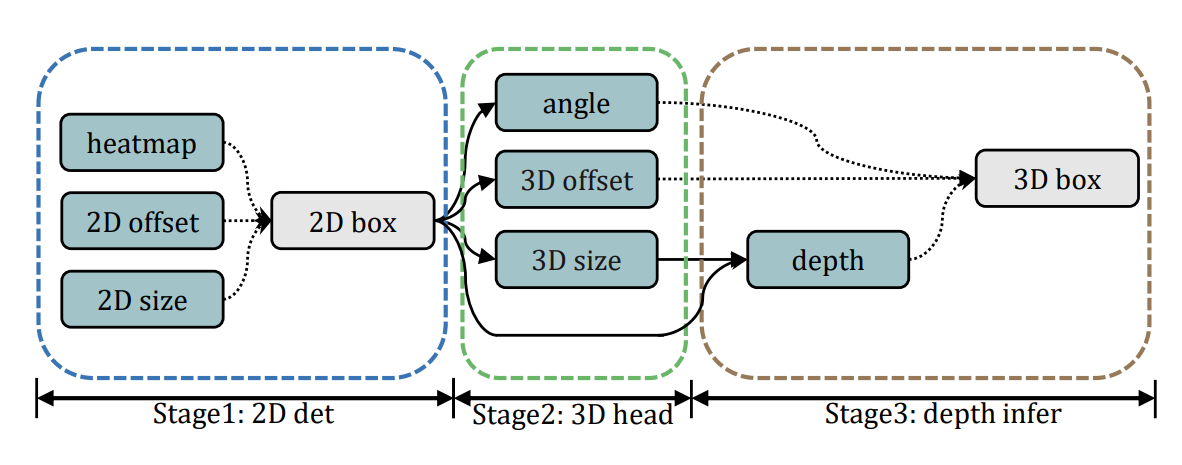
cupnet 的损失由7部分组成,
2d 框检测损失:3部分
- 分支一 通过输出heatmap,预测所有类别的中心点;使用 focal loss 函数。
- 分支二 预测的2d框中心点的偏移;使用 l1 loss 函数。
- 分支三 预测2d框的size;使用 l1 loss 函数。

3d detection损失:4部分
- 分支一 预测偏航角。类别使用交叉熵损失,偏航角使用l1 loss。
- 分支二 预测3d框的size。长和宽为l1 loss,权重占2/3,3d 高使用laplacian_aleatoric_uncertainty_loss() 函数,权重占1/3。
- 分支三 预测中心点的深度值,和和其不确定性;使用 laplacian_aleatoric_uncertainty_loss() 函数。
- 分支四 预测2d框中心点与真实的3d投影坐标之间的偏移;使用 l1 loss 函数。

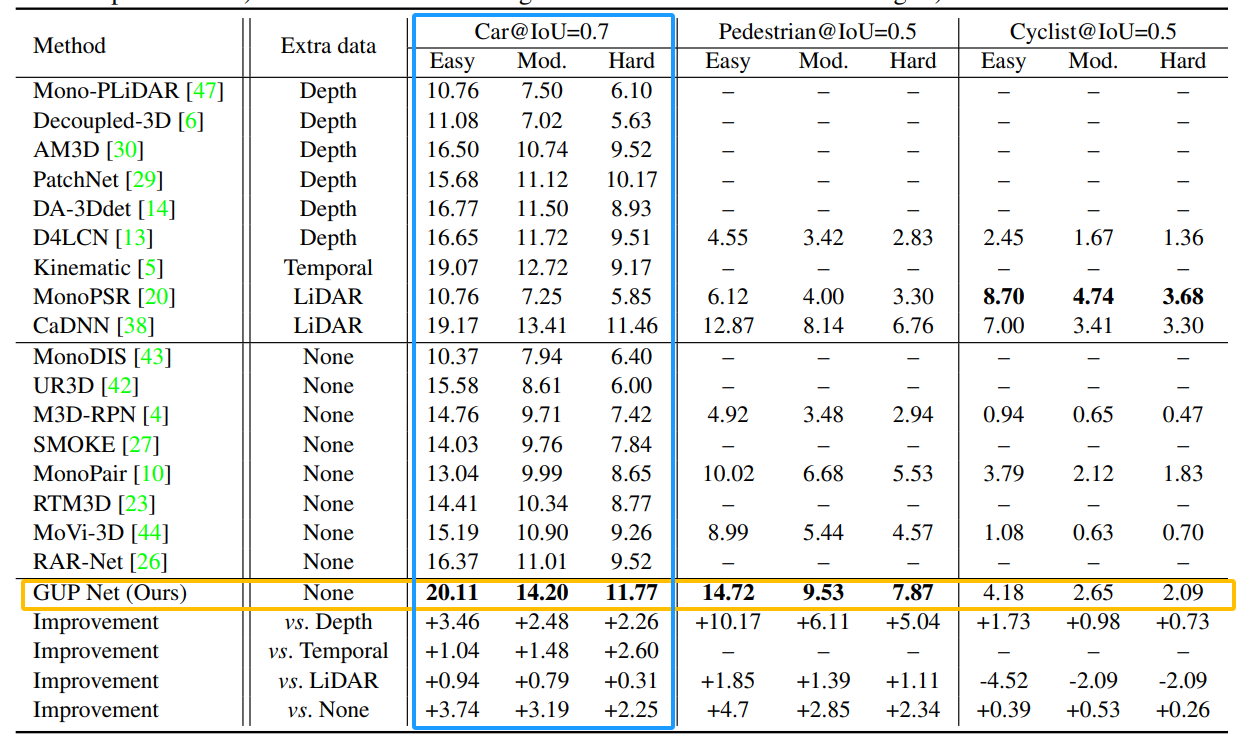
在kitti 测试集上的 3d物体检测,用以粗体突出显示最佳结果
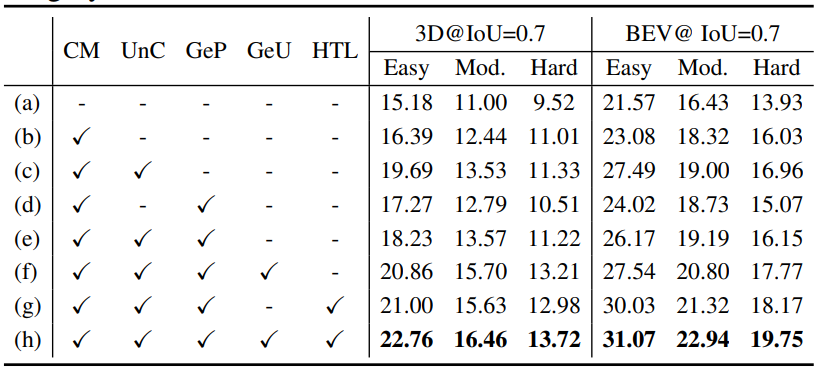
在kitti 验证集,汽车类别,进行消融实验:
模型效果:


这里只是简单讲了一下,详细讲解看我这篇博客:【论文解读】单目3d目标检测 cupnet(iccv 2021)-csdn博客
2.5 monoflex(cvpr 2021)
monoflex是一种端到端、单阶段的单目3d目标检测方法,它基于centernet框架结合几何约束,回归方式输出3d框信息。
它优化了被截断物体的3d检测,同时优化了中心点的深度估计,检测速度也比较快。

论文地址:objects are different: flexible monocular 3d object detection
论文核心观点,主要有3点组成:
- 1、有截断的物体和正常的物体要分开处理,提出了截断目标预测的解耦方法。主要体现在:截断的中心点选取差异。
- 2、深度估计中同时考虑:关键点估计的几何深度、直接回归深度,然后两者做加权结合。
- 3、边缘特征提取和融合,单独把边沿的像素拿出来做注意力特征提取,提高offset和heat map的精度。
monoflex是一个单阶段的框架,实现单目3d检测的模型结构如下:
backbone:dla34
neck:fpn
head:由四部分组成
第一部分,预测2d框中心点。
- 通过输出heatmap,预测所有类别的中心点(默认类别为3)。
- 这部分加入了edge fusion,增强边缘的中心点预测。
第二部分,预测中心点的偏差。
- 对于正常物体,预测2d框中心点与3d框投影坐标之间的偏差。
- 对于截断物体,预测2d框中心,和3d框中心投影点与图像边沿之间交点的偏差。(下面详细讲)
第三部分,预测常规的信息。
- 2d框宽高。
- 3d方向。
- 3d尺寸。
第四部分,预测深度信息。
- 深度信息1:模型直接归回的深度信息。
- 深度信息2:通过关键点和几何约束,计算出来的深度信息。估计一共10个关键点:3d框8个顶点和上框面、下框面在图片中的投影到x_r的offset;然后通过相机模型计算深度。
- 深度信息融合,把几何深度、直接回归深度,然后两者做加权结合。
模型结构如下图所示:

补充一下edge fusion模块:
为了提高截断物体的中心点检测,提出了边缘特征提取和融合,单独把边沿的像素拿出来做注意力特征提取,提高offset和heat map的精度。
- 模块首先提取特征映射的四个边界,将其连接到边缘特征向量中。
- 然后由两个1*1 conv处理,以学习截断对象的唯一特征。
- 最后,将处理的向量重新映射到四个边界,并添加到输入特征图。
在热图预测中,边缘特征可以专门用于预测外部对象的边缘热图,从而使内部对象的位置不被混淆。
monoflex 的损失由6部分组成:
- 2d框中心点损失,通过输出heatmap,预测所有类别的中心点;使用 focal loss 函数。
- 2d框尺寸损失,使用 l1 loss 函数。
- 3d框中心点与2d框中心点的偏差损失,使用 l1 loss 函数。
- 3d朝向角损失,使用multibin 函数。
- 3d尺寸损失,使用 l1 loss 函数。
- 深度信息损失,包括直接回归损失和关键点损失。
在kitti 验证/测试集上的实验,选择car类别。模型精度高,实时性好。

模型检测效果:

在截断物体的检测效果:

这里只是简单讲了一下,详细讲解看我这篇博客:【论文解读】单目3d目标检测 monoflex(cvpr 2021)-csdn博客

三、基于深度信息方法
基于深度信息引导的方法。这类算法利用单目深度估计模型预先得到像素级深度图,将深度图与单目图像结合后输入检测器。
考虑工程落地和模型精度速度,这类方法不会细讲~
mf3d算法,通过子网络生成深度图,并将目标感兴趣区域与深度图进行融合以回归目标3d位置信息。
monogrnet算法,引入一种全新的实例深度估计算法,利用稀疏监督预测目标3d边框中心的深度。不同于mf3d生成整个输入图像的深度图方法,该方法只对目标区域进行深度估计,避免了额外的计算量。
d4lcn算法,一种局部卷积神经网络,通过自动学习基于深度图中的卷积核及其接受域,克服了传统二维卷积无法捕获物体多尺度信息的问题。
monopsr算法,用相机成像原理计算图像中像素尺寸,与3d空间之间的比例关系,估计目标的深度位置信息。
许多单目3d目标检测算法将这些深度估计算法视为其自身网络的子模块。深度估计可以弥补单目视觉的不足,更准确地检测物体的三维信息。
四、基于点云信息方法
虽然深度信息有助于3d场景的理解,但简单地将其作为rgb 图像的额外通道,并不能弥补基于单目图像的方法和基于点云的方法之间的性能差异。
基于点云信息引导的方法。这类算法借助激光的雷达点云信息作为辅助监督进行模型训练,在推理时只需输入图像和单目相机信息。
pseudo lidar算法,采用单目深度估计算法dorn进行深度估计, 将得到的像素深度反投影为3d点云, 从而形成了伪激光点云数据。最后利用已有的基于点云的检测算法frustum
pointnets进行3d框检测。
pseudo-lidar++算法,在初始深度估计的指导下,将测量数据分散到整个深度图中以提高检测精度。并利用更加便宜的4线激光雷达来代替64线激光雷达以微调检测结果。
caddn算法,通过将深度分类来生成视锥特征,并通过相机参数进一步转化为体素特征,并完成bev特征生成和3d检测。由于caddn使用多个输入转换分支完成3d检测,导致其模型推理速度缓慢,不适用于实时场景。
补充一下,引入transformer的模型:
monodtr算法,则将transformer引入单目3d目标检测领域,通过深度感知特征增强模块和深度感知transformer模块,实现全局上下文和深度感知特征的综合,将使用深度位置编码向transformer注入深度位置提示,可以更好地将transformer应用于单目3d目标检测领域。但 monodtr使用的自注意力机制难以处理多尺度目标 ,表现为对远端目标的检测能力下降。
现有方法通常会考虑利用预训练的深度模型,或是激光雷达方法的检测器来辅助完成检测,并且在最近几年中许多直接回归三维参数的方法也涌现了出来。
本文会持续更新~
单目3d目标检测专栏,大家可以参考一下
【数据集】单目3d目标检测:
3d目标检测数据集 kitti(标签格式解析、3d框可视化、点云转图像、bev鸟瞰图)_kitti标签_一颗小树x的博客-csdn博客
3d目标检测数据集 dair-v2x-v_一颗小树x的博客-csdn博客
【论文解读】单目3d目标检测:
【论文解读】smoke 单目相机 3d目标检测(cvpr2020)_相机smoke-csdn博客
【论文解读】单目3d目标检测 cupnet(iccv 2021)-csdn博客
【论文解读】单目3d目标检测 dd3d(iccv 2021)-csdn博客
【论文解读】单目3d目标检测 monodle(cvpr2021)_一颗小树x的博客-csdn博客
【论文解读】单目3d目标检测 monoflex(cvpr 2021)-csdn博客
【论文解读】单目3d目标检测 monocon(aaai2022)_一颗小树x的博客-csdn博客
【实践应用】
单目3d目标检测——smoke 环境搭建|模型训练_一颗小树x的博客-csdn博客
单目3d目标检测——smoke 模型推理 | 可视化结果-csdn博客
单目3d目标检测——monodle 模型训练 | 模型推理_一颗小树x的博客-csdn博客
单目3d目标检测——monocon 模型训练 | 模型推理-csdn博客




发表评论