长短期记忆(lstm)网络已被广泛用于解决各种顺序任务。让我们了解这些网络如何工作以及如何实施它们。
就像我们一样,循环神经网络(rnn)也可能很健忘。这种与短期记忆的斗争导致 rnn 在大多数任务中失去有效性。不过,不用担心,长短期记忆网络 (lstm) 具有出色的记忆力,可以记住普通 rnn 无法记住的信息!
lstm 是 rnn 的一种特殊变体,因此掌握 rnn 相关的概念将极大地帮助您理解本文中的 lstm。我在上一篇文章中介绍了 rnn 的机制。
rnn 快速回顾
rnn 以顺序方式处理输入,其中在计算当前步骤的输出时考虑先前输入的上下文。这允许神经网络在不同的时间步长上携带信息,而不是保持所有输入彼此独立。
然而,困扰典型 rnn 的一个重大缺点是梯度消失/爆炸问题。在训练过程中通过 rnn 反向传播时会出现此问题,特别是对于具有更深层的网络。由于链式法则,梯度在反向传播过程中必须经过连续的矩阵乘法,导致梯度要么呈指数收缩(消失),要么呈指数爆炸(爆炸)。梯度太小会阻碍权重的更新和学习,而梯度太大会导致模型不稳定。
由于这些问题,rnn 无法处理较长的序列并保持长期依赖性,从而使它们遭受“短期记忆”的困扰。
什么是 lstm
虽然 lstm 是一种 rnn,其功能与传统 rnn 类似,但它的门控机制使其与众不同。该功能解决了 rnn 的“短期记忆”问题。

从图中我们可以看出,差异主要在于 lstm 保存长期记忆的能力。这在大多数自然语言处理 (nlp) 或时间序列和顺序任务中尤其重要。例如,假设我们有一个网络根据给我们的一些输入生成文本。文章开头提到作者有一只“名叫克里夫的狗”。在其他几个没有提到宠物或狗的句子之后,作者再次提到了他的宠物,模型必须生成下一个单词“但是,克里夫,我的宠物____”。由于单词 pet 出现在空白之前,rnn 可以推断出下一个单词可能是可以作为宠物饲养的动物。
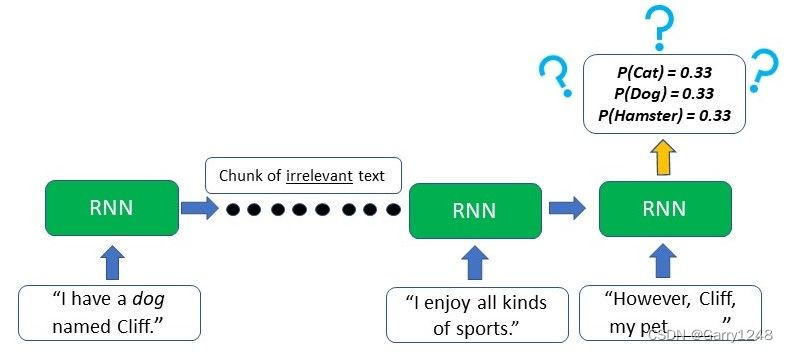
然而,由于短期记忆的原因,典型的 rnn 只能使用最后几句话中出现的文本中的上下文信息——这根本没有用处。rnn 不知道宠物可能是什么动物,因为文本开头的相关信息已经丢失。
另一方面,lstm 可以保留作者有一只宠物狗的早期信息,这将有助于模型在生成文本时根据大量上下文信息选择“狗” 。较早的时间步长。

lstm 的内部工作原理
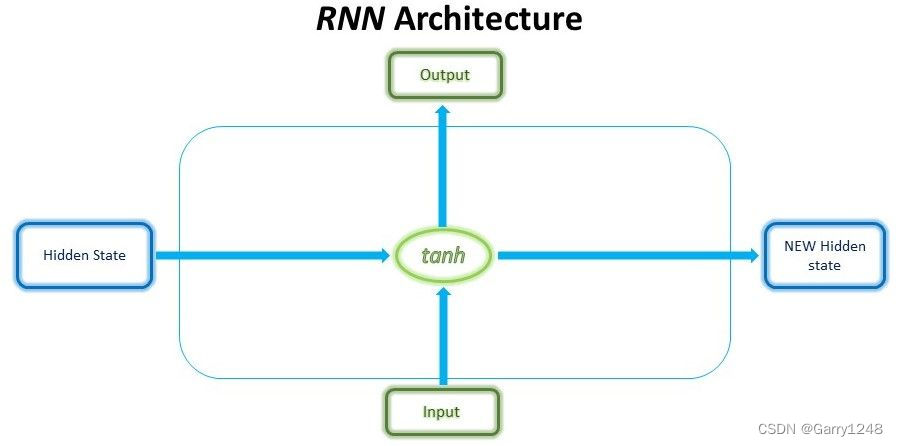
lstm 的秘密在于每个 lstm 单元内的门控机制。在普通 rnn 单元中,某个时间步的输入和前一个时间步的隐藏状态通过tanh激活函数来获得新的隐藏状态和输出。
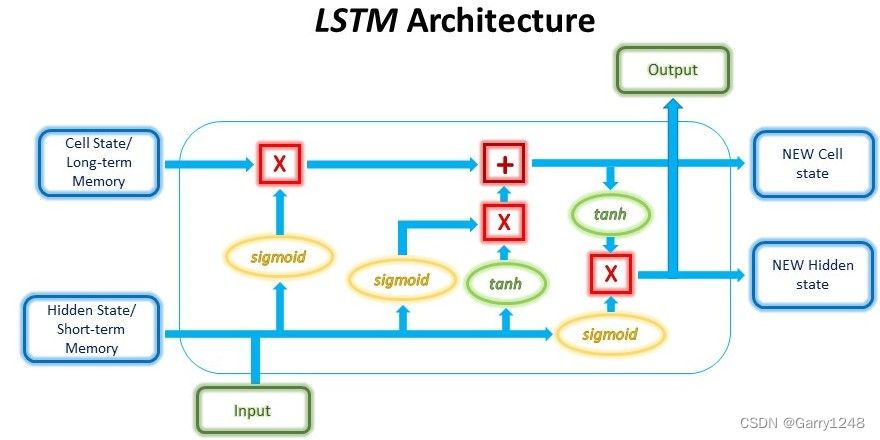
另一方面,lstm 的结构稍微复杂一些。在每个时间步,lstm 单元都会接收 3 条不同的信息:当前输入数据、前一个单元的短期记忆(类似于 rnn 中的隐藏状态)以及最后的长期记忆。
短期记忆通常称为隐藏状态,长期记忆通常称为细胞状态。
然后,在将长期和短期信息传递到下一个单元之前,单元使用门来调节每个时间步要保留或丢弃的信息。
这些门可以看作是水过滤器。理想情况下,这些门的作用应该是选择性地去除任何不相关的信息,类似于水过滤器如何防止杂质通过。同时,只有水和有益的营养物质才能通过这些过滤器,就像大门只保留有用的信息一样。当然,这些门需要经过训练才能准确过滤有用的内容和无用的内容。
这些门称为输入门、遗忘门和输出门。这些门的名称有多种变体。然而,这些门的计算和工作原理大部分是相同的。
让我们一一了解这些门的机制。
输入门
输入门决定哪些新信息将存储在长期记忆中。它仅适用于当前输入的信息和上一时间步的短期记忆。因此,它必须从这些变量中过滤掉无用的信息。
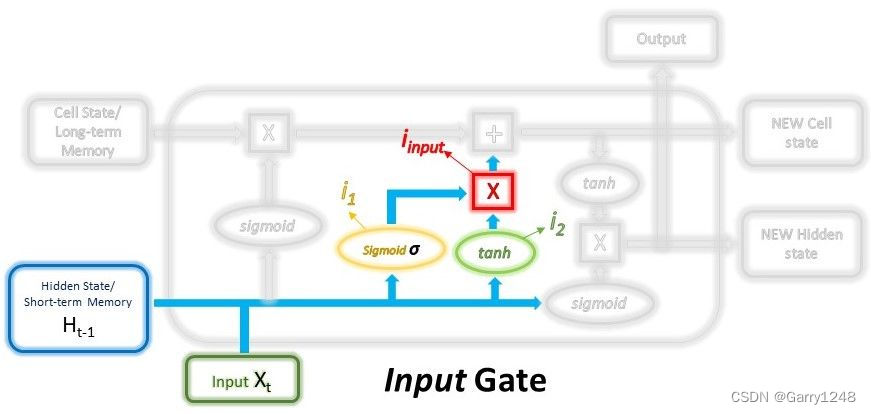
从数学上讲,这是使用2 层来实现的。第一层可以看作是过滤器,它选择哪些信息可以通过它以及哪些信息被丢弃。为了创建这一层,我们将短期记忆和当前输入传递给sigmoid函数。sigmoid函数会将值转换为0到1之间,0表示部分信息不重要,而1表示该信息将被使用。这有助于决定要保留和使用的值,以及要丢弃的值。当该层通过反向传播进行训练时,sigmoid函数中的权重将被更新,以便它学会只让有用的特征通过,同时丢弃不太重要的特征。
i
1
=
σ
(
w
i
1
⋅
(
h
t
−
1
,
x
t
)
+
b
i
a
s
i
1
)
i_1 = \sigma(w_{i_1} \cdot (h_{t-1}, x_t) + bias_{i_1})
i1=σ(wi1⋅(ht−1,xt)+biasi1)
第二层也采用短期记忆和当前输入,并将其传递给激活函数(通常是
t
a
n
h
tanh
tanh函数)来调节网络。
i
2
=
t
a
n
h
(
w
i
2
⋅
(
h
t
−
1
,
x
t
)
+
b
i
a
s
i
2
)
i_2 = tanh(w_{i_2} \cdot (h_{t-1}, x_t) + bias_{i_2})
i2=tanh(wi2⋅(ht−1,xt)+biasi2)
然后将这两层的输出相乘,最终结果表示要保存在长期记忆中并用作输出的信息。
i
i
n
p
u
t
=
i
1
∗
i
2
i_{input} = i_1 * i_2
iinput=i1∗i2
遗忘门
遗忘门决定应保留或丢弃长期记忆中的哪些信息。这是通过将传入的长期记忆乘以当前输入和传入的短期记忆生成的遗忘向量来完成的。
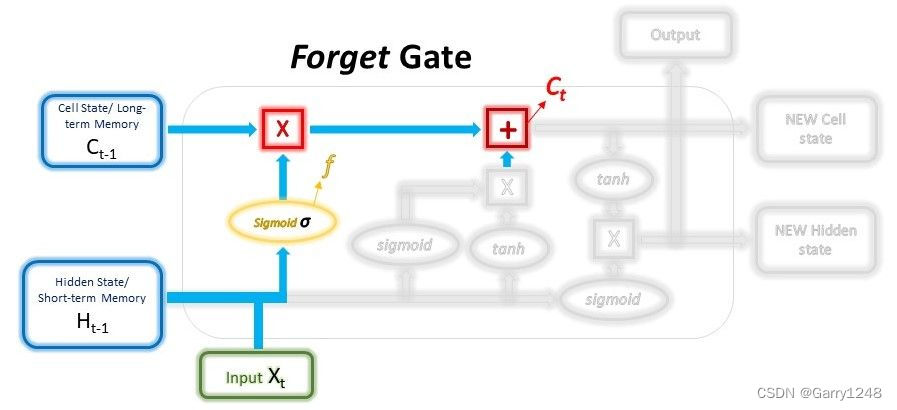
就像输入门中的第一层一样,遗忘向量也是一个选择性过滤层。为了获得遗忘向量,短期记忆和当前输入通过sigmoid函数传递,类似于上面输入门中的第一层,但具有不同的权重。该向量将由 0 和 1 组成,并将与长期记忆相乘以选择要保留长期记忆的哪些部分。
f
=
σ
(
w
f
o
r
g
e
t
⋅
(
h
t
−
1
,
x
t
)
+
b
i
a
s
f
o
r
g
e
t
)
f = \sigma(w_{forget} \cdot (h_{t-1}, x_t) + bias_{forget})
f=σ(wforget⋅(ht−1,xt)+biasforget)
输入门和遗忘门的输出将进行逐点加法,以给出新版本的长期记忆,并将其传递到下一个单元。这个新的长期记忆也将用于最后一个门,即输出门。
c
t
=
c
t
−
1
∗
f
+
i
i
n
p
u
t
c_t = c_{t-1} * f + i_{input}
ct=ct−1∗f+iinput
输出门
输出门将采用当前输入、先前的短期记忆和新计算的长期记忆来产生新的短期记忆/隐藏状态 ,该状态将在下一个时间步骤中传递到单元。当前时间步的输出也可以从这个隐藏状态中得出。
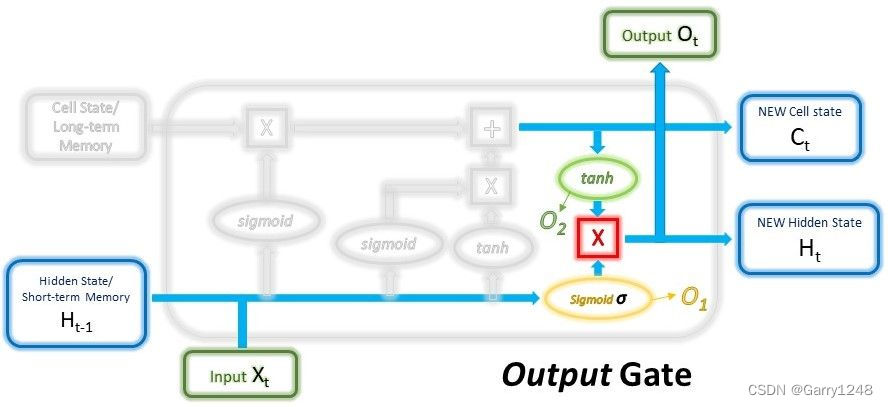
首先,之前的短期记忆和当前输入将再次以不同的权重传递到 sigmoid 函数(是的,这是我们第三次这样做),以创建第三个也是最后一个过滤器。然后,我们将新的长期记忆通过激活
t
a
n
h
tanh
tanh函数。这两个过程的输出将相乘以产生新的短期记忆。
o
1
=
σ
(
w
o
u
t
p
u
t
1
⋅
(
h
t
−
1
,
x
t
)
+
b
i
a
s
o
u
t
p
u
t
1
)
o
2
=
t
a
n
h
(
w
o
u
t
p
u
t
2
⋅
c
t
+
b
i
a
s
o
u
t
p
u
t
2
)
h
t
,
o
t
=
o
1
∗
o
2
o_1 = \sigma (w_{output_1} \cdot (h_{t-1}, x_t) + bias_{output_1})\\ o_2 = tanh(w_{output_2} \cdot c_t + bias_{output_2})\\ h_t, o_t = o_1 * o_2
o1=σ(woutput1⋅(ht−1,xt)+biasoutput1)o2=tanh(woutput2⋅ct+biasoutput2)ht,ot=o1∗o2
这些门产生的短期和长期记忆将被转移到下一个单元,以重复该过程。每个时间步的输出可以从短期记忆中获得,也称为隐藏状态。
这就是典型 lstm 结构的全部机制。没那么难吧?
代码实现
对 lstm 有了必要的理论了解后,让我们开始在代码中实现它。今天我们将使用 pytorch 库。
在我们进入具有完整数据集的项目之前,让我们通过可视化输出来看看 pytorch lstm 层在实践中的实际工作原理。我们不需要实例化模型来查看该层如何工作。您可以使用下面的按钮在 floydhub 上运行此程序lstm_starter.ipynb。(这部分不需要在 gpu 上运行)
import torch
import torch.nn as nn
就像其他类型的层一样,我们可以实例化 lstm 层并为其提供必要的参数。可以在此处找到已接受参数的完整文档。在此示例中,我们将仅定义输入维度、隐藏维度和层数。
- 输入维度- 表示每个时间步输入的大小,例如维度 5 的输入将如下所示 [1, 3, 8, 2, 3]
- 隐藏维度- 表示每个时间步隐藏状态和细胞状态的大小,例如,如果隐藏维度为 3,则隐藏状态和细胞状态都将具有 [3, 5, 4] 的形状
- 层数 - 彼此堆叠的 lstm 层数
input_dim = 5
hidden_dim = 10
n_layers = 1
lstm_layer = nn.lstm(input_dim, hidden_dim, n_layers, batch_first=true)
让我们创建一些虚拟数据来查看该层如何接收输入。由于我们的输入维度是5,我们必须创建一个形状为 ( 1, 1, 5 ) 的张量,它表示(批量大小、序列长度、输入维度)。
此外,我们必须初始化 lstm 的隐藏状态和单元状态,因为这是第一个单元。隐藏状态和单元状态存储在格式为 ( hidden_state , cell_state ) 的元组中。
batch_size = 1
seq_len = 1
inp = torch.randn(batch_size, seq_len, input_dim)
hidden_state = torch.randn(n_layers, batch_size, hidden_dim)
cell_state = torch.randn(n_layers, batch_size, hidden_dim)
hidden = (hidden_state, cell_state)
[out]:
input shape: (1, 1, 5)
hidden shape: ((1, 1, 10), (1, 1, 10))
接下来,我们将提供输入和隐藏状态,看看我们会从中得到什么。
out, hidden = lstm_layer(inp, hidden)
print("output shape: ", out.shape)
print("hidden: ", hidden)
[out]: output shape: torch.size([1, 1, 10])
hidden: (tensor([[[ 0.1749, 0.0099, -0.3004, 0.2846, -0.2262, -0.5257, 0.2925, -0.1894, 0.1166, -0.1197]]], grad_fn=<stackbackward>), tensor([[[ 0.4167, 0.0385, -0.4982, 0.6955, -0.9213, -1.0072, 0.4426,
-0.3691, 0.2020, -0.2242]]], grad_fn=<stackbackward>))
在上面的过程中,我们看到了 lstm 单元如何在每个时间步处理输入和隐藏状态。然而,在大多数情况下,我们将以大序列处理输入数据。lstm 还可以接收可变长度的序列并在每个时间步产生输出。这次我们尝试改变序列长度。
seq_len = 3
inp = torch.randn(batch_size, seq_len, input_dim)
out, hidden = lstm_layer(inp, hidden)
print(out.shape)
[out]: torch.size([1, 3, 10])
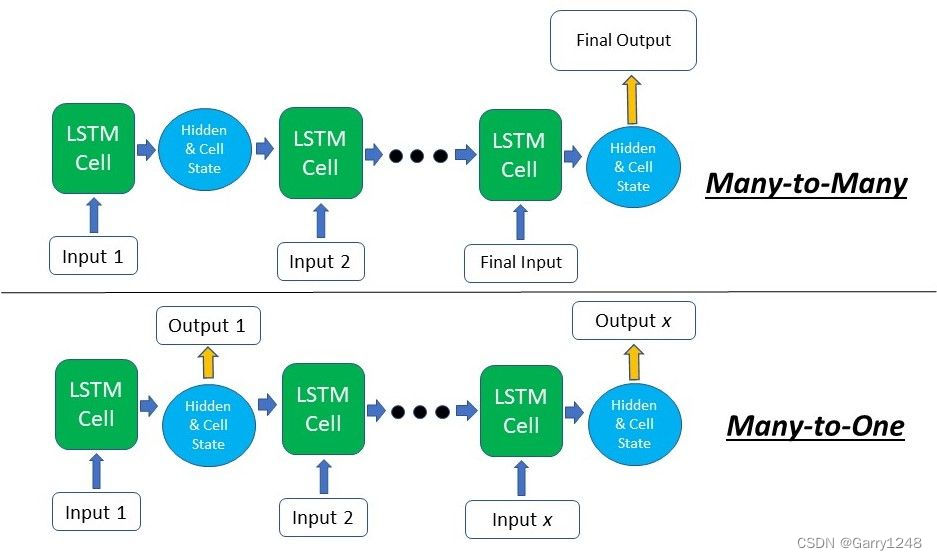
这次,输出的第二维是 3,表明 lstm 给出了 3 个输出。这对应于我们输入序列的长度。对于我们需要在每个时间步(多对多)输出的用例,例如文本生成,每个时间步的输出可以直接从第二维提取并输入到完全连接的层中。对于文本分类任务(多对一),例如情感分析,可以将最后的输出输入到分类器中。
# obtaining the last output
out = out.squeeze()[-1, :]
print(out.shape)
[out]: torch.size([10])
项目:亚马逊评论情绪分析
对于此项目,我们将使用 amazon 客户评论数据集,该数据集可以在kaggle上找到。该数据集总共包含 400 万条评论,每条评论都标记为正面或负面情绪, 可以在此处找到 github 存储库的链接。
我们实施此项目时的目标是创建一个 lstm 模型,能够准确分类和区分评论的情绪。为此,我们必须从一些数据预处理、定义和训练模型开始,然后评估模型。
我们的实现流程如下所示。
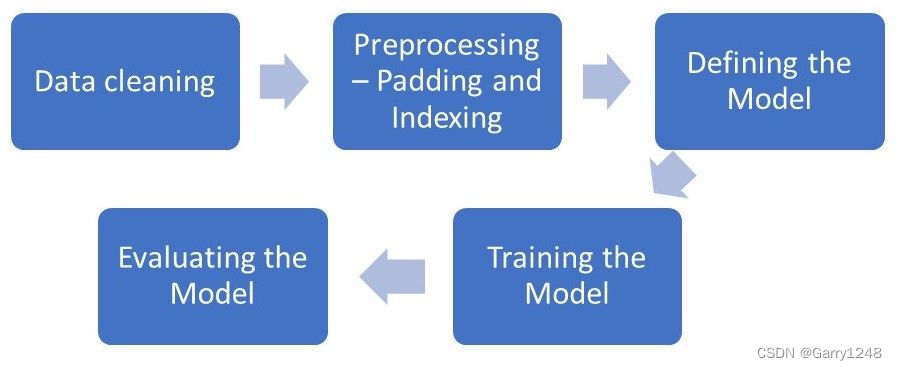
我们在此实现中仅使用 100 万条评论来加快速度,但是,如果您有时间和计算能力,请随意使用整个数据集自行运行它。
对于我们的数据预处理步骤,我们将使用regex、numpy和nltk(自然语言工具包)库来实现一些简单的 nlp 辅助函数。由于数据以bz2格式压缩,因此我们将使用 python bz2模块来读取数据。
import bz2
from collections import counter
import re
import nltk
import numpy as np
nltk.download('punkt')
train_file = bz2.bz2file('../input/amazon_reviews/train.ft.txt.bz2')
test_file = bz2.bz2file('../input/amazon_reviews/test.ft.txt.bz2')
train_file = train_file.readlines()
test_file = test_file.readlines()
number of training reviews: 3600000
number of test reviews: 400000
该数据集总共包含 400 万条评论,其中 360 万条用于训练,40 万条用于测试。我们将仅使用 800k 进行训练,200k 进行测试——这仍然是大量数据。
num_train = 800000 # we're training on the first 800,000 reviews in the dataset
num_test = 200000 # using 200,000 reviews from test set
train_file = [x.decode('utf-8') for x in train_file[:num_train]]
test_file = [x.decode('utf-8') for x in test_file[:num_test]]
句子的格式如下:
__label__2 stunning even for the non-gamer: this soundtrack was beautiful! it paints the scenery in your mind so well i would recommend it even to people who hate vid. game music! i have played the game chrono cross but out of all of the games i have ever played it has the best music! it backs away from crude keyboarding and takes a fresher step with great guitars and soulful orchestras. it would impress anyone who cares to listen! _
我们必须从句子中提取标签。数据是格式__label__1/2 ,因此我们可以轻松地相应地分割它。积极情绪标签存储为 1,消极情绪标签存储为 0。
我们还将所有url更改为标准,<url>因为在大多数情况下,确切的url与情绪无关。
# extracting labels from sentences
train_labels = [0 if x.split(' ')[0] == '__label__1' else 1 for x in train_file]
train_sentences = [x.split(' ', 1)[1][:-1].lower() for x in train_file]
test_labels = [0 if x.split(' ')[0] == '__label__1' else 1 for x in test_file]
test_sentences = [x.split(' ', 1)[1][:-1].lower() for x in test_file]
# some simple cleaning of data
for i in range(len(train_sentences)):
train_sentences[i] = re.sub('\d','0',train_sentences[i])
for i in range(len(test_sentences)):
test_sentences[i] = re.sub('\d','0',test_sentences[i])
# modify urls to <url>
for i in range(len(train_sentences)):
if 'www.' in train_sentences[i] or 'http:' in train_sentences[i] or 'https:' in train_sentences[i] or '.com' in train_sentences[i]:
train_sentences[i] = re.sub(r"([^ ]+(?<=\.[a-z]{3}))", "<url>", train_sentences[i])
for i in range(len(test_sentences)):
if 'www.' in test_sentences[i] or 'http:' in test_sentences[i] or 'https:' in test_sentences[i] or '.com' in test_sentences[i]:
test_sentences[i] = re.sub(r"([^ ]+(?<=\.[a-z]{3}))", "<url>", test_sentences[i])
快速清理数据后,我们将对句子进行标记化,这是标准的 nlp 任务。
标记化是将句子分割成单个标记的任务,这些标记可以是单词或标点符号等。
有许多 nlp 库可以做到这一点,例如spacy或scikit-learn,但我们将在这里使用nltk,因为它具有更快的分词器之一。
然后,这些单词将被存储在字典中,将单词映射到其出现次数。这些词将成为我们的词汇。
words = counter() # dictionary that will map a word to the number of times it appeared in all the training sentences
for i, sentence in enumerate(train_sentences):
# the sentences will be stored as a list of words/tokens
train_sentences[i] = []
for word in nltk.word_tokenize(sentence): # tokenizing the words
words.update([word.lower()]) # converting all the words to lowercase
train_sentences[i].append(word)
if i%20000 == 0:
print(str((i*100)/num_train) + "% done")
print("100% done")
- 为了删除可能不存在的拼写错误和单词,我们将从词汇表中删除仅出现一次的所有单词。
- 为了解决未知单词和填充问题,我们还必须将它们添加到我们的词汇表中。然后,词汇表中的每个单词将被分配一个整数索引,然后映射到该整数。
# removing the words that only appear once
words = {k:v for k,v in words.items() if v>1}
# sorting the words according to the number of appearances, with the most common word being first
words = sorted(words, key=words.get, reverse=true)
# adding padding and unknown to our vocabulary so that they will be assigned an index
words = ['_pad','_unk'] + words
# dictionaries to store the word to index mappings and vice versa
word2idx = {o:i for i,o in enumerate(words)}
idx2word = {i:o for i,o in enumerate(words)}
通过映射,我们将句子中的单词转换为其相应的索引。
for i, sentence in enumerate(train_sentences):
# looking up the mapping dictionary and assigning the index to the respective words
train_sentences[i] = [word2idx[word] if word in word2idx else 0 for word in sentence]
for i, sentence in enumerate(test_sentences):
# for test sentences, we have to tokenize the sentences as well
test_sentences[i] = [word2idx[word.lower()] if word.lower() in word2idx else 0 for word in nltk.word_tokenize(sentence)]
在最后的预处理步骤中,我们将用 0 填充句子并缩短冗长的句子,以便可以批量训练数据以加快速度。
# defining a function that either shortens sentences or pads sentences with 0 to a fixed length
def pad_input(sentences, seq_len):
features = np.zeros((len(sentences), seq_len),dtype=int)
for ii, review in enumerate(sentences):
if len(review) != 0:
features[ii, -len(review):] = np.array(review)[:seq_len]
return features
seq_len = 200 # the length that the sentences will be padded/shortened to
train_sentences = pad_input(train_sentences, seq_len)
test_sentences = pad_input(test_sentences, seq_len)
# converting our labels into numpy arrays
train_labels = np.array(train_labels)
test_labels = np.array(test_labels)
填充的句子看起来像这样,其中 0 代表填充:
array([ 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 44, 125, 13, 28, 1701, 5144, 60,
31, 10, 3, 44, 2052, 10, 84, 2131, 2,
5, 27, 1336, 8, 11, 125, 17, 153, 6,
5, 146, 103, 9, 2, 64, 5, 117, 14,
7, 42, 1680, 9, 194, 56, 230, 107, 2,
7, 128, 1680, 52, 31073, 41, 3243, 14, 3,
3674, 2, 11, 125, 52, 10669, 156, 2, 1103,
29, 0, 0, 6, 917, 52, 1366, 2, 31,
10, 156, 23, 2071, 3574, 2, 11, 12, 7,
2954, 9926, 125, 14, 28, 21, 2, 180, 95,
132, 147, 9, 220, 12, 52, 718, 56, 2,
2339, 5, 272, 11, 4, 72, 695, 562, 4,
722, 4, 425, 4, 163, 4, 1491, 4, 1132,
1829, 520, 31, 169, 34, 77, 18, 16, 1107,
69, 33])
我们的数据集已经分为训练数据和测试数据。然而,我们在训练过程中仍然需要一组数据进行验证。因此,我们将测试数据分成两半,分为验证集和测试集。可以在此处找到数据集拆分的详细说明。
split_frac = 0.5 # 50% validation, 50% test
split_id = int(split_frac * len(test_sentences))
val_sentences, test_sentences = test_sentences[:split_id], test_sentences[split_id:]
val_labels, test_labels = test_labels[:split_id], test_labels[split_id:]
接下来,我们将开始使用 pytorch 库。我们首先从句子和标签定义数据集,然后将它们加载到数据加载器中。我们将批量大小设置为 256。这可以根据您的需要进行调整。
import torch
from torch.utils.data import tensordataset, dataloader
import torch.nn as nn
train_data = tensordataset(torch.from_numpy(train_sentences), torch.from_numpy(train_labels))
val_data = tensordataset(torch.from_numpy(val_sentences), torch.from_numpy(val_labels))
test_data = tensordataset(torch.from_numpy(test_sentences), torch.from_numpy(test_labels))
batch_size = 400
train_loader = dataloader(train_data, shuffle=true, batch_size=batch_size)
val_loader = dataloader(val_data, shuffle=true, batch_size=batch_size)
test_loader = dataloader(test_data, shuffle=true, batch_size=batch_size)
我们还可以检查是否有 gpu 可以将训练时间加快很多倍。如果您使用带有 gpu 的 floydhub 来运行此代码,训练时间将显着减少。
# torch.cuda.is_available() checks and returns a boolean true if a gpu is available, else it'll return false
is_cuda = torch.cuda.is_available()
# if we have a gpu available, we'll set our device to gpu. we'll use this device variable later in our code.
if is_cuda:
device = torch.device("cuda")
else:
device = torch.device("cpu")
此时,我们将定义模型的架构。在此阶段,我们可以创建具有深层或大量相互堆叠的 lstm 层的神经网络。然而,像下面这样的简单模型,只有一个 lstm 和一个全连接层,效果很好,并且需要的训练时间要少得多。在将句子输入 lstm 层之前,我们将在第一层训练我们自己的词嵌入。
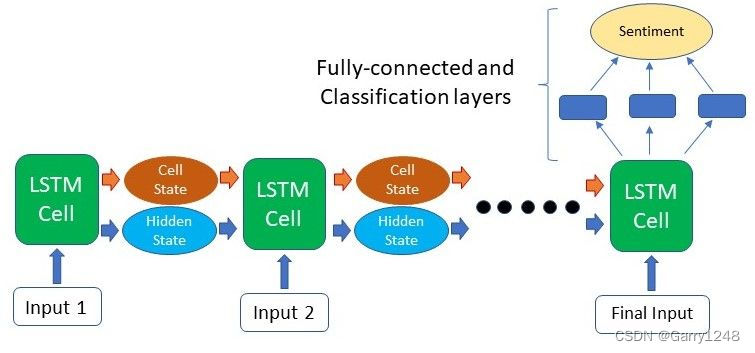
最后一层是一个全连接层,具有 sigmoid 函数,用于对评论是否具有积极/消极情绪进行分类。
class sentimentnet(nn.module):
def __init__(self, vocab_size, output_size, embedding_dim, hidden_dim, n_layers, drop_prob=0.5):
super(sentimentnet, self).__init__()
self.output_size = output_size
self.n_layers = n_layers
self.hidden_dim = hidden_dim
self.embedding = nn.embedding(vocab_size, embedding_dim)
self.lstm = nn.lstm(embedding_dim, hidden_dim, n_layers, dropout=drop_prob, batch_first=true)
self.dropout = nn.dropout(drop_prob)
self.fc = nn.linear(hidden_dim, output_size)
self.sigmoid = nn.sigmoid()
def forward(self, x, hidden):
batch_size = x.size(0)
x = x.long()
embeds = self.embedding(x)
lstm_out, hidden = self.lstm(embeds, hidden)
lstm_out = lstm_out.contiguous().view(-1, self.hidden_dim)
out = self.dropout(lstm_out)
out = self.fc(out)
out = self.sigmoid(out)
out = out.view(batch_size, -1)
out = out[:,-1]
return out, hidden
def init_hidden(self, batch_size):
weight = next(self.parameters()).data
hidden = (weight.new(self.n_layers, batch_size, self.hidden_dim).zero_().to(device),
weight.new(self.n_layers, batch_size, self.hidden_dim).zero_().to(device))
return hidden
请注意,我们实际上可以加载预先训练的词嵌入,例如glove或fasttext,这可以提高模型的准确性并减少训练时间。
这样,我们就可以在定义参数后实例化我们的模型。输出维度仅为 1,因为它只需要输出 1 或 0。还定义了学习率、损失函数和优化器。
vocab_size = len(word2idx) + 1
output_size = 1
embedding_dim = 400
hidden_dim = 512
n_layers = 2
model = sentimentnet(vocab_size, output_size, embedding_dim, hidden_dim, n_layers)
model.to(device)
lr=0.005
criterion = nn.bceloss()
optimizer = torch.optim.adam(model.parameters(), lr=lr)
最后,我们可以开始训练模型。每 1000 个步骤,我们将根据验证数据集检查模型的输出,如果模型的表现比前一次更好,则保存模型。
state_dict是 pytorch 中模型的权重,可以在单独的时间或脚本中加载到具有相同架构的模型中。
epochs = 2
counter = 0
print_every = 1000
clip = 5
valid_loss_min = np.inf
model.train()
for i in range(epochs):
h = model.init_hidden(batch_size)
for inputs, labels in train_loader:
counter += 1
h = tuple([e.data for e in h])
inputs, labels = inputs.to(device), labels.to(device)
model.zero_grad()
output, h = model(inputs, h)
loss = criterion(output.squeeze(), labels.float())
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
if counter%print_every == 0:
val_h = model.init_hidden(batch_size)
val_losses = []
model.eval()
for inp, lab in val_loader:
val_h = tuple([each.data for each in val_h])
inp, lab = inp.to(device), lab.to(device)
out, val_h = model(inp, val_h)
val_loss = criterion(out.squeeze(), lab.float())
val_losses.append(val_loss.item())
model.train()
print("epoch: {}/{}...".format(i+1, epochs),
"step: {}...".format(counter),
"loss: {:.6f}...".format(loss.item()),
"val loss: {:.6f}".format(np.mean(val_losses)))
if np.mean(val_losses) <= valid_loss_min:
torch.save(model.state_dict(), './state_dict.pt')
print('validation loss decreased ({:.6f} --> {:.6f}). saving model ...'.format(valid_loss_min,np.mean(val_losses)))
valid_loss_min = np.mean(val_losses)
完成训练后,是时候在以前从未见过的数据集(我们的测试数据集)上测试我们的模型了。我们首先从验证损失最低的点加载模型权重。
我们可以计算模型的准确性,看看我们的模型的预测有多准确。
# loading the best model
model.load_state_dict(torch.load('./state_dict.pt'))
test_losses = []
num_correct = 0
h = model.init_hidden(batch_size)
model.eval()
for inputs, labels in test_loader:
h = tuple([each.data for each in h])
inputs, labels = inputs.to(device), labels.to(device)
output, h = model(inputs, h)
test_loss = criterion(output.squeeze(), labels.float())
test_losses.append(test_loss.item())
pred = torch.round(output.squeeze()) # rounds the output to 0/1
correct_tensor = pred.eq(labels.float().view_as(pred))
correct = np.squeeze(correct_tensor.cpu().numpy())
num_correct += np.sum(correct)
print("test loss: {:.3f}".format(np.mean(test_losses)))
test_acc = num_correct/len(test_loader.dataset)
print("test accuracy: {:.3f}%".format(test_acc*100))
[out]: test loss: 0.161
test accuracy: 93.906%
通过这个简单的 lstm 模型,我们成功实现了93.8%的准确率!这显示了 lstm 在处理此类顺序任务方面的有效性。
这个结果是通过几个简单的层实现的,并且没有任何超参数调整。可以进行许多其他改进来提高模型的有效性,并且您可以自由地尝试通过实施这些改进来超越此准确性!
一些改进建议如下:
- 运行超参数搜索来优化您的配置。可以在此处找到技术指南
- 增加模型复杂性
- 添加更多层/使用双向 lstm 使用预先训练的词嵌入,例如glove嵌入
超越 lstm
多年来,lstm 在 nlp 任务方面一直是最先进的。然而,基于注意力的模型和transformer 的最新进展产生了更好的结果。随着 google 的 bert 和 openai 的 gpt 等预训练 transformer 模型的发布,lstm 的使用量一直在下降。尽管如此,理解 rnn 和 lstm 背后的概念肯定还是有用的,谁知道,也许有一天 lstm 会卷土重来呢?


发表评论