影响可复现的因素主要有这几个:
1、随机种子
2、训练使用不确定的算法
cuda卷积优化——cuda convolution benchmarking
pytorch使用不确定算法——avoiding nondeterministic algorithms
3、数据加载dataloader
4、自己代码是否使用随机排列数据集
1跟2,直接复制下面的代码,全网最全(自认为)
# 固定随机种子等操作
seed_n = 42
print('seed is ' + str(seed_n))
g = torch.generator()
g.manual_seed(seed_n)
random.seed(seed_n)
np.random.seed(seed_n)
torch.manual_seed(seed_n)
torch.cuda.manual_seed(seed_n)
torch.cuda.manual_seed_all(seed_n)
torch.backends.cudnn.deterministic=true
torch.backends.cudnn.benchmark = false
torch.backends.cudnn.enabled = false
torch.use_deterministic_algorithms(true)
os.environ['cublas_workspace_config'] = ':16:8'
os.environ['pythonhashseed'] = str(seed_n) # 为了禁止hash随机化,使得实验可复现。
(如果觉得训练太慢,用这个)
# 固定随机种子等操作
seed_n = 42
print('seed is ' + str(seed_n))
g = torch.generator()
g.manual_seed(seed_n)
random.seed(seed_n)
np.random.seed(seed_n)
torch.manual_seed(seed_n)
torch.cuda.manual_seed(seed_n)
torch.cuda.manual_seed_all(seed_n)
# torch.backends.cudnn.deterministic=true
# torch.backends.cudnn.benchmark = false
# torch.backends.cudnn.enabled = false
# torch.use_deterministic_algorithms(true)
# os.environ['cublas_workspace_config'] = ':16:8'
os.environ['pythonhashseed'] = str(seed_n) # 为了禁止hash随机化,使得实验可复现。
3点注意检查自己代码是否使用dataloader
将shuffle=false
dataloader = torch.utils.data.dataloader(dataset=dataset, batch_size=batch_size, shuffle=false)
4、自己代码是否使用随机排列数据集
类似于下面这种注释掉
# aug_shuffle = np.random.permutation(len(aug_data))
# aug_data = aug_data[aug_shuffle, :, :]
# aug_label = aug_label[aug_shuffle]
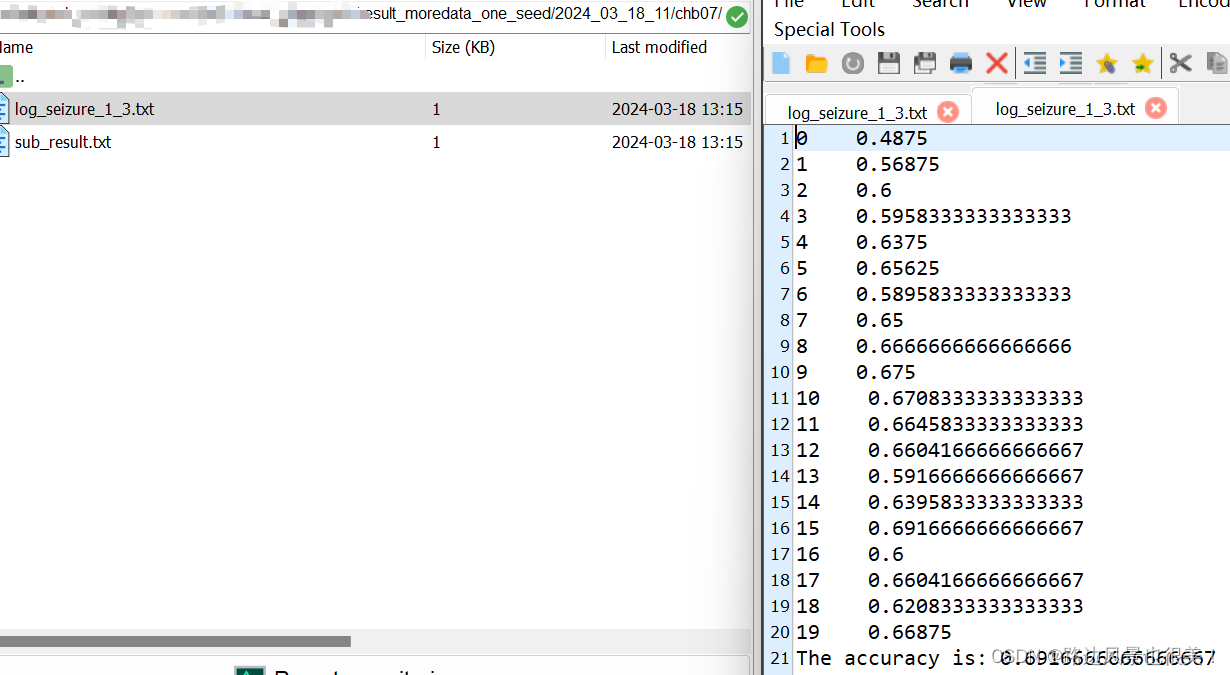
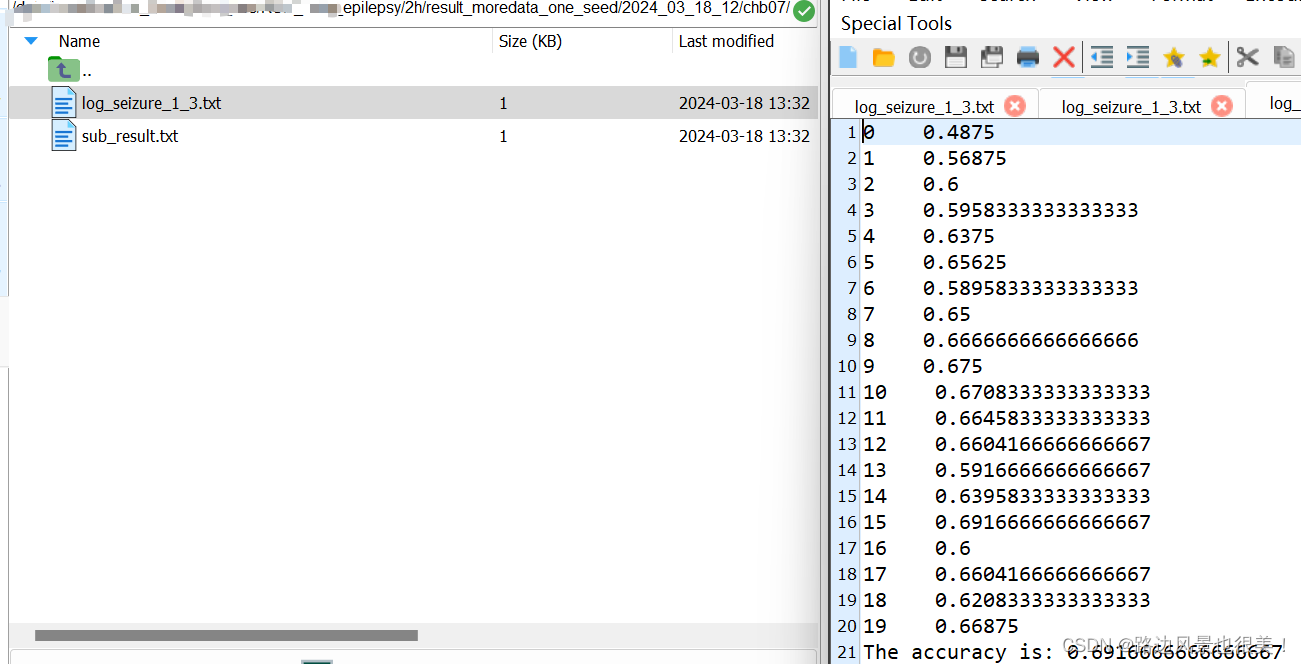
最后附上二次运行的结果!


发表评论