yolo系列算法解读:
yolov1通俗易懂版解读、ssd算法解读、yolov2算法解读、yolov3算法解读、yolov4算法解读、yolov5算法解读、yolor算法解读、yolox算法解读、yolov6算法解读、yolov7算法解读、yolov8算法解读、yolov9算法解读、yolov10算法解读
pp-yolo系列算法解读:
pp-yolo算法解读、pp-yolov2算法解读、pp-picodet算法解读、pp-yoloe算法解读、pp-yoloe-r算法解读
1、算法概述
yolox是旷视科技2021年提出的目标检测算法,它基于yolov3-spp进行改进,将原有的anchor-based调整为了anchor-free形式,并且集成了其他先进检测技术(比如decoupled head、label assignment simota)取得了sota性能。类似于yolov5,它也提供了多个尺度版本的模型,nano/tiny/s/m/l/x,而且该方法的onnx、tensorrt、ncnn、openvino推理模型均已开源。下图是yolox与其他检测算法的对比情况图:
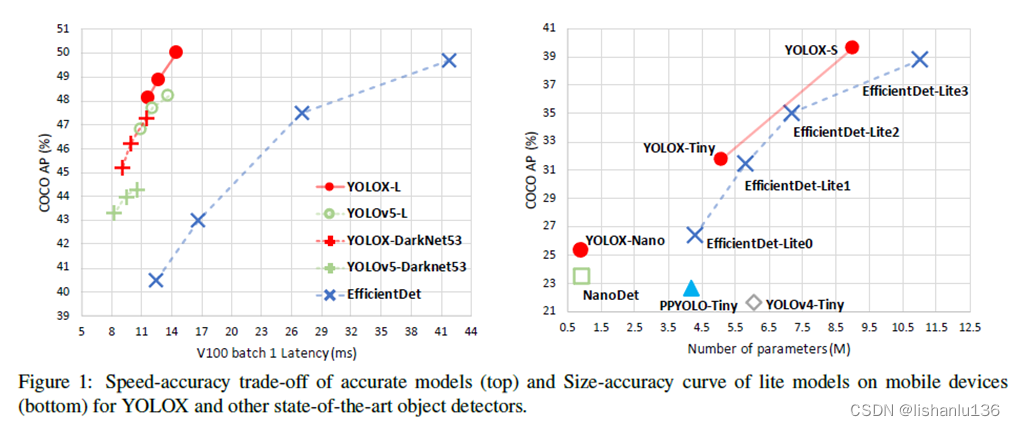
以我实际的使用情况来看,对比yolov5算法,yolox在检测精度方面确实比yolov5更加优秀,但速度会稍微慢一点点。
2、yolox细节
作者以yolov3-spp为基准,即backbone为darknet-53,neck为spp+fpn,head部分为分3个特征图输出nxnx(3x(4+1+80))。yolox对其进行一步步改进,下面来看具体的改进手段。
- 首先训练yolov3-spp baseline
和yolov3论文中不一样的是,作者增加了一些策略,比如在训练过程中加入ema权重更新技术,cosine学习率下降,iouloss和iou感知分支;用bceloss训练分类分支和obj分支,用iouloss训练回归分支。对于数据增强部分,作者只采用了随机水平翻转和颜色抖动以及多尺度训练,没有使用随机尺寸裁剪(因为作者认为这和后面的马赛克数据增强重叠了,不好评估马赛克数据增强带来的影响)。最终在coco val数据集上是38.5%map。 - decoupled head
在目标检测中,分类与回归任务的冲突是一种常见问题。因此,分类与定位头的解耦已被广泛应用到单阶段、两阶段检测中。然而yolov3/v4/v5都没有把检测头解耦,作者通过实验发现,解耦检测头能让训练收敛更快,如下图:
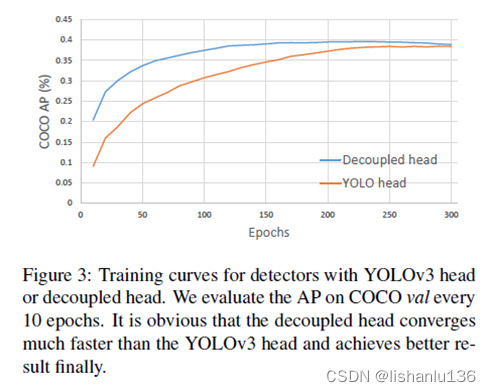
解耦头,意味着会检测头会多一个分支结构,所以参数量会增加,为了尽量少增加参数,作者在进入预测分支之前先用1x1卷积将特征通道减少,然后再接分类分支和回归分支。其结构如下所示:
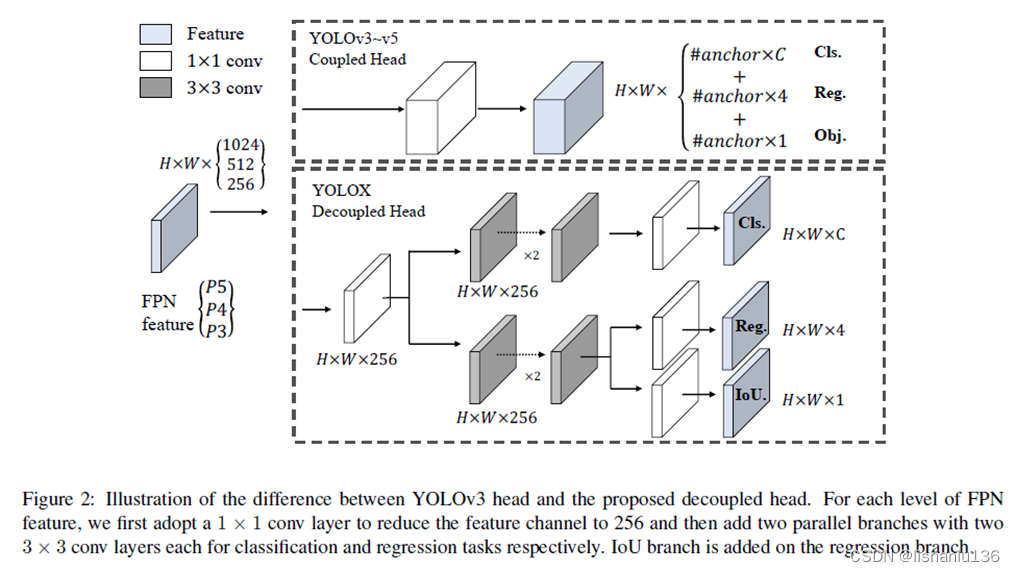
- strong data augmentation
数据增强部分,作者将mosaic和mixup添加到增强策略中,以提高yolox的性能。在模型训练过程中采用mixup和mosaic对数据进行增强,并在最后15个epoch关闭它。实际应用下来看,最后15epoch关闭数据增强很有用。 - anchor-free
anchor-based方法的弊端:1、需要在优化之前,聚类分析数据集标注框的情况,这会导致训练出来的模型使用场景及泛化性能受限。2、锚框设计增加了检测头的复杂性,预测框数量会根据锚框设计的增加而增加。
而无锚框机制显著减少了需要启发式调整的设计参数的数量和涉及的许多技巧(例如,锚框聚类,网格敏感)的良好性能,使检测器的训练和解码阶段大大简化。将anchor-based调整为anchor-free比较简单,作者将每个位置的预测从3个(yolov3是每个grid设置3个anchor)减少到1个,并使它们直接预测4个值,即网格左上角的两个偏移量,以及预测框的高度和宽度。改成anchor-free后,作者参考fcos,将每个目标的中心定位正样本并预定义一个尺度范围以便于对每个目标指派fpn特征尺度。经过这个改进后,模型参数和gflops都减少了,推理速度更快,而且性能还提升至42.9%map了。 - multi positives
上面的匹配策略,一个gt框只能匹配一个正样本(因为采用center location匹配),这意味着会忽略掉周边高质量预测框,所以作者划定gt框中心点3x3的区域内匹配正样本,这个区域就类似于fcos中的”center sampling”。这一改进促使模特map提升至45.0%。 - simota
ota从全局角度分析标签分配,并将分配过程制定为最优运输(optimal transport, ot)问题,从而产生当前分配策略中的sota性能。然而,在实践中我们发现用sinkhorn-knopp算法求解ot问题带来了额外25%的训练时间,这对于训练来说是相当昂贵的。因此,我们将其简化为动态top-k策略,命名为simota,以获得近似解。在simota中,预测框pj与gt框gi的匹配代价计算为
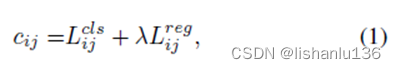
λ为平衡系数,前者为gi与pj的分类损失,后者为gi与pj的回归损失。
对于每一个gt框gi,选择前topk个与之损失最小的预测框,且该预测框中心点在gi中心点3x3的范围内的可作为该gt框gi的正样本,其余则作为负样本。通过这个改进,map又提升至47.3%。 - end-to-end yolo
即模型最后直接输出结果,不需要最后做nms,这样的改进会导致掉点,所以作者最终没有采用。
下面是上述改进的消融实验结果:
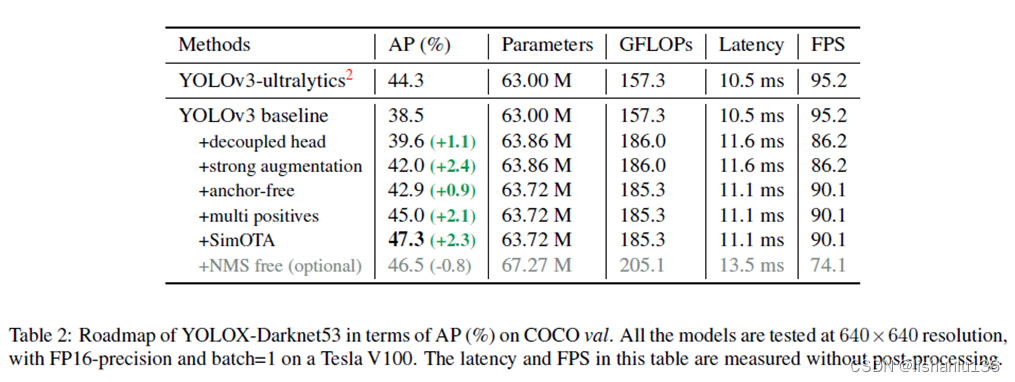
从表中可以看出,数据增强,划分3x3领域取更多正样本和simota动态匹配正样本这三个改进对yolox提升比较大。
- other backbones
仿照yolov5的网络规模改进得到yolox-s/m/l/x,仿照yolov4-tiny提出yolox-tiny及yolox-nano,实验结果均表明yolox的这些改进很优秀。

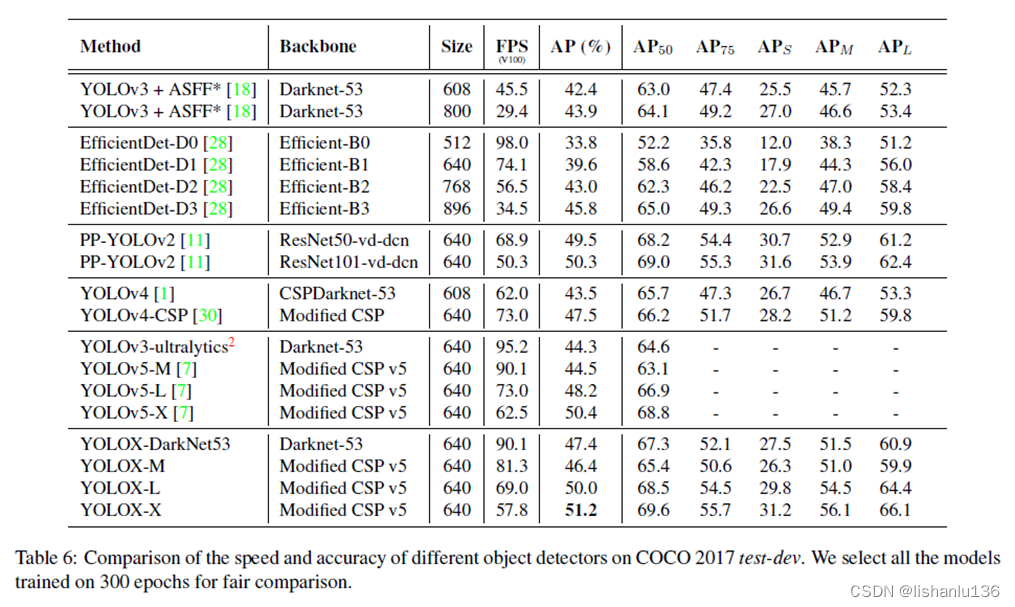
3、实验
与现如今其他检测算法对比
4、总结
yolox和yolov5是我个人用得比较熟练的算法,工程代码都仔细研读过,写得都是非常优秀,代码结构清晰明了,如今yolox和yolov5都在工业界得到了广泛的应用,就我个人使用感觉而言,yolox的精度是略高于yolov5的,但速度比yolov5稍慢,两个算法都有不同的应用版本,可以方便各个平台适配;个人使用下来,yolox似乎对小目标漏检比较多,yolov5泛化性能更强一点。



发表评论