提出背景
论文:mindmap: knowledge graph prompting sparks graph of thoughts in large language models
代码:https://github.com/wyl-willing/mindmap
mindmap 通过结合知识图谱提供实时知识更新和透明的推理路径,相比传统llm在处理复杂查询时显著提升了准确性、透明度和解释能力。
1. 知识更新与整合
- 传统llm:通常依赖于固定的预训练数据,难以实时更新或整合新知识。
- mindmap:通过动态接入知识图谱(kg),能够实时更新和引入新的、结构化的知识,提高模型的时效性和相关性。
2. 信息准确性与幻觉问题
- 传统llm:可能会生成不准确的信息或“幻觉”,特别是在数据稀疏或模型训练不足的领域。
- mindmap:利用知识图谱作为验证工具,减少错误信息的生成,增加输出的可靠性。
3. 推理透明度与解释性
- 传统llm:作为“黑盒”模型,其决策和推理过程往往缺乏透明度和易于理解的解释。
- mindmap:通过构建可视化的思维图,显著提高模型的透明度,使推理过程可追踪,易于理解。
4. 处理复杂查询的能力
- 传统llm:在处理需要多实体关联和多步骤逻辑推理的复杂查询时可能表现不足。
- mindmap:结合llm的自然语言处理能力和kg的结构化数据,强化了模型处理复杂、多变量查询的能力。
5. 系统灵活性和扩展性
- 传统llm:对于新领域或特定类型的任务需要重新训练或微调,这可能是资源密集和时间消耗大的。
- mindmap:通过模块化的知识图谱集成,可以更灵活地添加或修改知识领域,快速适应新的应用场景。
mindmap通过创新性地融合知识图谱和大型语言模型,克服了单纯依赖llm处理复杂查询时的多种限制,为用户提供了更精确、可靠、透明和解释性强的解决方案。
知识图谱和大模型联合推理
mindmap的优势在于可以利用自然语言处理能力,对于复杂的query(用户提问)和外在数据库联系起来。
工作流程涉及几个关键步骤,每一步都利用了llm和kg的特点,以确保生成的答案既准确又信息丰富。
预处理和输入理解
- 用户输入处理:当用户提交一个查询(query)时,首先由llm进行初步的语义分析,理解查询的核心意图和相关上下文。
- 实体识别和关键词提取:llm识别出输入中的关键实体和术语。这一步是确保能够从知识图谱中检索到正确信息的关键。
知识图谱检索
- 构建查询:基于llm识别出的关键词和实体,构建针对知识图谱的查询。这些查询用于从kg中检索相关的实体和它们之间的关系。
- 信息抽取:从知识图谱中抽取与查询相关的数据,如实体描述、实体之间的关系等。
证据合成
- 数据整合:将从kg检索到的结构化信息与llm提供的上下文信息结合。这一步骤通常涉及到信息的格式化处理,使其适用于llm进行进一步的处理。
- 推理图构建:利用检索到的信息构建一个推理图,这个图展示了不同实体和信息之间的关系,为生成回答提供逻辑框架。
输出和反馈
- 提供答案:最终优化后的答案呈现给用户。
- 收集反馈:收集用户对答案的反馈,这些反馈可用于调整llm的训练和优化知识图谱的内容。
mindmap = 基于邻居的证据探索 + 基于路径的证据探索 + 证据整合 + 推理与生成
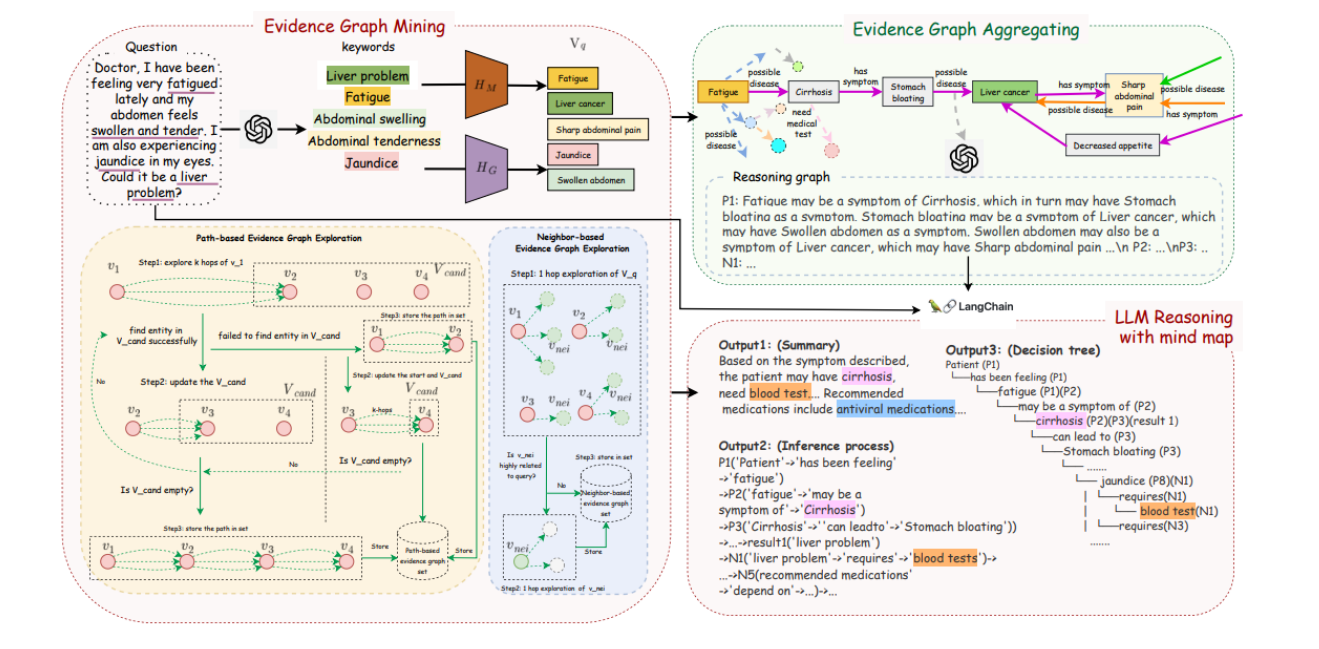
这张图展示了mindmap方法的整体架构,分为两个主要部分:证据图挖掘和证据图聚合,以及基于思维导图(树思维链)的llm推理。
左侧部分:证据图挖掘(evidence graph mining)
- 问题(question):
- 示例问题:“医生,我最近感觉非常疲倦,腹部肿胀和触痛,并且眼睛有黄疸。这可能是肝脏问题吗?”
- 关键词(keywords):
- 从问题中提取的关键词包括:肝脏问题(liver problem)、疲劳(fatigue)、腹部肿胀(abdominal swelling)、腹部触痛(abdominal tenderness)、黄疸(jaundice)。
- 实体识别(entity recognition):
- 通过bert相似度匹配,从提取的关键词和外部知识图谱中找到相关实体,形成vq。
- 基于路径的证据图探索(path-based evidence graph exploration):
- 详细展示了如何通过多跳路径探索找到相关实体和路径的过程。
假设症状是“疲劳”和“腹部肿胀”。
在多跳路径探索中,系统可能首先从疲劳这一症状出发,通过知识图谱探索与之直接相关的可能疾病,如“肝硬化”。
接着,系统进一步探索从“肝硬化”到其他相关症状和疾病的路径,比如“肝硬化”可能导致的“黄疸”。
这样一来,就形成了一个从“疲劳”出发,经过“肝硬化”,最终关联到“黄疸”的路径。
- 基于邻居的证据图探索(neighbor-based evidence graph exploration):
- 通过一跳邻居探索找到相关实体和证据图的过程。
右侧部分:证据图聚合(evidence graph aggregation)
- 证据图聚合(evidence graph aggregation):
- 将路径证据图和邻居证据图整合,形成推理图(reasoning graph)。
在上述例子中,我们已经通过路径证据图发现了“疲劳”与“黄疸”的关联路径。
同时,在邻居证据图中,系统可能发现“腹部肿胀”直接与“肝癌”关联。
通过整合这两个证据图,我们可以构建一个更全面的推理图。
这个推理图将包括从“疲劳”到“肝硬化”再到“黄疸”的路径,以及“腹部肿胀”直接与“肝癌”关联的信息。
这样的推理图帮助系统更全面地理解患者的症状可能指向的多种疾病。
- 推理图(reasoning graph):
- 示例推理过程:疲劳可能是肝硬化的症状,肝硬化可能导致胃胀,胃胀也可能是肝癌的症状等。
- 输出(outputs):
- output1:总结(summary):基于症状描述,患者可能患有肝硬化,需要进行血液测试,推荐使用抗病毒药物。
- output2:推理过程(inference process):详细描述了推理的每一步,包括从症状到可能疾病的路径。
- output3:决策树(decision tree):展示了患者症状到最终诊断结果的思维导图,清晰地展示了推理过程。
这张图提供了mindmap方法的概览,左侧部分展示了证据图挖掘的各个组件,右侧部分展示了证据图聚合和基于思维导图的llm推理。
基于思维导图的llm推理:
- 综合了上述所有信息后,llm(大型语言模型)进入推理阶段。
- 假设现在有一个推理图包含“疲劳”、“肝硬化”、“黄疸”和“腹部肿胀”到“肝癌”的路径。
- llm将使用这个推理图作为输入,进行深入分析。
- 首先,它可能评估每种疾病与症状的关联强度,然后生成一个推理过程。
- 例如,llm可能推断:“病人描述的疲劳和腹部肿胀可能是由肝硬化引起,而肝硬化又可能因肝癌造成。
- 建议进行肝功能测试和肝部超声检查来进一步诊断。”
- 这种基于llm的推理不仅考虑了直接的症状关联,还结合了可能的疾病间接关系和所需的医疗检查。
通过结合基于邻居和路径的证据探索,mindmap能够生成准确且有理由的答案,并通过图形化的推理过程提供透明的解释。
mindmap = 基于邻居 (关键实体识别+邻居节点扩展+相关节点筛选) + 基于路径 (关键路径识别+路径证据图构建+多跳信息整合)
邻居证据探索
- 特点:专注于邻近节点的探索,通过扩展每个节点到其直接邻居节点,来发现与查询相关的知识。
- 优势:在提高事实准确性方面表现较好,因为它能够通过邻近的相关节点快速找到准确的知识。
- 缺点:在处理需要跨越多个节点(多跳)的复杂答案(如药物和测试推荐)时,表现不佳。
路径证据探索
- 特点:通过探索从一个节点到另一个节点的路径,发现中介路径来连接查询中的重要实体。
- 优势:在查找相关外部信息方面表现较好,特别是在需要综合多个相关节点的信息时。
- 缺点:在处理需要精准的单步答案时,可能会因为路径过长而降低准确性。
证据整合
- 特点:将邻居和路径证据图整合为一个统一的综合证据图。
- 优势:能够将多种来源的证据整合,形成更全面的知识图谱,提高推理的全面性和准确性。
- 缺点:需要处理和消除冗余信息,可能增加计算复杂性。
推理与生成
- 特点:基于综合证据图进行推理,生成准确且带有理由的答案。
- 优势:生成的答案更加可信,因为推理过程透明且可追溯。
- 缺点:需要较强的计算能力来处理复杂的推理过程。
mindmap通过结合这两种方法,能够充分利用它们各自的优势,达到更好的性能和鲁棒性:
- 减少幻觉:结合路径和邻居的证据探索方法,能够有效减少生成答案中的幻觉。
- 提高准确性:利用邻居证据探索的高准确性,确保回答的基本正确性。
- 增强多跳推理能力:利用路径证据探索的多跳推理能力,处理复杂的查询任务,如药物和测试推荐。
基于邻居的方法,在提高事实准确性方面比基于路径的方法更有效。
对于涉及医学查询的任务,基于路径的方法在查找相关外部信息方面更好,但在处理诸如药物和测试推荐等多跳答案时表现不佳。
- 基于邻居的方法适合处理直接相关和单步答案的查询(简单症状查询、单一测试推荐)
- 基于路径的方法更适合处理复杂、多因素相关的查询(复杂疾病诊断、药物推荐)。
mindmap的优越表现主要来自于它能够灵活结合邻居和路径两种证据探索方法,从而在不同类型的任务中都能表现出色。
这种综合方法确保了系统在处理简单和复杂查询时都能提供准确且合理的答案。
假设有一个用户查询:“患者最近一直感到疲劳,并且腹部肿胀,可能是什么问题?”
邻居证据探索
- 回答:"疲劳"和"腹部肿胀"可能与"肝硬化"相关。
- 过程:模型扩展到直接邻居节点,找到"疲劳"和"腹部肿胀"与"肝硬化"的直接关联。
路径证据探索
- 回答:"疲劳"和"腹部肿胀"可能与"肝硬化"或"肝癌"相关。
- 过程:模型探索从"疲劳"和"腹部肿胀"到"肝硬化"和"肝癌"的中介路径,发现多个可能的关联。
mindmap(结合邻居和路径)
- 回答:"疲劳"和"腹部肿胀"可能与"肝硬化"相关,需要进行"血液测试"以确认,且可能需要"抗病毒药物"治疗。
- 过程:
- 邻居证据探索:模型找到"疲劳"和"腹部肿胀"与"肝硬化"的直接关联。
- 路径证据探索:模型发现从"疲劳"和"腹部肿胀"到"肝硬化"和"肝癌"的中介路径。
- 证据整合:整合邻居和路径信息,确定最相关的疾病。
- 推理与生成:基于综合证据图,生成详细的诊断建议,包括"血液测试"和"抗病毒药物"。
推理过程
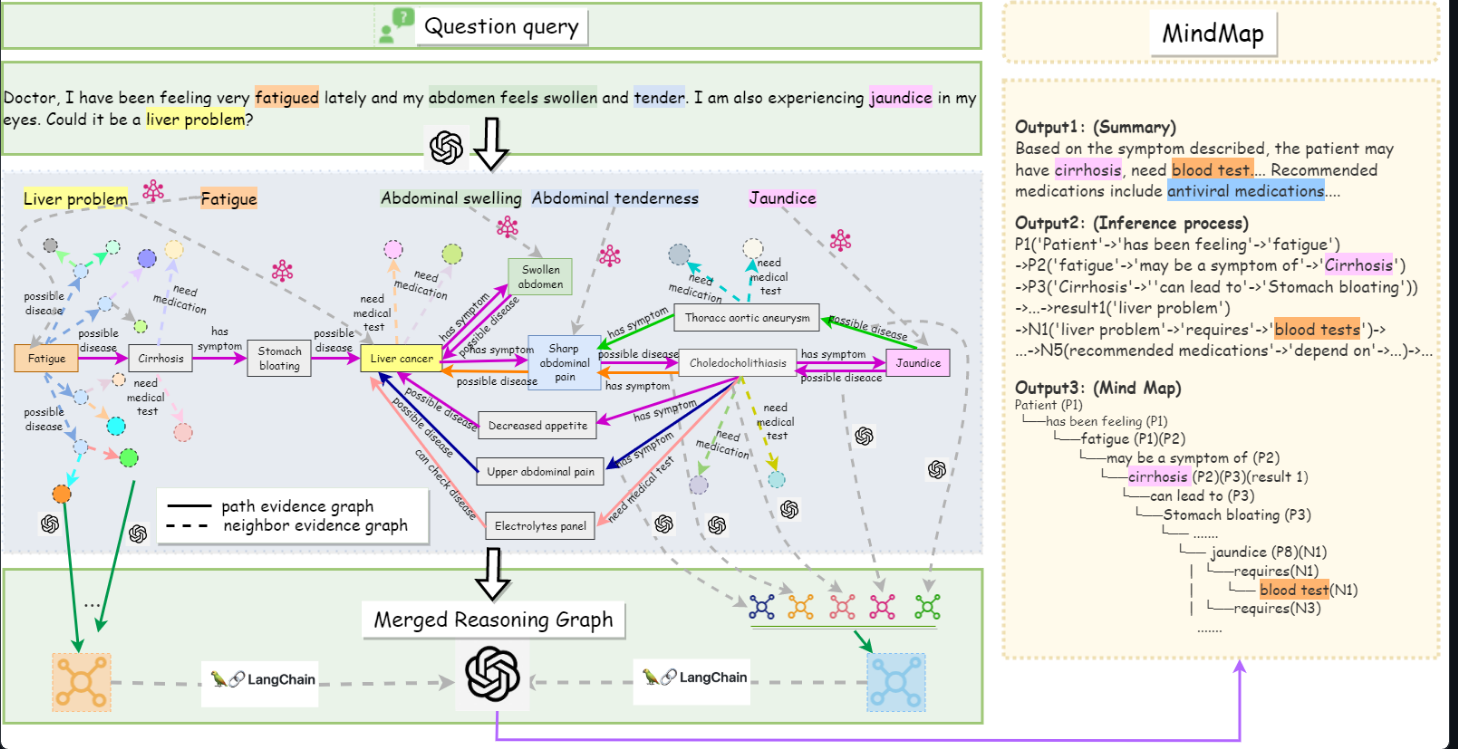

这张图片详细展示了mindmap框架在处理用户健康查询时的具体工作流程和推理过程。
1. 用户查询 (question query)
- 用户输入一个问题,描述了自己的症状:“疲劳、腹胀、触痛、黄疸等”,并询问是否可能是肝脏问题。
2. 首次llm处理(实体识别和初步推理)
- 提取关键症状和潜在疾病:llm识别用户输入中的关键症状(如疲劳、腹胀、触痛、黄疸)和可能的相关疾病(如肝脏问题、肝癌等)。
- 初步推理和证据图构建:系统生成路径证据图(path evidence graph)和邻居证据图(neighbor evidence graph),显示症状与潜在疾病之间的关联。
3. 证据图聚合 (merged reasoning graph)
- 路径证据图:展示了从疲劳到肝硬化、肝癌的可能路径,包括相关症状和需要的医疗测试。
- 邻居证据图:展示了其他相关的症状和疾病之间的关系,例如黄疸与胆结石之间的关系。
- 合并推理图:结合路径证据图和邻居证据图,形成一个综合推理图,显示所有相关信息和推理路径。
4. 第二次llm处理(生成输出)
- output 1:摘要:基于描述的症状,生成一个摘要,指出患者可能患有肝硬化,并需要进行血液测试等推荐的医疗措施。
- output 2:推理过程:详细说明推理步骤,例如从“疲劳”推导出可能是“肝硬化”的症状,并进一步推导出需要的测试和医疗措施。
- output 3:思维导图:生成一个思维导图,显示推理过程中的各个步骤和逻辑关系,例如患者感觉到疲劳,这可能是肝硬化的症状,进一步需要进行血液测试等。

mindmap分为三个主要部分。
3.1 步骤i:证据图挖掘
在这一阶段,我们需要从外部知识图谱(kg)中发现与问题相关的证据子图。具体步骤如下:
3.1.1 实体识别
- 目标:从用户输入的问题查询(q)中识别关键实体。
- 过程:
- 构建提示:提示包含三个部分:待分析的问题、模板短语“the extra entities are”和两个示例。详见附录d的表9。
- 使用llm识别实体:应用bert相似度匹配实体和关键词。具体步骤如下:
- 将llm提取的所有关键词实体(m)和外部知识图谱中的所有实体(g)编码为稠密嵌入(hm和hg)。
- 计算它们之间的余弦相似度矩阵。
- 对于每个关键词,找到相似度最高的实体集(vq),以便在下一步中构建证据子图。
3.1.2 证据子图探索
- 目标:基于识别出的实体(vq)从知识图谱中构建证据子图(gq)。
- 过程:
- 定义源知识图谱:g = {⟨u, r, o⟩ |u ∈ ψ, r ∈ φ, o ∈ l },其中ψ、φ和l分别代表实体集、关系集和文本集。
- 构建证据子图:使用两种方法:
- 基于路径的探索:追踪知识图谱中的中介路径以连接查询中的重要实体。
- 从vq中的某个节点出发,探索最多k跳的连接节点,直到所有路径段连接在一起,形成子图集gpath q。
- 基于邻居的探索:通过扩展每个节点到其邻居节点来添加相关知识。
- 添加三元组{(n, e, n′)}到gnei q中。
- 基于路径的探索:追踪知识图谱中的中介路径以连接查询中的重要实体。
- 更新和修剪子图:
- 新增中间节点更新vq。
- 通过聚类和采样对gpath q和gnei q进行修剪,以管理信息过载并保持多样性。
- 结果:生成最终的证据图gq,优化信息同时保持多样性。
3.2 步骤ii:证据图聚合
在此阶段,llm需要将不同的证据子图(gq)整合为一个统一的推理图(gm)。
3.2.1 整合步骤
- 目标:将多样的证据子图整合为统一的推理图(gm)。
- 过程:
- 提取子图:从前一步中提取至少k个基于路径和k个基于邻居的证据子图。
- 格式化子图:将每个子图格式化为实体链(例如“(fatigue, nausea) - issymptomof - liverproblem”),并分配序列号(如p1、p2、n1、n2)。
- 提示llm转换实体链:使用附录d表10中的模板,将每个实体链转换为自然语言描述,并定义为推理图gm。
- 优势:简化子图为捕捉关键信息的简洁一致格式,并利用llm的自然语言理解和生成能力统一语义相似的实体,解决潜在歧义。
3.3 步骤iii:llm结合思维导图进行推理
在此步骤中,我们使用推理图(gpath m和gnei m)提示llm生成最终输出。
3.3.1 图推理提示
- 目标:生成思维导图并找到最终结果。
- 过程:
- 提示组件:包含五个部分:系统指令、问题、证据图gm、思维图指令和示例。
- 构建思维导图:使用langchain技术指导llm理解和增强输入,构建自己的推理思维导图,并索引思维导图的知识来源。提示模板详见图3。
- 生成最终答案:包括摘要答案、推理过程和显示图推理路径的思维导图。
3.3.2 llm与kg知识的协同推理
- 目标:利用llm和知识图谱(kg)的知识进行协同推理。
- 过程:
- 语言理解:llm能够理解并提取gm和自然语言查询中的知识。
- 知识推理:llm能够进行实体消歧,并基于由gm构建的思维导图生成最终答案。
- 知识增强:llm能够利用其隐含知识扩展、连接和改进与查询相关的信息。
逻辑关系拆解:
- 目的:生成思维导图并进行推理。
- 解法拆解:
- 子解法1:识别关键实体
- 之所以用实体识别子解法,是因为它能确定查询中的重要信息。
- 子解法2:构建证据子图
- 之所以用证据子图子解法,是因为它能提供与查询相关的背景知识。
- 子解法3:整合证据图
- 之所以用证据图整合子解法,是因为它能统一信息,简化推理过程。
- 子解法4:提示llm生成思维导图
- 之所以用思维导图子解法,是因为它能直观展示推理过程并生成最终答案。
- 子解法1:识别关键实体
举个例子。
步骤一:证据图挖掘
- 场景:如果用户询问“糖尿病的常见并发症有哪些?”
- 操作:系统首先识别出“糖尿病”作为关键实体,并通过路径探索和邻居探索在知识图谱中查找与糖尿病直接相关的并发症实体,如“视网膜病变”、“肾病”和“神经病变”。
- 结果:这一步生成多个证据子图,展示糖尿病与各种并发症之间的直接联系和潜在路径。
步骤二:证据图聚合
- 场景:整合从第一步得到的所有相关证据子图。
- 操作:将不同的证据子图聚合成一个统一的推理图(gm),这个图将详细展示糖尿病及其并发症之间的关系。
- 结果:推理图帮助llm全面理解糖尿病及其并发症的复杂关系,提供一个结构化的知识框架以支持更精确的输出。
步骤三:llm在思维图上的推理
- 场景:利用构建的推理图进行深入推理,回答用户的原始问题。
- 操作:llm结合推理图和自身的隐含知识,通过语言理解、知识推理和知识增强,生成关于糖尿病并发症的详细解答。
- 结果:生成的答案不仅列出了糖尿病的常见并发症,还可能包括预防和治疗这些并发症的建议,提供了准确而深入的医疗信息。
mindmap 细节分析
为什么好于知识图谱+大模型

方式3代表了传统的知识图谱查询,这通常侧重于单一路径或直接关系的检索。
方式4 mindmap,它不仅依赖于知识图谱的结构化查询,还融合了多跳推理(长链条)和多路径探索。这意味着它能够通过多个节点和连接分析复杂的关系,从而提供更全面的问题解读。
在这种模式下,如图所示的路径和邻居方法被并用,使得系统能够通过探索症状与多种疾病间的潜在联系,如肝硬化、黄疸至胆结石等多个步骤的逻辑链路,进而提供更为全面的诊断视角。
在我觉得,医学诊断就是特征识别,之所以有xxx特征,是因为yyy病
知识图谱就是特征匹配的好工具。
mindmap比 知识图谱+大模型 更强,因为多链路推理使得知识图谱结构化推理。
- mindmap不仅使用了知识图谱来获取与症状相关的直接信息,还结合了多链路推理来探索间接关系和可能的深层链接。这种方法能更全面地分析病因,提供更为精确的诊断。
- 传统知识图谱只是单一路径下的特征识别
知识图谱的单一路径推理相比于结构化推理,缺少了对多症状和多疾病间复杂关联的全面考量,限制了其在处理多因素交织的医疗诊断问题时的适应性和准确性。
mindmap结论:已经有了结构化推理 + 海量疾病模式识别库
比如一个问题,想通需要十步,而正常人或者大模型,ta最多只能推导三步,这意味着解决不了这种复杂关系问题。
而mindmap可以通过 知识图谱结构化 + 类似二级结论(不用推理直接走2步)的病症疾病识别 + 拼接每个逻辑短链 的方式,变成 3 + 3 + 3 + 1 再整合起来,就能做到十步的推理。
mindmap 查邻居、查关系、结合推理每步具体是什么?
在使用知识图谱进行医学分析时,查邻居和查路径是两种常见的查询方式,每种方式得到的结果都有其特定的用途和特点。
查邻居(neighbor lookup):
-
这是图数据库中的一种操作,用于查询与某个特定节点直接连接的其他节点。这些直接连接的节点称为“邻居”。这种查询通常用于快速获取与某个实体直接相关的信息。
-
结果:得到与指定节点(如一个症状)直接连接的所有节点,通常是直接相关的疾病或其他症状。
-
例如,如果查询症状“头痛”,查邻居的结果可能包括与头痛直接相关的疾病如偏头痛、高血压等。
查路径(path finding):
-
这种操作用于发现两个节点之间的路径,可以是最短路径,或特定类型的路径,这取决于图的性质和查询的具体要求。路径查找帮助识别两个实体之间的潜在关系,这些关系可能通过多个中间节点相连。
-
结果:找出两个节点之间的连接路径,可能包括一个或多个中间节点。这有助于理解两个看似不直接相关的实体(如两个症状)如何通过一系列中间联系(可能是其他症状或疾病)相连。
-
例如,可能探索从“头痛”到“视力模糊”之间的路径,揭示它们通过“高血压”这一共同的潜在原因相连。
结合查邻居和查路径:
- 结果:结合这两种方法可以创建一个更为复杂和全面的推理图,显示从一个节点(如症状)出发的直接和间接关系网。
- 这种综合视图可以揭示更为复杂的关系和深层次的连接,有助于理解一个症状背后的多种可能的医学背景。
怎么得到的一个症状的所有可能性?
如果要得到一个症状的所有可能性适用方法:为了得到一个症状的所有可能性,即所有可能的疾病和相关的症状,最有效的方法是结合查邻居和查路径。
通过这种结合,可以不仅查看与症状直接关联的疾病,还能探索通过不同路径连接的其他可能关联的症状和疾病,从而构建一个全面的症状-疾病网络。
这种方法提供了从单一症状出发的最广泛的医学解释和联系,从而帮助医生或研究人员全面理解症状的潜在原因和复杂性。
这种综合查询策略能够极大地增强医学诊断的深度和准确性,为患者提供更为精确的诊断信息和治疗建议。
查邻居,查路径,再结合,和查邻居和邻居的邻居区别?
查邻居和查路径再结合的操作能够揭示节点之间复杂的直接和间接关系,而查邻居和邻居的邻居仅涉及到简单的、多一层的直接关系探索,缺乏深入的路径分析和复杂关系的整合。
应用可能的问题
思想实验,在实际场景可能遇到的问题:
- 节点堆积
- 大量无用文本和推理速度变慢
- 大量相似度节点
- 提示词写死无法适配环境

我们将具体问题按逻辑关系进行拆解,并逐步提出详细的解决方案。
可能问题
- 节点堆积
- 大量无用文本
- 推理速度变慢
- 大量相似度节点
- 提示词写死,无法适配环境
- 可靠性问题,没有机制,去复验生成结果的
解决节点堆积问题
- 子解法1:优化节点选择算法
- 原因:确保仅选择最相关的节点,减少不必要的节点堆积。
- 步骤:
- 使用基于重要度评分的过滤器。
- 实现节点权重动态调整算法,确保关键节点优先处理。
- 子解法2:引入节点压缩技术
- 原因:通过合并相似节点,减少节点数量。
- 步骤:
- 使用聚类算法合并相似节点。
- 定期清理冗余节点,保持节点集合精简。
减少无用文本
- 子解法1:改进文本生成规则
- 原因:确保生成的文本与查询密切相关。
- 步骤:
- 在生成过程中加入上下文相关性检测。
- 设定生成文本的质量门槛,过滤低质量文本。
- 子解法2:增强文本过滤机制
- 原因:有效过滤掉无关或低质量的文本。
- 步骤:
- 使用自然语言处理(nlp)技术对生成文本进行语义分析。
- 实现自动过滤无关内容的算法。
提高推理速度
- 子解法1:优化推理算法
- 原因:加速推理过程,减少处理时间。
- 步骤:
- 实现并行处理机制,分段推理。
- 使用缓存机制存储常用推理路径,减少重复计算。
- 子解法2:精简推理路径
- 原因:减少推理路径中的冗余步骤。
- 步骤:
- 使用优化算法精简推理路径。
- 定期评估和更新推理路径,保持路径高效。
知识图谱不用 neo4j,改成 nebula graph (开源分布式图数据库,千亿顶点和万亿边仅毫秒级查询延时)。
减少相似度节点
- 子解法1:改进相似度计算方法
- 原因:确保相似度计算更加精准,减少相似度节点的生成。
- 步骤:
- 使用更高级的相似度计算算法(如bert)。
- 实现动态相似度阈值调整,确保相似度节点的准确性。
- 子解法2:引入相似节点合并机制
- 原因:通过合并相似节点,减少重复信息。
- 步骤:
- 使用聚类算法合并相似节点。
- 实现节点合并后的信息整合算法。
优化提示词设计
- 子解法1:使用动态提示词生成
- 原因:确保提示词能够适应不同查询环境。
- 步骤:
- 实现基于上下文的提示词动态生成算法。
- 使用机器学习模型预测最优提示词组合。
- 子解法2:定期更新提示词库
- 原因:保持提示词库的最新和适应性。
- 步骤:
- 定期收集和分析用户查询,更新提示词库。
- 实现自动化提示词测试和验证机制。
优化节点选择算法
- 目的:解决节点堆积问题
- 子解法1:优化节点选择算法
- 原因:确保仅选择最相关的节点,减少不必要的节点堆积。
- 步骤:
- 使用基于重要度评分的过滤器:通过为每个节点分配重要度评分,过滤掉低重要度节点。
- 实现节点权重动态调整算法,确保关键节点优先处理:根据上下文动态调整节点的权重,优先处理最关键的节点。
- 子解法1:优化节点选择算法
可靠性问题,没有机制,去复验生成结果的
少了评估校准,这个工作流是很理想化。
到了真正工作的过程中,需要一个机制,去复验生成结果的。
作者想法:其实可以采用用知识图谱反验证的形式,对结果进行调控。输入的事实准确度还是会对最后结果影响挺大的,可以做一下噪声处理或者采用知识编辑的方式,交叉验证。
推理算法分析
证据图挖掘阶段,主要是知识图谱驱动的,侧重于从庞大的结构化数据中提取相关信息,知识图谱提供了结构化的数据支持,而大模型则辅助进行语义分析和实体识别。
证据图聚合阶段,则是大模型推理的,侧重于使用这些信息进行有效的逻辑推理和答案生成,目的是将挖掘阶段得到的多个子图合成一个统一的、能够支持答案生成的推理图。
阶段1: 证据图挖掘(数据输入 => 实体识别,实体 => 子图)
实体识别
- 隐性步骤:识别与问题直接相关的关键实体,并从大量无关数据中筛选出重要信息。
- 关键方法:使用自然语言处理工具(如命名实体识别)自动标记文本中的实体,并利用机器学习模型进行实体的重要性评分,从而优先处理与问题最相关的实体。
子图探索
- 隐性步骤:从识别的实体出发,确定这些实体间的潜在联系和结构。
- 关键方法:采用图遍历算法(如深度优先搜索或广度优先搜索)来探索实体间的所有可能关系,并根据关系的强度和相关性生成子图。引入启发式规则来剪枝,避免无关或边缘的实体关系影响图的质量。
阶段2: 证据图聚合(子图 => 推理图)
- 隐性步骤:合并多个子图中的信息,构建一个统一的、可以表达问题复杂性的推理图。
- 关键方法:实现一个图合并算法,该算法可以识别和整合重叠的信息点,消除矛盾,保持信息的完整性。使用图聚类技术来识别相似的图模式并合并,优化信息的表示和存储。
阶段3: llm利用脑图推理(推理图 => 输出)
-
隐性步骤:利用合成的推理图,指导llm进行逻辑推理,并生成解答。
-
关键方法:开发一个图理解的语言模型提示系统,将图的结构和实体关系转化为文本描述,使llm能够理解并运用这些信息。
结合推理链提示技术,指导模型沿着正确的推理路径前进,从而生成准确的答案。
验证和优化
- 关键步骤:对以上每一步定义的方法进行系统测试,包括单元测试和集成测试,以验证方法的有效性和效率。
- 方法:实施迭代优化,根据测试结果对方法进行调整,使用模拟数据和真实场景数据进行压力测试和性能评估,确保解决方案的稳定性和可靠性。
全流程问题分析
实体识别阶段问题
实体识别可能受限于上下文理解的精确性,尤其是在复杂或含糊的文本中,可能导致错误或遗漏关键实体。

子图探索阶段问题
子图探索可能无法有效捕捉复杂或间接的实体关系,导致推理图不完整或错误。
图神经网络优化:利用图神经网络(gnn)来识别和学习实体间的复杂关系模式。
证据图聚合阶段问题
据图聚合可能会因为信息过载导致重要信息丢失或推理路径不明确。
优化方案:
- 信息权重系统:为不同的证据分配权重,根据其对最终推理结果的贡献度来优先处理。
- 层次化处理:引入层次化的处理方法,先处理高级别(重要性高)的关系,逐步向下细化。
llm利用脑图推理阶段问题
llm可能在解释复杂推理图时出现理解偏差,或生成不准确的推理结果。
优化方案:
- 推理链优化:增强模型在理解复杂逻辑链条方面的能力,通过改进训练数据集和优化训练策略。
- 反馈机制:引入用户或专家的反馈,用于不断校正和提升llm的推理准确性。



发表评论