
目录
一、研究背景
超市作为零售业的主要形式之一,在现代都市生活中扮演着重要角色。随着社会经济的发展和消费者需求的变化,超市经营者越来越意识到了客户细分的重要性。不同的客户群体有着不同的购物习惯、消费行为和偏好,了解并满足不同客户群体的需求,可以帮助超市提供更加个性化的服务和商品推荐,从而提升客户的满意度和忠诚度,促进超市的经营发展。
为了实现客户细分,研究者和业界常常采用聚类分析的方法。kmeans算法作为一种常见的聚类算法,具有计算效率高、易于理解和实现的优点,被广泛应用于客户细分领域。
因此,本实验旨在使用kmeans算法对超市客户进行聚类分群,从而识别出不同的客户群体,并分析这些群体的特征和行为习惯。通过这种客户细分的方式,超市经营者可以更好地了解其客户群体,优化产品陈列和推广策略,提供更加个性化的购物体验,增加客户的购买频率和客单价,从而实现超市业务的增长和盈利能力的提升。
二、算法原理
k-means算法是一种简单的迭代型聚类算法,采用距离作为相似性指标,从而发现给定数据集中的k个类,且每个类的中心是根据类中所有值的均值得到,每个类用聚类中心来描述。对于给定的一个包含n个d维数据点的数据集x以及要分得的类别k,选取欧式距离作为相似度指标,聚类目标是使得各类的聚类平方和最小,即最小化。
结合最小二乘法和拉格朗日原理,聚类中心为对应类别中各数据点的平均值,同时为了使得算法收敛,在迭代过程中,应使最终的聚类中心尽可能的不变。
k-means是一个反复迭代的过程,算法分为四个步骤:
1)选取数据空间中的k个对象作为初始中心,每个对象代表一个聚类中心;
2)对于样本中的数据对象,根据它们与这些聚类中心的欧氏距离,按距离最近的准则将它们分到距离它们最近的聚类中心(最相似)所对应的类;
3)更新聚类中心:将每个类别中所有对象所对应的均值作为该类别的聚类中心,计算目标函数的值;
4)判断聚类中心和目标函数的值是否发生改变,若不变,则输出结果,若改变,则返回2)。
三、实验步骤
3.1加载数据集
首先导入本次实验用到的第三方库和数据集
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(font='simhei')
import warnings
warnings.filterwarnings('ignore')
# 读取数据
data = pd.read_csv('mall_customers.csv')
data.head()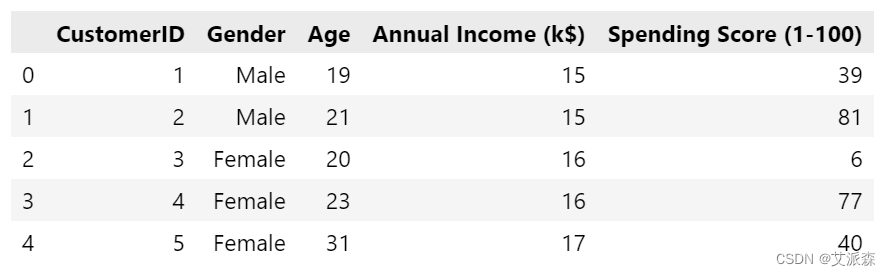
使用shape属性查看数据大小

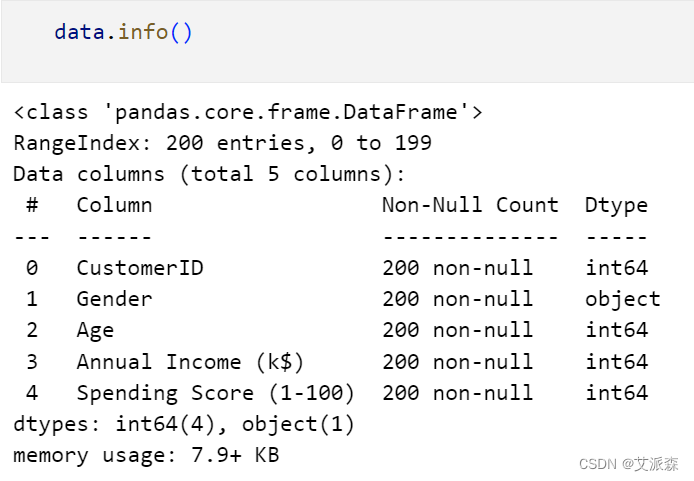
使用info函数查看数据基本信息
3.2数据预处理
这里我们需要将性别变量进行编码转化

3.3确定聚类参数k
方法1:肘部法则
肘部法则(elbow method)是一种常用于确定kmeans聚类算法中参数k的方法。该方法通过绘制不同k值对应的聚类误差(通常是sse,sum of squared errors)的折线图,来寻找一个“肘点”,该点对应的k值即为较为合适的聚类数。
以下是使用肘部法则确定k的步骤:
-
选择一定范围的k值:首先,确定一个k值的范围,一般从较小的k开始,例如1到10或者更大的范围,具体根据问题的复杂程度而定。
-
计算聚类误差(sse):对于每一个k值,使用kmeans算法进行聚类,并计算每个数据点到其所属簇中心的距离之和的平方,即sse。sse是衡量聚类效果的指标,表示样本点与其所属簇中心的紧密程度。
-
绘制肘部法则图:将不同k值对应的sse绘制成折线图(k-sse曲线图)。横坐标为k值,纵坐标为对应的sse值。
-
寻找“肘点”:观察k-sse曲线图,通常会出现一个明显的拐点,即曲线从下降阶段转为平缓下降或持平阶段的位置。这个拐点所对应的k值,即为肘部法则确定的较为合适的聚类数。
请注意,肘部法则并不是一个绝对准确的方法,有时候k-sse曲线可能没有明显的肘点,或者存在多个肘点。在实际应用中,我们可以结合领域知识和业务需求,综合考虑选择最合适的k值。另外,还可以尝试其他聚类评估指标(如轮廓系数、dbi等)来辅助确定最佳的k值。
from sklearn.cluster import kmeans
new_df = data.drop('customerid',axis=1)
# 肘部法则
loss = []
for i in range(2,10):
model = kmeans(n_clusters=i).fit(new_df)
loss.append(model.inertia_)
plt.plot(range(2,10),loss)
plt.xlabel('k')
plt.ylabel('loss')
plt.show() 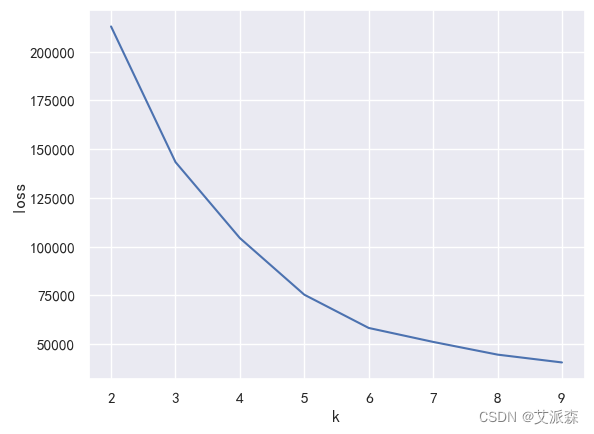
方法2:轮廓系数
轮廓系数(silhouette coefficient)是一种用于评估聚类质量的指标,可以帮助确定kmeans聚类算法中最佳的聚类数k。它结合了聚类的紧密度(簇内样本距离平均值)和分离度(不同簇之间样本距离平均值),从而提供一个综合的聚类效果评估。
轮廓系数的计算过程如下:
-
对于每个数据点,首先计算它与同簇其他数据点的平均距离,称为a(簇内紧密度)。
-
然后,对于每个数据点,计算它与其他簇中所有数据点的平均距离,找到其中最近的一个平均距离,称为b(簇间分离度)。
-
计算每个数据点的轮廓系数:s = (b - a) / max(a, b)
-
对于整个数据集,计算所有数据点的轮廓系数的平均值,作为整个聚类的轮廓系数。
轮廓系数的取值范围在-1到1之间:
- 如果轮廓系数接近于1,则表示簇内样本紧密度高,簇间分离度较好,聚类效果较好。
- 如果轮廓系数接近于-1,则表示簇内样本紧密度较低,簇间分离度不好,聚类效果较差。
- 如果轮廓系数接近于0,则表示簇内外样本的距离相差不大,聚类效果一般。
通常来说,较高的轮廓系数意味着更好的聚类效果。在使用轮廓系数确定k值时,我们可以尝试不同的k值,计算对应的轮廓系数,选择轮廓系数最大的k值作为最佳的聚类数。但是,需要注意的是,轮廓系数也有一定的局限性,特别是在数据分布不均匀或者聚类间有重叠的情况下,可能不适用于评估聚类效果。因此,综合考虑多种评估指标和领域知识,能够更全面地确定最佳的聚类数。
# 轮廓系数
from sklearn.metrics import silhouette_score
score = []
for i in range(2,10):
model = kmeans(n_clusters=i).fit(new_df)
score.append(silhouette_score(new_df, model.labels_, metric='euclidean'))
plt.plot(range(2,10),score)
plt.xlabel('k')
plt.ylabel('silhouette_score')
plt.show()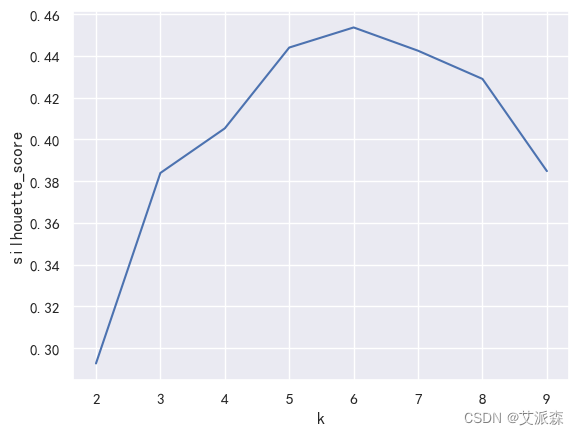
通过两种方法的结合,我们观察出最佳的聚类个数应该为k=6。
3.4 kmeans聚类
from sklearn.metrics import silhouette_score
kmeans = kmeans(n_jobs = -1, n_clusters = 6, init='k-means++')
kmeans.fit(new_df)
print(silhouette_score(new_df, kmeans.labels_, metric='euclidean'))0.45206493204632353将聚类结果进行可视化展示
clusters = kmeans.fit_predict(data.iloc[:,1:])
new_df["label"] = clusters
fig = plt.figure(figsize=(21,10))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(new_df.age[new_df.label == 0], new_df["annual income (k$)"][new_df.label == 0], new_df["spending score (1-100)"][new_df.label == 0], c='blue', s=60)
ax.scatter(new_df.age[new_df.label == 1], new_df["annual income (k$)"][new_df.label == 1], new_df["spending score (1-100)"][new_df.label == 1], c='red', s=60)
ax.scatter(new_df.age[new_df.label == 2], new_df["annual income (k$)"][new_df.label == 2], new_df["spending score (1-100)"][new_df.label == 2], c='green', s=60)
ax.scatter(new_df.age[new_df.label == 3], new_df["annual income (k$)"][new_df.label == 3], new_df["spending score (1-100)"][new_df.label == 3], c='orange', s=60)
ax.scatter(new_df.age[new_df.label == 4], new_df["annual income (k$)"][new_df.label == 4], new_df["spending score (1-100)"][new_df.label == 4], c='black', s=60)
ax.scatter(new_df.age[new_df.label == 5], new_df["annual income (k$)"][new_df.label == 5], new_df["spending score (1-100)"][new_df.label == 5], c='purple', s=60)
ax.view_init(30, 185)
plt.show()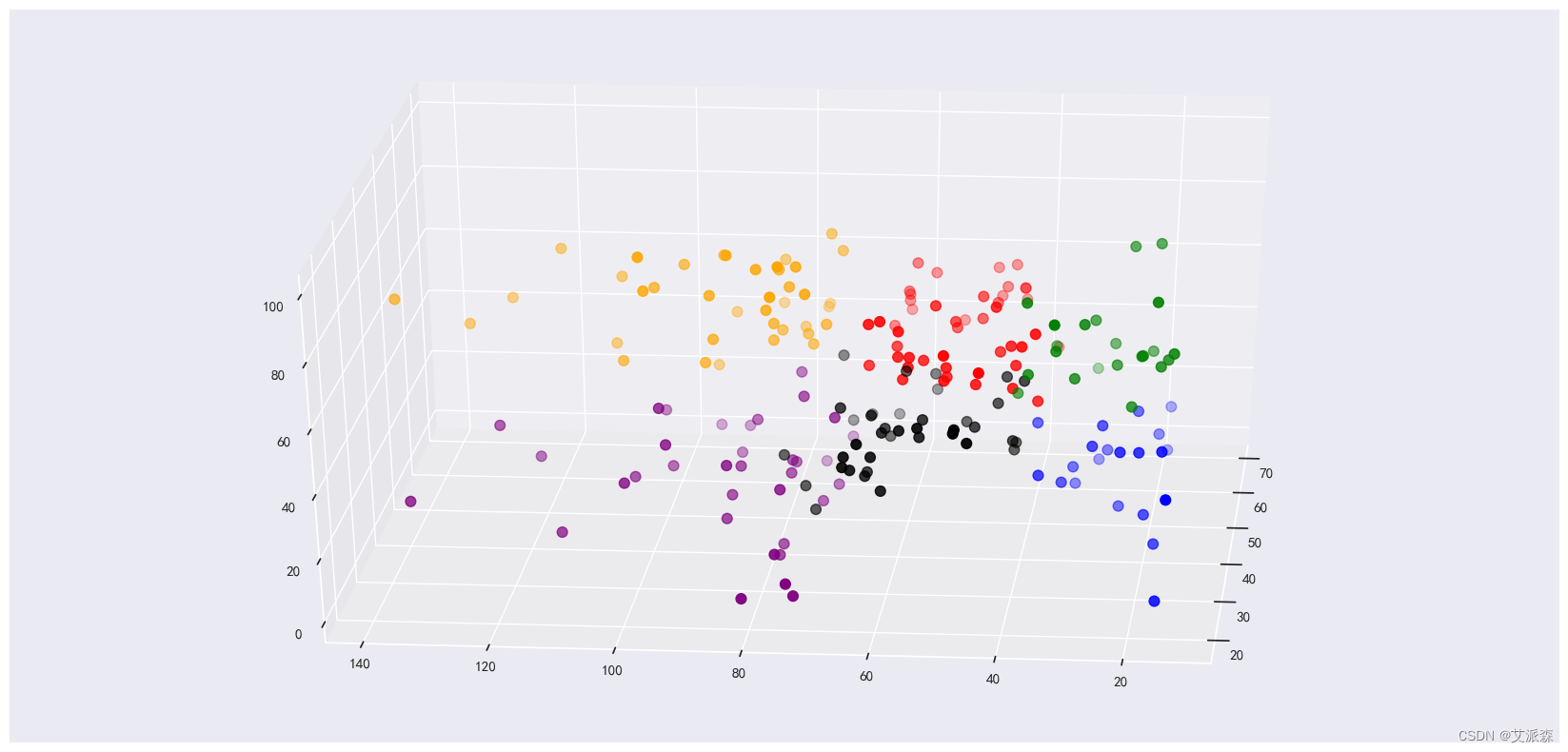
3.5聚类结果
查看各聚类类别的个数
data['label'] = clusters
print(data['label'].value_counts())
data.head()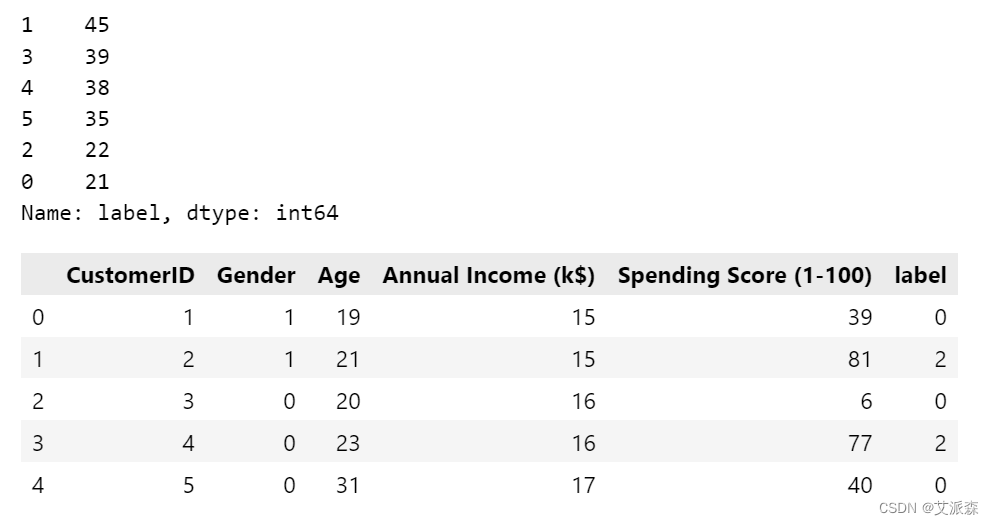
分析各类别的变量差异
avg_df = data.groupby(['label'], as_index=false).mean()
plt.figure(figsize=(10,8))
plt.subplot(2,2,1)
sns.barplot(x='label',y='age',data=avg_df)
plt.subplot(2,2,2)
sns.barplot(x='label',y='gender',data=avg_df)
plt.subplot(2,2,3)
sns.barplot(x='label',y='spending score (1-100)',data=avg_df)
plt.subplot(2,2,4)
sns.barplot(x='label',y='annual income (k$)',data=avg_df)
plt.show()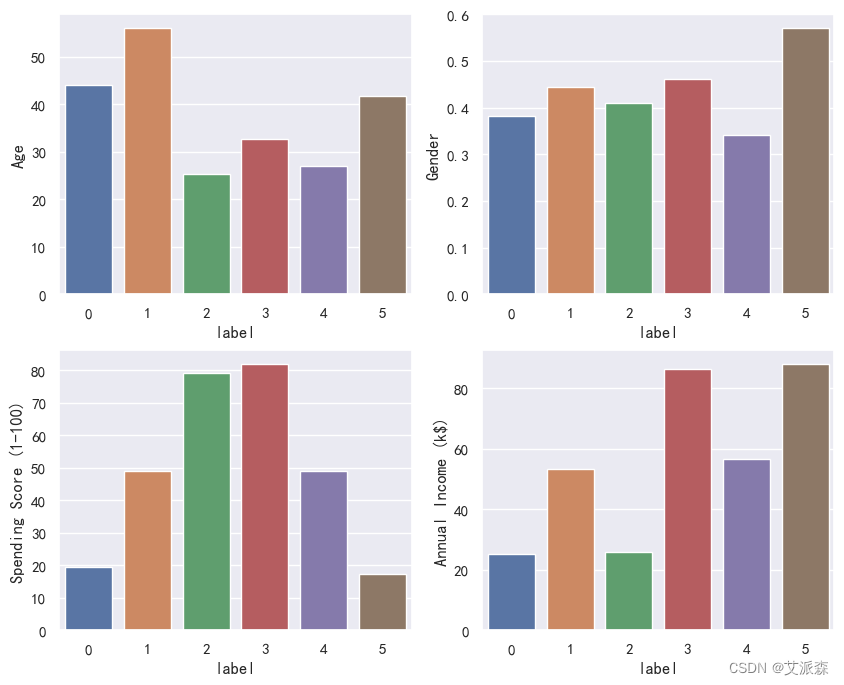
通过图表我们可得出以下结论:
各细分市场的主要特点
簇类0:
低收入,低消费能力。
平均年龄在40岁左右,性别以女性为主。
簇类1:
中等收入,中等消费能力。
平均年龄在55岁左右,性别以女性为主。
簇类2:
低收入,高消费能力。
平均年龄在25岁左右,性别以女性为主。
簇类3:
高收入,高消费能力。
平均年龄在30岁左右,性别以女性为主。
簇类4:
中等收入,中等消费能力。
平均年龄在30岁左右,性别以女性为主。
簇类5:
高收入,低消费能力。
平均年龄在40岁左右,性别以男性为主。
四、总结
本实验基于kmeans算法对超市客户进行了聚类分群。通过对客户购物数据进行聚类,我们成功将客户分为不同的群体。每个群体代表了具有相似购物行为和偏好的客户群体。通过实验结果,我们发现了客户群体之间的明显差异和共性。不同群体的客户在购买频率、购物金额和购买种类等方面有所区别。这为超市提供了重要的市场细分信息,帮助超市经营者更好地了解不同客户群体的需求和喜好,制定有针对性的营销策略和商品推荐,提高客户满意度和忠诚度。此外,实验还揭示了超市客户的购物行为规律,为超市优化商品陈列和促销策略提供了指导。通过针对不同客户群体推出个性化的促销活动,超市可以更有效地吸引客户,提升销售额和利润。
完整代码
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(font='simhei')
import warnings
warnings.filterwarnings('ignore')
# 读取数据
data = pd.read_csv('mall_customers.csv')
data.head()
data.shape
data.info()
data['gender'].replace(to_replace={'female':0,'male':1},inplace=true)
data.head()
from sklearn.cluster import kmeans
new_df = data.drop('customerid',axis=1)
# 肘部法则
loss = []
for i in range(2,10):
model = kmeans(n_clusters=i).fit(new_df)
loss.append(model.inertia_)
plt.plot(range(2,10),loss)
plt.xlabel('k')
plt.ylabel('loss')
plt.show()
# 轮廓分数
from sklearn.metrics import silhouette_score
score = []
for i in range(2,10):
model = kmeans(n_clusters=i).fit(new_df)
score.append(silhouette_score(new_df, model.labels_, metric='euclidean'))
plt.plot(range(2,10),score)
plt.xlabel('k')
plt.ylabel('silhouette_score')
plt.show()
from sklearn.metrics import silhouette_score
kmeans = kmeans(n_jobs = -1, n_clusters = 6, init='k-means++')
kmeans.fit(new_df)
print(silhouette_score(new_df, kmeans.labels_, metric='euclidean'))
clusters = kmeans.fit_predict(data.iloc[:,1:])
new_df["label"] = clusters
fig = plt.figure(figsize=(21,10))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(new_df.age[new_df.label == 0], new_df["annual income (k$)"][new_df.label == 0], new_df["spending score (1-100)"][new_df.label == 0], c='blue', s=60)
ax.scatter(new_df.age[new_df.label == 1], new_df["annual income (k$)"][new_df.label == 1], new_df["spending score (1-100)"][new_df.label == 1], c='red', s=60)
ax.scatter(new_df.age[new_df.label == 2], new_df["annual income (k$)"][new_df.label == 2], new_df["spending score (1-100)"][new_df.label == 2], c='green', s=60)
ax.scatter(new_df.age[new_df.label == 3], new_df["annual income (k$)"][new_df.label == 3], new_df["spending score (1-100)"][new_df.label == 3], c='orange', s=60)
ax.scatter(new_df.age[new_df.label == 4], new_df["annual income (k$)"][new_df.label == 4], new_df["spending score (1-100)"][new_df.label == 4], c='black', s=60)
ax.scatter(new_df.age[new_df.label == 5], new_df["annual income (k$)"][new_df.label == 5], new_df["spending score (1-100)"][new_df.label == 5], c='purple', s=60)
ax.view_init(30, 185)
plt.show()
data['label'] = clusters
print(data['label'].value_counts())
data.head()
avg_df = data.groupby(['label'], as_index=false).mean()
avg_df
plt.figure(figsize=(10,8))
plt.subplot(2,2,1)
sns.barplot(x='label',y='age',data=avg_df)
plt.subplot(2,2,2)
sns.barplot(x='label',y='gender',data=avg_df)
plt.subplot(2,2,3)
sns.barplot(x='label',y='spending score (1-100)',data=avg_df)
plt.subplot(2,2,4)
sns.barplot(x='label',y='annual income (k$)',data=avg_df)
plt.show()
文末推荐
文末福利
发表评论