目录
原论文
综述
vits(variational inference with adversarial learning for end-to-end text-to-speech)是一种并行的端到端tts方法。采用变分推理,并辅以归一化流程和对抗训练过程,产生更自然的音频。使用一种随机持续时间预测器,用于从输入文本中合成具有不同节奏的声音。通过对潜在变量的不确定性建模和随机持续时间预测器,vits表达了自然的一对多关系,即文本输入可以以多种方式以不同的音高和节奏说出。
传统的tts(文本转语音)系统流水线除了文本规范化和音素化等文本预处理以外,被简化为两阶段生成建模,第一阶段是从预处理文本中产生中间语音表示(梅尔谱图或语言特征),第二阶段是生成以中间表示为条件的原始波形。基于神经网络的自回归tts系统已显示出合成真实语音的能力,但其每个时间步的输出依赖于之前的输出,生成速度较慢。
而vits是一种并行的端到端的tts方法,使用变分自动编码器(vae),通过潜在变量连接tts系统的两个模块,以实现高效的端到端学习,为了合成高质量的语音波形,将归一化流应用于波形域上的条件先验分布和对抗训练。通过随机持续时间预测器从输入文本中合成具有不同节奏的语音。总之,通过对潜在变量的不确定性建模和随机持续时间预测器,可以获得更自然的语音变化。
模块架构
训练程序和推理程序系统图
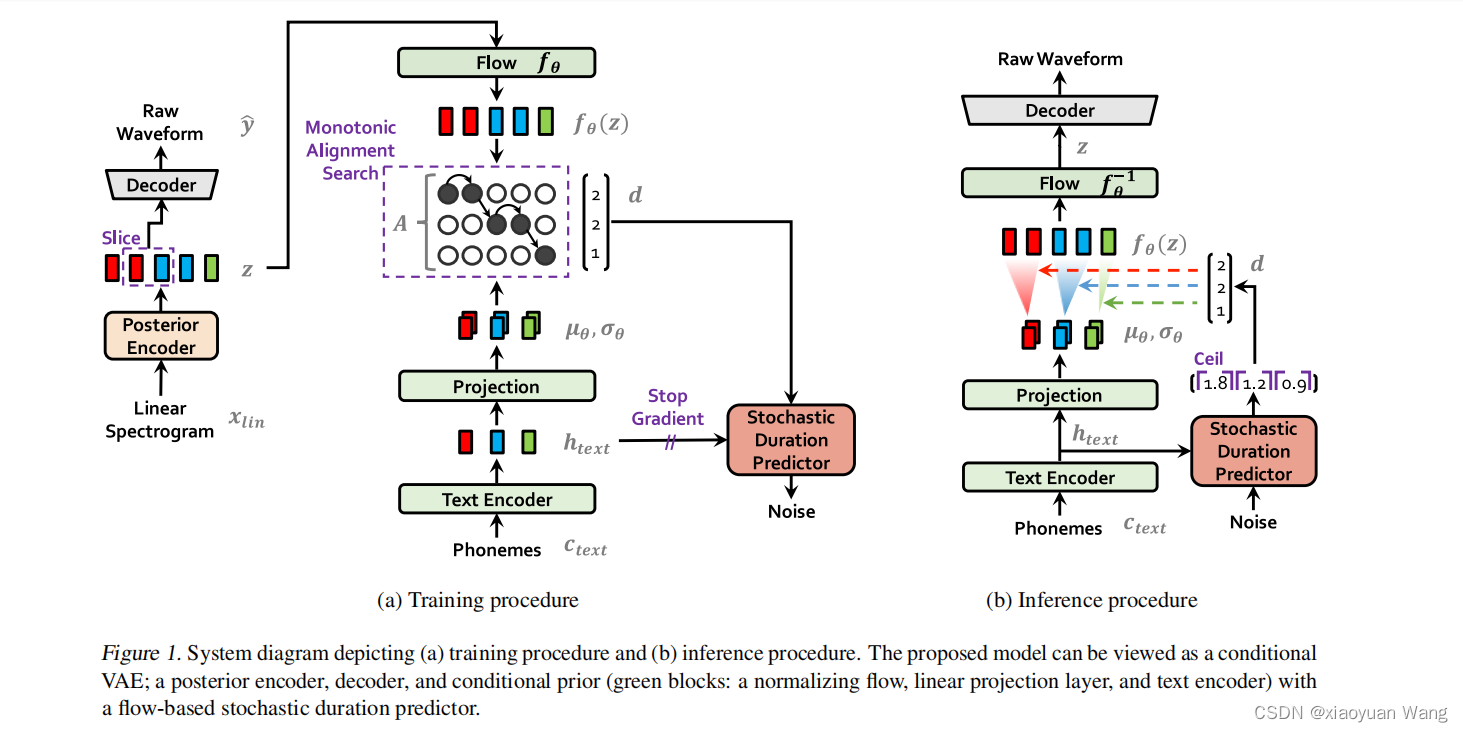
上图架构由:后验编码器、先验编码器、解码器、基于流的随机持续时间预测器组成,左图为训练过程,右图为推理过程。
各个模块及方法
条件变分自编码器(vae)
条件vae的目的是最大化数据对数似然的变分下界,也称为证据下界(elbo)。elbo可以用来估计vae模型的训练误差,并且可以通过优化elbo来训练模型。eblo由两部分组成:重建损失(reconstruction loss)和kl散度(kl-divergence),我们希望最大化eblo,以使得生成模型的似然性不断提高,学习到一个生成数据分布(潜在变量的概率分布),该分布可以用于生成与原始数据相似的新数据样本。
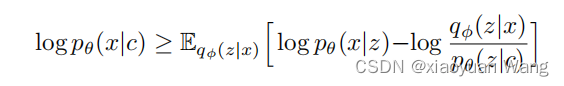
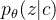 表示给定条件 c 的潜在变量 z 的先验分布,
表示给定条件 c 的潜在变量 z 的先验分布,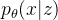 是数据点 x 的似然函数,
是数据点 x 的似然函数,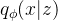 是近似后验分布。那么训练损失就是负elbo,可以看作是重建损失
是近似后验分布。那么训练损失就是负elbo,可以看作是重建损失 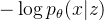 和 kl 散度
和 kl 散度 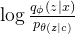 的总和,其中 z ∼
的总和,其中 z ∼ 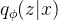 。整体来说,要使后验分布和条件先验分布越接近,使输入音素和经过解码器生成音素相似(从后验编码器生成的分布中采样z,再用z生成x期望最大)。
。整体来说,要使后验分布和条件先验分布越接近,使输入音素和经过解码器生成音素相似(从后验编码器生成的分布中采样z,再用z生成x期望最大)。
1.先验编码器
先验编码器由一个文本编码器组成,该编码器处理输入音素(由文本生成的符号序列国际音标ipa序列)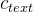 和一个归一化流
和一个归一化流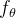 ,从而提高先验分布的灵活性,先验编码器c输入条件由本文中提取的音素以及音素和z之间的对齐方式a组成,所谓的对齐就是
,从而提高先验分布的灵活性,先验编码器c输入条件由本文中提取的音素以及音素和z之间的对齐方式a组成,所谓的对齐就是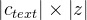 大小的严格单调注意力矩阵,表示每一个音素的发音时长。由于对齐没有基本实况标签,必须估计每次训练迭代的对齐情况。因此kl散度为:
大小的严格单调注意力矩阵,表示每一个音素的发音时长。由于对齐没有基本实况标签,必须估计每次训练迭代的对齐情况。因此kl散度为:
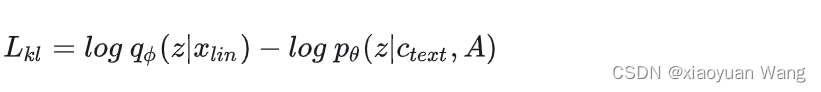
其中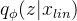 表示给定数据点
表示给定数据点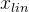 的后验分布,
的后验分布,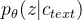 表示表示给定条件的潜在变量 z的先验分布,为输入后验编码器的目标语音的线性谱,隐变量z为:
表示表示给定条件的潜在变量 z的先验分布,为输入后验编码器的目标语音的线性谱,隐变量z为:
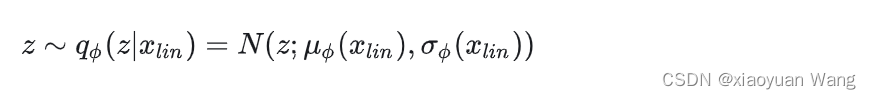
vits通过文本编码器和文本编码器上方的线性投影层获得隐藏表示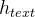 ,该投影层产生用于构建先验分布的均值
,该投影层产生用于构建先验分布的均值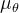 和方差
和方差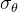 。
。
为了增加先验分布的表现力以生成逼真样本,vits使用了归一化流,将简单先验分布转为更复杂的先验分布: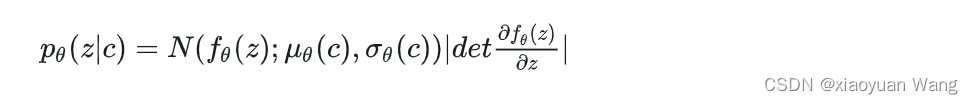

归一化流程是一叠仿射耦合层,由一堆wavenet残差块组成,将归一化流设计为雅可比行列式为1的保容变换,在多扬声器设置中,通过全局调节的方法将扬声器嵌入到归一化流中的残余块中。
2.后验编码器
为了给后验编码器提供更多分辨率信息,因此使用目标语音的的线性谱(短时傅里叶变换stft获得)作为后验编码器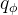 的输入。后验编码器由wavenet残差块构成,块上方的线性投影层产生用于构建后验分布的均值
的输入。后验编码器由wavenet残差块构成,块上方的线性投影层产生用于构建后验分布的均值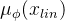 和方差
和方差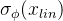 ,对于多扬声器设置,在残差块中使用全局条件来添加扬声器的嵌入。vits在训练时实际还是会以生成梅尔频谱来指导模型训练,重建损失中的目标样本点使用的是梅尔频谱,不是原始波形,用
,对于多扬声器设置,在残差块中使用全局条件来添加扬声器的嵌入。vits在训练时实际还是会以生成梅尔频谱来指导模型训练,重建损失中的目标样本点使用的是梅尔频谱,不是原始波形,用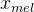 表示,通过解码器将z上采样到波形域
表示,通过解码器将z上采样到波形域 ,并将转换到频谱图域
,并将转换到频谱图域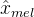 ,然后将预测和目标梅尔频谱之间的loss作为重建损失:
,然后将预测和目标梅尔频谱之间的loss作为重建损失:
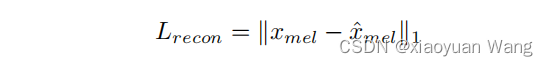
在实践中,只采样潜在变量z的部分序列作为解码器的输入。
归一化流(flow)
flow本身作用就是直接构建两个分布之间的映射函数可以双向进行转换,来完成线性谱输入的后验分布到先验分布之间的转换,增加模型表示能力。
gan对抗训练(gan)
vits为了在系统中使用对抗训练,在解码器g后添加了鉴别器d,输入真实波形y和解码器生成的波形g(z),区分解码器生成的输出和真实波形。使用了两种成功应用于语音合成的模型:用于对抗训练的最小二乘损失函数,和用于训练生成器的附加特征匹配损失。g(z)被称为虚假样本,鉴别器d与解码器(也可以看成训练全过程)g依次交替更新,进行竞争训练:更新d时,固定g,令d能区别输入的是real(真实)或者fake(虚假)数据;更新g时,固定d,令g生成的虚假数据能够欺骗鉴别器d,而gan整体作用就是,是生成的采样数据和真实分布的采样数据尽可能相似,解码器工作时让鉴别器每一层中间也尽可能相似。
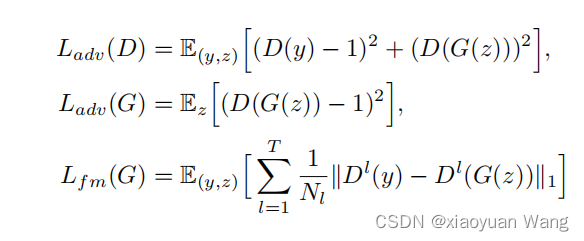
对齐估计
单调对齐搜索(mas)
为了估计输入文本和目标语音之间的对齐方式a,vits采用了单调对齐搜索(mas),该方法寻找一个最优的对齐路径以最大化利用标准化流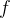 参数化数据的对数似然:
参数化数据的对数似然:
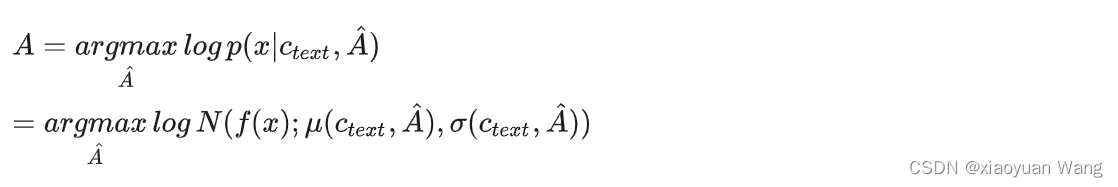
但是无法直接将mas直接应用到vits,因为vits优化目标是elbo而非确定的潜在变量z的对数似然,因此vits稍微改变了一下mas,寻找最优的对齐路径以最大化elbo,从而简化为找到最大化潜在变量z的对数似然的对齐方式:

随机持续时间预测器(spa)
随机持续时间预测器用于从文本中合成不同节奏的声音。从一个条件输入的中估计音素持续时间的分布。为了有效地参数化随机持续时间预测器,vits叠加了具有扩展和深度可分离卷积层的残差块,还将神经样条流应用于耦合层,它以可逆非线性变换的形式应用于耦合层。与常用的仿射耦合层相比,神经样条流以相似数量的参数提高了转换表达性。对于多扬声器设置,vits添加了一个线性层来转换扬声器嵌入,并将其添加到输入的中。
vits应用变分去量化和变分数据增强来解决每个输入音素持续时间是离散整数造成的一系列问题(最大似然估计的直接应用等)。具体来说,vits引入了两个随机变量u和v,它们的时间分辨率和维数与持续时间序列d的时间分辨率和维数相同,分别用于变分去量化和变分数据增强。将u的限制为[0,1),使d-u变成一个正实数序列,将ν和d通道连接起来,形成一个更高维的潜在表示,通过一个近似的后验分布 对这两个变量进行抽样。由此产生的目标是音素持续时间的对数似然值的一个变分下界:
对这两个变量进行抽样。由此产生的目标是音素持续时间的对数似然值的一个变分下界:
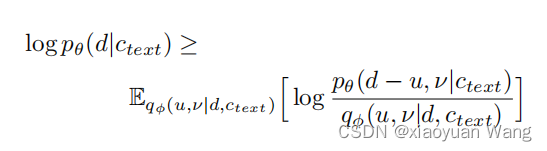
训练损失为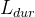 。
。
右图推理过程:通过对随机持续时间预测器的逆变换,从随机噪声中采样音素持续时间,然后将其转换为整数。
最终损失
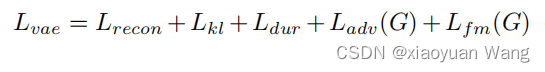
整体系统图的理解
左图为训练过程,右图为推理过程。这里只解释训练过程
训练过程将文本转为国际音标(ipa)序列作为先验编码器的输入,获得隐藏表示(估计音素持续时间的分布进入spa),其上方的线性投影层产生用于构建先验分布的均值和方差。
训练过程采样目标语音的的线性谱输入后验编码器,经过线性投影层(图中省略)生成构成后验分布的均值和方差,上采样部分序列z进入解码器形成原始音频数据再进入鉴别器进行对抗训练;部分进入flow归一化流形成更为复杂的分布与先验分布进行强制对齐,形成持续时间序列d,经过变分去量化和变分数据增强后进入spa,形成随机噪声。
模型优势
1.学习直接从文本合成原始波形不需要额外的输入条件;
2.使用动态规划方法mas来搜索最优对齐而不是计算损失;
3.并行生成样本;
4.优于最好的公开两阶段模型;
5.通过mas将潜在序列与时间对齐的源序列进行匹配,消除了将潜在序列转换为标准正态随机变量的负担,从而简化了归一化流架构。
6.spa可以学习估计音素持续时间的联合分布,从而并行产生不同的语音节奏。
参考文献
【1】tts | 保姆级端到端的语音合成vits论文详解及项目实现(超详细图文代码)_vits语音合成-csdn博客
【3】vits 语音合成完全端到端tts的里程碑-csdn博客
【4】 https://arxiv.org/pdf/2106.06103.pdf
发表评论