01 背景介绍
日志作为线上定位问题排障的重要手段,在可观测领域有着不可替代的作用。
稳定性、成本、易用性、可扩展性都是日志系统需要追求的关键点。
b站基于elastic stack的日志系统(billions) 从2017建设以来, 已经服务了超过5年,目前规模超过500台机器,每日写入日志量超过700tb。
elk体系是业界最常用的日志技术栈,在传输上以结合规范key的json作为传输格式,易于多种语言实现和解析,并支持动态结构化字段。存储上elasticsearch支持全文检索,能够快速从杂乱的日志信息中搜寻到关键字。展示上kibana具有美观、易用等特性。
随着业务系统的高速发展,日志系统的规模也随之快速扩展,我们遇到了一系列的问题,同时可观测业界随着opentelemetry规范的成熟,推动着我们重新考量,迈入下一代日志系统。 02 遇到的问题
-
首先必须要提的就是成本和稳定性。日志作为一种应用产生的实时数据,随着业务应用规模发展而紧跟着扩大。日志系统必须在具备高吞吐量的同时,也要具备较高的实时性要求。elasticsearch由于分词等特性,在写吞吐量上有着明显的瓶颈,分词耗cpu且难以解决热点问题。如果资源冗余不足,就容易导致稳定性下降,日志摄入发生延迟,日志的延迟会对排障产生极大负面影响。
-
同时由于压缩率不高的原因,es的存储成本也较高,对内存有着较高的要求。这些因素导致我们日志必须进行常态化的采样和限流,对用户使用上造成了困扰,限制了排障的场景。
-
内存使用率的问题也迫使我们必须将warm阶段的索引进行close,避免占用内存。用户如果需要查询就必须操作进行open,牺牲了一定的易用性。
-
为了稳定性和成本,动态mapping也必须被关闭,有时用户引导不到位,就会导致用户发现自己搜索的日志遗留了mapping配置而导致难以追溯查询。
-
在运维上,es7之前缺少生命周期的能力,我们必须维护一整套生命周期相关组件,来对索引进行预创建、关闭和删除,不可避免的带来高维护成本。
-
kibana虽然好用,但也不是没有缺点的,整体代码复杂,二次开发困难。且每次升级es必须升级到对应的kibana版本也增加了用户迁移的成本。还有一点就是kibana query虽然语法较为简单,但对于初次接触的研发还是有一定的学习成本的。
-
在采集和传输上,我们制定了一套内部的日志格式规范,使用json作为传输格式,并提供了java和golang的sdk。这套传输格式本身在序列化/反序列化上性能一般,且私有协议难以避免兼容性和可维护性问。
03 新架构体系 针对上述的一系列问题,我们设计了bilibili日志服务2.0的体系,主要的进化为使用clickhouse作为存储,实现了自研的日志可视化分析平台,并使用opentelemetry作为统一日志上报协议。
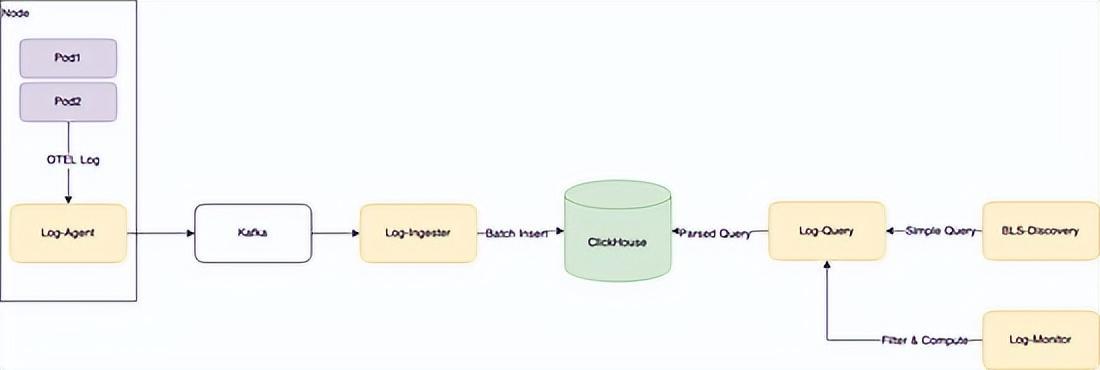
如图所示为日志实时上报和使用的全链路。日志从产生到消费会经过采集→摄入 →存储 →分析四个步骤,分别对应我们在链路上的各个组件,先做个简单的介绍:
-
otel logging sdk
-
完整实现otel logging日志模型规范和协议的结构化日志高性能sdk,提供了golang和java两个主要语言实现。
-
log-agent
-
日志采集器,以agent部署方式部署在物理机上,通过domain socket接收otel协议日志,同时进行低延迟文件日志采集,包括容器环境下的采集。支持多种format和一定的加工能力,如解析和切分等。
-
log-ingester
-
负责从日志 kafka 订阅日志数据, 然后将日志数据按时间维度和元数据维度(如appid) 拆分,并进行多队列聚合, 分别攒批写入clickhouse中.
-
clickhouse
-
我们使用的日志存储方案,在clickhouse高压缩率列式存储的基础上,配合隐式列实现了动态schema以获得更强大的查询性能,在结构化日志场景如猛虎添翼。
-
log-query
-
日志查询模块,负责对日志查询进行路由、负载均衡、缓存和限流,以及提供查询语法简化。
-
bls-discovery
-
新一代日志的可视化分析平台,提供一站式的日志检索、查询和分析,追求日志场景的高易用性,让每个研发0学习成本无障碍使用。
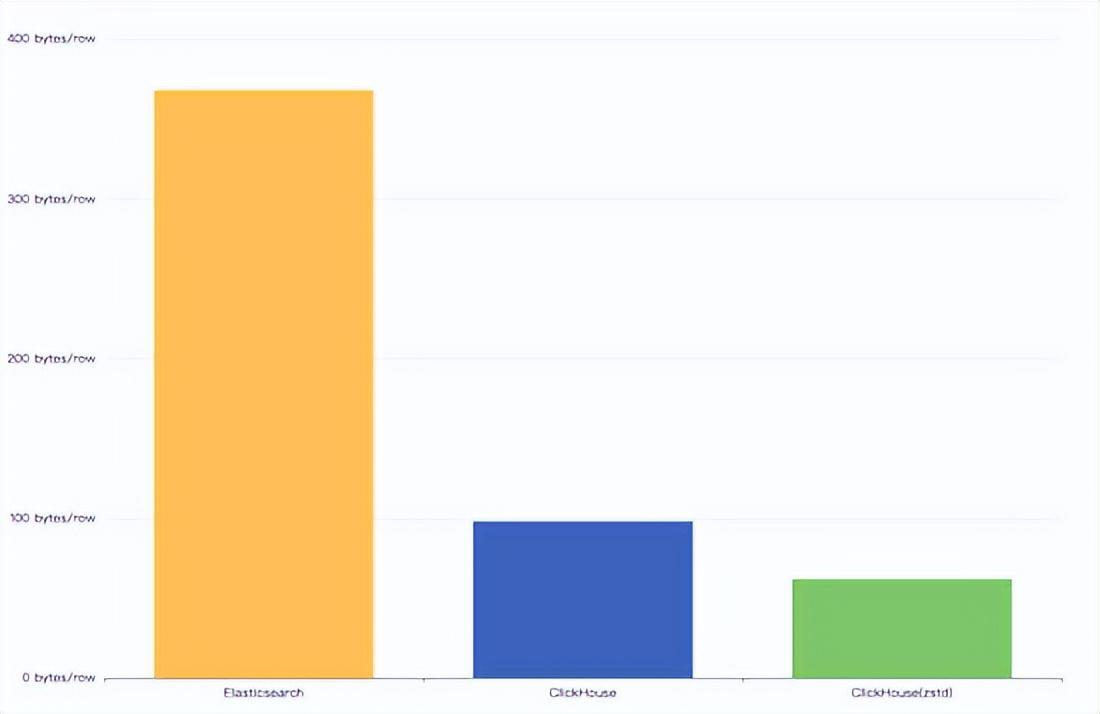
下边我们将针对几个重点进行详细设计阐述。 3.1 基于clickhouse的日志存储 新方案的最核心的部分就是我们将日志的通用存储换成了clickhouse。 先说结果,我们在用户只需要付出微小迁移成本的条件下( 转过来使用sql语法进行查询),达到了10倍的写入吞吐性能,并以原先日志系统 1/3的成本,存储了同等规模量的日志。在查询性能上,结构化字段的查询性能提升2倍, 99%的查询能够在3秒内完成。 下图为同一份日志在elasticsearch, clickhouse和clickhouse(zstd)中的容量, 最终对比es达到了 1:6。
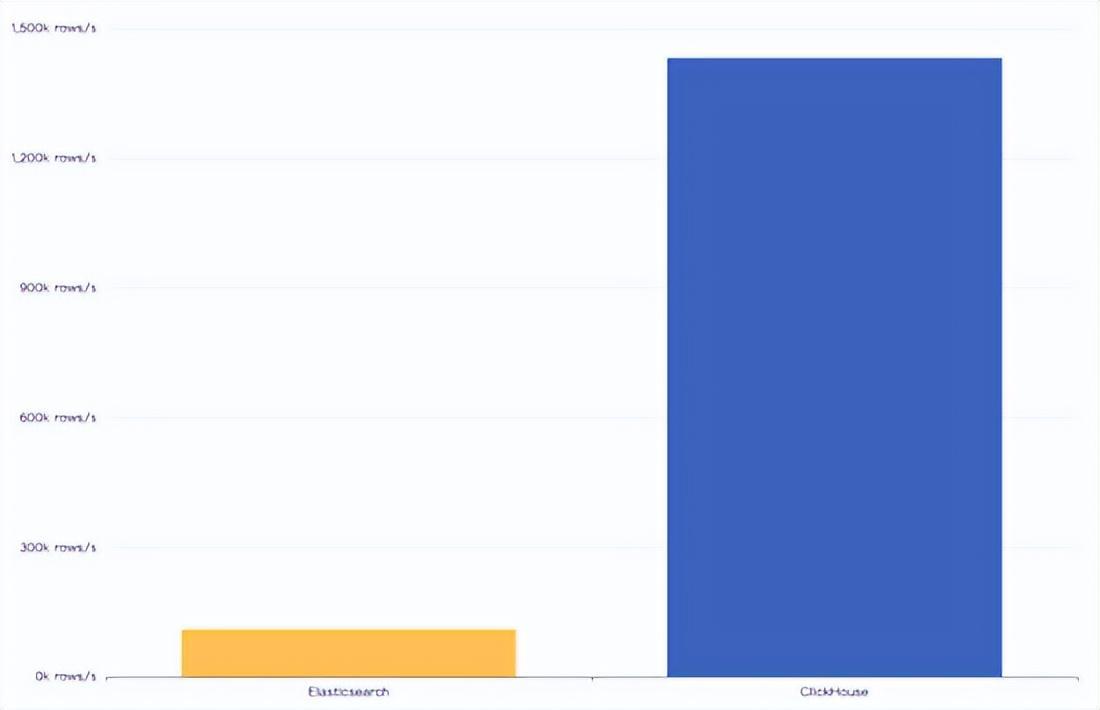
clickhouse方案里另一个最大的提升是写入性能,clickhouse的写入性能达到了es的10倍以上。
在通用结构化日志场景,用户往往是使用动态schema的,所以我们引入了隐式列map类型来存储动态字段, 以同时获得动态性和高查询性能,稍后将会重点介绍隐式列的实现。
我们的表设计如下,我们针对每个日志组,都建立了一张复制表。表中的字段分为公共字段(即otel规范的resource字段, 以及trace_id和span_id等),以及隐式列字段,string_map,number_map,bool_map 分别对应字符串字段,数字字段和布尔字段。我们对常用的日志值类型进行分组,使用这三个字段能满足大部分查询和写入的需求。





发表评论