之前碰到的一个真实案例,记录一下
先来看看左移监控:优化云应用程序的途径,以及如何使用可观察性工具对 spring boot 代码问题进行左移故障排除,从而避免生产问题、不必要的成本并提高产品质量。
通俗解释
-
传统方法 vs 左移监控:
- 传统方法:通常在开发接近尾声时,才开始进行严格的测试和监控。这时发现问题可能会导致返工,浪费时间和资源。
- 左移监控:在开发的早期阶段(左边)就开始进行监控和测试。这样可以尽早发现并解决问题,避免后期的麻烦。
-
为什么叫“左移”:
- 在项目管理的时间线上,左边代表早期阶段,右边代表后期阶段。把监控和质量保障的工作“左移”,就是提前到开发早期进行。
-
具体措施:
- 持续集成(ci):代码一提交就自动进行测试,确保每次修改没有引入新问题。
- 代码审查:开发过程中进行代码审查,及时发现和修复问题。
- 自动化测试:编写自动化测试脚本,在开发早期就进行功能和性能测试。
- 静态代码分析:使用工具在编写代码时就检测潜在的问题和漏洞。
举个例子
假设你在建造一栋房子:
- 传统方法:房子快要完工时才开始检查是否有漏水、墙体是否稳固。如果发现问题,可能需要大规模返工。
- 左移监控:在建造的每个阶段(比如地基、墙体、屋顶)都进行详细检查,发现问题立即修正。这样到最后,房子基本上不会有大问题,节省时间和成本。
左移是一种软件开发和运营方法,强调在软件开发生命周期的早期进行测试、监控和自动化。左移方法的目标是通过及早发现问题并快速解决问题来预防问题出现。
当您及早发现可扩展性问题或错误时,解决它会更快且更具成本效益。将低效代码转移到云容器可能成本高昂,因为它可能会激活自动扩展并增加您的每月账单。此外,在您能够识别、隔离和解决问题之前,您将处于紧急状态。
java spring boot 预生产故障排除
这是最近的一个现实案例,来自可观测性解决方案的数据使客户能够避免应用程序出现可能在生产环境中引起重大问题的潜在问题。
客户正在测试新版本的 java spring boot 微服务,使用 mariadb 作为后端,在 apache 反向代理和 aws 应用程序负载均衡器后面运行。在集成应用程序更改之前和之后的整个测试周期中,使用 eg enterprise 监控端到端系统。进行了预生产 uat(用户验收测试)并且所有 uat 测试用例均已通过。
然而,根据最近的应用程序更改,对 uat(用户验收测试)基础设施的 eg enterprise 性能报告进行了审查。 mariadb 性能仪表板中的性能图表与部署前的模式存在显着偏差。
调查中发现了一个严重的编码问题,凸显了在此类测试中对应用程序和基础设施行为进行基线分析的重要性。稍后我还将介绍应用程序 uat 测试成功的原因。
我将介绍 eg enterprise 捕获的关键指标和信息,使客户能够诊断和分析全栈行为。
spring boot 和 kubernetes
spring boot 是一个基于 java 的开源框架,可简化生产就绪、独立和基于 web 的应用程序的开发。 kubernetes (k8s) 旨在管理容器化应用程序,而 spring boot 应用程序非常适合微服务架构。 spring boot 的轻量级和模块化特性使开发人员能够轻松创建容器化微服务,而 kubernetes 为编排和扩展这些服务提供了一个出色的平台。
java spring boot 应用程序迁移的时间表
8 月 6 日 14:13,应用程序使用包含嵌入式 tomcat 的新 spring boot jar 文件重新启动。
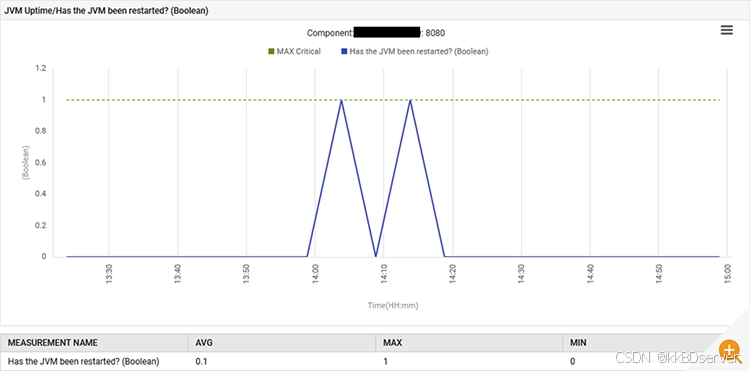
14:52,mariadb 的查询处理速率从每秒 0.1 个查询增加到每秒 88 个查询,然后增加到每秒 301 个查询。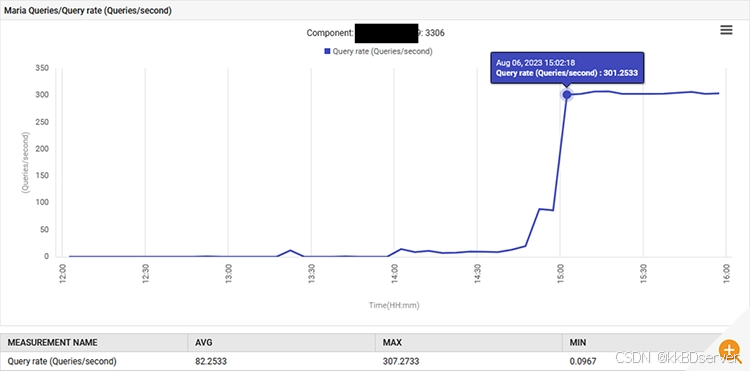
此外,系统 cpu 利用率从 1% 提升至 6%。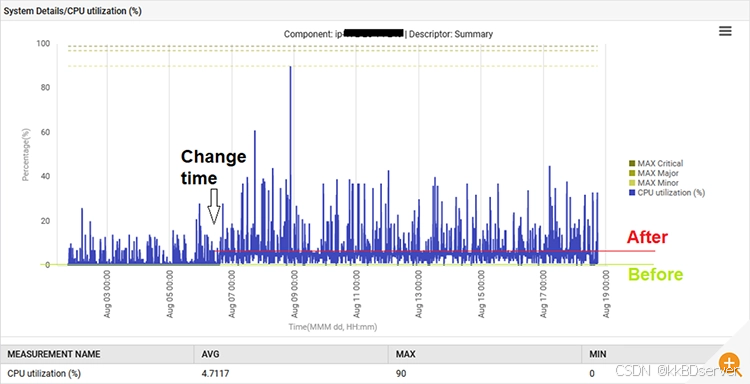
最后,花在 g1 年轻代垃圾收集上的 jvm 时间从 0% 增加到 0.1%,并保持在该水平。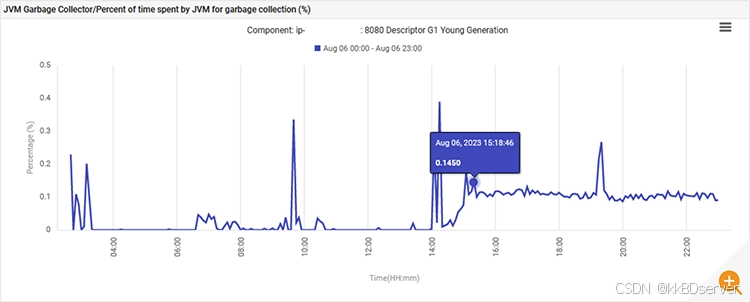
该应用程序在 uat 阶段表现异常,每秒发出 300 次查询,这远远超出了它的设计目标。新功能导致数据库连接增加,这就是查询增加如此惊人的原因。
监控仪表板还显示,在部署新版本之前,有问题的指标一直是正常的。
spring boot问题的解决
jpa是什么?
jpa(java persistence api)是一个基于 java 的规范和 api,用于使用 java 管理应用程序中的关系数据。 jpa 提供了一组接口和标准注释,允许 java 开发人员以既可移植又易于使用的方式与关系数据库进行交互。
该应用程序是一个 spring boot 应用程序,它使用 jpa 来查询 mariadb。该应用程序设计为在负载最小时在两个容器上运行,但预计在高峰需求下可扩展到十个容器。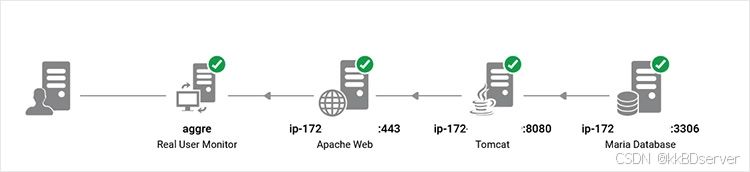
逻辑问题自然会出现——如果单个容器每秒可以生成 300 个查询,那么如果所有 10 个容器都可运行,堆栈可以每秒处理 3000 个查询吗?数据库是否有足够的连接来满足应用程序其他部分的需求?
此时我们调查了开发人员在 git 中提交的更改。这些更改相对较小,并添加了简单的功能来从表中获取一些记录并对其进行处理。然而,这是我们在服务类中观察到的。
list findall = this.xrepository.findall();
在 spring 的 crudrepository 中不合格地使用没有分页的 findall() 方法,效率不高。大多数基本的 rdbms 教程都涵盖了这一点 - 就像 sql 中 where 的使用一样,按特定标准请求记录子集比请求所有记录并按类似标准处理它们更有效。分页有助于通过限制获取的数据量来减少从数据库检索数据所需的时间。此外,分页有助于保持较低的内存使用率,以防止应用程序因数据过载而崩溃,并减少 java 虚拟机的垃圾收集工作,这在上面的问题陈述中提到过。
此测试仅使用一个容器中的 2,000 条记录进行。如果这段代码转移到生产环境(最多 10 个容器中包含大约 200,000 条记录),那么那天可能会给团队带来很大的压力和担忧。
通过在方法中添加“by”子句(相当于 sql 中 where 子句的作用)来重建应用程序。
list findall = this.xrepository.findallbyy(y);
进行此更改并重新部署应用程序后,恢复了正常行为。每秒查询次数从 300 次减少到 30 次,垃圾收集的工作量恢复到原来的水平。此外,系统的 cpu 使用率也有所下降。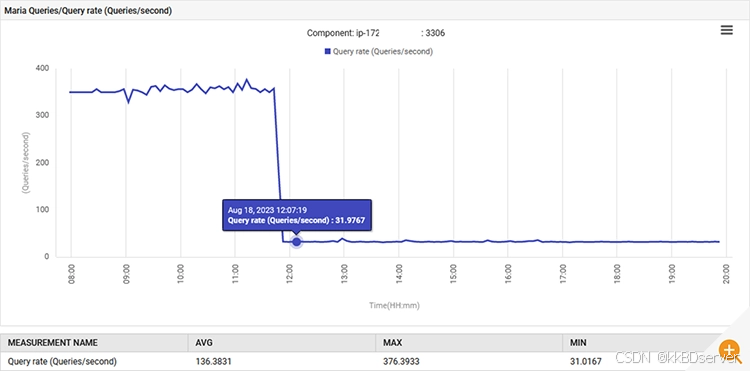
使用 eg enterprise 改进和调整生产前测试的可观测性和监控
在这种情况下,拥有参与审查数据概述的可观察性专业知识可以快速识别问题。像这样的事件使组织能够在测试期间迭代和完善其监控,以进一步自动化问题诊断。
在这种情况下,uat 测试并未实际反映生产环境的使用情况和可扩展性预期。从长远来看,客户将完善他们的测试覆盖范围。
用于 eg enterprise 警报的测试系统和相关指标阈值是专为客户的生产系统设计的,开箱即用,自然不会在 cpu 使用率达到 6% 时触发。然而,经验丰富的用户可以调整此类阈值,以利用自动基线,aiops 引擎和机器学习技术借此建立系统的正常行为,并在发生异常时自动发出警报。在这种情况下,客户可能希望在此类测试期间调整其阈值,以便在 cpu 等基础设施资源偏离既定行为 200% 时发出警报。有关利用 eg enterprise 强大的自动基线和异常检测的信息,请参阅:白皮书 |借助 aiops 支持的智能阈值和警报 (eginnovations.com),使 it 服务监控变得简单且主动。
据了解,代码更改很小,并且仅限于单个开发人员进行 git 签入,因此客户直接从 git 查找编码问题。在许多情况下,尽管应用程序的新版本将在多个 java 方法中集成来自多个开发人员的数百个更改,但诊断问题根本原因的确切方法将是一项繁琐且通常是手动的任务。在这种情况下,可以利用 eg enterprise 的全栈 devops 监控功能来识别导致速度缓慢的确切方法调用。 eg innovations 在统一控制台下提供 devops 监控,以便管理员能够全面了解部署过程。 eg enterprise 支持 ci-cd 管道的重要组件,例如 github、jenkins、docker、k8s、bitbucket、redhat ansible tower、jira 等。请参阅:识别和诊断 jvm 中的 cpu 问题 (eginnovations.com) 和 java 代码级别能见度| eg 创新。
学习与总结
任何从事站点可靠性工程 (sre) 工作的人都会意识到这一发现的重要性。我们能够对其采取行动,而无需升起 1 级严重性标志。如果没有对这个有缺陷的 spring boot 包进行生产前故障排除,在生产中它可能会触发客户的自动缩放阈值,从而导致即使没有任何额外的用户负载也会启动新容器。
这个故事有三个主要要点。
- 首先,最佳实践是从一开始就启用可观察性解决方案,因为它可以提供可用于识别潜在问题的事件历史记录。如果没有这段历史,很容易就会忽视 0.1% 的垃圾收集百分比和 6% 的 cpu 消耗表明了一个严重的问题,并且代码可能会在发布到生产环境时带来灾难性的后果。将监控解决方案的范围扩展到其 uat 服务器有助于该团队识别潜在的根本原因并在问题影响实时服务和业务之前预防问题。
- 其次,测试过程中应该存在与性能相关的测试用例,并且这些测试用例应该由具有可观察性经验的人员进行审查。这将确保代码的功能及其性能得到测试。
- 第三,云原生性能跟踪技术有助于接收有关高利用率、可用性等的警报。为了实现可观察性,您还需要拥有正确的工具和专业知识。快乐编码!

发表评论