个人名片:
文章目录
hashset集合🎋
1.1 hashset集合的概述和特点🎐🎐🎐
首先先来研究一下帮助文档

hashset 基于 hashmap 来实现的,是一个不允许有重复元素的集合。
hashset 允许有 null 值。
hashset 是无序的,即不会记录插入的顺序。
hashset 不是线程安全的, 如果多个线程尝试同时修改 hashset,则最终结果是不确定的。 您必须在多线程访问时显式同步对 hashset 的并发访问。
hashset 实现了 set 接口。
此类实现 set 接口,由哈希表(实际上是一个 hashmap 实例)支持。它不保证 set 的迭代顺序;特别是它不保证该顺序恒久不变。此类允许使用 null 元素。
set s = collections.synchronizedset(new hashset(...));
总结:hashset集合特点
- 底层数据结构是哈希表
- 对集合的迭代顺序不做任何的保证,也就是说不保证存储和取出的元素顺序一致
- 没有带索引的方法,所以不能使用普通for循环来遍历(可以使用迭代器和增强for遍历)
- 由于是set 集合,所以不包含重复元素的集合
1.2 hashset 集合 demo✨✨✨
代码示例:存储字符串并遍历
package com.ithmm_06;
import java.util.hashset;
import java.util.iterator;
/\*\*
\* hashset集合特点
\*
\* 底层数据结构是哈希表
\* 对集合的迭代顺序不做任何的保证,也就是说不保证存储和取出的元素顺序一致
\* 没有带索引的方法,所以不能使用普通for循环来遍历(可以使用迭代器和增强for遍历)
\* 由于是set 集合,所以不包含重复元素的集合
\*/
public class hashsetdemo {
public static void main(string[] args) {
//创建集合对象
hashset<string> hs = new hashset<string>();
//添加元素
hs.add("hello");
hs.add("world");
hs.add("java");
// hs.add("hello");
//遍历
for(string s:hs){
system.out.println(s);//world java hello
}
//迭代器 iterator<e> iterator()
// 返回对此 set 中元素进行迭代的迭代器
iterator<string> it = hs.iterator();
while (it.hasnext()) {
string str = it.next();
system.out.println(str);
}
}
}
1.3 hashset集合保证元素唯一性底层逻辑(源码分析)🎊🎊🎊
hashset集合添加一个元素的过程:
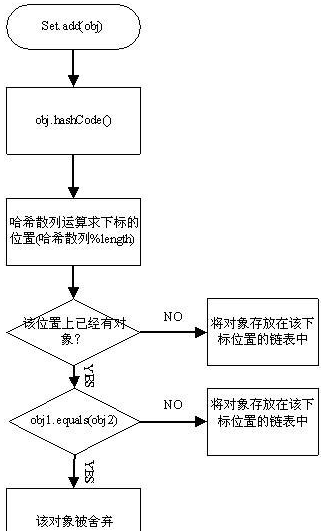
hashset底层源码:
//
// source code recreated from a .class file by intellij idea
// (powered by fernflower decompiler)
//
package java.util;
import java.io.ioexception;
import java.io.invalidobjectexception;
import java.io.objectinputstream;
import java.io.objectoutputstream;
import java.io.serializable;
import java.util.hashmap.keyspliterator;
public class hashset<e> extends abstractset<e> implements set<e>, cloneable, serializable {
static final long serialversionuid = -5024744406713321676l;
private transient hashmap<e, object> map;
private static final object present = new object();
public hashset() {
this.map = new hashmap();
}
public hashset(collection<? extends e> var1) {
this.map = new hashmap(math.max((int)((float)var1.size() / 0.75f) + 1, 16));
this.addall(var1);
}
public hashset(int var1, float var2) {
this.map = new hashmap(var1, var2);
}
public hashset(int var1) {
this.map = new hashmap(var1);
}
hashset(int var1, float var2, boolean var3) {
this.map = new linkedhashmap(var1, var2);
}
public iterator<e> iterator() {
return this.map.keyset().iterator();
}
public int size() {
return this.map.size();
}
public boolean isempty() {
return this.map.isempty();
}
public boolean contains(object var1) {
return this.map.containskey(var1);
}
public boolean add(e var1) {
return this.map.put(var1, present) == null;
}
public boolean remove(object var1) {
return this.map.remove(var1) == present;
}
public void clear() {

**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
mg-z9p3761b-1714657843635)]
[外链图片转存中...(img-ynbnyuu8-1714657843635)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**




发表评论