前言
前面我们对哈希表进行了介绍并用线性探测和哈希桶两种方式进行了实现!本期我们在上期的基础上对哈希表进行改造,并封装出unordered_map和unordered_set!
本期内容介绍
• 改造哈希表的存储
我们目前的哈希表只是可以存储pair的键值对,但是我们知道unordered_map和unordered_set,一个存在是k,一个存在的是<k,v>的键值对,难道我们得用两个哈希表分别来封装吗?显然不是的,前面map和set的封装也是同类的问题,他们底层用的是一颗红黑树,我们这里也是底层只用一个哈希表!那如何只用一个哈希表呢?答案是将哈希表和红黑树一样进行改造!本期我们就用拉链法实现的哈希表来封装unordered_map和unordered_set!
回忆一下map和set的封装:
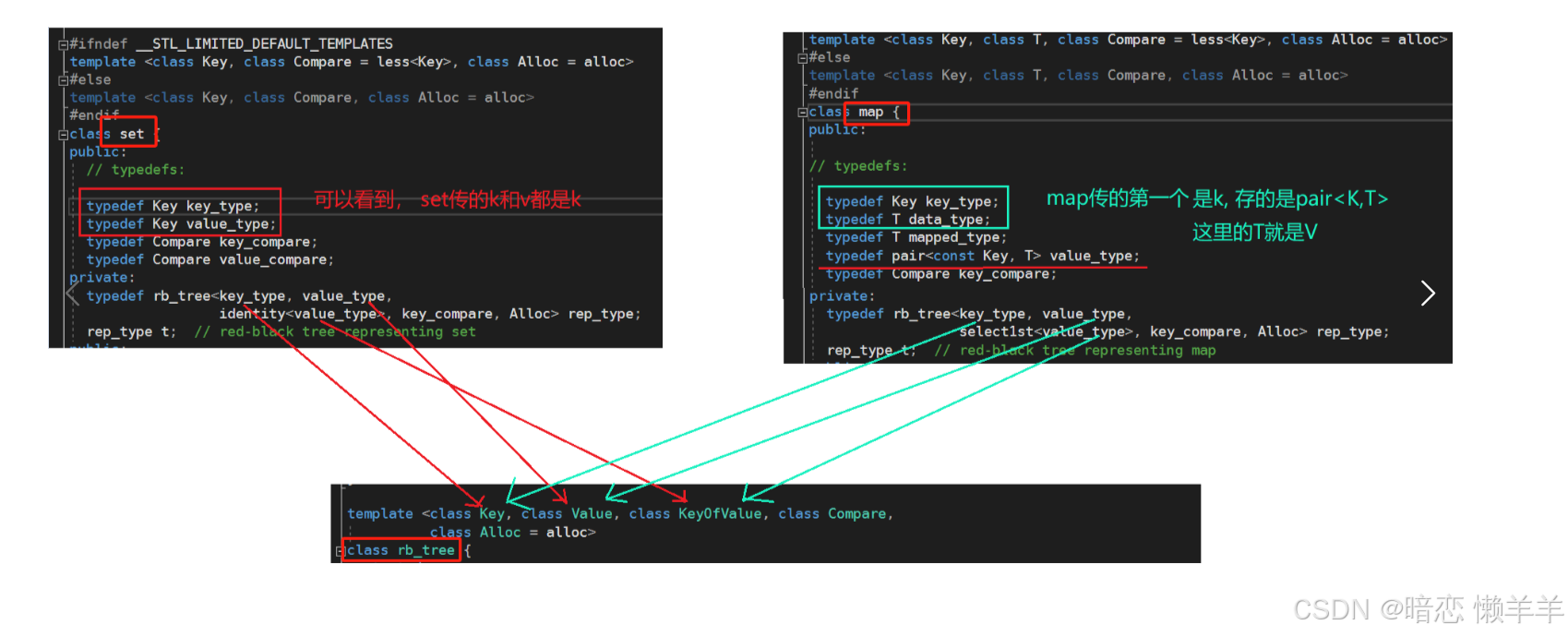
可以看到,set的k和v都是k,而map的k就是k,v是pair<k,v>;当时我们是将红黑树的存储做了修改将其原本的pair<k,v>键值对修改成了t,上层给k,t就是k,上层给pair<k,v>就是键值对!
这里的思路和map和set的思路一模一样,也是这样做的!
template<class t>
struct hashnode
{
t _data;//存储的元素的类型改为t,t是什么上层决定
hashnode<t>* _next;//后继指针
//构造函数初始化
hashnode(const t& data)
:_data(data)
,_next(nullptr)
{}
};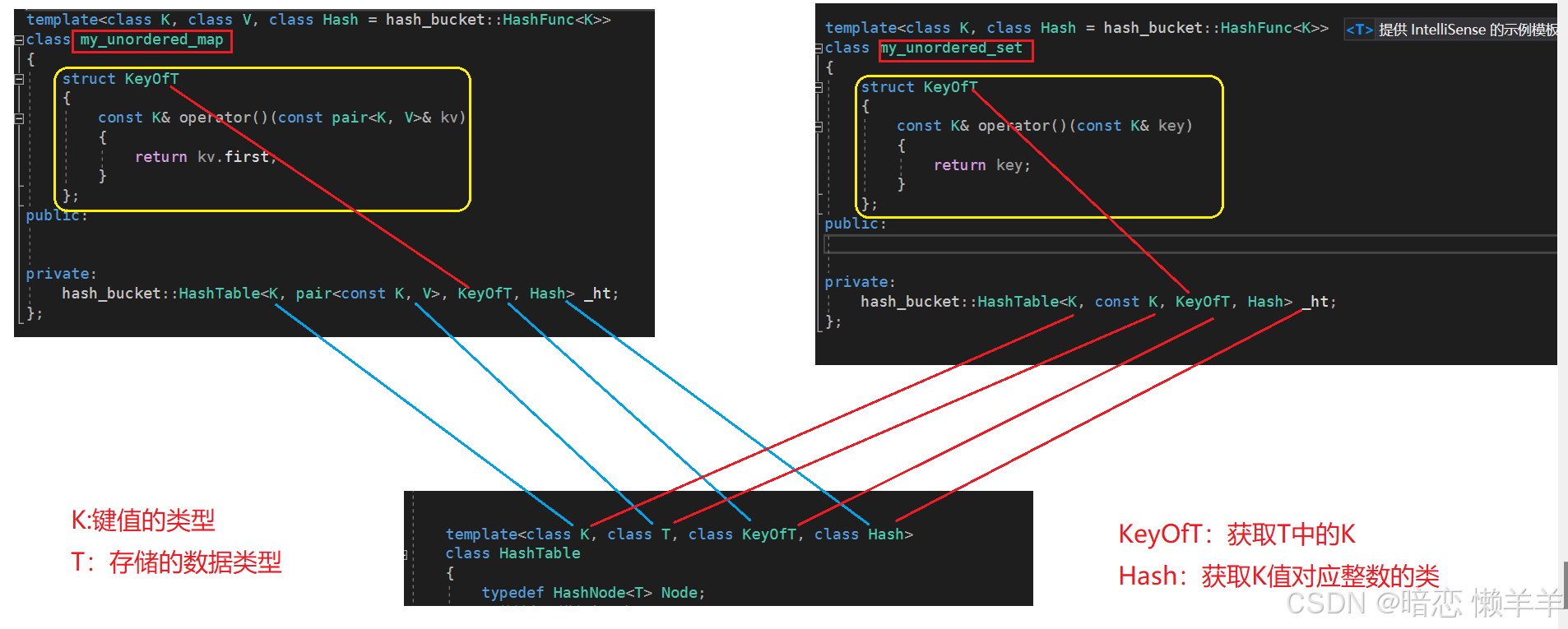
当把节点中存储的数据类型修改为t后,此时哈希表类的模板参数也需要修改:

相对应的其他接口也是需要改变的:
其他的就不在一一列举了,想获取k必须用keyoft的对象调用仿函数,原先的pair一律换成t!
ok,我们下来实现一下哈希表的迭代器:
• 实现哈希表的迭代器
哈希表的迭代器实现起来思路很简单!和前面链表以及红黑树的实现思路一样!
//迭代器类的实现
template<class k, class t, class ref, class ptr, class keyoft, class hash>
struct _htiterator
{
typedef _htiterator<k, t, ref, ptr, keyoft, hash> self;//迭代器类
typedef hashnode<t> node;//哈希表的节点
const hashtable<k, t, keyoft, hash>* _pht;//指向哈希表的指针,这是只对哈希表查找
node* _node;//迭代器节点指针
_htiterator(node* node, const hashtable<k, t, keyoft, hash>* pht)
:_node(node)
,_pht(pht)
{}
ref operator*()
{
return _node->_data;//返回该迭代器的指针节点指向的数据
}
ptr operator->()
{
return &_node->_data;//返回该迭代器的指针节点指向的数据的地址
}
bool operator!=(const self& it)
{
return _node != it._node;//直接比较两个迭代器节点的地址不等即可
}
bool operator==(const self& it)
{
return _node == it._node;//直接比较两个迭代器节点的地址相等即可
}
};下面我们来单独讨论一下++:
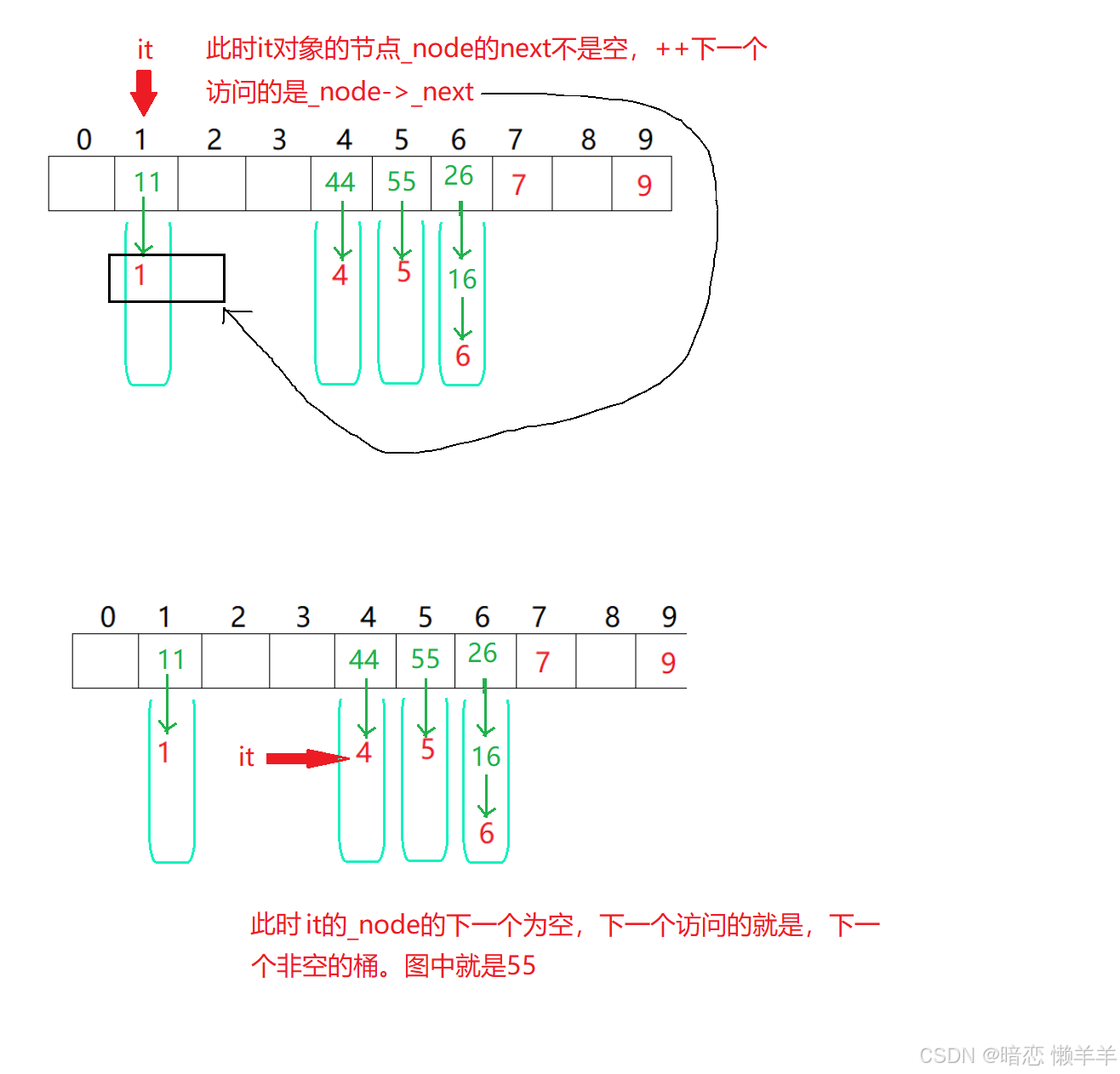
self& operator++()
{
//当前节点的后一个不为空
if (_node->_next)
{
_node = _node->_next;//++后迭代器的节点指针,指向当前节点的下一个
}
else
{
hash hs;//获取key值对应整数的对象
keyoft kot;//获取key值的对象
size_t hashi = hs(kot(_node->_data)) % _pht->_tables.size();//计算哈希地址
++hashi;//++一下hashi,看下一个桶
while (hashi < _pht->_tables.size())
{
node* cur = _pht->_tables[hashi];
if (cur != nullptr)//找到一个不为空的桶
break;//跳出循环
++hashi;
}
//hashi已经到哈希表的结尾了
if (hashi == _pht->_tables.size())
_node = nullptr;//让_node节点指向空
else
_node = _pht->_tables[hashi];//让_node节点指向当前不为空的桶
}
return *this;//返回该迭代器对象
}我们现在有很尴尬的问题就是:
• 我们把迭代器类放到那个位置呢?把由于编译器是向上查找,把迭代器的类放到哈希表类的上面,此时迭代器类的上面没有哈希表的类,而用到了哈希表对象的指针,就会出报错!如果将迭代器的类放到哈希表类的下面,此时哈希表中访问迭代器又找不到迭代器了!!!如何解决呢?
• 解决方案:可以将迭代器类依旧放在哈希表类的上面,然后在迭代器类的上面进行哈希表类的声明即可!(内部类也可以)

• 迭代器类在哈希表的上面,而在迭代器其中要用哈希表对象的指针,即访问_tables,而_tables是哈希表的私有成员,也就是即使有声明迭代器还是访问不到哈希表!如何解决?
• 解决方案:上述的不变,可以在哈希表类中进行迭代器类的声明!

迭代器源码
//哈希表的前置声明
template<class k, class t, class keyoft, class hash>
class hashtable;
//迭代器类的实现
template<class k, class t, class ref, class ptr, class keyoft, class hash>
struct _htiterator
{
typedef _htiterator<k, t, ref, ptr, keyoft, hash> self;//迭代器类
typedef hashnode<t> node;//哈希表的节点
const hashtable<k, t, keyoft, hash>* _pht;//指向哈希表的指针,这是只对哈希表查找
node* _node;//迭代器节点指针
_htiterator(node* node, const hashtable<k, t, keyoft, hash>* pht)
:_node(node)
,_pht(pht)
{}
ref operator*()
{
return _node->_data;//返回该迭代器的指针节点指向的数据
}
ptr operator->()
{
return &_node->_data;//返回该迭代器的指针节点指向的数据的地址
}
bool operator!=(const self& it)
{
return _node != it._node;//直接比较两个迭代器节点的地址不等即可
}
bool operator==(const self& it)
{
return _node == it._node;//直接比较两个迭代器节点的地址相等即可
}
self& operator++()
{
//当前节点的后一个不为空
if (_node->_next)
{
_node = _node->_next;//++后迭代器的节点指针,指向当前节点的下一个
}
else
{
hash hs;//获取key值对应整数的对象
keyoft kot;//获取key值的对象
size_t hashi = hs(kot(_node->_data)) % _pht->_tables.size();//计算哈希地址
++hashi;//++一下hashi,看下一个桶
while (hashi < _pht->_tables.size())
{
node* cur = _pht->_tables[hashi];
if (cur != nullptr)//找到一个不为空的桶
break;//跳出循环
++hashi;
}
//hashi已经到哈希表的结尾了
if (hashi == _pht->_tables.size())
_node = nullptr;//让_node节点指向空
else
_node = _pht->_tables[hashi];//让_node节点指向当前不为空的桶
}
return *this;//返回该迭代器对象
}
};• 对哈希表类进行完善
拷贝构造
//拷贝构造
hashtable(const hashtable& ht)
:_tables(ht._tables.size())//设置大小为被拷贝一样的大小
, _size(0)
{
//遍历ht,将ht表中的数据插入到当前的表即可
for (auto cur : ht._tables)
{
while (cur)
{
insert(cur->_data);
cur = cur->_next;
}
}
}赋值拷贝
//赋值拷贝 -> 现代写法
hashtable& operator=(hashtable ht)
{
if (this != &ht)//自己不要给自己赋值
{
_tables.swap(ht._tables);
_size = ht._size;
}
return *this;
}
//赋值拷贝 -> 传统写法
hashtable& operator=(const hashtable& ht)
{
if (this != &ht) // 自己不要给自己赋值
{
clear(); // 清空当前对象
//遍历ht的表,如果不为空,将ht表中的 数据插入到当前的表中
for (auto cur : ht._tables)
{
while (cur)
{
insert(cur->_data);
cur = cur->_next;
}
}
}
return *this;
}迭代器实现
先在哈希表中将迭代器类进行重命名
//迭代器
typedef _htiterator<k, t, t&, t*, keyoft, hash> iterator;
typedef _htiterator<k, t, const t&, const t*, keyoft, hash> const_iterator;begin
iterator begin()
{
//找第一个不为空的哈希桶
for (auto& cur : _tables)
{
if (cur)
{
return iterator(cur, this);
}
}
return end();//没找到直接返回end
}end
iterator end()
{
return iterator(nullptr, this);//最后一个和哈希桶的下一个位置
}const_begin
const_iterator begin() const
{
//找第一个不为空的哈希桶
for (auto& cur : _tables)
{
if (cur)
{
return const_iterator(cur, this);
}
}
return end();//没找到直接返回end
}const_end
const_iterator end() const
{
return const_iterator(nullptr, this);//最后一个和哈希桶的下一个位置
}find
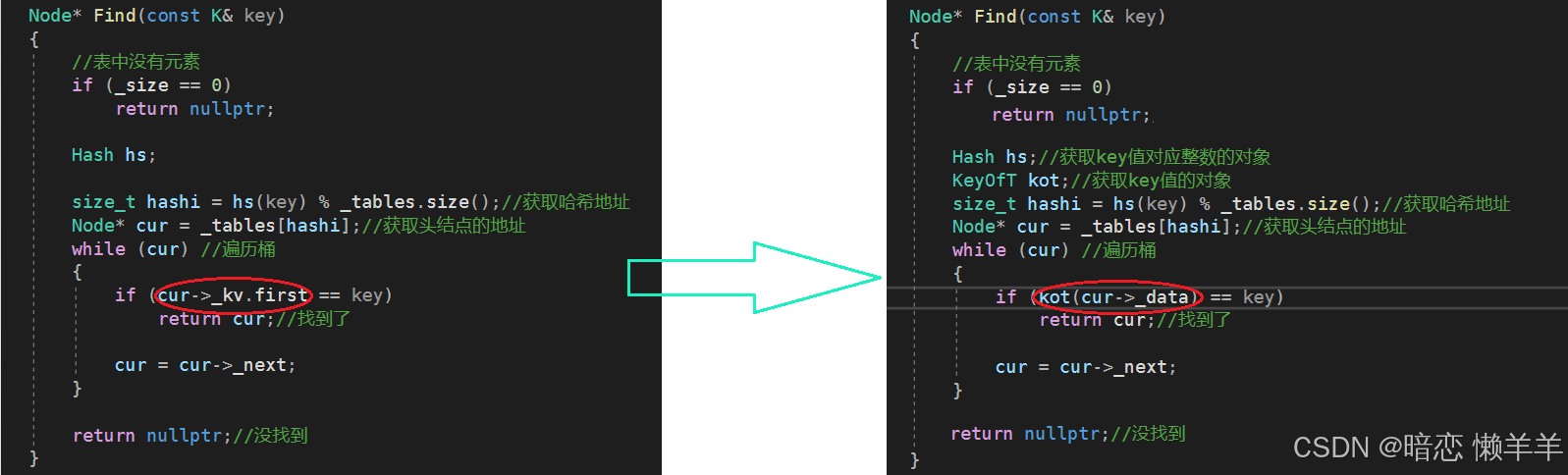
iterator find(const k& key)
{
//表中没有元素
if (_size == 0)
return end();
hash hs;//获取key值对应整数的对象
keyoft kot;//获取key值的对象
size_t hashi = hs(key) % _tables.size();//获取哈希地址
node* cur = _tables[hashi];//获取头结点的地址
while (cur) //遍历桶
{
if (kot(cur->_data) == key)
return iterator(cur, this);//找到了
cur = cur->_next;
}
return end();//没找到
}insert
pair<iterator, bool> insert(const t& data)
{
hash hs;//获取key值对应整数的对象
keyoft kot;//获取key值的对象
//要插入的元素在哈希表中已经存在
//if (find(kot(data)))
//return false;
iterator it = find(kot(data));//要插入的元素在哈希表中已经存在
if (it != end())
return make_pair(it, false);
//扩容 - 》现代写法(效率不好,相当于将旧表中的数据节点拷贝到新表,然后再将旧表释放)
//if (_size == _tables.size())
//{
// size_t newsize = _tables.size() * 2;
// hashtable<k, t, keyoft, hash> newtable;
// newtable._tables.resize(newsize);
// //遍历旧表
// for (auto& cur : _tables)
// {
// while (cur)
// {
// newtable.insert(cur->_data);
// cur = cur->_next;
// }
// }
// _tables.swap(newtable._tables);
//}
//扩容 -> 传统写法(直接将旧表中的节点拿下来,映射到新表)
if (_size == _tables.size())
{
size_t newsize = _tables.size() * 2;
//创建一个新的哈希表,大小是旧表的2倍
vector<node*> newtable(newsize, nullptr);
//遍历旧表
for (auto& cur : _tables)
{
while (cur)
{
node* next = cur->_next;//保存下一个节点
size_t hashi = hs(kot(cur->_data)) % newtable.size();//算出当前节点在新表中的哈希地址
//头插映射到新表
cur->_next = newtable[hashi];
newtable[hashi] = cur;
cur = next;//当前节点的指针指向下一个节点
}
cur = nullptr;//将一个桶映射完了,将该位置置空
}
_tables.swap(newtable);//交换新表和旧表
}
//插入
size_t hashi = hs(kot(data)) % _tables.size();
node* newnode = new node(data);
//头插
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
_size++;//有效元素+1
return make_pair(iterator(newnode, this), true);
}删除没有要改的,就是在遍历桶对比key时应该使用keyoft的对象获取t的key!size, clear以及empty都不变!
count
size_t count(const k& key)
{
iterator ret = find(key);
return ret == end() ? 0 : 1;//如果没有查找到,直接返回0,找到了返回1
}swap
void swap(hashtable& ht)
{
_tables.swap(ht._tables);//调用vextor的swap
std::swap(_size, ht._size);//调用std里面的将两个整数交换即可
}ok,至此,哈希表类的改造以及迭代器的实现均已完毕!下面我们就可以封装unordered_map和unordered_set了!
• 基于哈希表封装unordered_map和unordered_set
直到底层的哈希表和迭代器没问题,unordered_map和unordered_set的封装就是套一层壳!唯一有挑战的就是unordered_map的[ ];下面也只是介绍一下[],其他接口直接调用哈希表的即可!
v& operator[](const k& key)
{
pair<iterator, bool> ret = _ht.insert({ key, v() });
return ret.first->second;
}unordered_map源码
#pragma once
template<class k, class v, class hash = hash_bucket::hashfunc<k>>
class my_unordered_map
{
struct keyoft
{
const k& operator()(const pair<k, v>& kv)
{
return kv.first;
}
};
public:
typedef typename hash_bucket::_htiterator<k, pair<const k,v>, pair<const k, v>&, pair<const k, v>*, keyoft, hash> iterator;
typedef typename hash_bucket::_htiterator<k, pair<const k,v>, const pair<const k, v>&, const pair<const k, v>*, keyoft, hash> const_iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
const_iterator begin() const
{
return _ht.begin();
}
const_iterator end() const
{
return _ht.end();
}
pair<iterator, bool> insert(const pair<k, v>& kv)
{
return _ht.insert(kv);
}
v& operator[](const k& key)
{
pair<iterator, bool> ret = _ht.insert({ key, v() });
return ret.first->second;
}
bool erase(const k& key)
{
return _ht.erase(key);
}
iterator find(const k& key)
{
return _ht.find(key);
}
size_t size() const
{
return _ht.size();
}
bool empty() const
{
return _ht.empty();
}
void clear()
{
_ht.clear();
}
size_t count(const k& key)
{
return _ht.count(key);
}
void swap(my_unordered_map& ump)
{
_ht.swap(ump._ht);
}
private:
hash_bucket::hashtable<k, pair<const k, v>, keyoft, hash> _ht;//k不允许修改
};unordered_set源码
#pragma once
template<class k, class hash = hash_bucket::hashfunc<k>>
class my_unordered_set
{
struct keyoft
{
const k& operator()(const k& key)
{
return key;
}
};
public:
//typedef typename hash_bucket::_htiterator<k, k, k&, k*, keyoft, hash> iterator;
//这里不管是否是const迭代器,我们底层都给成const的,防止修改k
typedef typename hash_bucket::_htiterator<k, const k, const k&, const k*, keyoft, hash> const_iterator;
typedef typename hash_bucket::_htiterator<k, const k, const k&, const k*, keyoft, hash> iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
const_iterator begin() const
{
return _ht.begin();
}
const_iterator end() const
{
return _ht.end();
}
pair<iterator, bool> insert(const k& kv)
{
return _ht.insert(kv);
}
bool erase(const k& key)
{
return _ht.erase(key);
}
iterator find(const k& key)
{
return _ht.find(key);
}
size_t size() const
{
return _ht.size();
}
bool empty() const
{
return _ht.empty();
}
void clear()
{
_ht.clear();
}
size_t count(const k& key)
{
return _ht.count(key);
}
void swap(my_unordered_set& ust)
{
_ht.swap(ust._ht);
}
private:
hash_bucket::hashtable<k, const k, keyoft, hash> _ht;
};哈希表的源码
#pragma once
#include <vector>
namespace hash_bucket
{
template<class k>
struct hashfunc
{
//解决浮点数和负数
size_t operator()(const k& key)
{
return (size_t)key;
}
};
template<>//模板的特化
struct hashfunc<string>
{
//字符串哈希算法
size_t operator()(const string& key)
{
size_t sum = 0;
for (auto& c : key)
{
sum *= 131;//乘以131可以更好的降低冲突
sum += c;
}
return sum;
}
};
template<class t>
struct hashnode
{
t _data;//存储的元素的类型改为t,t是什么上层决定
hashnode<t>* _next;//后继指针
//构造函数初始化
hashnode(const t& data)
:_data(data)
,_next(nullptr)
{}
};
//哈希表的前置声明
template<class k, class t, class keyoft, class hash>
class hashtable;
//迭代器类的实现
template<class k, class t, class ref, class ptr, class keyoft, class hash>
struct _htiterator
{
typedef _htiterator<k, t, ref, ptr, keyoft, hash> self;//迭代器类
typedef hashnode<t> node;//哈希表的节点
const hashtable<k, t, keyoft, hash>* _pht;//指向哈希表的指针,这是只对哈希表查找
node* _node;//迭代器节点指针
_htiterator(node* node, const hashtable<k, t, keyoft, hash>* pht)
:_node(node)
,_pht(pht)
{}
ref operator*()
{
return _node->_data;//返回该迭代器的指针节点指向的数据
}
ptr operator->()
{
return &_node->_data;//返回该迭代器的指针节点指向的数据的地址
}
bool operator!=(const self& it)
{
return _node != it._node;//直接比较两个迭代器节点的地址不等即可
}
bool operator==(const self& it)
{
return _node == it._node;//直接比较两个迭代器节点的地址相等即可
}
self& operator++()
{
//当前节点的后一个不为空
if (_node->_next)
{
_node = _node->_next;//++后迭代器的节点指针,指向当前节点的下一个
}
else
{
hash hs;//获取key值对应整数的对象
keyoft kot;//获取key值的对象
size_t hashi = hs(kot(_node->_data)) % _pht->_tables.size();//计算哈希地址
++hashi;//++一下hashi,看下一个桶
while (hashi < _pht->_tables.size())
{
node* cur = _pht->_tables[hashi];
if (cur != nullptr)//找到一个不为空的桶
break;//跳出循环
++hashi;
}
//hashi已经到哈希表的结尾了
if (hashi == _pht->_tables.size())
_node = nullptr;//让_node节点指向空
else
_node = _pht->_tables[hashi];//让_node节点指向当前不为空的桶
}
return *this;//返回该迭代器对象
}
};
template<class k, class t, class keyoft, class hash>
class hashtable
{
typedef hashnode<t> node;
//将迭代器进行友元声明
template<class k, class t, class ref, class ptr, class keyoft, class hash>
friend struct _htiterator;
public:
//迭代器
typedef _htiterator<k, t, t&, t*, keyoft, hash> iterator;
typedef _htiterator<k, t, const t&, const t*, keyoft, hash> const_iterator;
iterator begin()
{
//找第一个不为空的哈希桶
for (auto& cur : _tables)
{
if (cur)
{
return iterator(cur, this);
}
}
return end();//没找到直接返回end
}
iterator end()
{
return iterator(nullptr, this);//最后一个和哈希桶的下一个位置
}
const_iterator begin() const
{
//找第一个不为空的哈希桶
for (auto& cur : _tables)
{
if (cur)
{
return const_iterator(cur, this);
}
}
return end();//没找到直接返回end
}
const_iterator end() const
{
return const_iterator(nullptr, this);//最后一个和哈希桶的下一个位置
}
//开放地址法,没有写构造,扩容有两种情况,这里写一个构造,扩容就只是负载因子引起的
hashtable()
:_tables(4, nullptr)//一开始的大小给为4
, _size(0)
{}
//拷贝构造
hashtable(const hashtable& ht)
:_tables(ht._tables.size())//设置大小为被拷贝一样的大小
, _size(0)
{
//遍历ht,将ht表中的数据插入到当前的表即可
for (auto cur : ht._tables)
{
while (cur)
{
insert(cur->_data);
cur = cur->_next;
}
}
}
//赋值拷贝 -> 现代写法
hashtable& operator=(hashtable ht)
{
if (this != &ht)//自己不要给自己赋值
{
_tables.swap(ht._tables);
_size = ht._size;
}
return *this;
}
//赋值拷贝 -> 传统写法
//hashtable& operator=(const hashtable& ht)
//{
// if (this != &ht) // 自己不要给自己赋值
// {
// clear(); // 清空当前对象
//
// //遍历ht的表,如果不为空,将ht表中的 数据插入到当前的表中
// for (auto cur : ht._tables)
// {
// while (cur)
// {
// insert(cur->_data);
// cur = cur->_next;
// }
// }
// }
// return *this;
//}
//这里必须得写析构函数,否则会出现内存泄漏
~hashtable()
{
clear();
}
iterator find(const k& key)
{
//表中没有元素
if (_size == 0)
return end();
hash hs;//获取key值对应整数的对象
keyoft kot;//获取key值的对象
size_t hashi = hs(key) % _tables.size();//获取哈希地址
node* cur = _tables[hashi];//获取头结点的地址
while (cur) //遍历桶
{
if (kot(cur->_data) == key)
return iterator(cur, this);//找到了
cur = cur->_next;
}
return end();//没找到
}
pair<iterator, bool> insert(const t& data)
{
hash hs;//获取key值对应整数的对象
keyoft kot;//获取key值的对象
//要插入的元素在哈希表中已经存在
//if (find(kot(data)))
//return false;
iterator it = find(kot(data));//要插入的元素在哈希表中已经存在
if (it != end())
return make_pair(it, false);
//扩容 - 》现代写法(效率不好,相当于将旧表中的数据节点拷贝到新表,然后再将旧表释放)
//if (_size == _tables.size())
//{
// size_t newsize = _tables.size() * 2;
// hashtable<k, t, keyoft, hash> newtable;
// newtable._tables.resize(newsize);
// //遍历旧表
// for (auto& cur : _tables)
// {
// while (cur)
// {
// newtable.insert(cur->_data);
// cur = cur->_next;
// }
// }
// _tables.swap(newtable._tables);
//}
//扩容 -> 传统写法(直接将旧表中的节点拿下来,映射到新表)
if (_size == _tables.size())
{
size_t newsize = _tables.size() * 2;
//创建一个新的哈希表,大小是旧表的2倍
vector<node*> newtable(newsize, nullptr);
//遍历旧表
for (auto& cur : _tables)
{
while (cur)
{
node* next = cur->_next;//保存下一个节点
size_t hashi = hs(kot(cur->_data)) % newtable.size();//算出当前节点在新表中的哈希地址
//头插映射到新表
cur->_next = newtable[hashi];
newtable[hashi] = cur;
cur = next;//当前节点的指针指向下一个节点
}
cur = nullptr;//将一个桶映射完了,将该位置置空
}
_tables.swap(newtable);//交换新表和旧表
}
//插入
size_t hashi = hs(kot(data)) % _tables.size();
node* newnode = new node(data);
//头插
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
_size++;//有效元素+1
return make_pair(iterator(newnode, this), true);
}
bool erase(const k& key)
{
hash hs;//获取key值对应整数的对象
keyoft kot;//获取key值的对象
size_t hashi = hs(key) % _tables.size();//计算哈希地址
node* cur = _tables[hashi];
node* prev = nullptr;//前驱
while (cur)
{
node* next = cur->_next;
//找到关键码和key一样的桶了
if (kot(cur->_data) == key)
{
if (prev == nullptr)//头删
_tables[hashi] = next;
else
prev->_next = next;//正常删除
delete cur;
cur = nullptr;
--_size;
return true;
}
else//没找到继续找
{
prev = cur;
cur = next;
}
}
return false;//没找到删除的
}
size_t size() const
{
return _size;//返回成员变量_size即可
}
bool empty() const
{
return _size == 0;//返回_size是否==0即可
}
void clear()
{
//遍历整个哈希表
for (size_t i = 0; i < _tables.size(); i++)
{
if (_tables[i])//当前桶不为空
{
node* cur = _tables[i];//当前节点的下一个位置
while (cur)
{
node* next = cur->_next;//保存下一个节点的指针
delete cur;
cur = next;
}
_tables[i] = nullptr;//将每个桶的链表清理完了后置为空
}
}
_size = 0;//将有效元素的个数置0
}
size_t count(const k& key)
{
iterator ret = find(key);
return ret == end() ? 0 : 1;//如果没有查找到,直接返回0,找到了返回1
}
void swap(hashtable& ht)
{
_tables.swap(ht._tables);//调用vextor的swap
std::swap(_size, ht._size);//调用std里面的将两个整数交换即可
}
private:
vector<node*> _tables;//哈希表
size_t _size;//有效元素的个数
};
}• unordered_map和unordered_set的测试
测试unordered_map
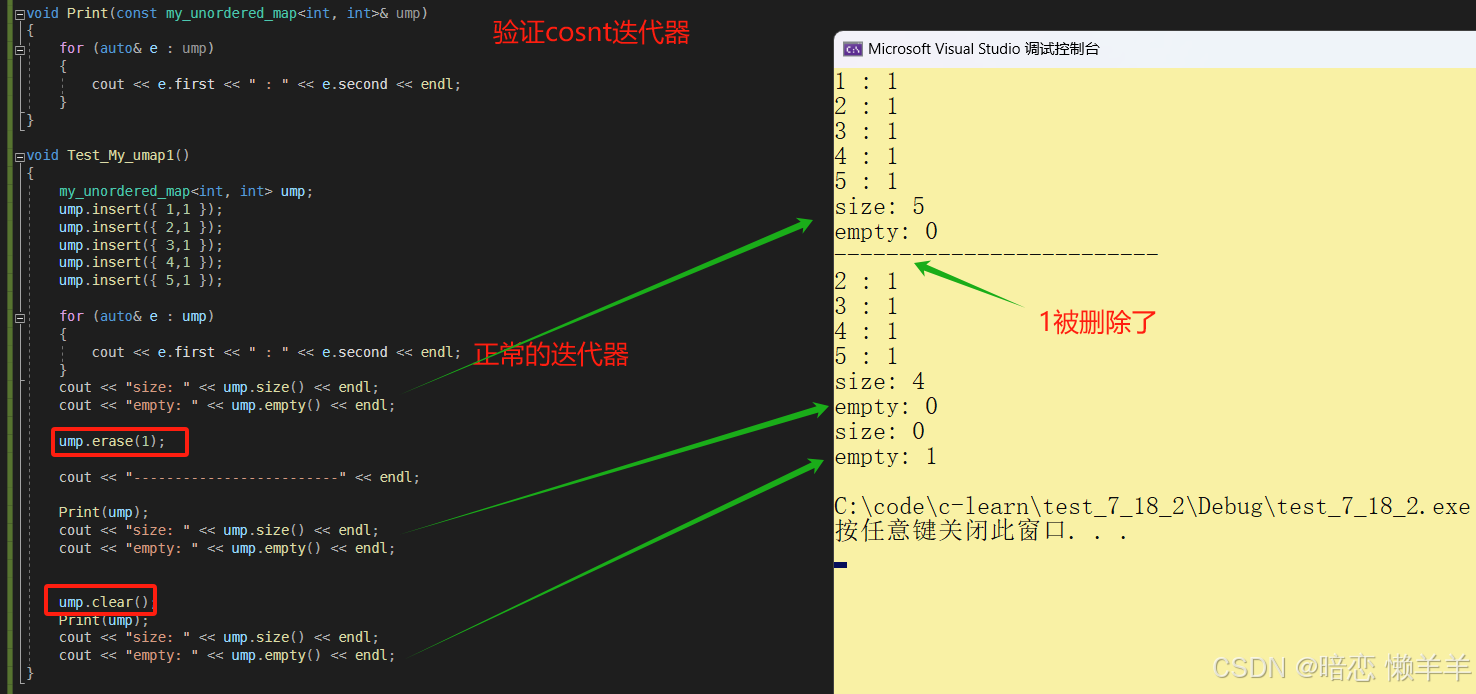
void test_my_umap1()
{
my_unordered_map<int, int> ump;
ump.insert({ 1,1 });
ump.insert({ 2,1 });
ump.insert({ 3,1 });
ump.insert({ 4,1 });
ump.insert({ 5,1 });
for (auto& e : ump)
{
cout << e.first << " : " << e.second << endl;
}
cout << "size: " << ump.size() << endl;
cout << "empty: " << ump.empty() << endl;
ump.erase(1);
cout << "-------------------------" << endl;
print(ump);
cout << "size: " << ump.size() << endl;
cout << "empty: " << ump.empty() << endl;
ump.clear();
print(ump);
cout << "size: " << ump.size() << endl;
cout << "empty: " << ump.empty() << endl;
}
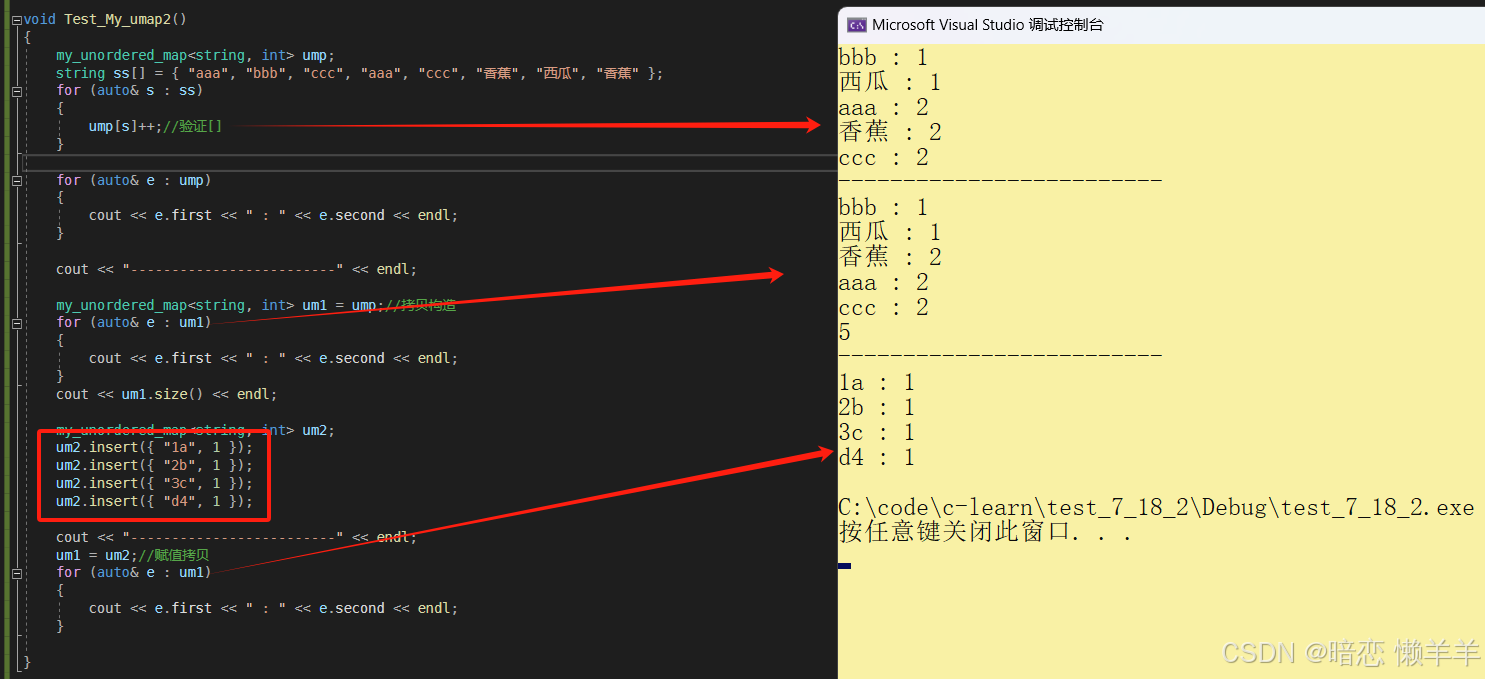
void test_my_umap2()
{
my_unordered_map<string, int> ump;
string ss[] = { "aaa", "bbb", "ccc", "aaa", "ccc", "香蕉", "西瓜", "香蕉" };
for (auto& s : ss)
{
ump[s]++;//验证[]
}
for (auto& e : ump)
{
cout << e.first << " : " << e.second << endl;
}
cout << "-------------------------" << endl;
my_unordered_map<string, int> um1 = ump;//拷贝构造
for (auto& e : um1)
{
cout << e.first << " : " << e.second << endl;
}
cout << um1.size() << endl;
my_unordered_map<string, int> um2;
um2.insert({ "1a", 1 });
um2.insert({ "2b", 1 });
um2.insert({ "3c", 1 });
um2.insert({ "d4", 1 });
cout << "-------------------------" << endl;
um1 = um2;//赋值拷贝
for (auto& e : um1)
{
cout << e.first << " : " << e.second << endl;
}
}
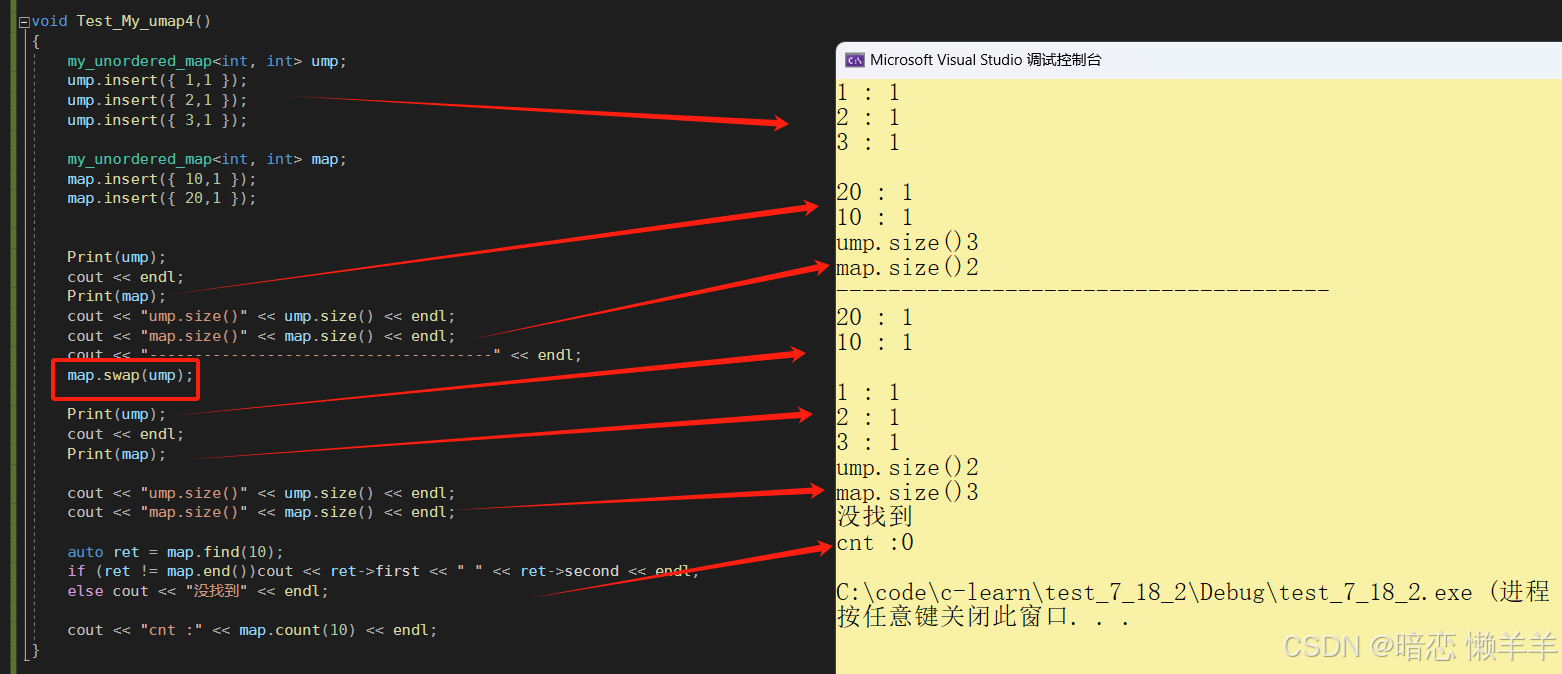
void test_my_umap4()
{
my_unordered_map<int, int> ump;
ump.insert({ 1,1 });
ump.insert({ 2,1 });
ump.insert({ 3,1 });
my_unordered_map<int, int> map;
map.insert({ 10,1 });
map.insert({ 20,1 });
print(ump);
cout << endl;
print(map);
cout << "ump.size()" << ump.size() << endl;
cout << "map.size()" << map.size() << endl;
cout << "--------------------------------------" << endl;
map.swap(ump);
print(ump);
cout << endl;
print(map);
cout << "ump.size()" << ump.size() << endl;
cout << "map.size()" << map.size() << endl;
auto ret = map.find(10);
if (ret != map.end())cout << ret->first << " " << ret->second << endl;
else cout << "没找到" << endl;
cout << "cnt :" << map.count(10) << endl;
}
unordered_set的测试
template<class k>
void print(const my_unordered_set<k>& ust)
{
for (auto& e : ust)
{
cout << e << endl;
}
}
void test_my_ust1()
{
my_unordered_set<int> ust;
ust.insert(1);
ust.insert(2);
ust.insert(3);
ust.insert(4);
ust.insert(11);
for (auto& e : ust)
{
cout << e << endl;
}
cout << endl;
ust.erase(1);
print(ust);
cout << ust.count(1) << endl;
auto ret = ust.find(20);
if (ret != ust.end()) cout << *ret << endl;
else cout << "没找到" << endl;
cout << "-------------------------------" << endl;
ust.clear();
print(ust);
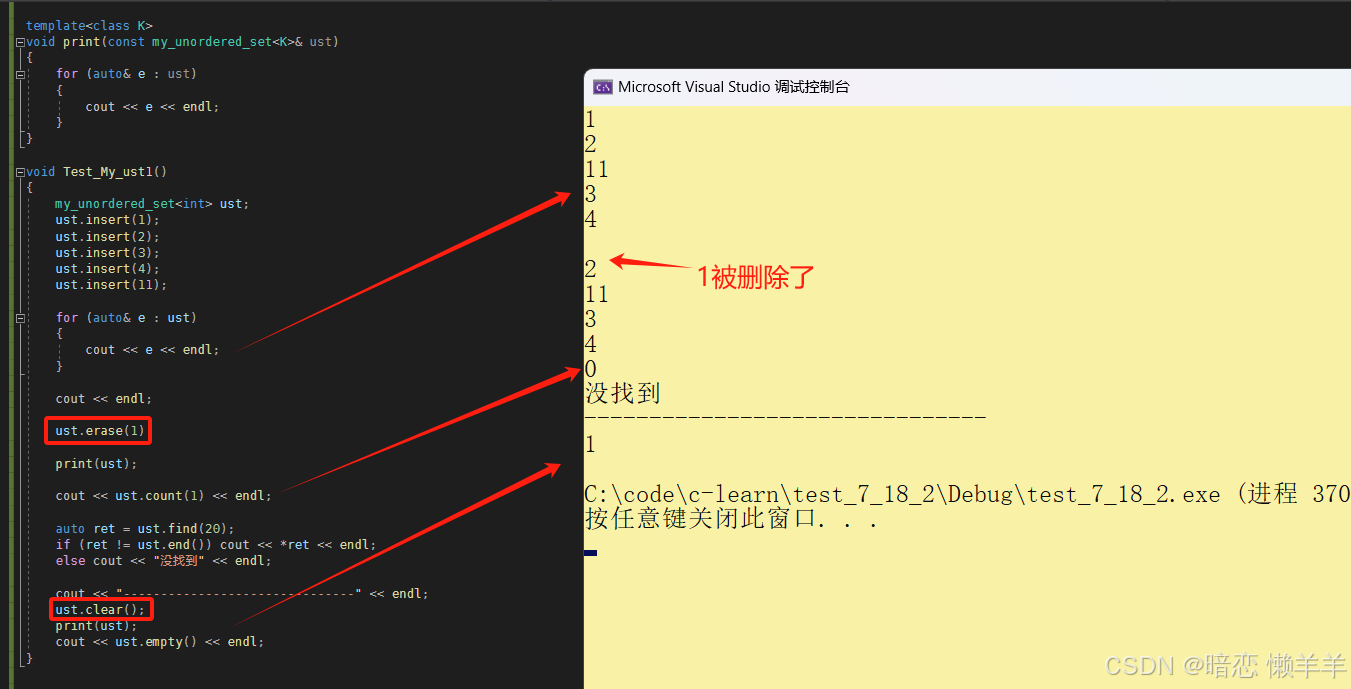
void test_my_ust2()
{
my_unordered_set<int> ust;
ust.insert(1);
ust.insert(2);
ust.insert(3);
ust.insert(4);
ust.insert(11);
my_unordered_set<int> st;
st.insert(100);
st.insert(200);
st.insert(300);
print(ust);
print(st);
cout << "-------------------------------" << endl;
ust.swap(st);
print(ust);
print(st);
}
ok,测试就到这里,没有问题(其实我测了好多情况~)!
ok,本期分享就到这里,好兄弟,我们下期再见!


发表评论