在flink-connector-jdbc中增加对国产数据库达梦(v8)的支持
本文将展示如何在flink-connector-jdbc中增加对国产数据库达梦(v8)的支持。演示基于java语言,使用maven。
1. 关于flink-connector-jdbc
flink-connector-jdbc是apache flink框架提供的一个用于与关系型数据库进行连接和交互的连接器。它提供了使用flink进行批处理和流处理的功能,可以方便地将关系型数据库中的数据引入flink进行分析和处理,或者将flink计算结果写入关系型数据库。
flink-connector-jdbc可以实现以下核心功能:
- 数据源连接:可以通过flink-connector-jdbc连接到各种支持jdbc标准的关系型数据库,如mysql、postgresql、oracle等。
- 数据写入:可以将flink的计算结果写入关系型数据库中,实现数据的持久化。
- 数据读取:可以从关系型数据库中读取数据,并将其作为flink计算的输入数据。
- 数据格式转换:可以将关系型数据库中的数据转换为适合flink计算的数据格式。
- 并行处理:可以根据数据源的并行度将数据进行分区和并行处理,以加速数据处理的速度。
flink-connector-jdbc为flink提供了与关系型数据库集成的能力,可以方便地进行数据的导入、导出和处理,为开发人员提供了更强大和灵活的数据处理能力。
2. flink-connector-jdbc包含对哪些关系型数据库的支持
截止目前,flink最新版到flink-1.17.1,但是不管是flink-1.17.0还是flink-1.17.1,都没有找到关于flink-connector-jdbc的实现,从flink-1.16.2中能相关实现找到;
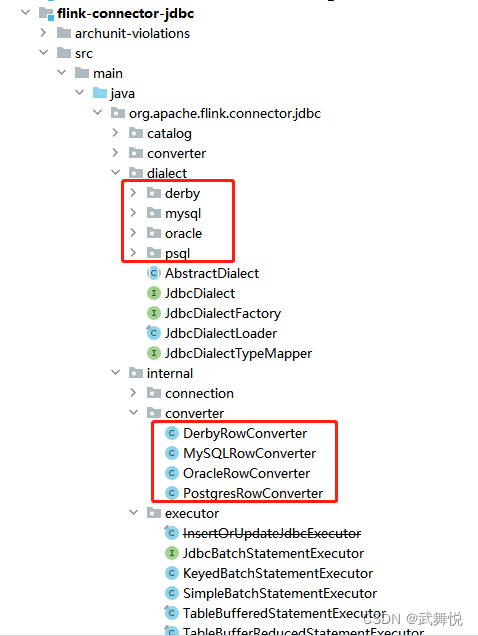
可以看到,flink-connector-jdbc目前只支持4种关系型数据库:derby、mysql、oracle、psql,
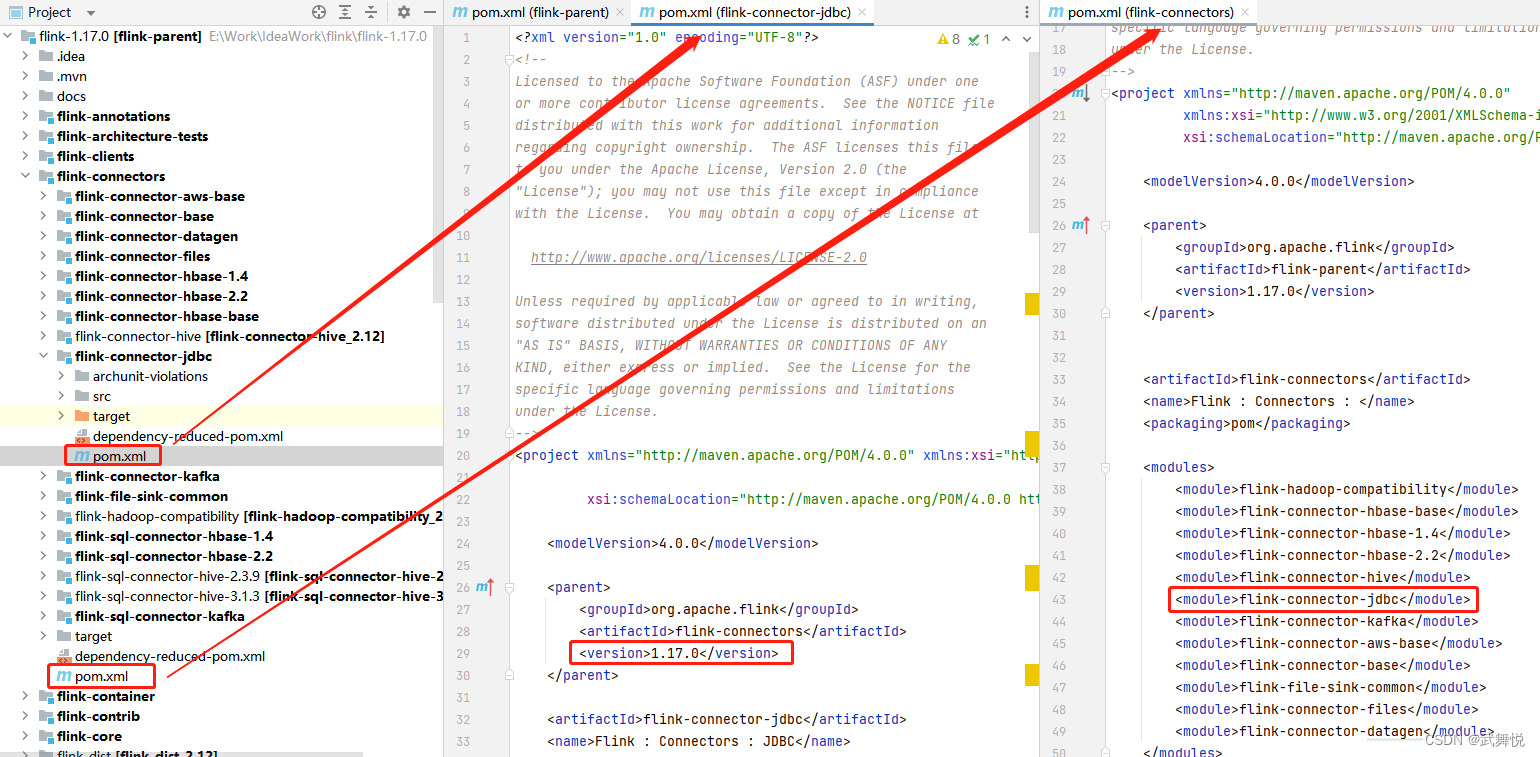
3. 在flink-1.17中添加对flink-connector-jdbc支持
这个不难,直接把flink-1.16.2中flink-connector-jdbc的代码实现拷贝到flink-1.17.0中相应位置即可,但注意修改flink-connectors和flink-connector-jdbc下的pom.xml文件
4. 在flink-connector-jdbc中添加对国产数据库达梦(v8)的支持
4.1 新增damengrowconverter
在flink-connector-jdbc模块的org.apache.flink.connector.jdbc.internal.converter包下新增damengrowconverter.java
package org.apache.flink.connector.jdbc.internal.converter;
import org.apache.flink.connector.jdbc.converter.abstractjdbcrowconverter;
import org.apache.flink.table.data.decimaldata;
import org.apache.flink.table.data.stringdata;
import org.apache.flink.table.data.timestampdata;
import org.apache.flink.table.types.logical.decimaltype;
import org.apache.flink.table.types.logical.logicaltype;
import org.apache.flink.table.types.logical.rowtype;
import dm.jdbc.driver.dmdbblob;
import dm.jdbc.driver.dmdbclob;
import java.io.ioexception;
import java.io.inputstream;
import java.math.bigdecimal;
import java.math.biginteger;
import java.sql.date;
import java.sql.time;
import java.sql.timestamp;
/**
* runtime converter that responsible to convert between jdbc object and flink internal object for
* dameng.
*/
public class damengrowconverter extends abstractjdbcrowconverter {
private static final long serialversionuid = 1l;
public damengrowconverter(rowtype rowtype) {
super(rowtype);
}
@override
public jdbcdeserializationconverter createinternalconverter(logicaltype type) {
switch (type.gettyperoot()) {
case null:
return val -> null;
case boolean:
case float:
case double:
case interval_year_month:
case interval_day_time:
case integer:
case bigint:
return val -> val;
case tinyint:
return val -> {
if (val instanceof byte) {
return (byte) val;
} else if (val instanceof short) {
return ((short) val).bytevalue();
} else {
return ((integer) val).bytevalue();
}
};
case smallint:
// converter for small type that casts value to int and then return short value,
// since
// jdbc 1.0 use int type for small values.
return val -> val instanceof integer ? ((integer) val).shortvalue() : val;
case decimal:
final int precision = ((decimaltype) type).getprecision();
final int scale = ((decimaltype) type).getscale();
// using decimal(20, 0) to support db type bigint unsigned, user should define
// decimal(20, 0) in sql,
// but other precision like decimal(30, 0) can work too from lenient consideration.
return val ->
val instanceof biginteger
? decimaldata.frombigdecimal(
new bigdecimal((biginteger) val, 0), precision, scale)
: decimaldata.frombigdecimal((bigdecimal) val, precision, scale);
case date:
return val ->
(int) ((date.valueof(string.valueof(val))).tolocaldate().toepochday());
case time_without_time_zone:
return val ->
(int)
((time.valueof(string.valueof(val))).tolocaltime().tonanoofday()
/ 1_000_000l);
case timestamp_with_time_zone:
case timestamp_without_time_zone:
return val -> timestampdata.fromtimestamp((timestamp) val);
case char:
case varchar:
return val -> {
// support text type
if (val instanceof dmdbclob) {
try {
return stringdata.fromstring(
inputstream2string(((dmdbclob) val).getasciistream()));
} catch (exception e) {
throw new unsupportedoperationexception(
"failed to get length from text");
}
} else if (val instanceof dmdbblob) {
try {
return stringdata.fromstring(
inputstream2string(((dmdbblob) val).getbinarystream()));
} catch (exception e) {
throw new unsupportedoperationexception(
"failed to get length from text");
}
} else {
return stringdata.fromstring((string) val);
}
};
case binary:
case varbinary:
return val ->
val instanceof dmdbblob
? ((dmdbblob) val).getbytes(1, (int) ((dmdbblob) val).length())
: val.tostring().getbytes();
case array:
case row:
case map:
case multiset:
case raw:
default:
return super.createinternalconverter(type);
}
}
@override
public string convertername() {
return "dameng";
}
/**
* get string from inputstream.
*
* @param input inputstream
* @return string value
* @throws ioexception convert exception
*/
private static string inputstream2string(inputstream input) throws ioexception {
stringbuilder stringbuffer = new stringbuilder();
byte[] byt = new byte[1024];
for (int i; (i = input.read(byt)) != -1; ) {
stringbuffer.append(new string(byt, 0, i));
}
return stringbuffer.tostring();
}
}
在flink的flink-connector-jdbc中,createinternalconverter是一个方法,用于创建将jdbc resultset中的数据转换为flink的内部数据结构的转换器。这个方法通常在jdbcinputformat中被调用。
在flink中,使用jdbcinputformat从关系型数据库中读取数据时,它会将jdbc的resultset对象作为输入,然后通过createinternalconverter方法将resultset中的每一行数据转换为flink的内部数据结构(例如tuple或row),以便后续的处理和计算。
createinternalconverter方法接受参数resultsetextractor,它是一个接口,定义了将resultset中的数据转换为flink内部数据结构的方法。实际上,flink的flink-connector-jdbc提供了一些默认的resultsetextractor实现,可以根据数据的类型自动选择适当的转换规则。例如,对于数字类型的数据,可以使用jdbctypeinformation来进行转换,对于字符串类型的数据,可以使用jdbctypeutils进行转换。
除了默认的转换器之外,也可以根据具体的需求自定义createinternalconverter方法。这样可以根据数据的特定类型或格式,定义自己的转换规则,并将resultset中的数据转换为特定的数据类型。
4.2 新增dameng的dialect
4.2.1 damengdialectfactory
package org.apache.flink.connector.jdbc.dialect.dameng;
import org.apache.flink.annotation.internal;
import org.apache.flink.connector.jdbc.dialect.jdbcdialect;
import org.apache.flink.connector.jdbc.dialect.jdbcdialectfactory;
@internal
public class damengdialectfactory implements jdbcdialectfactory {
@override
public boolean acceptsurl(string url) {
return url.startswith("jdbc:dm:");
}
@override
public jdbcdialect create() {
return new damengdialect();
}
}
在flink-connector-jdbc中,jdbcdialectfactory是一个工厂类,用于创建特定数据库的jdbcdialect实例。
jdbcdialectfactory的主要作用是根据用户提供的jdbc连接url,确定要连接的数据库类型,并创建对应的jdbcdialect实例。jdbcdialect是一个接口,定义了与特定数据库相关的sql语法和行为。不同类型的数据库可能具有一些特定的sql方言,并且可能有不同的行为和限制。jdbcdialectfactory利用jdbc连接url中所指定的数据库类型信息,根据配置中的各种数据库方言实现,创建适用于该数据库的jdbcdialect实例。
通过jdbcdialect实例,flink-connector-jdbc可以为特定类型的数据库提供更高级的功能和最佳性能。例如,jdbcdialect可以优化生成的sql查询,使用特定的语法和函数。它还可以检测数据库支持的特性,以避免不支持的操作。
使用jdbcdialectfactory时,通常在flink-connector-jdbc的连接器配置中指定jdbc连接url,以确定要连接的数据库类型。之后,会调用jdbcdialectfactory.create方法,提供jdbc连接url,根据该url创建并返回适当的jdbcdialect实例。然后,该jdbcdialect实例可以与jdbcinputformat和jdbcoutputformat等组件一起使用,以实现特定数据库的查询和操作。
4.2.2 damengdialect
package org.apache.flink.connector.jdbc.dialect.dameng;
import org.apache.flink.connector.jdbc.converter.jdbcrowconverter;
import org.apache.flink.connector.jdbc.dialect.abstractdialect;
import org.apache.flink.connector.jdbc.internal.converter.oraclerowconverter;
import org.apache.flink.table.types.logical.logicaltyperoot;
import org.apache.flink.table.types.logical.rowtype;
import java.util.arrays;
import java.util.enumset;
import java.util.optional;
import java.util.set;
import java.util.stream.collectors;
/** jdbc dialect for dameng. */
class damengdialect extends abstractdialect {
private static final long serialversionuid = 1l;
private static final int max_timestamp_precision = 9;
private static final int min_timestamp_precision = 1;
private static final int max_decimal_precision = 38;
private static final int min_decimal_precision = 1;
@override
public jdbcrowconverter getrowconverter(rowtype rowtype) {
return new oraclerowconverter(rowtype);
}
@override
public string getlimitclause(long limit) {
return "fetch first " + limit + " rows only";
}
@override
public optional<string> defaultdrivername() {
return optional.of("dm.jdbc.driver.dmdriver");
}
@override
public string dialectname() {
return "dameng";
}
@override
public string quoteidentifier(string identifier) {
return identifier;
}
@override
public optional<string> getupsertstatement(
string tablename, string[] fieldnames, string[] uniquekeyfields) {
string sourcefields =
arrays.stream(fieldnames)
.map(f -> ":" + f + " " + quoteidentifier(f))
.collect(collectors.joining(", "));
string onclause =
arrays.stream(uniquekeyfields)
.map(f -> "t." + quoteidentifier(f) + "=s." + quoteidentifier(f))
.collect(collectors.joining(" and "));
final set<string> uniquekeyfieldsset =
arrays.stream(uniquekeyfields).collect(collectors.toset());
string updateclause =
arrays.stream(fieldnames)
.filter(f -> !uniquekeyfieldsset.contains(f))
.map(f -> "t." + quoteidentifier(f) + "=s." + quoteidentifier(f))
.collect(collectors.joining(", "));
string insertfields =
arrays.stream(fieldnames)
.map(this::quoteidentifier)
.collect(collectors.joining(", "));
string valuesclause =
arrays.stream(fieldnames)
.map(f -> "s." + quoteidentifier(f))
.collect(collectors.joining(", "));
// if we can't divide schema and table-name is risky to call quoteidentifier(tablename)
// for example [tbo].[sometable] is ok but [tbo.sometable] is not
string mergequery =
" merge into "
+ tablename
+ " t "
+ " using (select "
+ sourcefields
+ " from dual) s "
+ " on ("
+ onclause
+ ") "
+ " when matched then update set "
+ updateclause
+ " when not matched then insert ("
+ insertfields
+ ")"
+ " values ("
+ valuesclause
+ ")";
return optional.of(mergequery);
}
@override
public optional<range> decimalprecisionrange() {
return optional.of(range.of(min_decimal_precision, max_decimal_precision));
}
@override
public optional<range> timestampprecisionrange() {
return optional.of(range.of(min_timestamp_precision, max_timestamp_precision));
}
@override
public set<logicaltyperoot> supportedtypes() {
// the data types used in dameng are list at:
// https://www.techonthenet.com/oracle/datatypes.php
return enumset.of(
logicaltyperoot.char,
logicaltyperoot.varchar,
logicaltyperoot.boolean,
logicaltyperoot.varbinary,
logicaltyperoot.decimal,
logicaltyperoot.tinyint,
logicaltyperoot.smallint,
logicaltyperoot.integer,
logicaltyperoot.bigint,
logicaltyperoot.float,
logicaltyperoot.double,
logicaltyperoot.date,
logicaltyperoot.time_without_time_zone,
logicaltyperoot.timestamp_without_time_zone,
logicaltyperoot.timestamp_with_local_time_zone,
logicaltyperoot.array);
}
}
在flink-connector-jdbc中,jdbcdialect是一个接口,用于定义与特定数据库相关的sql语法和行为。每种不同类型的数据库可能有一些特定的sql方言和行为,jdbcdialect提供了一种方式来处理这些差异,以确保在不同类型的数据库上执行的sql操作正确执行,并且能够提供最佳的性能。
jdbcdialect接口定义了以下几种方法:
- string quoteidentifier(string identifier): 将标识符(例如表名、列名)包装在适当的引号中,以在sql语句中正确引用它。这是为了处理不同数据库对标识符的命名规则的差异。
- jdbcrowconverter getrowconverter(rowtypeinfo rowtypeinfo): 根据给定的rowtypeinfo,创建一个jdbcrowconverter实例,用于将flink的row数据对象转换为适用于特定数据库的jdbc数据对象。这是为了处理不同数据库对数据类型的差异。
- optional defaultdrivername(): 获取jdbc驱动程序的默认名称,以在使用未指定驱动程序名称的情况下与数据库建立连接。
- optional getupsertstatement(string tablename, string[] fieldnames, string[] uniquekeyfields): 用于生成用于"upsert"(插入或更新)操作的sql语句。"upsert"操作是指当目标表中存在指定的记录时,执行更新操作;如果不存在,则执行插入操作;在具体的jdbcdialect的实现中,getupsertstatement方法会根据特定数据库的语法和行为生成相应的sql语句。不同数据库对于"upsert"操作的语法可能有所不同,因此jdbcdialect会根据数据库类型来生成适当的语句。
jdbcdialect的具体实现类会根据特定数据库的特性来实现这些方法,以确保flink-connector-jdbc在不同类型的数据库上能够正确工作。例如,mysqldialect、postgresdialect和oracledialect等都是jdbcdialect的实现类,分别处理mysql、postgresql和oracle数据库的特定语法和行为。
5. 实测
编译打包不难,这里略过,我们测试一下;
我这边第一次测试时,就遇到一个大坑,数据写入失败,日志如下:
2023-09-01 17:38:58,545 error org.apache.flink.connector.jdbc.internal.jdbcoutputformat [] - jdbc executebatch error, retry times = 0
dm.jdbc.driver.dmexception: unbinded parameter: 0
at dm.jdbc.driver.dberror.throwz(dberror.java:727) ~[dmjdbcdriver18-8.1.2.79.jar:- 8.1.2.79 - production]
at dm.jdbc.driver.dmdbpreparedstatement.checkbindparameters(dmdbpreparedstatement.java:347) ~[dmjdbcdriver18-8.1.2.79.jar:- 8.1.2.79 - production]
at dm.jdbc.driver.dmdbpreparedstatement.beforeexectuewithparameters(dmdbpreparedstatement.java:372) ~[dmjdbcdriver18-8.1.2.79.jar:- 8.1.2.79 - production]
at dm.jdbc.driver.dmdbpreparedstatement.do_executelargebatch(dmdbpreparedstatement.java:535) ~[dmjdbcdriver18-8.1.2.79.jar:- 8.1.2.79 - production]
at dm.jdbc.driver.dmdbpreparedstatement.do_executebatch(dmdbpreparedstatement.java:514) ~[dmjdbcdriver18-8.1.2.79.jar:- 8.1.2.79 - production]
at dm.jdbc.driver.dmdbpreparedstatement.executebatch(dmdbpreparedstatement.java:1494) ~[dmjdbcdriver18-8.1.2.79.jar:- 8.1.2.79 - production]
at org.apache.flink.connector.jdbc.statement.fieldnamedpreparedstatementimpl.executebatch(fieldnamedpreparedstatementimpl.java:65) ~[flink-connector-jdbc-1.17.0.jar:1.17.0]
at org.apache.flink.connector.jdbc.internal.executor.tableinsertorupdatestatementexecutor.executebatch(tableinsertorupdatestatementexecutor.java:104) ~[flink-connector-jdbc-1.17.0.jar:1.17.0]
at org.apache.flink.connector.jdbc.internal.executor.tablebufferreducedstatementexecutor.executebatch(tablebufferreducedstatementexecutor.java:101) ~[flink-connector-jdbc-1.17.0.jar:1.17.0]
at org.apache.flink.connector.jdbc.internal.jdbcoutputformat.attemptflush(jdbcoutputformat.java:246) ~[flink-connector-jdbc-1.17.0.jar:1.17.0]
at org.apache.flink.connector.jdbc.internal.jdbcoutputformat.flush(jdbcoutputformat.java:216) ~[flink-connector-jdbc-1.17.0.jar:1.17.0]
at org.apache.flink.connector.jdbc.internal.jdbcoutputformat.lambda$open$0(jdbcoutputformat.java:155) ~[flink-connector-jdbc-1.17.0.jar:1.17.0]
at java.util.concurrent.executors$runnableadapter.call(executors.java:511) [?:1.8.0_221]
at java.util.concurrent.futuretask.runandreset(futuretask.java:308) [?:1.8.0_221]
at java.util.concurrent.scheduledthreadpoolexecutor$scheduledfuturetask.access$301(scheduledthreadpoolexecutor.java:180) [?:1.8.0_221]
at java.util.concurrent.scheduledthreadpoolexecutor$scheduledfuturetask.run(scheduledthreadpoolexecutor.java:294) [?:1.8.0_221]
at java.util.concurrent.threadpoolexecutor.runworker(threadpoolexecutor.java:1149) [?:1.8.0_221]
at java.util.concurrent.threadpoolexecutor$worker.run(threadpoolexecutor.java:624) [?:1.8.0_221]
at java.lang.thread.run(thread.java:748) [?:1.8.0_221]
2023-09-01 17:38:58,679 error org.apache.flink.connector.jdbc.internal.jdbcoutputformat [] - jdbc executebatch error, retry times = 1
dm.jdbc.driver.dmexception: unbinded parameter: 0
这个异常很奇怪:dm.jdbc.driver.dmexception: unbinded parameter: 0
总之,代码看不出问题来,正百思不得其解的时候,决定升级dmjdbcdriver试试,从8.1.2.79升到了8.1.2.141,终于成功了!
原始代码下载可以参考: https://gitee.com/flink_acme/flink-connector-jdbc.git
6. 附
达梦数据库版本:
sql> select *,id_code from v$version;
lineid banner id_code
---------- ------------------------- ---------------------------------------
1 dm database server 64 v8 1-2-38-21.07.09-143359-10018-ent pack1
2 db version: 0x7000c 1-2-38-21.07.09-143359-10018-ent pack1
used time: 00:00:07.719. execute id is 2300.
sql>
sql> select * from v$instance;
lineid name instance_name instance_number host_name svr_version db_version
---------- -------- ------------- --------------- --------- -------------------------- -------------------
start_time status$ mode$ oguid dsc_seqno dsc_role
------------------- ------- ------ ----------- ----------- --------
1 dmserver dmserver 1 bd161 dm database server x64 v8 db version: 0x7000c
2023-08-28 13:51:41 open normal 0 0 null
used time: 565.918(ms). execute id is 2301.



发表评论