一、什么是 cdc ?
cdc 是 change data capture(变更数据获取) 的简称。 核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、 更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
二、flink-cdc 是什么?
cdc connectors for apache flink是一组用于apache flink 的源连接器,使用变更数据捕获 (cdc) 从不同数据库获取变更。用于 apache flink 的 cdc 连接器将 debezium 集成为捕获数据更改的引擎。所以它可以充分发挥 debezium 的能力。
大概意思就是,flink 社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 mysql、 postgresql等数据库直接读取全量数据和增量变更数据的 source 组件。
flink-cdc 开源地址: apache/flink-cdc
flink-cdc 中文文档:apache flink cdc | apache flink cdc
三、springboot 整合 flink-cdc
3.1、如何集成到springboot中?
flink 作业通常独立于一般的服务之外,专门编写代码,用 flink 命令行工具来运行和停止。将flink 作业集成到 spring boot 应用中并不常见,而且一般也不建议这样做,因为flink作业一般运行在大数据环境中。
然而,在特殊需求下,我们可以做一些改变使 flink 应用适应 spring boot 环境,比如在你的场景中使用 flink cdc 进行 数据变更捕获。将 flink 作业以本地项目的方式启动,集成在 spring boot应用中,可以使用到 spring 的便利性。
- commandlinerunner
- applicationrunner
3.2、集成举例
1、commandlinerunner
@springbootapplication
public class myapp {
public static void main(string[] args) {
springapplication.run(myapp.class, args);
}
@bean
public commandlinerunner commandlinerunner(applicationcontext ctx) {
return args -> {
streamexecutionenvironment env = streamexecutionenvironment.getexecutionenvironment();
debeziumsourcefunction<string> sourcefunction = mysqlsource.<string>builder()
.hostname("localhost")
.port(3306)
.username("flinkuser")
.password("flinkpw")
.databaselist("mydb") // monitor all tables under "mydb" database
.tablelist("mydb.table1", "mydb.table2") // monitor only "table1" and "table2" under "mydb" database
.deserializer(new stringdebeziumdeserializationschema()) // converts sourcerecord to string
.build();
datastreamsource<string> mysqlsource = env.addsource(sourcefunction);
// formulate processing logic here, e.g., printing to standard output
mysqlsource.print();
// execute the flink job within the spring boot application
env.execute("flink cdc");
};
}
}
2、applicationrunner
@springbootapplication
public class flinkcdcapplication implements applicationrunner {
public static void main(string[] args) {
springapplication.run(flinkcdcapplication.class, args);
}
@override
public void run(applicationarguments args) throws exception {
final streamexecutionenvironment env = streamexecutionenvironment.getexecutionenvironment();
// configure your flink job here
debeziumsourcefunction<string> sourcefunction = mysqlsource.<string>builder()
.hostname("localhost")
.port(3306)
.username("flinkuser")
.password("flinkpw")
.databaselist("mydb")
// set other source options ...
.deserializer(new stringdebeziumdeserializationschema()) // converts sourcerecord to string
.build();
datastream<string> cdcstream = env.addsource(sourcefunction);
// implement your processing logic here
// for example:
cdcstream.print();
// start the flink job within the spring boot application
env.execute("flink cdc with spring boot");
}
}
这次用例采用 applicationrunner,不过要改变一下,让 flink cdc 作为 bean 来实现。
四、功能实现
4.1、功能逻辑
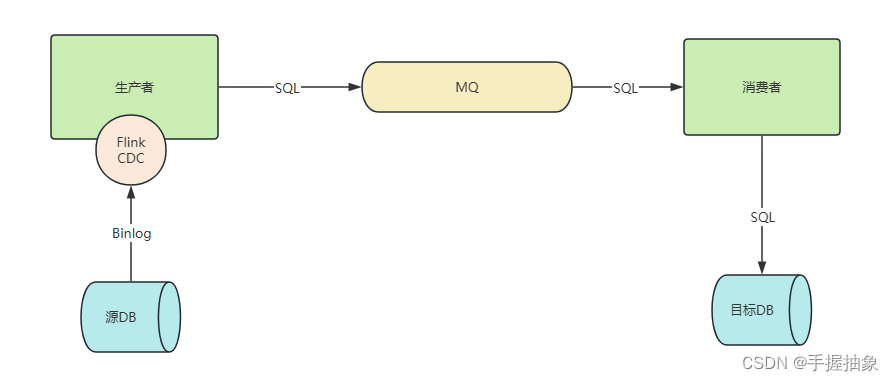
总体来讲,不太想把 flink cdc单独拉出来,更想让它依托于一个服务上,彻底当成一个组件。
其中在生产者中,我们将要进行实现:
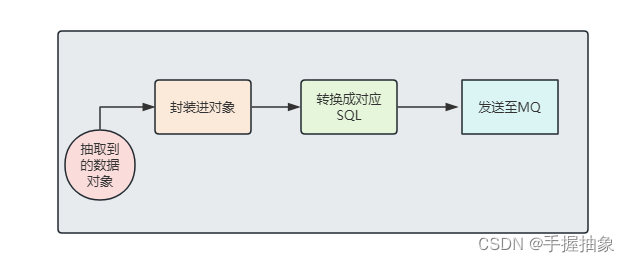
4.2、所需环境
- mysql 5.7 +:确保源数据库已经开启 binlog 日志功能,并且设置 row 格式
- spring boot 2.7.6:还是不要轻易使用 3.0 以上为好,有好多jar没有适配
- rabbitmq:适配即可
- flink cdc:特别注意版本
4.3、flink cdc pom依赖
<flink.version>1.13.6</flink.version>
<dependency>
<groupid>org.apache.flink</groupid>
<artifactid>flink-clients_2.12</artifactid>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupid>org.apache.flink</groupid>
<artifactid>flink-java</artifactid>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupid>org.apache.flink</groupid>
<artifactid>flink-streaming-java_2.12</artifactid>
<version>${flink.version}</version>
</dependency>
<!--mysql -cdc-->
<dependency>
<groupid>com.ververica</groupid>
<artifactid>flink-connector-mysql-cdc</artifactid>
<version>2.0.0</version>
</dependency>
<dependency>
<groupid>org.projectlombok</groupid>
<artifactid>lombok</artifactid>
<version>1.18.10</version>
</dependency>
<dependency>
<groupid>cn.hutool</groupid>
<artifactid>hutool-all</artifactid>
<version>5.8.5</version>
</dependency>
<dependency>
<groupid>org.apache.commons</groupid>
<artifactid>commons-lang3</artifactid>
<version>3.10</version>
</dependency>
<dependency>
<groupid>com.alibaba</groupid>
<artifactid>fastjson</artifactid>
<version>2.0.42</version>
</dependency>上面是一些flink cdc必须的依赖,当然如果需要实现其他数据库,可以替换其他数据库的cdc jar。怎么安排jar包的位置和其余需要的jar,这个可自行调整。
4.4、代码展示
核心类
- mysqleventlistener:配置类
- mysqldeserialization:mysql消息读取自定义序列化
- datachangeinfo:封装的变更对象
- datachangesink:继承一个flink提供的抽象类,用于定义数据的输出或“下沉”逻辑,sink 是flink处理流的最后阶段,通常用于将数据写入外部系统,如数据库、文件系统、消息队列等
(1)通过 applicationrunner 接入 springboot
@component
public class mysqleventlistener implements applicationrunner {
private final datachangesink datachangesink;
public mysqleventlistener(datachangesink datachangesink) {
this.datachangesink = datachangesink;
}
@override
public void run(applicationarguments args) throws exception {
streamexecutionenvironment env = streamexecutionenvironment.getexecutionenvironment();
env.setparallelism(1);
debeziumsourcefunction<datachangeinfo> datachangeinfomysqlsource = builddatachangesourceremote();
datastream<datachangeinfo> streamsource = env
.addsource(datachangeinfomysqlsource, "mysql-source")
.setparallelism(1);
streamsource.addsink(datachangesink);
env.execute("mysql-stream-cdc");
}
private debeziumsourcefunction<datachangeinfo> builddatachangesourcelocal() {
return mysqlsource.<datachangeinfo>builder()
.hostname("127.0.0.1")
.port(3306)
.username("root")
.password("0507")
.databaselist("flink-cdc-producer")
.tablelist("flink-cdc-producer.producer_content", "flink-cdc-producer.name_content")
/*
* initial初始化快照,即全量导入后增量导入(检测更新数据写入)
* latest:只进行增量导入(不读取历史变化)
* timestamp:指定时间戳进行数据导入(大于等于指定时间错读取数据)
*/
.startupoptions(startupoptions.latest())
.deserializer(new mysqldeserialization())
.servertimezone("gmt+8")
.build();
}
}(2)自定义 mysql 消息读取序列化
public class mysqldeserialization implements debeziumdeserializationschema<datachangeinfo> {
public static final string ts_ms = "ts_ms";
public static final string bin_file = "file";
public static final string pos = "pos";
public static final string create = "create";
public static final string before = "before";
public static final string after = "after";
public static final string source = "source";
public static final string update = "update";
/**
* 反序列化数据,转为变更json对象
*/
@override
public void deserialize(sourcerecord sourcerecord, collector<datachangeinfo> collector) {
string topic = sourcerecord.topic();
string[] fields = topic.split("\\.");
string database = fields[1];
string tablename = fields[2];
struct struct = (struct) sourcerecord.value();
final struct source = struct.getstruct(source);
datachangeinfo datachangeinfo = new datachangeinfo();
datachangeinfo.setbeforedata(getjsonobject(struct, before).tojsonstring());
datachangeinfo.setafterdata(getjsonobject(struct, after).tojsonstring());
//5.获取操作类型 create update delete
envelope.operation operation = envelope.operationfor(sourcerecord);
// string type = operation.tostring().touppercase();
// int eventtype = type.equals(create) ? 1 : update.equals(type) ? 2 : 3;
datachangeinfo.seteventtype(operation.name());
datachangeinfo.setfilename(optional.ofnullable(source.get(bin_file)).map(object::tostring).orelse(""));
datachangeinfo.setfilepos(optional.ofnullable(source.get(pos)).map(x -> integer.parseint(x.tostring())).orelse(0));
datachangeinfo.setdatabase(database);
datachangeinfo.settablename(tablename);
datachangeinfo.setchangetime(optional.ofnullable(struct.get(ts_ms)).map(x -> long.parselong(x.tostring())).orelseget(system::currenttimemillis));
//7.输出数据
collector.collect(datachangeinfo);
}
private struct getstruct(struct value, string fieldelement) {
return value.getstruct(fieldelement);
}
/**
* 从元数据获取出变更之前或之后的数据
*/
private jsonobject getjsonobject(struct value, string fieldelement) {
struct element = value.getstruct(fieldelement);
jsonobject jsonobject = new jsonobject();
if (element != null) {
schema afterschema = element.schema();
list<field> fieldlist = afterschema.fields();
for (field field : fieldlist) {
object aftervalue = element.get(field);
jsonobject.put(field.name(), aftervalue);
}
}
return jsonobject;
}
@override
public typeinformation<datachangeinfo> getproducedtype() {
return typeinformation.of(datachangeinfo.class);
}
}(3)封装的变更对象
@data
public class datachangeinfo implements serializable {
/**
* 变更前数据
*/
private string beforedata;
/**
* 变更后数据
*/
private string afterdata;
/**
* 变更类型 1新增 2修改 3删除
*/
private string eventtype;
/**
* binlog文件名
*/
private string filename;
/**
* binlog当前读取点位
*/
private integer filepos;
/**
* 数据库名
*/
private string database;
/**
* 表名
*/
private string tablename;
/**
* 变更时间
*/
private long changetime;
}(4)定义 flink 的 sink
@component
@slf4j
public class datachangesink extends richsinkfunction<datachangeinfo> {
transient rabbittemplate rabbittemplate;
transient confirmservice confirmservice;
transient tabledataconvertservice tabledataconvertservice;
@override
public void invoke(datachangeinfo value, context context) {
log.info("收到变更原始数据:{}", value);
//转换后发送到对应的mq
if (migration_table_cache.containskey(value.gettablename())) {
string routingkey = migration_table_cache.get(value.gettablename());
//可根据需要自行进行confirmservice的设计
rabbittemplate.setreturnscallback(confirmservice);
rabbittemplate.setconfirmcallback(confirmservice);
rabbittemplate.convertandsend(exchange_name, routingkey, tabledataconvertservice.convertsqlbydatachangeinfo(value));
}
}
/**
* 在启动springboot项目是加载了spring容器,其他地方可以使用@autowired获取spring容器中的类;但是flink启动的项目中,
* 默认启动了多线程执行相关代码,导致在其他线程无法获取spring容器,只有在spring所在的线程才能使用@autowired,
* 故在flink自定义的sink的open()方法中初始化spring容器
*/
@override
public void open(configuration parameters) throws exception {
super.open(parameters);
this.rabbittemplate = applicationcontextutil.getbean(rabbittemplate.class);
this.confirmservice = applicationcontextutil.getbean(confirmservice.class);
this.tabledataconvertservice = applicationcontextutil.getbean(tabledataconvertservice.class);
}
}(5)数据转换类接口和实现类
public interface tabledataconvertservice {
string convertsqlbydatachangeinfo(datachangeinfo datachangeinfo);
}@service
public class tabledataconvertserviceimpl implements tabledataconvertservice {
@autowired
map<string, sqlgeneratorservice> sqlgeneratorservicemap;
@override
public string convertsqlbydatachangeinfo(datachangeinfo datachangeinfo) {
sqlgeneratorservice sqlgeneratorservice = sqlgeneratorservicemap.get(datachangeinfo.geteventtype());
return sqlgeneratorservice.generatorsql(datachangeinfo);
}
}因为在 datachangeinfo 中我们有封装对象的类型(create、delete、update),所以我希望通过不同类来进行不同的工作。于是就有了下面的类结构:
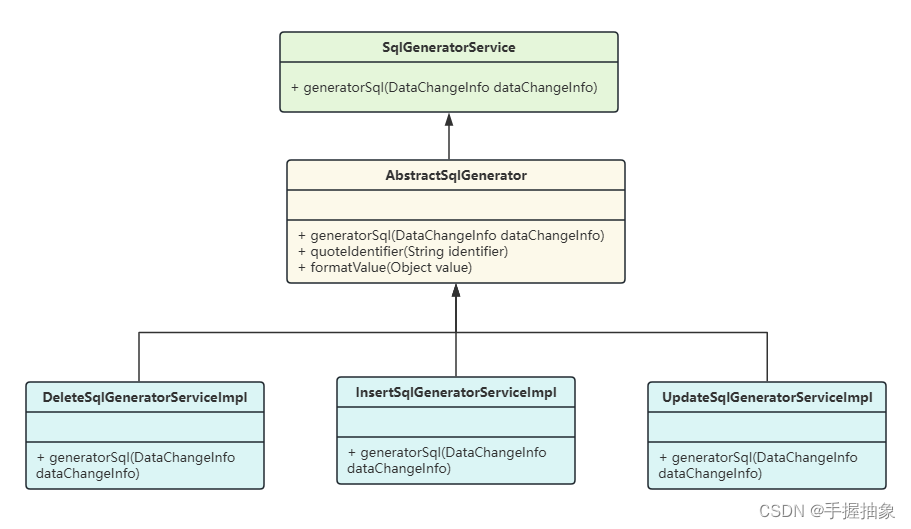
根据 datachangeinfo 的类型去生成对应的 sqlgeneratorserviceimpl。
值得注意的是,在 tabledataconvertserviceimpl 中,我们注入了一个 map<string, sqlgeneratorservice> sqlgeneratorservicemap,通过它来进行具体实现类的获取。那么他是个什么东西呢?作用是什么呢?为什么可以通过它来获取呢?
@resource、@autowired 标注作用于 map 类型时,如果 map 的 key 为 string 类型,则 spring 会将容器中所有类型符合 map 的 value 对应的类型的 bean 增加进来,用 bean 的 id 或 name 作为 map 的 key。
那么可以看到下面第六步,在进行deletesqlgeneratorserviceimpl装配的时候进行指定了名字@service("delete"),方便通过datachangeinfo获取。
(6)转换类部分代码
public interface sqlgeneratorservice {
string generatorsql(datachangeinfo datachangeinfo);
}
public abstract class abstractsqlgenerator implements sqlgeneratorservice {
@override
public string generatorsql(datachangeinfo datachangeinfo) {
return null;
}
public string quoteidentifier(string identifier) {
// 对字段名进行转义处理,这里简化为对其加反引号
// 实际应该处理数据库标识符的特殊字符
return "`" + identifier + "`";
}
}@service("delete")
@slf4j
public class deletesqlgeneratorserviceimpl extends abstractsqlgenerator {
@override
public string generatorsql(datachangeinfo datachangeinfo) {
string beforedata = datachangeinfo.getbeforedata();
map<string, object> beforedatamap = jsonobjectutils.jsontomap(beforedata);
stringbuilder wherepart = new stringbuilder();
for (string key : beforedatamap.keyset()) {
object beforevalue = beforedatamap.get(key);
if ("create_time".equals(key)){
simpledateformat dateformat = new simpledateformat("yyyy-mm-dd hh:mm:ss");
beforevalue = dateformat.format(beforevalue);
}
if (wherepart.length() > 0) {
// 不是第一个更改的字段,增加逗号分隔
wherepart.append(", ");
}
wherepart.append(quoteidentifier(key)).append(" = ").append(formatvalue(beforevalue));
}
log.info("wherepart : {}", wherepart);
return "delete from " + datachangeinfo.gettablename() + " where " + wherepart;
}
}核心代码如上所示,具体实现可自行设计。
五、源码获取
github:incremental-sync-flink-cdc



发表评论