文章目录
1. 架构图
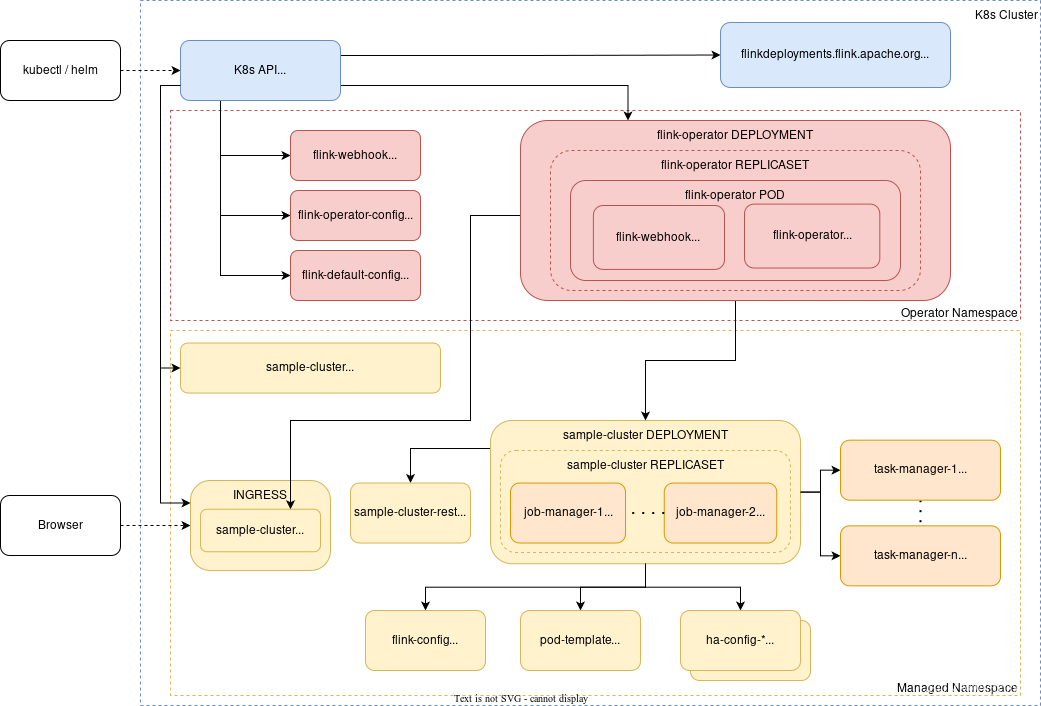
参考:部署验证demo
2. helm 安装operator
安装cert-manager依赖
jetstack/cert-manager 是 kubernetes 生态系统中的一款开源项目,它提供了一种自动化的方式来管理 tls 证书的生命周期
kubectl create -f https://github.com/jetstack/cert-manager/releases/download/v1.8.2/cert-manager.yaml
# helm 安装 , 包含 deploy*1 、cm*1、crd*2 以及 rbac sa webhook
kubectl create -f https://github.com/jetstack/cert-manager/releases/download/v1.8.2/cert-manager.yaml
helm repo add flink-operator-repo https://downloads.apache.org/flink/flink-kubernetes-operator-1.7.0/
helm install flink-kubernetes-operator flink-operator-repo/flink-kubernetes-operator
3. 集群知识
k8s上的两种模式:native和standalone
flink kubernetes operator 支持:原生部署native(默认)和独立部署standalone
可以使用部署规范中的 mode 字段设置部署模式。
apiversion: flink.apache.org/v1beta1
kind: flinkdeployment
...
spec:
...
mode: standalone
两种cr
flinkdeployment cr 定义了 flink 应用程序和会话集群部署。
flinksessionjob cr 定义了 session 集群上的会话任务(job)
flink kubernetes operator 支持两种主要类型的部署:application集群 和 session集群 ,k8s上不支持job集群。
4. 运行集群实例
demo1:application 集群
一次性任务,只有一个job,执行器和逻辑代码打包成一个jar,直接运行,运行即结束。
# 此crd创建后,operator会创建:
# 1个deploy(即jobmanager,镜像为flink:1.17)
# 1个pod(即taskmanager,镜像也是flink:1.17,任务jar包在镜像中)
apiversion: flink.apache.org/v1beta1
kind: flinkdeployment
metadata:
name: basic-example
spec:
image: flink:1.17
flinkversion: v1_17
flinkconfiguration:
taskmanager.numberoftaskslots: "2"
serviceaccount: flink
jobmanager:
resource:
memory: "2048m"
cpu: 1
taskmanager:
resource:
memory: "2048m"
cpu: 1
job:
jaruri: local:///opt/flink/examples/streaming/statemachineexample.jar
parallelism: 2
upgrademode: stateless
注:k8s不支持job集群,可以看做是 flink application 集群”客户端运行“的替代方案。集群管理器为每个提交的作业启动一个集群。
demo2:session集群
多租户,多个job,每个sessionjob代表一个job,有提交jar包的功能。
session使用与application 集群类似的规范,唯一的区别是 job 未定义。
apiversion: flink.apache.org/v1beta1
kind: flinkdeployment
metadata:
name: basic-session-deployment-example
spec:
image: flink:1.17
flinkversion: v1_17
jobmanager:
resource:
memory: "2048m"
cpu: 1
taskmanager:
resource:
memory: "2048m"
cpu: 1
serviceaccount: flink
---
apiversion: flink.apache.org/v1beta1
kind: flinksessionjob
metadata:
name: basic-session-job-example
spec:
deploymentname: basic-session-deployment-example
job:
jaruri: https://repo1.maven.org/maven2/org/apache/flink/flink-examples-streaming_2.12/1.16.1/flink-examples-streaming_2.12-1.16.1-topspeedwindowing.jar
parallelism: 4
upgrademode: stateless
---
apiversion: flink.apache.org/v1beta1
kind: flinksessionjob
metadata:
name: basic-session-job-example2
spec:
deploymentname: basic-session-deployment-example
job:
jaruri: https://repo1.maven.org/maven2/org/apache/flink/flink-examples-streaming_2.12/1.16.1/flink-examples-streaming_2.12-1.16.1.jar
parallelism: 2
upgrademode: stateless
entryclass: org.apache.flink.streaming.examples.statemachine.statemachineexample
注:为了方便访问,可以再创建ingress。svc端口默认为8081,指向svc-rest即可。
优劣
- session集群,是常规的共享方式。
- application集群,提供了更好的隔离,生命周期与程序逻辑有关。
- job集群,适合长期运行、要求高稳定性的大型作业。(启动慢)
5. 高可用部署
flink 提供了两种高可用服务实现:
- zookeeper:每个 flink 集群部署都可以使用 zookeeper ha 服务。它们需要一个运行的 zookeeper 复制组(quorum)。
- kubernetes:kubernetes ha 服务只能运行在 kubernetes 上。
注:flink 持久化元数据和 job 组件,直到作业执行成功、被取消或最终失败,再删除。
我在实践时,遇到两个问题:
问题1:high availability should be enabled when starting standby jobmanagers
直接增加jobmanager的副本数提示上述错误,要先做选举配置,我选择的是k8s实现,下面仅列出修改部分,注意flinkconfiguration和podtemplate两部分:
apiversion: flink.apache.org/v1beta1
kind: flinkdeployment
spec:
flinkconfiguration:
high-availability: org.apache.flink.kubernetes.highavailability.kuberneteshaservicesfactory
high-availability.storagedir: file:///flink-data/ha
web.upload.dir: /flink-data #会自动创建flink-web-upload目录保存上传的jar包
jobmanager:
replicas: 2
taskmanager:
replicas: 2
podtemplate:
spec:
containers:
- name: flink-main-container
volumemounts:
- mountpath: /flink-data
name: flink-volume
volumes:
- name: flink-volume
persistentvolumeclaim:
claimname: flink-ha
问题2:the base directory of the jobresultstore isn’t accessible
如果没有正确挂载存储卷提示上述错误。
官方demo配置的卷是宿主机的路径,如下:
volumes:
- name: flink-volume
hostpath:
path: /tmp/flink # 如果宿主机上没有这个路径会报错
type: director
6. 补充
- 拉取国外镜像比较困难,可以使用https://dockerproxy.com/
- 搭建多租户paas平台,可以使用session方式,新任务可以通过cr进行管理,也可以由页面添加jar包。
- 本文内容来源于flink官网,进行翻译、简化、整理,供大家参考~

发表评论