系列文章目录
一、spark应用程序启动与资源申请
二、dag(有向无环图)的构建与划分
三、task的生成与调度
四、task的执行与结果返回
五、监控与容错
六、优化策略
文章目录
前言
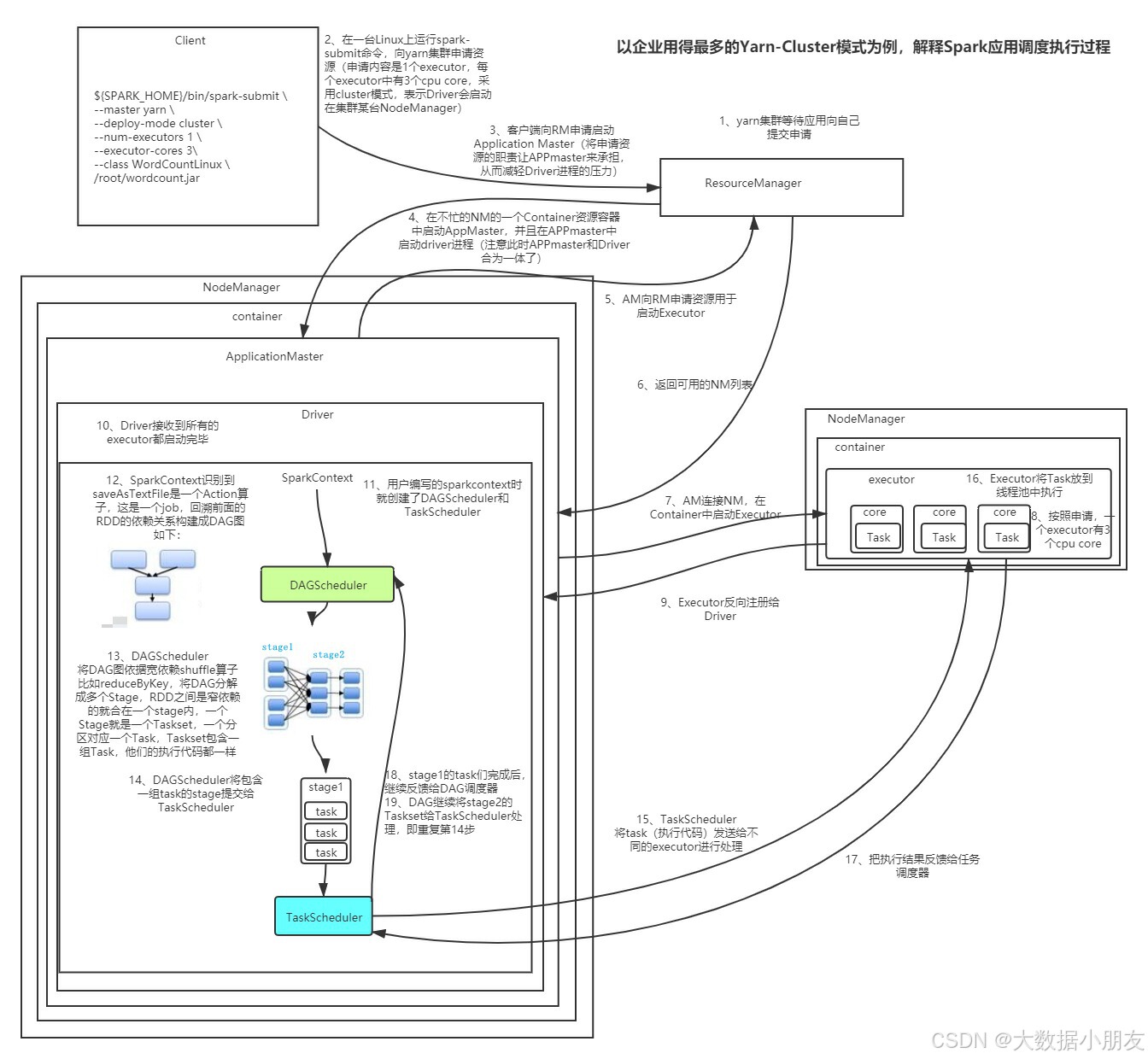
spark调度底层执行原理是一个复杂而精细的过程,它涉及到多个组件的交互和协同工作,以实现大数据处理的高效性和灵活性。本文主要对spark调度底层执行原理进行详细解析。
- spark调度底层执行原理详解图
一、spark应用程序启动与资源申请
1. sparkcontext的创建
当spark应用程序启动时,首先会创建sparkcontext对象。sparkcontext是spark的入口点,负责初始化与资源管理器(如yarn、mesos等)的连接,注册应用,并请求分配executor资源。
2. 资源申请
sparkcontext向资源管理器注册并向其申请运行executor。资源管理器分配executor资源后,启动executor进程。这些executor是spark在每个worker节点上启动的进程,负责执行具体的task。
二、dag(有向无环图)的构建与划分
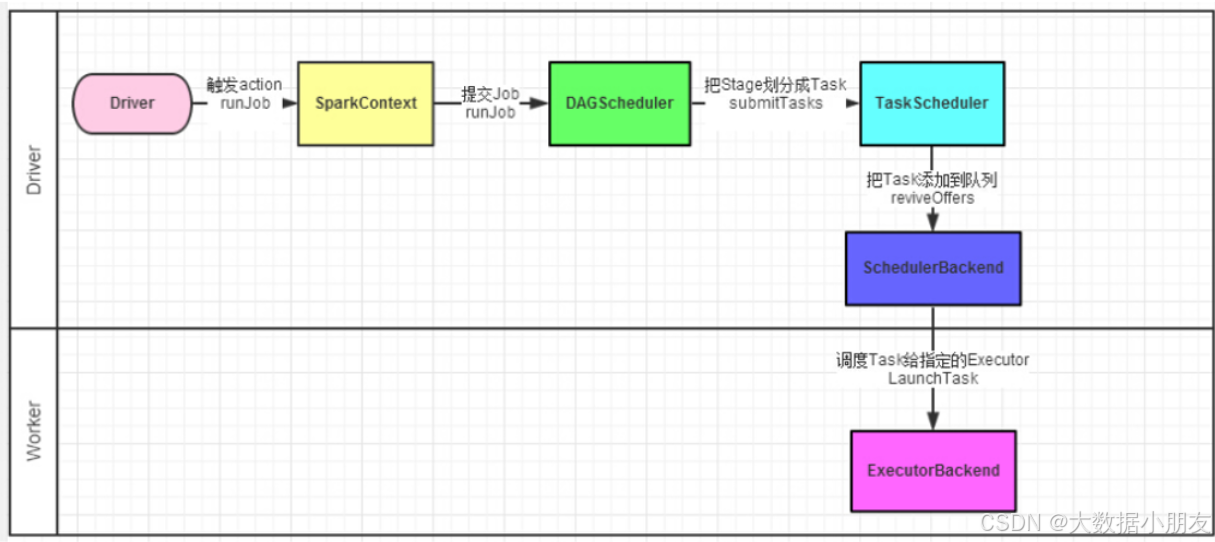
spark的dag(directed acyclic graph,有向无环图)调度原理是spark作业调度机制的核心部分,它负责将复杂的作业分解成可并行执行的任务集,并通过任务调度器进行高效执行。以下是spark dag调度原理的详细解释:
1. dag的构建
用户代码中包含transformations(转换操作)和actions(行动操作)时,spark会构建一个dag来表示rdd(弹性分布式数据集)之间的依赖关系。这些依赖关系决定了数据处理的流程。
- rdd的依赖关系:
在spark中,rdd(弹性分布式数据集)是数据处理的基本单位。rdd之间的依赖关系决定了数据处理的流程和顺序。这些依赖关系是有向的,总是由子rdd指向父rdd。 - dag的生成:
当用户提交一个spark作业时,spark会根据rdd之间的依赖关系构建一个dag。这个dag表示了作业中所有rdd之间的转换和行动操作,以及它们之间的数据流动关系。
2. dag的划分
- dag scheduler负责将dag划分为多个stage(阶段)。stage的划分依据是rdd依赖关系中的宽依赖(如shuffle操作)。宽依赖标志着数据重分布的需求,自然成为stage的边界。每个stage包含一组可以并行执行的task。
- stage的划分:
如果rdd之间的依赖是窄依赖(即一个父rdd的分区只会被一个子rdd的分区使用),则它们会被划分到同一个stage中。如果依赖是宽依赖(即一个父rdd的分区会被多个子rdd的分区使用,通常涉及shuffle操作),则会在宽依赖处进行stage的划分。
task的生成:
每个stage会被进一步划分为多个task(任务)。这些task是spark实际执行的最小单元,它们将被分发到集群中的executor上执行。
3. dag的调度执行
- task的提交与执行:
dag scheduler将划分好的stage提交给task scheduler。task scheduler负责将stage中的task分发到集群的executor上执行。executor多线程地执行task,每个线程负责一个task。 - 执行结果的收集:
当task执行完成后,会将结果返回给task scheduler。task scheduler将结果汇总后,通知dag scheduler。dag scheduler根据task的执行结果和stage的依赖关系,决定是否提交下一个stage执行。 - 容错与重试:
如果某个task执行失败,task scheduler会负责重试该task。如果某个stage中的所有task都执行失败,dag scheduler会重新提交该stage执行。这种容错机制保证了spark作业的健壮性和可靠性。
4. dag调度的优化
- 本地性优化:
spark在调度task时,会尽量将task分配到存储了所需数据的节点上执行,以减少数据的网络传输开销。这种本地性优化策略提高了spark作业的执行效率。 - 资源动态分配:
spark支持资源的动态分配,即根据作业的执行情况和集群的负载情况动态调整executor的数量和资源。这种动态分配策略有助于充分利用集群资源,提高资源利用率。
综上所述,spark的dag调度原理是一个复杂而高效的过程,它通过将作业分解成可并行执行的stage和task,并利用dag scheduler和task scheduler进行高效的调度执行。同时,spark还通过本地性优化和资源动态分配等策略来优化dag调度的性能。
三、task的生成与调度
1. task的生成
dag scheduler将每个stage转换为一个或多个taskset(任务集),task scheduler负责将这些taskset分配到各个executor上执行。
2. task的调度
task scheduler接收dag scheduler提交过来的taskset,并将task分发到集群中的executor上运行。executor多线程地执行task,每个线程负责一个task。
四、task的执行与结果返回
1. task的执行
task在executor上执行,处理数据,并将结果返回给driver。对于shufflemaptask,计算结果会写入blockmanager中,并返回给dag scheduler一个mapstatus对象,存储blockmanager的基本信息,这些信息将成为下一个阶段任务获取输入数据的依据。
2. 结果的返回
对于resulttask(最终任务),返回的是func函数的计算结果。这些结果会被发送到driver端,供用户程序进一步处理或展示。
五、监控与容错
1. 监控
dagscheduler监控job与task的完成情况,通过回调函数接收taskscheduler的通知,了解任务的开始、结束、失败等信息,以维护作业和调度阶段的状态信息。
2. 容错
如果某个executor失败,dagscheduler会根据rdd的依赖关系重新计算丢失的分区。spark通过rdd的lineage(血统)进行容错,确保数据的完整性和一致性。
六、优化策略
1. 内存计算
spark利用内存进行计算加速,通过存储rdd的分区在内存中来避免频繁的磁盘读写。这大大提高了数据处理的效率。
2. 智能shuffle机制
在涉及宽依赖的stage间,数据需经过shuffle过程重分布。spark使用了基于排序的shuffle机制,优化了数据处理的效率和内存使用。
3. 资源管理与调度
spark通过智能的资源管理与调度策略,如fifo调度策略等,确保任务的高效执行。同时,spark还优化了数据处理的本地性,优先安排task在数据所在的节点上执行,以减少网络传输和提高执行效率。
综上所述,spark调度底层执行原理是一个复杂而精细的过程,它通过高度优化的dag执行模型、内存计算、智能的shuffle机制和强大的资源管理与调度策略,实现了大数据处理的高效性和灵活性。

发表评论