kafka是一种高吞吐量的分布式发布订阅消息系统,本文介绍了如何使用kafka-go这个库实现go语言与kafka的交互。
go社区中目前有三个比较常用的kafka客户端库 , 它们各有特点。
首先是ibm/sarama(这个库已经由shopify转给了ibm),之前我写过一篇使用sarama操作kafka的教程,相较于sarama, kafka-go 更简单、更易用。
segmentio/kafka-go 是纯go实现,提供了与kafka交互的低级别和高级别两套api,同时也支持context。
此外社区中另一个比较常用的confluentinc/confluent-kafka-go,它是一个基于cgo的librdkafka包装,在项目中使用它会引入对c库的依赖。
准备kafka环境
这里推荐使用docker compose快速搭建一套本地开发环境。
以下docker-compose.yml文件用来搭建一套单节点zookeeper和单节点kafka环境,并且在8080端口提供kafka-ui管理界面。
version: '2.1'
services:
zoo1:
image: confluentinc/cp-zookeeper:7.3.2
hostname: zoo1
container_name: zoo1
ports:
- "2181:2181"
environment:
zookeeper_client_port: 2181
zookeeper_server_id: 1
zookeeper_servers: zoo1:2888:3888
kafka1:
image: confluentinc/cp-kafka:7.3.2
hostname: kafka1
container_name: kafka1
ports:
- "9092:9092"
- "29092:29092"
- "9999:9999"
environment:
kafka_advertised_listeners: internal://kafka1:19092,external://${docker_host_ip:-127.0.0.1}:9092,docker://host.docker.internal:29092
kafka_listener_security_protocol_map: internal:plaintext,external:plaintext,docker:plaintext
kafka_inter_broker_listener_name: internal
kafka_zookeeper_connect: "zoo1:2181"
kafka_broker_id: 1
kafka_log4j_loggers: "kafka.controller=info,kafka.producer.async.defaulteventhandler=info,state.change.logger=info"
kafka_offsets_topic_replication_factor: 1
kafka_transaction_state_log_replication_factor: 1
kafka_transaction_state_log_min_isr: 1
kafka_jmx_port: 9999
kafka_jmx_hostname: ${docker_host_ip:-127.0.0.1}
kafka_authorizer_class_name: kafka.security.authorizer.aclauthorizer
kafka_allow_everyone_if_no_acl_found: "true"
depends_on:
- zoo1
kafka-ui:
container_name: kafka-ui
image: provectuslabs/kafka-ui:latest
ports:
- 8080:8080
depends_on:
- kafka1
environment:
dynamic_config_enabled: "true"
将上述docker-compose.yml文件在本地保存,在同一目录下执行以下命令启动容器。
docker-compose up -d
容器启动后,使用浏览器打开127.0.0.1:8080 即可看到如下kafka-ui界面。
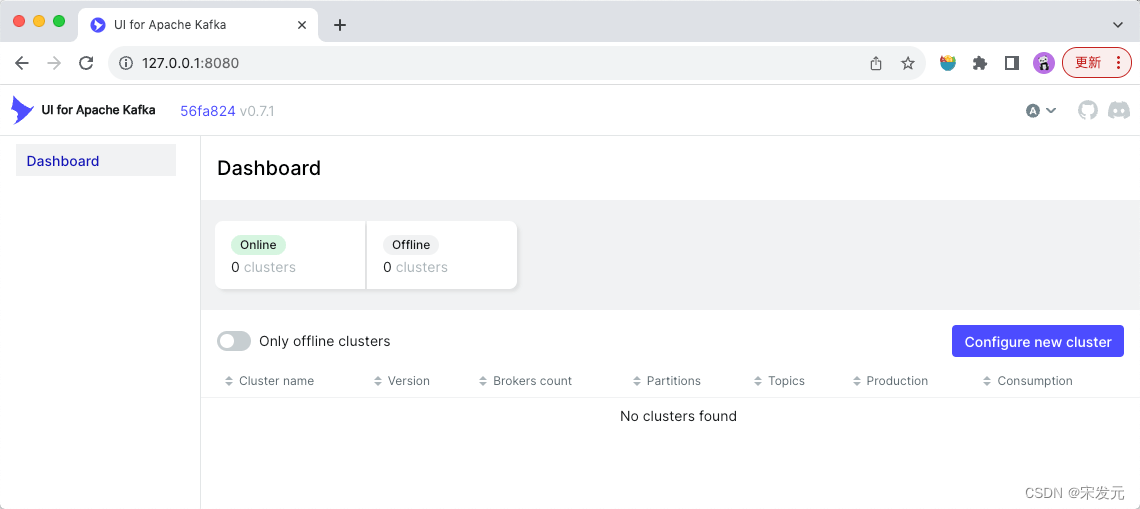
点击页面右侧的“configure new cluster”按钮,配置kafka服务连接信息。
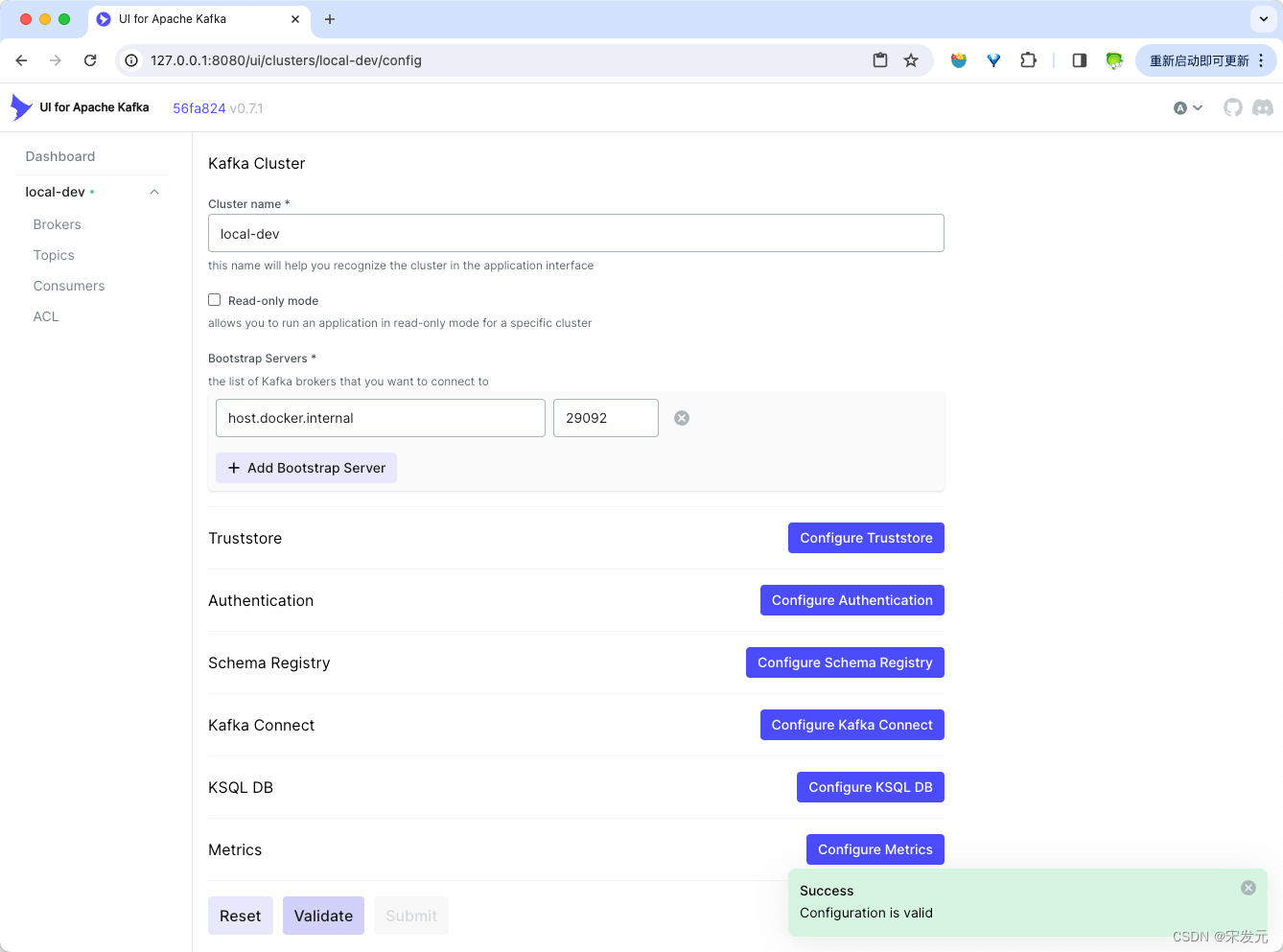
填写完信息后,点击页面下方的“submit”按钮提交即可。

安装kafka-go
执行以下命令下载 kafka-go依赖。
go get github.com/segmentio/kafka-go
kafka-go使用指南
kafka-go 提供了两套与kafka交互的api。
- 低级别( low-level):基于与 kafka 服务器的原始网络连接实现。
- 高级别(high-level):对于常用读写操作封装了一套更易用的api。
通常建议直接使用高级别的交互api。
connection
conn 类型是 kafka-go 包的核心。它代表与 kafka broker之间的连接。基于它实现了一套与kafka交互的低级别 api。
发送消息
下面是连接至kafka之后,使用conn发送消息的代码示例。
// writebyconn 基于conn发送消息
func writebyconn() {
topic := "my-topic"
partition := 0
// 连接至kafka集群的leader节点
conn, err := kafka.dialleader(context.background(), "tcp", "localhost:9092", topic, partition)
if err != nil {
log.fatal("failed to dial leader:", err)
}
// 设置发送消息的超时时间
conn.setwritedeadline(time.now().add(10 * time.second))
// 发送消息
_, err = conn.writemessages(
kafka.message{value: []byte("one!")},
kafka.message{value: []byte("two!")},
kafka.message{value: []byte("three!")},
)
if err != nil {
log.fatal("failed to write messages:", err)
}
// 关闭连接
if err := conn.close(); err != nil {
log.fatal("failed to close writer:", err)
}
}
消费消息
// readbyconn 连接至kafka后接收消息
func readbyconn() {
// 指定要连接的topic和partition
topic := "my-topic"
partition := 0
// 连接至kafka的leader节点
conn, err := kafka.dialleader(context.background(), "tcp", "localhost:9092", topic, partition)
if err != nil {
log.fatal("failed to dial leader:", err)
}
// 设置读取超时时间
conn.setreaddeadline(time.now().add(10 * time.second))
// 读取一批消息,得到的batch是一系列消息的迭代器
batch := conn.readbatch(10e3, 1e6) // fetch 10kb min, 1mb max
// 遍历读取消息
b := make([]byte, 10e3) // 10kb max per message
for {
n, err := batch.read(b)
if err != nil {
break
}
fmt.println(string(b[:n]))
}
// 关闭batch
if err := batch.close(); err != nil {
log.fatal("failed to close batch:", err)
}
// 关闭连接
if err := conn.close(); err != nil {
log.fatal("failed to close connection:", err)
}
}
使用batch.read更高效一些,但是需要根据消息长度选择合适的buffer(上述代码中的b),如果传入的buffer太小(消息装不下)就会返回io.errshortbuffer错误。
如果不考虑内存分配的效率问题,也可以按以下代码使用batch.readmessage读取消息。
for {
msg, err := batch.readmessage()
if err != nil {
break
}
fmt.println(string(msg.value))
}
创建topic
当kafka关闭自动创建topic的设置时,可按如下方式创建topic。
// createtopicbyconn 创建topic
func createtopicbyconn() {
// 指定要创建的topic名称
topic := "my-topic"
// 连接至任意kafka节点
conn, err := kafka.dial("tcp", "localhost:9092")
if err != nil {
panic(err.error())
}
defer conn.close()
// 获取当前控制节点信息
controller, err := conn.controller()
if err != nil {
panic(err.error())
}
var controllerconn *kafka.conn
// 连接至leader节点
controllerconn, err = kafka.dial("tcp", net.joinhostport(controller.host, strconv.itoa(controller.port)))
if err != nil {
panic(err.error())
}
defer controllerconn.close()
topicconfigs := []kafka.topicconfig{
{
topic: topic,
numpartitions: 1,
replicationfactor: 1,
},
}
// 创建topic
err = controllerconn.createtopics(topicconfigs...)
if err != nil {
panic(err.error())
}
}
通过非leader节点连接leader节点
下面的示例代码演示了如何通过已有的非leader节点的conn,连接至 leader节点。
conn, err := kafka.dial("tcp", "localhost:9092")
if err != nil {
panic(err.error())
}
defer conn.close()
// 获取当前控制节点信息
controller, err := conn.controller()
if err != nil {
panic(err.error())
}
var connleader *kafka.conn
connleader, err = kafka.dial("tcp", net.joinhostport(controller.host, strconv.itoa(controller.port)))
if err != nil {
panic(err.error())
}
defer connleader.close()
获取topic列表
conn, err := kafka.dial("tcp", "localhost:9092")
if err != nil {
panic(err.error())
}
defer conn.close()
partitions, err := conn.readpartitions()
if err != nil {
panic(err.error())
}
m := map[string]struct{}{}
// 遍历所有分区取topic
for _, p := range partitions {
m[p.topic] = struct{}{}
}
for k := range m {
fmt.println(k)
}
reader
reader是由 kafka-go 包提供的另一个概念,对于从单个主题-分区(topic-partition)消费消息这种典型场景,使用它能够简化代码。reader 还实现了自动重连和偏移量管理,并支持使用 context 支持异步取消和超时的 api。
注意: 当进程退出时,必须在 reader 上调用 close() 。kafka服务器需要一个优雅的断开连接来阻止它继续尝试向已连接的客户端发送消息。如果进程使用 sigint (shell 中的 ctrl-c)或 sigterm (如 docker stop 或 kubernetes start)终止,那么下面给出的示例不会调用 close()。当同一topic上有新reader连接时,可能导致延迟(例如,新进程启动或新容器运行)。在这种场景下应使用signal.notify处理程序在进程关闭时关闭reader。
消费消息
下面的代码演示了如何使用reader连接至kafka消费消息。
// readbyreader 通过reader接收消息
func readbyreader() {
// 创建reader
r := kafka.newreader(kafka.readerconfig{
brokers: []string{"localhost:9092", "localhost:9093", "localhost:9094"},
topic: "topic-a",
partition: 0,
maxbytes: 10e6, // 10mb
})
r.setoffset(42) // 设置offset
// 接收消息
for {
m, err := r.readmessage(context.background())
if err != nil {
break
}
fmt.printf("message at offset %d: %s = %s\n", m.offset, string(m.key), string(m.value))
}
// 程序退出前关闭reader
if err := r.close(); err != nil {
log.fatal("failed to close reader:", err)
}
}
消费者组
kafka-go支持消费者组,包括broker管理的offset。要启用消费者组,只需在 readerconfig 中指定 groupid。
使用消费者组时,readmessage 会自动提交偏移量。
// 创建一个reader,指定groupid,从 topic-a 消费消息
r := kafka.newreader(kafka.readerconfig{
brokers: []string{"localhost:9092", "localhost:9093", "localhost:9094"},
groupid: "consumer-group-id", // 指定消费者组id
topic: "topic-a",
maxbytes: 10e6, // 10mb
})
// 接收消息
for {
m, err := r.readmessage(context.background())
if err != nil {
break
}
fmt.printf("message at topic/partition/offset %v/%v/%v: %s = %s\n", m.topic, m.partition, m.offset, string(m.key), string(m.value))
}
// 程序退出前关闭reader
if err := r.close(); err != nil {
log.fatal("failed to close reader:", err)
}
在使用消费者组时会有以下限制:
显式提交
kafka-go 也支持显式提交。当需要显式提交时不要调用 readmessage,而是调用 fetchmessage获取消息,然后调用 commitmessages 显式提交。
ctx := context.background()
for {
// 获取消息
m, err := r.fetchmessage(ctx)
if err != nil {
break
}
// 处理消息
fmt.printf("message at topic/partition/offset %v/%v/%v: %s = %s\n", m.topic, m.partition, m.offset, string(m.key), string(m.value))
// 显式提交
if err := r.commitmessages(ctx, m); err != nil {
log.fatal("failed to commit messages:", err)
}
}
在消费者组中提交消息时,具有给定主题/分区的最大偏移量的消息确定该分区的提交偏移量的值。例如,如果通过调用 fetchmessage 获取了单个分区的偏移量为 1、2 和 3 的消息,则使用偏移量为3的消息调用 commitmessages 也将导致该分区的偏移量为 1 和 2 的消息被提交。
管理提交间隔
默认情况下,调用commitmessages将同步向kafka提交偏移量。为了提高性能,可以在readerconfig中设置commitinterval来定期向kafka提交偏移。
// 创建一个reader从 topic-a 消费消息
r := kafka.newreader(kafka.readerconfig{
brokers: []string{"localhost:9092", "localhost:9093", "localhost:9094"},
groupid: "consumer-group-id",
topic: "topic-a",
maxbytes: 10e6, // 10mb
commitinterval: time.second, // 每秒刷新一次提交给 kafka
})
writer
向kafka发送消息,除了使用基于conn的低级api,kafka-go包还提供了更高级别的 writer 类型。大多数情况下使用writer即可满足条件,它支持以下特性。
- 对错误进行自动重试和重新连接。
- 在可用分区之间可配置的消息分布。
- 向kafka同步或异步写入消息。
- 使用context的异步取消。
- 关闭时清除挂起的消息以支持正常关闭。
- 在发布消息之前自动创建不存在的topic。
发送消息
// 创建一个writer 向topic-a发送消息
w := &kafka.writer{
addr: kafka.tcp("localhost:9092", "localhost:9093", "localhost:9094"),
topic: "topic-a",
balancer: &kafka.leastbytes{}, // 指定分区的balancer模式为最小字节分布
requiredacks: kafka.requireall, // ack模式
async: true, // 异步
}
err := w.writemessages(context.background(),
kafka.message{
key: []byte("key-a"),
value: []byte("hello world!"),
},
kafka.message{
key: []byte("key-b"),
value: []byte("one!"),
},
kafka.message{
key: []byte("key-c"),
value: []byte("two!"),
},
)
if err != nil {
log.fatal("failed to write messages:", err)
}
if err := w.close(); err != nil {
log.fatal("failed to close writer:", err)
}
创建不存在的topic
如果给writer配置了allowautotopiccreation:true,那么当发送消息至某个不存在的topic时,则会自动创建topic。
// 创建不存在的topic
// 如果给writer配置了allowautotopiccreation:true,那么当发送消息至某个不存在的topic时,则会自动创建topic。
func writebywriter2() {
writer := kafka.writer{
addr: kafka.tcp("192.168.2.204:9092"),
topic: "kafka-test-topic",
allowautotopiccreation: true, //自动创建topic
}
messages := []kafka.message{
{
key: []byte("key-a"),
value: []byte("hello world!"),
},
{
key: []byte("key-b"),
value: []byte("one!"),
},
{
key: []byte("key-c"),
value: []byte("tow!"),
},
}
const retries = 3
//重试3次
for i := 0; i < retries; i++ {
ctx, cancel := context.withtimeout(context.background(), 10*time.second)
defer cancel()
err := writer.writemessages(ctx, messages...)
if errors.is(err, kafka.leadernotavailable) || errors.is(err, context.deadlineexceeded) {
time.sleep(time.millisecond * 250)
continue
}
if err != nil {
log.fatal("unexpected error %v", err)
}
break
}
//关闭writer
if err := writer.close(); err != nil {
log.fatal("failed to close writer:", err)
}
}
写入多个topic
通常,writerconfig.topic用于初始化单个topic的writer。通过去掉writerconfig中的topic配置,分别设置每条消息的message.topic,可以实现将消息发送至多个topic。
w := &kafka.writer{
addr: kafka.tcp("localhost:9092", "localhost:9093", "localhost:9094"),
// 注意: 当此处不设置topic时,后续的每条消息都需要指定topic
balancer: &kafka.leastbytes{},
}
err := w.writemessages(context.background(),
// 注意: 每条消息都需要指定一个 topic, 否则就会报错
kafka.message{
topic: "topic-a",
key: []byte("key-a"),
value: []byte("hello world!"),
},
kafka.message{
topic: "topic-b",
key: []byte("key-b"),
value: []byte("one!"),
},
kafka.message{
topic: "topic-c",
key: []byte("key-c"),
value: []byte("two!"),
},
)
if err != nil {
log.fatal("failed to write messages:", err)
}
if err := w.close(); err != nil {
log.fatal("failed to close writer:", err)
}
注意:writer中的topic和message中的topic是互斥的,同一时刻有且只能设置一处。
其他配置
tls
对于基本的 conn 类型或在 reader/writer 配置中,可以在dialer中设置tls选项。如果 tls 字段为空,则它将不启用tls 连接。
注意:不在conn/reder/writer上配置tls,连接到启用tls的kafka集群,可能会出现io.errunexpectedeof错误。
connection
dialer := &kafka.dialer{
timeout: 10 * time.second,
dualstack: true,
tls: &tls.config{...tls config...}, // 指定tls配置
}
conn, err := dialer.dialcontext(ctx, "tcp", "localhost:9093")
reader
dialer := &kafka.dialer{
timeout: 10 * time.second,
dualstack: true,
tls: &tls.config{...tls config...}, // 指定tls配置
}
r := kafka.newreader(kafka.readerconfig{
brokers: []string{"localhost:9092", "localhost:9093", "localhost:9094"},
groupid: "consumer-group-id",
topic: "topic-a",
dialer: dialer,
})
writer
创建writer时可以按如下方式指定tls配置。
w := kafka.writer{
addr: kafka.tcp("localhost:9092", "localhost:9093", "localhost:9094"),
topic: "topic-a",
balancer: &kafka.hash{},
transport: &kafka.transport{
tls: &tls.config{}, // 指定tls配置
},
}

发表评论