论文题目:distpred: a distribution-free probabilistic inference method for regression and forecasting
论文作者:daojun liang, haixia zhang,dongfeng yuan
论文地址:https://arxiv.org/abs/2406.11397
代码地址:https://github.com/anoise/distpred
论文在线版本 — 论文地址 — github代码地址
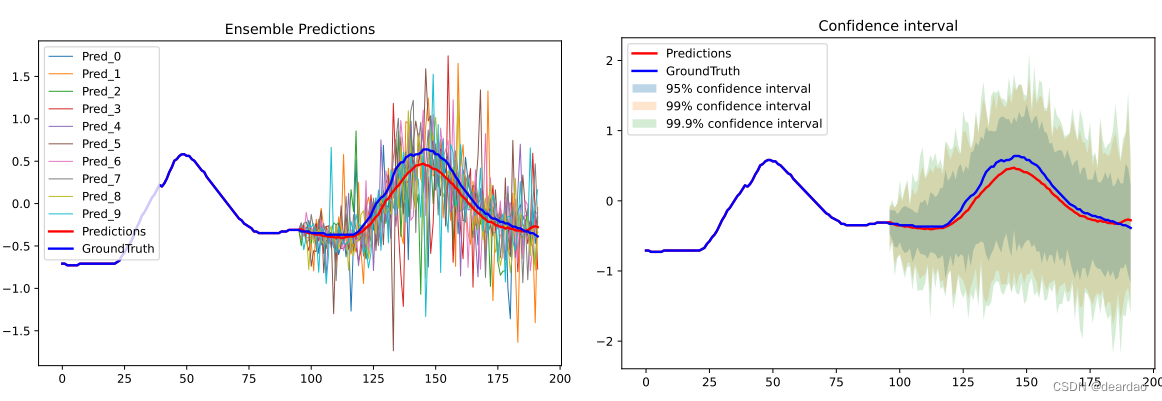
图 0:distpred可在一次前向过程中给出n个预测,根据这n个预测可求得该点的分布。
摘要
传统的回归和预测任务通常只提供确定性的点估计。为了估计响应变量的不确定性或分布信息,通常使用贝叶斯推理、模型集成或mc dropout等方法。这些方法要么假设样本的后验分布遵循高斯过程,要么需要数千次前向传递来生成样本。我们提出了一种新的方法,称为distpred,用于回归和预测任务,它克服了现有方法的局限性,同时保持简单和强大。具体来说,我们将测量预测分布与目标分布之间差异的适当评分规则转换为可微离散形式,并将其用作损失函数来端到端训练模型。这允许模型在单个前向传递中采样大量样本,以估计响应变量的潜在分布。我们已经将我们的方法与多个数据集上的几种现有方法进行了比较,并获得了最先进的性能。此外,我们的方法显著提高了计算效率。例如,与最先进的模型相比,distpred的推理速度快了90x倍,训练速度提升230x倍(考虑数据处理与指标计算等步骤)。实验结果可以通过这个github库复现。
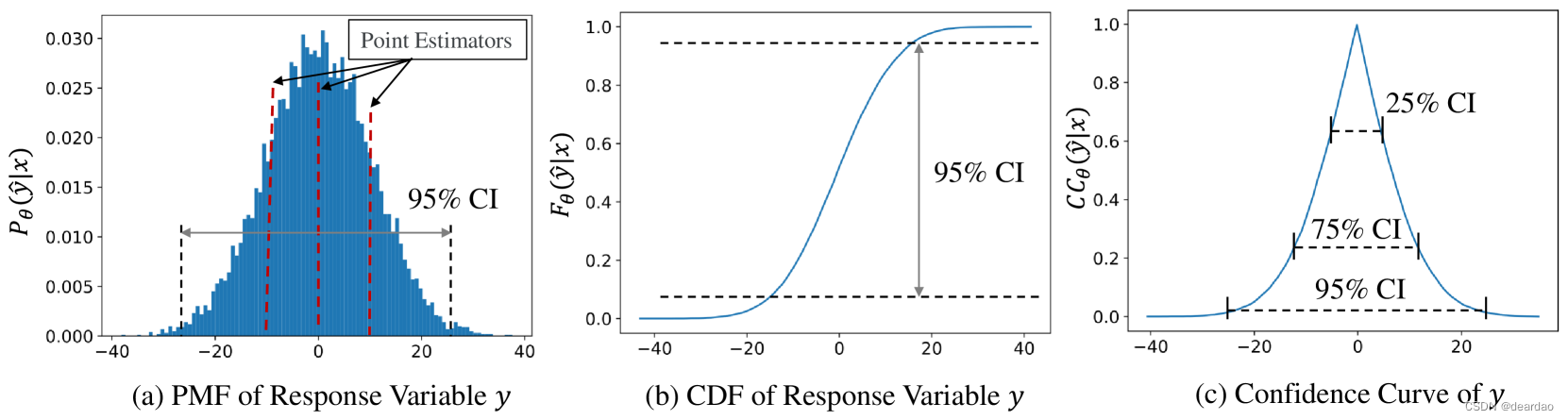
图1:distpred可以在单个前向过程中给出预测变量的变量,给出响应变量的变量的
k
k
k预测值,表示为
y
^
\hat{y}
y^,其中
y
^
\hat{y}
y^表示的是一个最大似然样本。基于这个抽样,可以计算响应变量
y
y
y的质量分布的概率(pmd)
p
θ
(
y
^
∣
x
)
p_{\theta}(\hat{y}|x)
pθ(y^∣x),累积分布函数(pdf)
f
θ
(
y
^
∣
x
)
f_{\theta}(\hat{y}|x)
fθ(y^∣x),和信心曲线
c
c
θ
(
y
^
∣
x
)
cc_{\theta}(\hat{y}|x)
ccθ(y^∣x),从而产生
y
y
y全面统计量。例如,这包括任何期望水平上的置信区间(ci)以及p-value。
1 简介
在本文中,我们考虑了预测响应变量背后的潜在分布,因为它反映了所有水平的置信区间。例如,基于这个分布,我们可以计算任何级别的置信区间、覆盖率和不确定性量化。目前,预测响应变量的分布是一个挑战,因为在特定时刻,响应变量只能采取单一的确定性值。这个点可以看作是其潜在分布的最大似然样本,但它不能反映潜在分布的整体状态。
目前,在回归和预测任务中,用于解决分布预测和不确定性量化的主要方法是频率采样。这些方法包括通过干扰解释变量或模型来采样大量样本,以近似响应变量的潜在分布。例如,贝叶斯神经网络(bnn)通过假设其参数遵循高斯分布来模拟这种不确定性,从而捕获给定数据的模型的不确定性(blundell et al., 2015)。同样,基于集成的方法也被提出,将多个具有随机输出的深度模型结合起来,以捕获预测的不确定性。mc dropout (gal和ghahramani, 2016)表明,在每个测试过程中启用dropout会产生类似于模型集成的结果。此外,还引入了基于gan和扩散的条件密度估计和预测不确定性量化模型。这些模型利用产生或扩散过程中的噪声来获得不同的预测值,以估计响应变量的不确定性。
上述这些方法的共同特点是要求𝐾前向通过采样 k k k代表性样本。例如,基于贝叶斯框架的方法需要推断 k k k可学习的参数样本,以获得 k k k代表性样本;集成方法需要 k k k模型共同推断;mc dropout需要 k k k向前通过随机dropout激活;生成模型需要 k k k正向或扩散过程。然而,过多的向前传递会导致显著的计算开销和较慢的速度,对于具有高实时性要求的ai应用程序来说,这一缺点变得越来越明显。
为了解决这个问题,我们提出了一种新的方法,称为distpred,它是一种用于回归和预测任务的无分布概率推理方法。distpred是一种简单而强大的方法,可以估计单次正向传递中响应变量的分布。具体来说,我们考虑使用所有预测分位数来指定预测变量的潜在累积密度函数(cdf),并且我们表明,整个分位数的预测可以转化为计算响应变量和预测集合变量的最小期望值。在此基础上,我们将测量预测分布与目标分布之间差异的适当评分规则转换为可微离散形式,并将其用作损失函数来端到端训练模型。这允许模型在单个前向传递中采样大量样本,以估计响应变量的潜在分布。distpred与其他方法是正交的,这使得它可以与其他方法相结合来增强估计性能。此外,我们还展示了distpred可以提供对响应变量的全面统计见解,包括任何期望水平上的置信区间、p值和其他统计信息,如图1所示。实验结果表明,distpred在精度和计算效率方面都优于现有方法。具体来说,distpred的推理速度比最先进的模型快90倍,训练速度提升230x倍(考虑数据处理与指标计算等步骤)。
2 方法
假设数据集
d
=
{
x
i
,
y
i
}
i
=
1
n
d=\{x_i,y_i\}_{i=1}^n
d={xi,yi}i=1n由
n
n
n样本标签对组成。如果下标
i
i
i不会在上下文中引起歧义,则将被省略。我们的目标是利用具有参数
θ
\theta
θ的机器学习模型
m
m
m来预测响应变量
y
y
y从
d
d
d的潜在分布
p
(
y
)
p(y)
p(y),旨在获得全面的统计见解,例如获得置信区间(ci)和在任何期望水平上量化不确定性。
直接预测分布
p
p
p是不可行的,因为:
- 如果没有分布假设,我们就不能给出预测分布 p θ ( y ^ ) p_\theta(\hat{y}) pθ(y^)的pdf或cdf的有效表示。
- 对于响应变量 y y y,我们只能得到一个奇异的确定性值,无法获得其分布信息来指导模型学习。
为了解决上述问题,我们考虑采用所有预测分位数 q ^ 1 , q ^ 2 , ⋯ \hat{q}_1, \hat{q}_2, \cdots q^1,q^2,⋯,在水平 α 1 , α 2 , ⋯ \alpha_1, \alpha_2, \cdots α1,α2,⋯上指定预测变量 y ^ \hat{y} y^的潜在cdf f θ ( y ^ ) f_\theta(\hat{y}) fθ(y^)。这是因为如果我们知道随机变量的累积分布函数,我们可以通过设置 f ( y ) = q f(y) = q f(y)=q找到任何分位数。相反,如果我们有一个完整的分位数集,我们可以近似或重建随机变量的累积分布函数。如图2所示,分位数提供了分布的离散“快照”,而cdf是这些快照的连续、平滑版本,提供了从最小值到最大值的累积概率的完整描述。
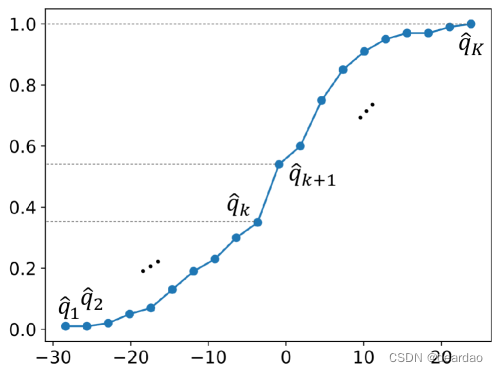
图2:cdf与所有预测分位数之间的关系。
接下来,我们将介绍前面概述的完整预测分位数作为响应变量cdf的适当近似值。全分位数预测可转化为计算响应变量和预测集合变量 y ^ \hat{y} y^的最小期望值,其中 y ^ = { y ^ 1 , ⋯ , y ^ k } \hat{y} = \{\hat{y} _1, \cdots, \hat{y} _k \} y^={y^1,⋯,y^k}。在深入研究此分析之前,我们将首先介绍用于评估预测分布的适当性的评分规则。
2.1 使用适当的评分规则作为损失函数
评分规则通过根据预测分布和预测结果分配数值分数,为评估概率预测提供了一个简明的度量\citep{gneiting2007strictly, jordan2017evaluating}。具体地说,设
ω
\omega
ω表示感兴趣的数量的可能值的集合,设
p
\mathcal{p}
p表示
ω
\omega
ω上概率分布的凸类。评分规则是一个函数
s
:
ω
×
p
→
r
∪
{
∞
}
(
1
)
s: \omega \times \mathcal{p} \rightarrow \mathbb{r} \cup \{\infty\} \quad \quad (1)
s:ω×p→r∪{∞}(1)
它将数值赋给预测
p
∈
p
p \in \mathcal{p}
p∈p和观测
y
∈
ω
y \in \omega
y∈ω。我们用相关的cdf
f
f
f或pdf
f
f
f来识别概率预测
p
p
p,并认为评分规则是负向的,分数越低表示预测越准确。当预测与观测的真实分布一致时,则优化了适当的评分规则,即,如果,
e
y
∼
q
[
s
(
q
,
y
)
]
≤
e
y
∼
q
[
s
(
p
,
y
)
]
(
2
)
e_{y \sim q} [s(q, y)] \leq e_{y \sim q} [s(p, y)] \quad \quad (2)
ey∼q[s(q,y)]≤ey∼q[s(p,y)](2)
对于所有
p
,
q
∈
p
p, q \in \mathcal{p}
p,q∈p。当只有在
p
=
q
p = q
p=q时才达到相等时,评分规则被称为严格正确的。适当的评分规则(psr)对于比较评价至关重要,特别是在排名预测中。在实践中,在多个预测案例中平均得分最低的预测者通常表现出最好的预测性能。适当的评分规则激励预测者准确地报告他们对这种情况下真实分布的看法。因此,psr提供了有吸引力的损失和效用函数,可以针对回归或预测问题进行调整。为了估计
θ
\theta
θ,我们可以用均值来衡量拟合优度
s
n
(
θ
)
=
1
n
∑
i
=
1
n
s
(
p
θ
(
y
^
i
)
,
y
i
)
.
(
3
)
s_n(\theta) = \frac{1}{n} \sum_{i=1}^n s(p_{\theta}(\hat{y}_i), y_i). \quad \quad (3)
sn(θ)=n1i=1∑ns(pθ(y^i),yi).(3)
设
θ
∗
\theta^*
θ∗为真参数值,则渐近参数表明
argmin
θ
s
n
(
θ
)
→
θ
∗
\text{argmin}_\theta s_n(\theta) \rightarrow \theta^*
argminθsn(θ)→θ∗为
n
→
∞
n\rightarrow \infty
n→∞。这提出了一种将psr转换为训练模型损失函数的一般方法,该方法隐含地最小化了预测分布和真实分布之间的差异。

图3:distpred的工作流程。在前向传递中推断预测变量
y
^
\hat{y}
y^的集合,并使用psr
s
(
e
(
y
^
∣
x
)
,
y
)
s(\mathbb{e}(\hat{y}|x), y)
s(e(y^∣x),y)对学习器进行端到端训练。
2.2 全预测分位数的性质
我们考虑与连续量有关的概率预测,表现为完整的预测分位数
q
^
1
,
⋯
,
q
^
k
\hat{q}_1, \cdots, \hat{q}_k
q^1,⋯,q^k。对于
p
∈
p
p\in \mathcal{p}
p∈p,让
q
1
,
⋯
,
q
k
q_1, \cdots, q_k
q1,⋯,qk表示级别
α
1
,
⋯
,
α
k
∈
(
0
,
1
)
\alpha_1, \cdots, \alpha_k \in (0,1)
α1,⋯,αk∈(0,1)上的真实
p
p
p -分位数。则可将期望分数
s
(
q
1
,
⋯
,
q
k
;
p
)
s(q_1, \cdots, q_k; p)
s(q1,⋯,qk;p)定义为
s
(
q
^
1
,
⋯
,
q
^
k
;
p
)
=
∫
s
(
q
^
1
,
⋯
,
q
^
k
;
y
)
d
p
(
y
)
.
(
4
)
s(\hat{q}_1, \cdots, \hat{q}_k; p) = \int s(\hat{q}_1, \cdots, \hat{q}_k; y) \,\text{d}p(y). \quad \quad (4)
s(q^1,⋯,q^k;p)=∫s(q^1,⋯,q^k;y)dp(y).(4)
此外,评分规则s是适当的,如果
s
(
q
1
,
⋯
,
q
k
;
p
)
≥
s
(
q
^
1
,
⋯
,
q
^
k
;
p
)
s(q_1, \cdots, q_k; p) \ge s( \hat{q}_1, \cdots, \hat{q}_k; p)
s(q1,⋯,qk;p)≥s(q^1,⋯,q^k;p)。基于这个定义,我们假设
s
k
,
i
∈
[
1
,
⋯
k
]
s_k, i \in [1,\cdots k]
sk,i∈[1,⋯k] 是非递减的,
h
h
h是任意的,那么得分规则
s
(
q
^
1
,
⋯
,
q
^
k
;
p
)
=
∑
k
=
1
k
(
α
i
s
k
(
q
^
k
)
+
(
s
k
(
y
)
−
s
k
(
q
k
^
)
1
{
y
≤
q
^
k
}
)
)
(
5
)
s( \hat{q}_1, \cdots, \hat{q}_k; p) = \sum_{k=1}^k \left( \alpha_i s_k(\hat{q}_k) + (s_k(y) - s_k(\hat{q_k})\mathbb{1}\{y\le \hat{q}_k\} ) \right) \quad \quad (5)
s(q^1,⋯,q^k;p)=k=1∑k(αisk(q^k)+(sk(y)−sk(qk^)1{y≤q^k}))(5)
是适当的预测分位数水平
α
1
,
⋯
,
α
k
\alpha_1, \cdots, \alpha_k
α1,⋯,αk当
k
→
∞
k \rightarrow \infty
k→∞。
1
{
y
≤
q
^
k
}
\mathbb{1}\{y\le \hat{q}_k\}
1{y≤q^k}表示指示函数,如果
y
≤
q
^
k
y \le \hat{q}_k
y≤q^k为1,否则为0。
等式5表明,完整的预测分位数是合适的。本质上,描述预测cdf等同于指定所有预测分位数。因此,我们可以根据分位数的评分规则来制定预测分布的评分规则。具体来说,让
s
α
s_\alpha
sα表示级别
α
\alpha
α的分位数的适当评分规则,然后是评分规则
s
(
f
,
y
)
=
∫
0
1
s
α
(
f
−
1
(
α
)
;
y
)
d
α
=
∫
−
∞
∞
s
(
f
(
y
^
)
,
1
{
y
≤
y
^
}
)
d
y
^
(
6
)
s(f,y) = \int_0^1 s_\alpha(f^{-1}(\alpha); y) \,\text{d}\alpha = \int_{-\infty}^{\infty} s(f(\hat{y}), \mathbb{1}\{y \le \hat{y} \}) \,\text{d}\hat{y} \quad \quad (6)
s(f,y)=∫01sα(f−1(α);y)dα=∫−∞∞s(f(y^),1{y≤y^})dy^(6)
是恰当的。在这里,我们可以发现,方程6的右侧对应于
s
s
s为二次或brier分数的crps,定义为
c
(
f
,
y
)
=
∫
−
∞
∞
(
f
(
y
^
)
−
1
{
y
≤
y
^
}
)
2
d
y
^
.
(
7
)
c(f, y) = \int_{-\infty}^{\infty} (f(\hat{y}) - \mathbb{1}\{y \le \hat{y} \})^2 \,\text{d}\hat{y}. \quad \quad (7)
c(f,y)=∫−∞∞(f(y^)−1{y≤y^})2dy^.(7)
如果
f
f
f的第一阶矩是有限的,则crps可以写成
c
(
f
,
y
)
=
e
f
[
∣
y
^
−
y
∣
]
−
1
2
e
f
f
[
∣
y
^
−
y
^
′
∣
]
,
(
8
)
c(f, y) = \mathbb{e}_f[|\hat{y} - y|] - \frac{1}{2} \mathbb{e}_{ff}[|\hat{y} - \hat{y}'|], \quad \quad (8)
c(f,y)=ef[∣y^−y∣]−21eff[∣y^−y^′∣],(8)
其中
y
^
\hat{y}
y^和
y
^
′
\hat{y}'
y^′表示具有分布
f
f
f的独立预测变量。
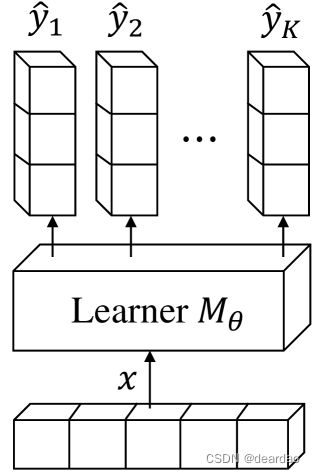
图4: distpred的架构。
2.3 端到端集成推理
根据上面提供的分析,很明显,预测完整的分位数相当于最小化方程8 w.r.t
e
(
y
^
∣
y
)
\mathbb{e}(\hat{y}|y)
e(y^∣y)。因此,正如图3所示的工作流,我们可以开发一个带有参数
θ
\theta
θ的模型
m
m
m,该模型在向前传递中推断预测变量
y
^
\hat{y}
y^的集合,并利用方程8对其进行端到端训练。这允许模型在单个前向传递中采样大量样本,以通过预测集合变量估计经验cdf
f
^
\hat{f}
f^
c
(
f
^
,
y
)
=
1
k
∑
k
=
1
k
∣
y
^
k
−
y
∣
−
1
2
k
2
∑
k
=
1
k
∑
j
=
1
k
∣
y
^
k
−
y
^
j
′
∣
.
(
9
)
c(\hat{f},y) = \frac{1}{k}\sum_{k=1}^{k}|\hat{y}_k - y| - \frac{1}{2k^2}\sum_{k=1}^{k}\sum_{j=1}^{k}|\hat{y}_k - \hat{y}'_{j}|. \quad \quad (9)
c(f^,y)=k1k=1∑k∣y^k−y∣−2k21k=1∑kj=1∑k∣y^k−y^j′∣.(9)
值得注意的是,方程9是严格满足psr的可微离散形式w.r.t
y
^
\hat{y}
y^和
y
′
^
\hat{y'}
y′^。然而,方程9的实现由于其计算复杂性
o
(
k
2
)
o(k^2)
o(k2)而表现出低效率。这可以通过使用基于广义分位数函数\citep{laio2007verification}和排序的预测集成变量的表示来增强
c
(
f
^
,
y
)
=
1
2
k
2
∑
k
=
1
k
(
y
k
→
−
y
)
(
k
1
{
y
≤
y
k
→
}
−
i
+
1
2
)
.
(
9
)
c(\hat{f},y) = \frac{1}{2k^2}\sum_{k=1}^{k}(\overrightarrow{y_k} - y)(k \mathbb{1}\{y \le \overrightarrow{y_k} \} -i + \frac{1}{2}). \quad \quad (9)
c(f^,y)=2k21k=1∑k(yk−y)(k1{y≤yk}−i+21).(9)
由于涉及排序操作,公式10的计算复杂度为
o
(
k
l
o
g
k
)
o(klogk)
o(klogk)。为了节省内存,我们还建议使用公式10作为损失函数,因为在长期预测任务中预测集成变量可能会导致gpu内存不足的问题。
2.4 结合其他方法
distpred与其他方法是正交的,这使得它可以与其他方法相结合来增强估计性能。在这里,考虑到计算效率和内存保护,我们选择将mc dropout与distpred集成,从而将合并表示为distpred-mcd。在我们的实验中,我们观察到distpred-mcd可以进一步提高不确定性量化性能,尽管计算工作量略有增加。
3 实验
在本文中,我们的重点集中在回归(由hernández-lobato和adams(2015)提出)和预测(由zhou等人(2021a)提出)任务上,我们验证了所提出的distpred方法在这些具体工作中的应用。
3.1 picp和qice指标
这两个指标都旨在经验地评估学习条件分布与真实条件分布之间的相似程度:
- picp(预测区间覆盖概率)(yao等人,2019)是衡量落在预测区间内的真实标签比例的度量。
- qice (分位数间隔校准误差)(han2022card)是一个度量,用于测量给定水平上预测分位数与真实分位数之间的平均差异
α
\alpha
α。
picp计算为:
p i c p : = 1 n ∑ n = 1 n 1 { y ^ n ≥ q α / 2 } ⋅ 1 { y ^ n ≤ q 1 − α / 2 } , ( 11 ) picp := \frac{1}{n} \sum_{n=1}^{n} \mathbb{1}\{\hat{y}_n \ge q_{\alpha/2} \} \cdot \mathbb{1}\{\hat{y}_n \le q_{1-\alpha/2} \}, \quad \quad (11) picp:=n1n=1∑n1{y^n≥qα/2}⋅1{y^n≤q1−α/2},(11)
其中 q α / 2 q_{\alpha/2} qα/2和 q 1 − α / 2 q_{1-\alpha/2} q1−α/2分别表示在相同的 x x x输入下,我们为预测的 y ^ \hat{y} y^输出选择的低百分位数和高百分位数。该指标评估与每个 x x x输入相对应的生成的 y ^ \hat{y} y^样本的百分位数范围内的准确观测值的比例。
q i c e : = 1 m ∑ m = 1 m ∣ r m − 1 m ∣ , ( 12 ) where r m = 1 n ∑ n = 1 n 1 { y ^ n ≥ q α / 2 } ⋅ 1 { y ^ n ≤ q 1 − α / 2 } . qice := \frac{1}{m}\sum_{m=1}^{m} | r_m - \frac{1}{m} |, \quad \quad (12) \\ \quad \text{where} \ \ r_m = \frac{1}{n} \sum_{n=1}^{n} \mathbb{1}\{\hat{y}_n \ge q_{\alpha/2} \} \cdot \mathbb{1}\{\hat{y}_n \le q_{1-\alpha/2} \}. qice:=m1m=1∑m∣rm−m1∣,(12)where rm=n1n=1∑n1{y^n≥qα/2}⋅1{y^n≤q1−α/2}.
3.2 toy 案例
为了证明distpred的有效性,我们首先在 8 8 8玩具示例上进行实验,如card 中所做的那样。这些例子在其数据生成函数中具有独特的统计特征:一些具有单模态对称分布的误差项(线性回归,二次回归,正弦回归),其他具有异方差(对数-对数线性回归,对数-对数三次回归)或多模态(反正弦回归,8高斯,全圆)。
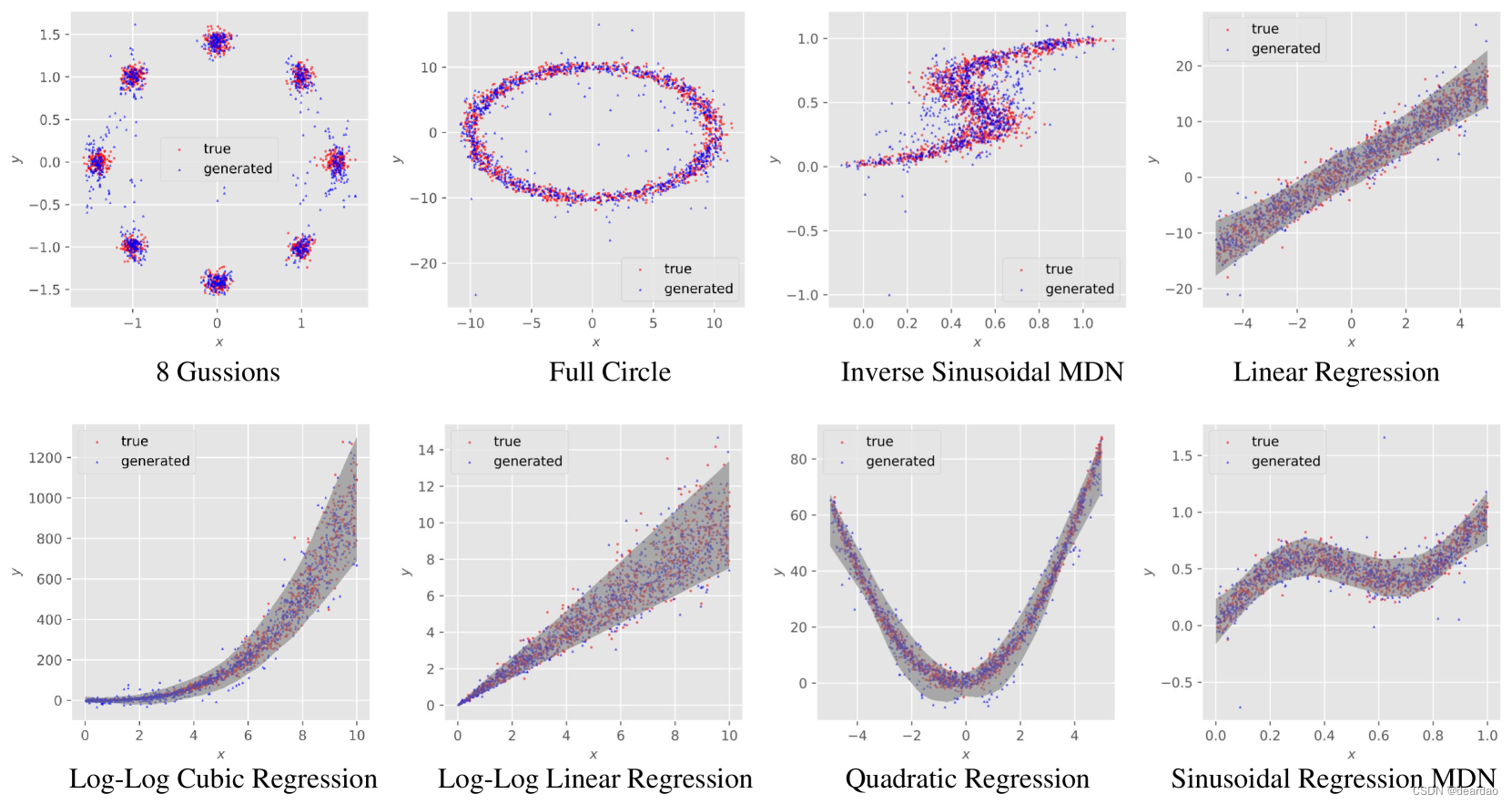
图5:distpred的回归结果,在8个toy数据集上的例子。
实验表明,经过训练的distpred模型具有产生与新协变量的真实响应变量非常相似的样本的能力。此外,它可以根据一定的汇总统计量定量地匹配真实分布。该研究将所有8个任务的真实数据和生成数据的散点图可视化,见图5。在任务涉及单峰条件分布的情况下,兴趣区域填充生成的 y ^ \hat{y} y^值的2.5-th和97.5-th百分位数之间的区域。
我们注意到,在每个任务中,生成的样本与真实的测试实例无缝集成,表明distpred重构固有数据生成过程的潜力。该实验直观地表明,distpred有效地重构了目标响应变量的样本电位分布。这表明distpred的优势可以在分布预测中得到充分利用。
3.3 uci回归任务
对于在真实世界数据集上进行的实验,我们使用相同的10个uci回归基准数据集(asuncion和newman, 2007),并遵循hernández-lobato和adams(2015)引入的实验协议,gal和ghahramani(2016)和lakshminarayanan等人(2017)以及han等人(2022)也遵循了该协议。数据集信息可在附录b的表5中找到。
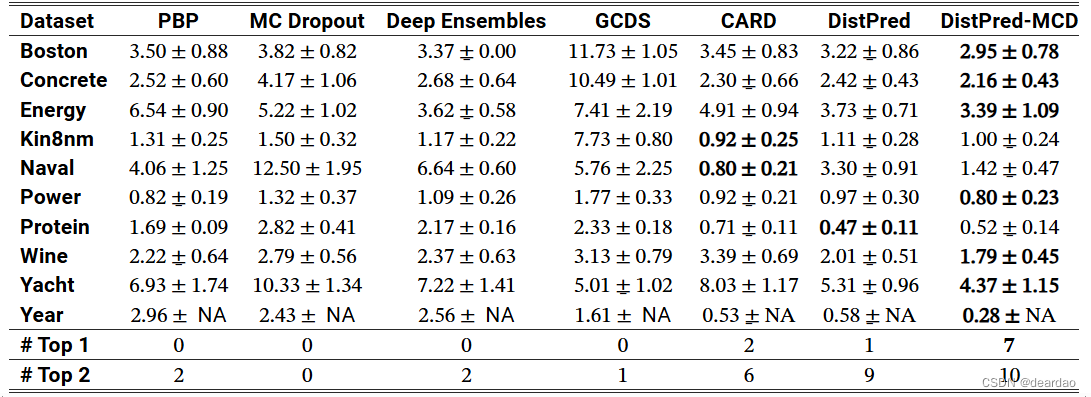
表1:uci回归任务的qice
↓
\downarrow
↓ (
%
\%
%)。
结果表明,distpred方法优于现有的方法,通常有相当大的差距。值得注意的是,这些令人印象深刻的结果是在distpred方法的一次向前传递中实现的。至关重要的是,利用distpred- mcd(一种结合distpred和mc dropout的混合方法)可以进一步提高不确定量化的性能。

表2:uci波士顿数据集上模型训练和推理时间(分钟)的比较。
很明显,与最先进的模型card相比,distpred在训练方面快了大约230倍,在推理方面快了大约90倍。distpred的推理速度比训练速度慢,因为它涉及到计算分布统计指标,如qice和picp。
3.4 烧蚀研究的样品和集合的数量
我们研究了由distpred生成的样本数量以及distpred-mcd的集合数量对它们各自性能的影响。如图6所示,随着输出样本和集合数量的增加,模型的性能逐渐提高,最终达到饱和点。
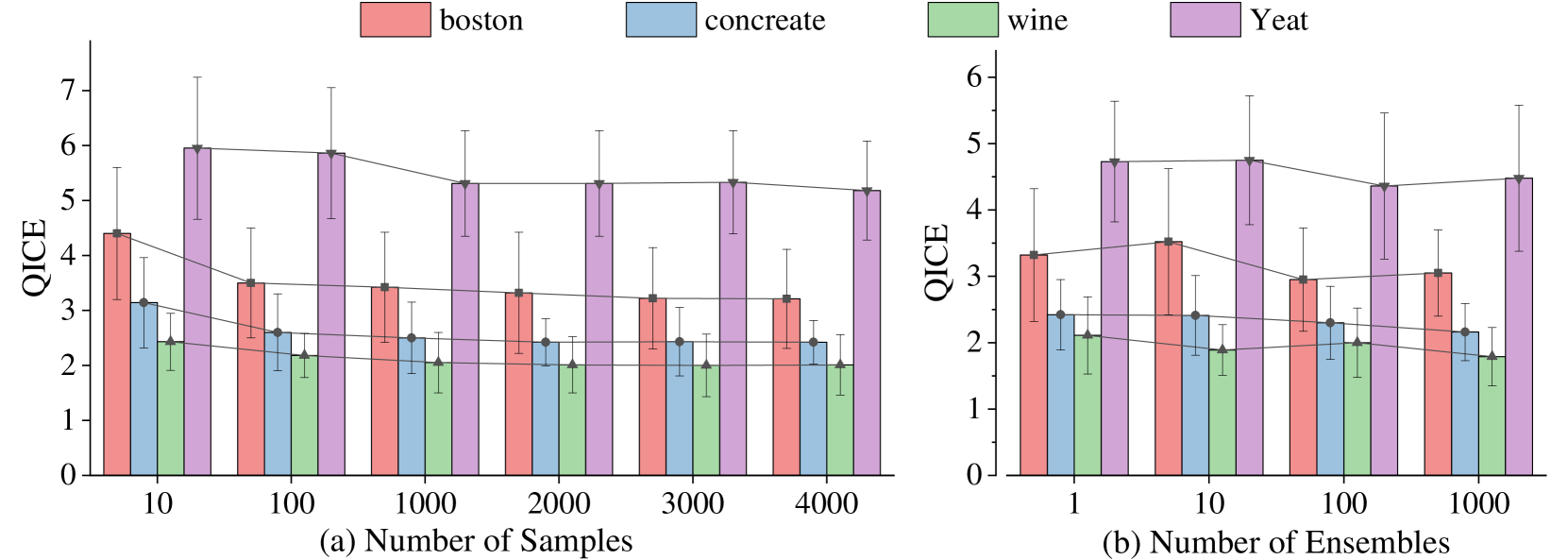
图6: distpred中样品数量(a)和distpred- mcd中集合数量(b)的消融研究。
3.5 时间序列分布预测
我们扩展了时间序列预测(zhou et al., 2021a;wu et al., 2021;zhou et al., 2022;liu et al., 2023)从点估计到分布预测的任务,以推断出关于某个时刻的更多统计信息。
有关数据集的详细信息可以在附录中找到。在实验中使用的模型在广泛的预测长度范围内进行评估,以比较不同未来视界的表现:96、192、336和720。多变量和单变量任务的实验设置是相同的。我们使用mse和mae的平均值(
m
s
e
+
m
a
e
2
\frac{mse+mae}{2}
2mse+mae)来评估模型的整体性能。值得注意的是,distpred提供了响应变量的集合
y
^
\hat{y}
y^。因此,我们采用
y
^
\hat{y}
y^的平均值作为该时刻的点估计。
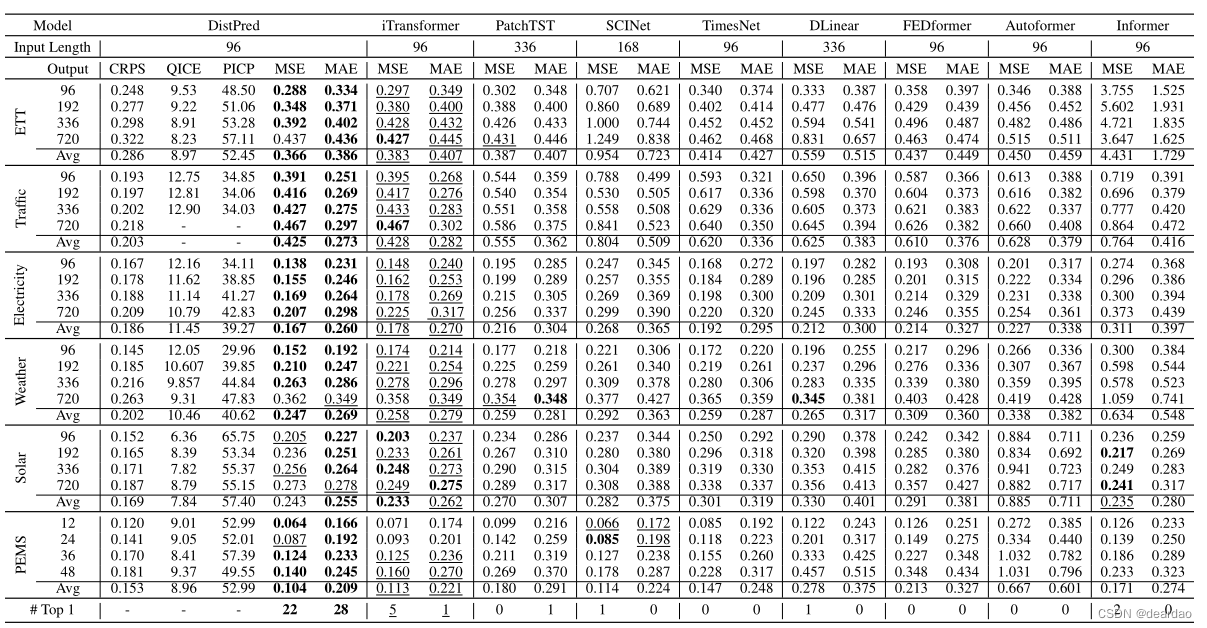
表3: 6个基准数据集的多元时间序列预测结果。
表3列出了多变量ts预测的结果,最优结果用粗体突出显示,次优结果用下划线强调。可以发现,尽管没有使用mse和mae, distpred在所有数据集和预测长度配置上都达到了最先进的性能。itransformer和patchtst以其卓越的平均性能脱颖而出,成为公认的最新型号。与它们相比,所提出的distpred的平均性能分别提高了3.5%和16.5%,实现了实质性的性能提升。我们提供的指标,如crps, qice, picp,供未来的研究界比较。
4 结论
本文提出了一种新的方法,称为distpred,它是一种用于回归和预测任务的无分布概率推理方法。我们将测量预测分布与目标分布之间差异的适当评分规则转换为可微离散形式,并将其用作损失函数来端到端训练模型。这允许模型在单个前向传递中采样大量样本,以估计响应变量的潜在分布。我们还提出了一种称为distpred-mcd的混合方法,该方法将distpred与mc dropout相结合,进一步提高了不确定量化的性能。实验结果表明,distpred优于现有的方法,通常有相当大的差距。我们还将时间序列预测从点估计扩展到分布预测,并在多变量和单变量时间序列预测任务上取得了最先进的性能。在未来,我们计划将distpred扩展到其他任务,如分类和强化学习。
[1] liang d, zhang h, yuan d, et al. distpred: a distribution-free probabilistic inference method for regression and forecasting[j]. arxiv preprint arxiv:2406.11397, 2024.
关注微信公众号,获取更多资讯内容:


发表评论