文章目录
0. 代码数据下载
关注公众号:『ai学习星球』
回复:小红书消费情况分析 即可获取数据下载。
算法学习、4对1辅导、论文辅导或核心期刊可以通过公众号或➕v:codebiubiubiu滴滴我

1. 项目介绍
本文包括以下几个部分:
- 数据来源及说明
- 分析思路
- 数据清洗
- 数据分析
- 结论
2. 数据说明
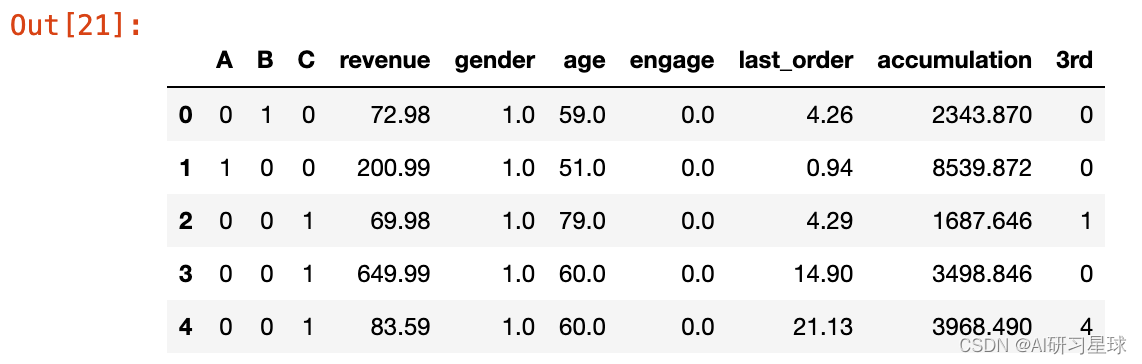
这是一个关于用户在小红书购买金额的数据集, 共有29452条数据, 7个变量。
| 字段名字 | 字段介绍 |
|---|---|
| revenue | 用户下单的购买金额 |
| 3rd_party_stores | 用户过往在app中从第三方购买的数量,为0则代表只在自营商品中购买 |
| gender | 性别 1:男 0:女 未知则空缺 |
| engaged_last_30 | 最近30天在app上有参与重点活动(讨论,卖家秀) |
| lifecycle | 生命周期分为a,b,c (分别对应注册6个月内,1年内,2年内) |
| days_since_last_order | 最近一次下单距今的天数 (小于1则代表当天有下单) |
| previous_order_amount | 以往累积的用户购买金额 |
数据来源:某红书销售情况
3. 分析目的
1. 提出问题:哪些消费群体更庞大,平均购买力更强?已知自变量能否准确预测用户购买金额?
数据整理:数据预处理
a. 数据导入
import pandas as pd
import numpy as np
import random
from matplotlib import pyplot as plt
from pyecharts.charts import boxplot
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
df= pd.read_csv("31 l2_week2.csv")
df.head(10)
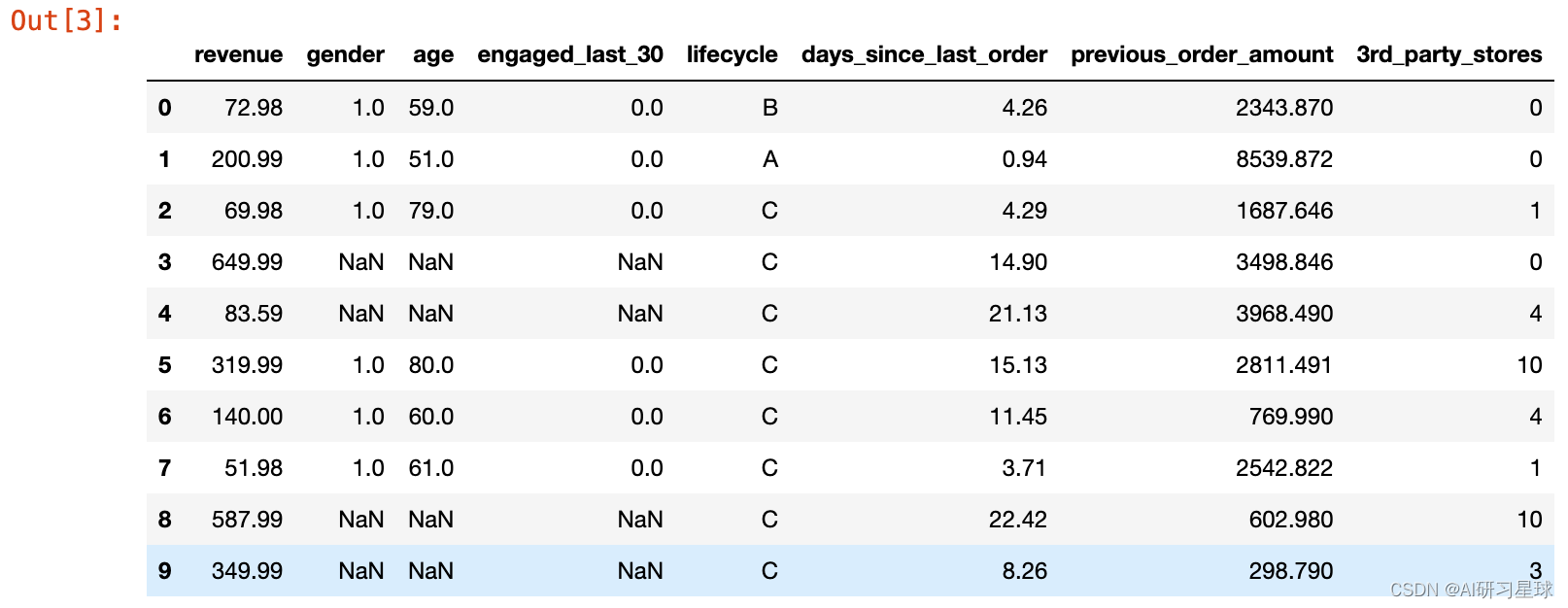
b. 去除重复数值和缺失数值
df.drop_duplicates(inplace=true)
df.reset_index(drop=true,inplace=true)
df.replace('nan',np.nan,inplace=true)
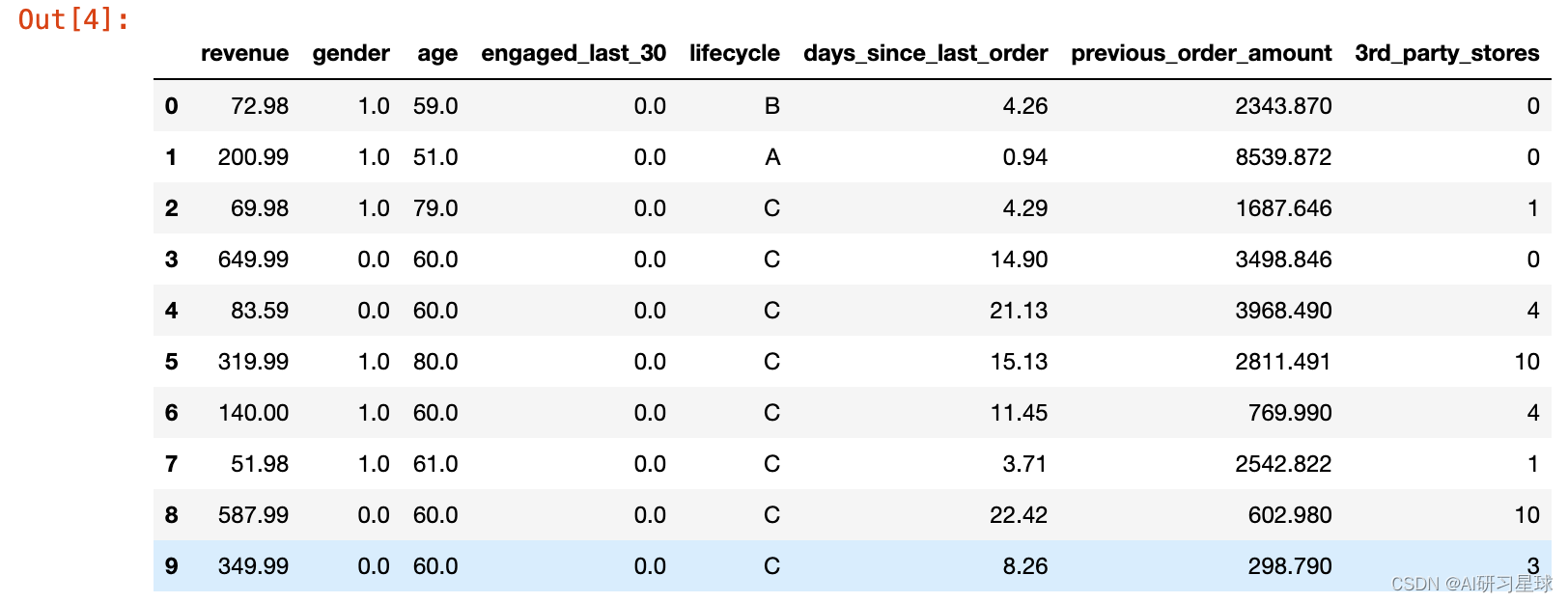
###把性别、年龄、用户过往中为nan的数值分别用随机dummy variable、平均值、随机dummy variable替代
df.fillna(value={"gender":random.choice([1.0,0.0]),"age":round(df["age"].mean(),0),"engaged_last_30":random.choice([1.0,0.0])},inplace=true)
df.head(10)
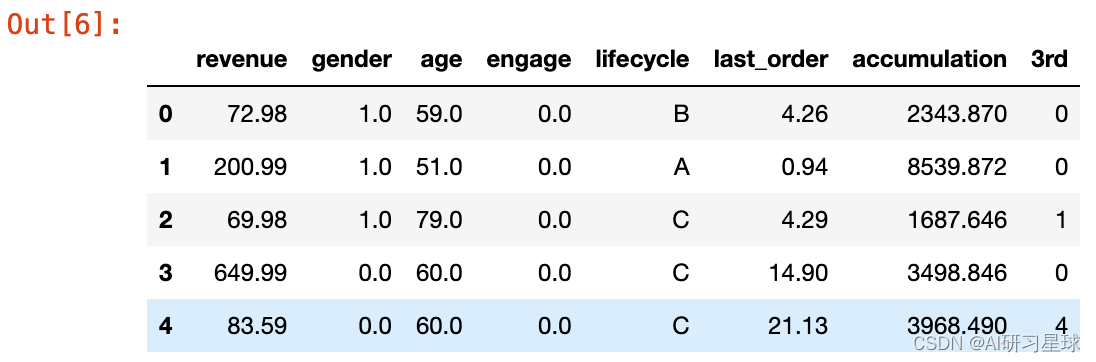
c. 简化部分columns的命名, 方便之后绘图与处理
df=df.rename(columns={"engaged_last_30": "engage", df.keys()[5]: "last_order", "previous_order_amount":"accumulation", "3rd_party_stores":"3rd"})
df.head()
df.dtypes

关注公众号:『ai学习星球』
回复:小红书消费情况分析 即可获取数据下载。
算法学习、4对1辅导、论文辅导或核心期刊可以通过公众号或➕v:codebiubiubiu滴滴我
2. 数据分析:哪些消费群体更庞大, 平均购买力更强
a. 先分析单一变量与利润的关系
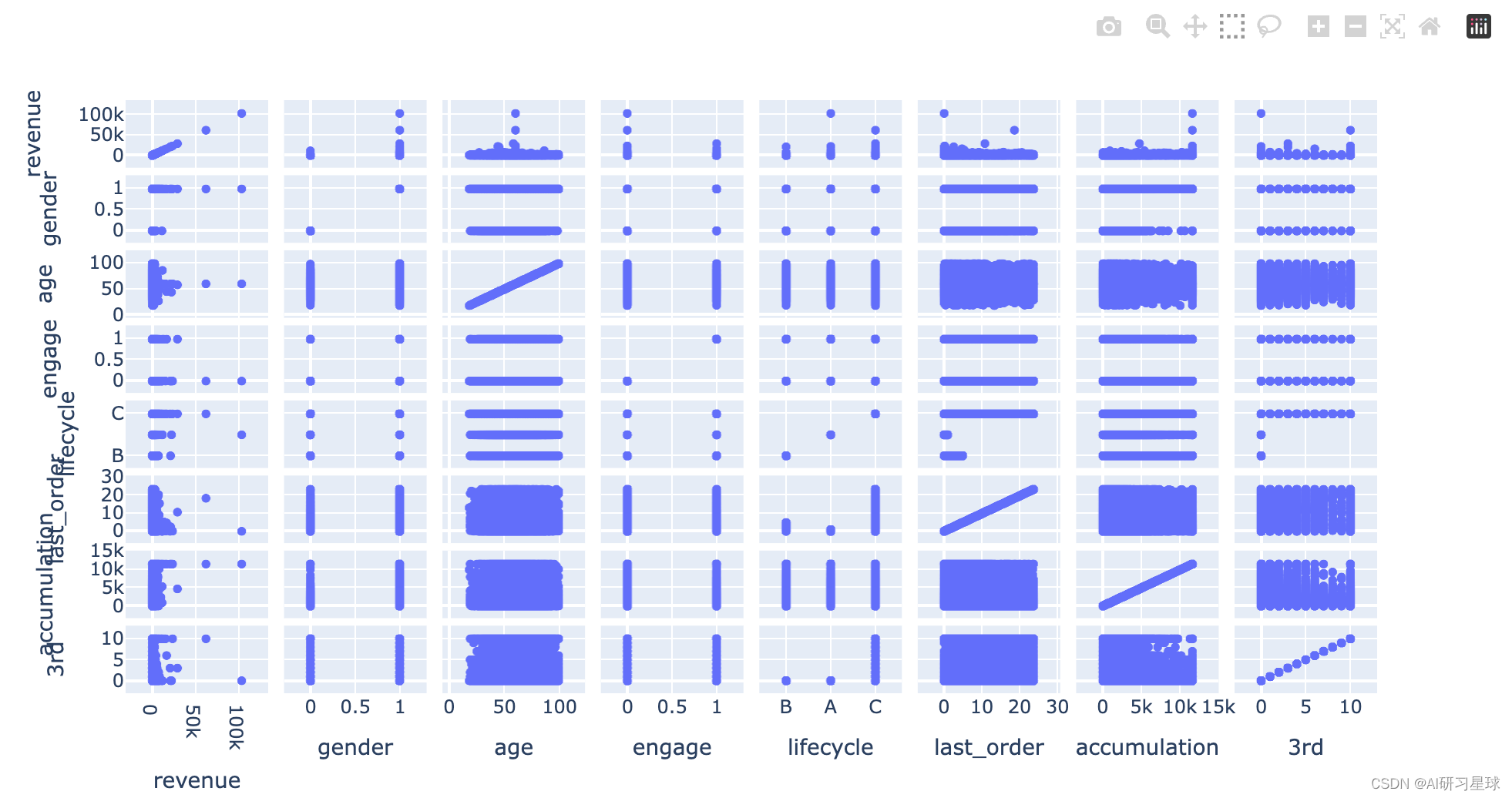
###用matrix plot大致看一下变量之间的线性关系
import plotly.express as px
fig = px.scatter_matrix(df)
fig.show()
#从第一排的图像可以看出各个变量与利润的关系, 更详细的图如下:
plt.scatter(df['gender'], df['revenue'], color='purple')
plt.title('gender vs revenue', fontsize=14)
plt.xlabel('gender', fontsize=14)
plt.ylabel('revenue', fontsize=14)
plt.grid(true)
plt.show()
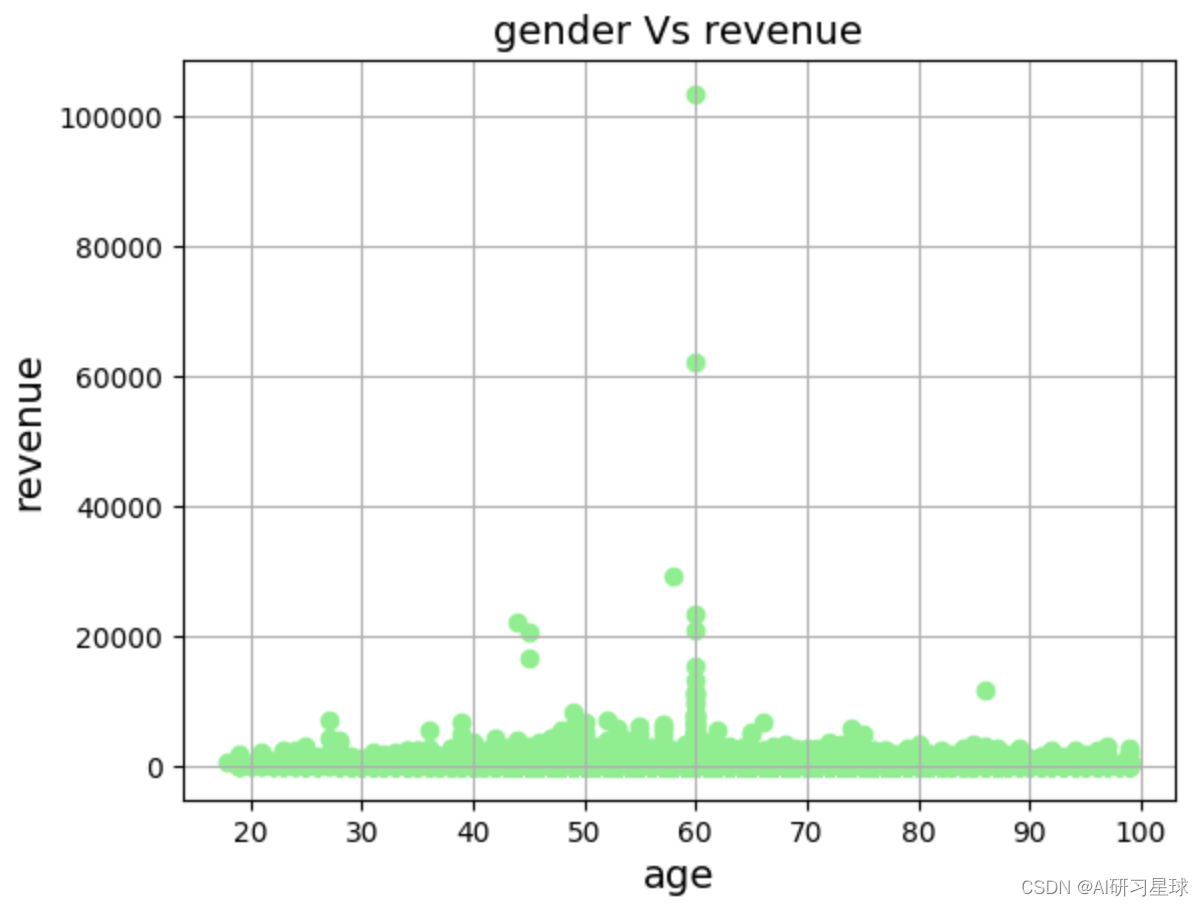
plt.scatter(df['age'], df['revenue'], color='lightgreen')
plt.title('gender vs revenue', fontsize=14)
plt.xlabel('age', fontsize=14)
plt.ylabel('revenue', fontsize=14)
plt.grid(true)
plt.show()
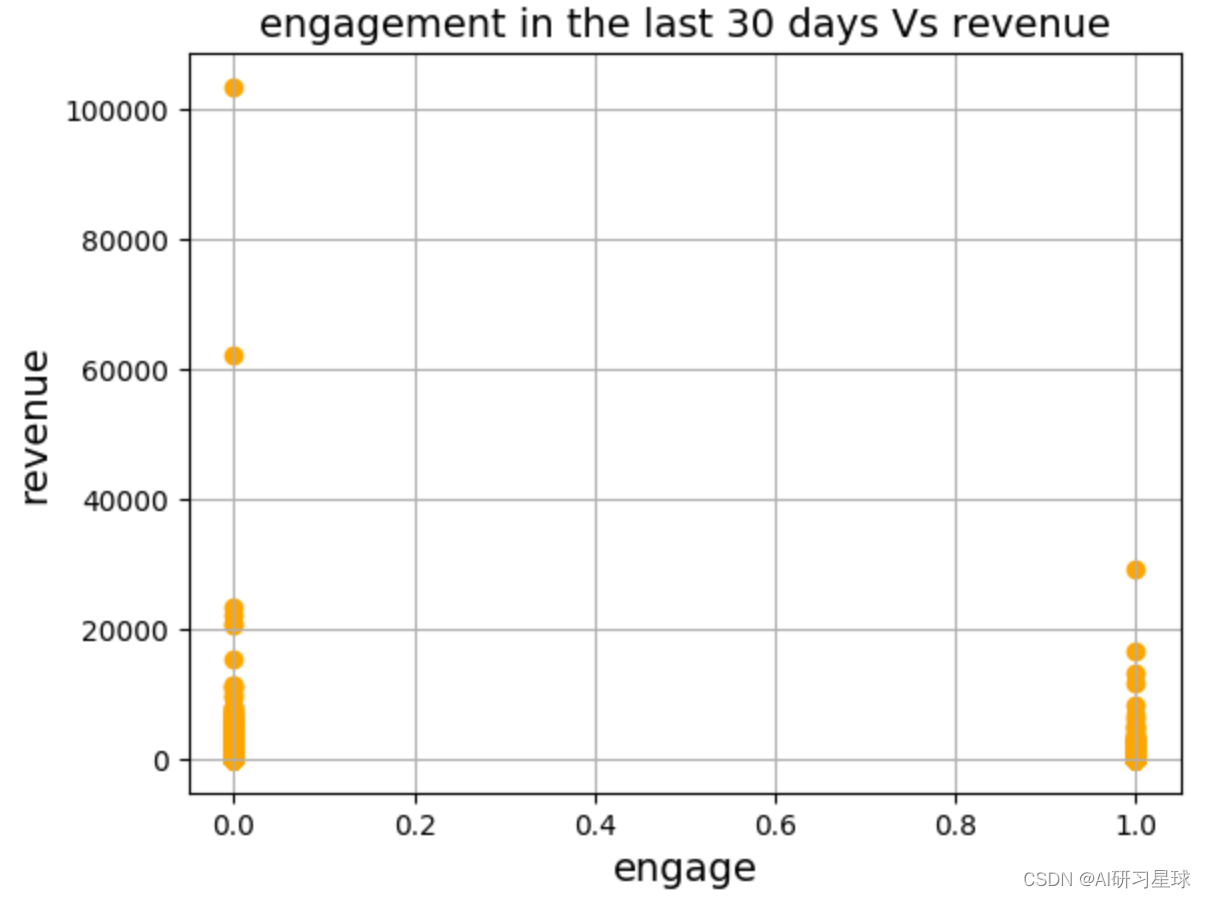
plt.scatter(df['engage'], df['revenue'], color='orange')
plt.title('engagement in the last 30 days vs revenue', fontsize=14)
plt.xlabel('engage', fontsize=14)
plt.ylabel('revenue', fontsize=14)
plt.grid(true)
plt.show()
###参与活动的人群总体购买金额更高
plt.scatter(df['lifecycle'], df['revenue'], color='pink')
plt.title('lifecycle vs revenue', fontsize=14)
plt.xlabel('lifecycle', fontsize=14)
plt.ylabel('revenue', fontsize=14)
plt.grid(true)
plt.show()
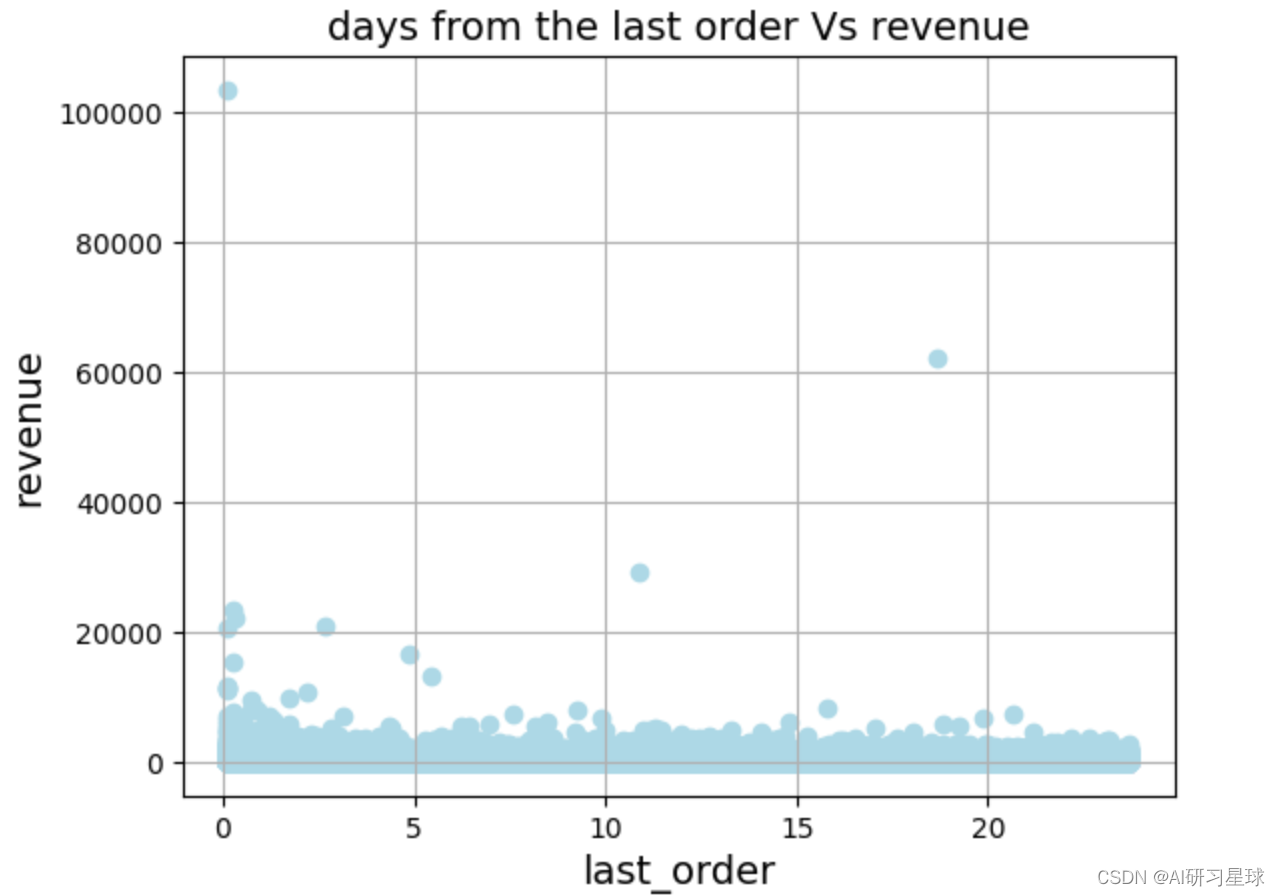
plt.scatter(df['last_order'], df['revenue'], color='lightblue')
plt.title('days from the last order vs revenue', fontsize=14)
plt.xlabel('last_order', fontsize=14)
plt.ylabel('revenue', fontsize=14)
plt.grid(true)
plt.show()
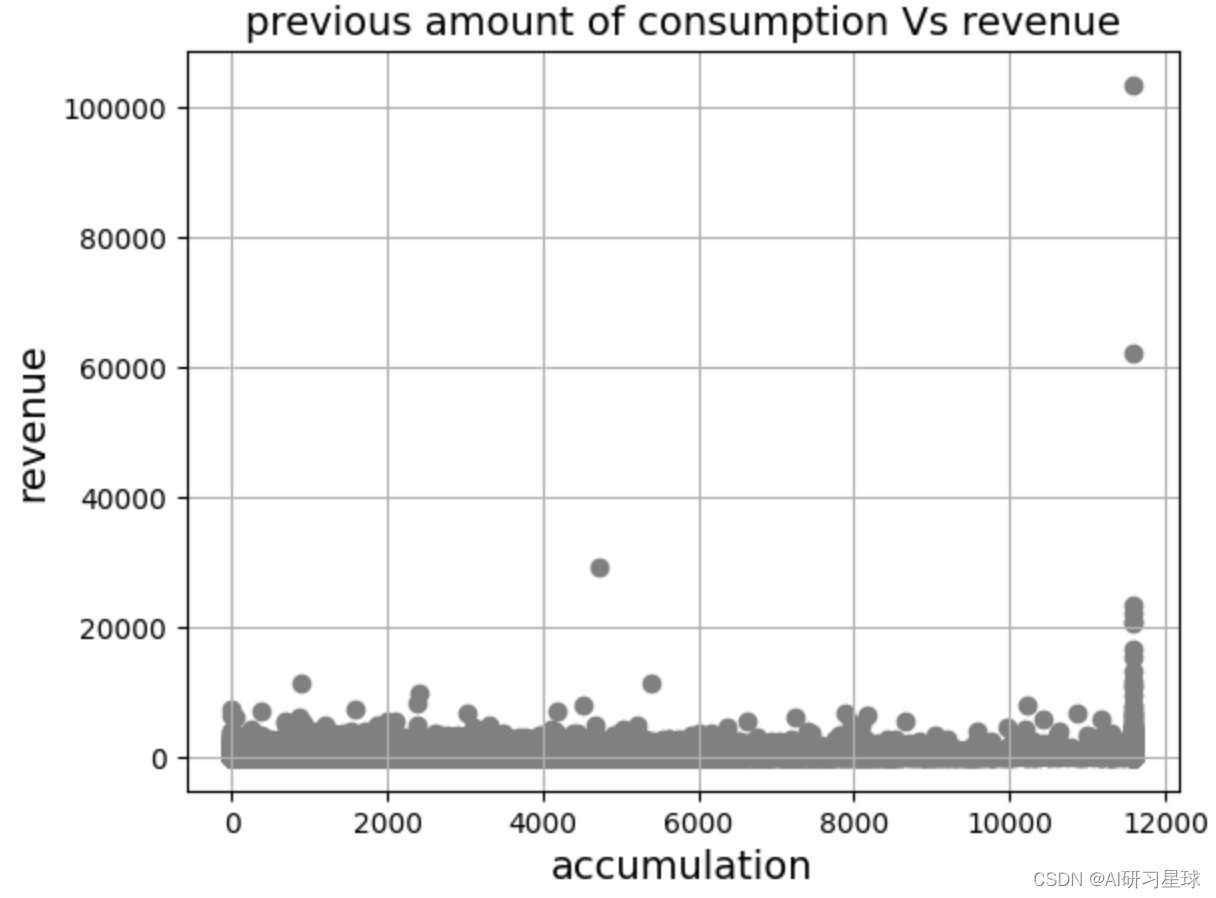
plt.scatter(df['accumulation'], df['revenue'], color='grey')
plt.title('previous amount of consumption vs revenue', fontsize=14)
plt.xlabel('accumulation', fontsize=14)
plt.ylabel('revenue', fontsize=14)
plt.grid(true)
plt.show()
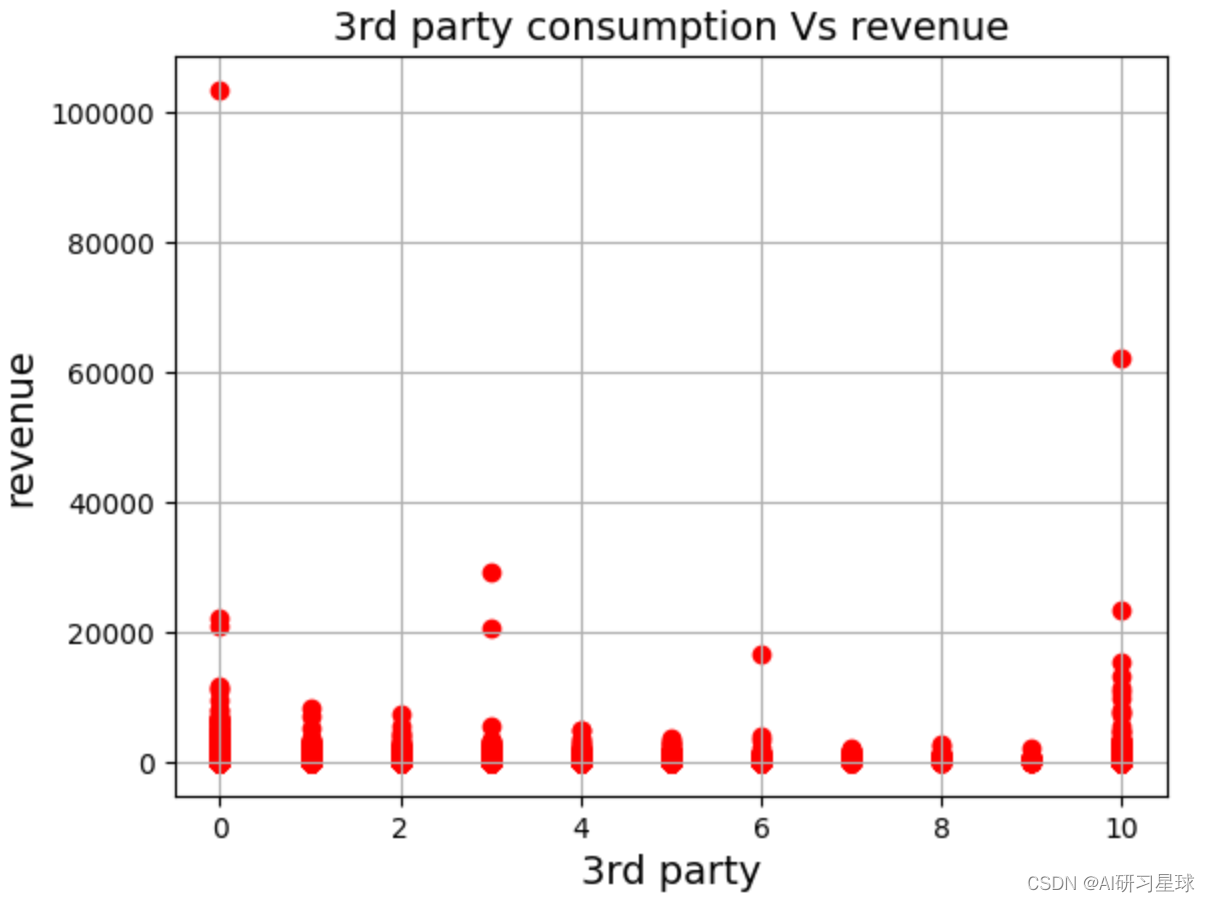
plt.scatter(df['3rd'], df['revenue'], color='red')
plt.title('3rd party consumption vs revenue', fontsize=14)
plt.xlabel('3rd party', fontsize=14)
plt.ylabel('revenue', fontsize=14)
plt.grid(true)
plt.show()
###图像呈现两个极端, 从不购买第三方产品和购买第三方产品数量最多的人群的购买金额更高
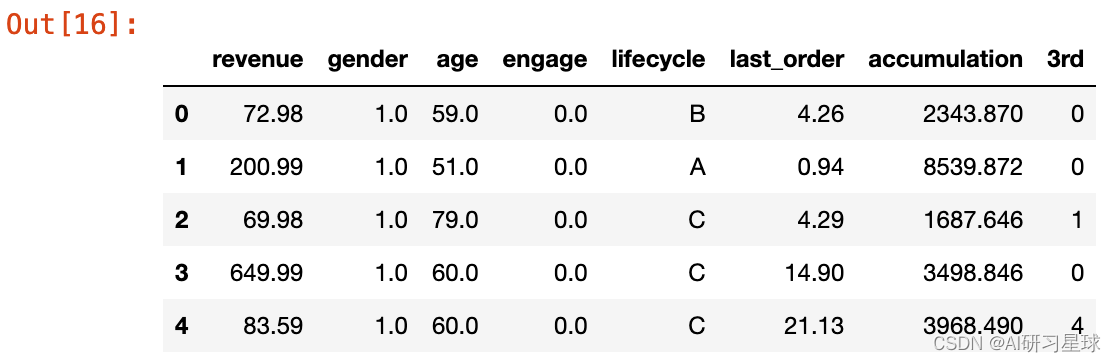
df.head()
b. categorical变量和quantitative变量的组合和利润的关系
(1)年龄与性别
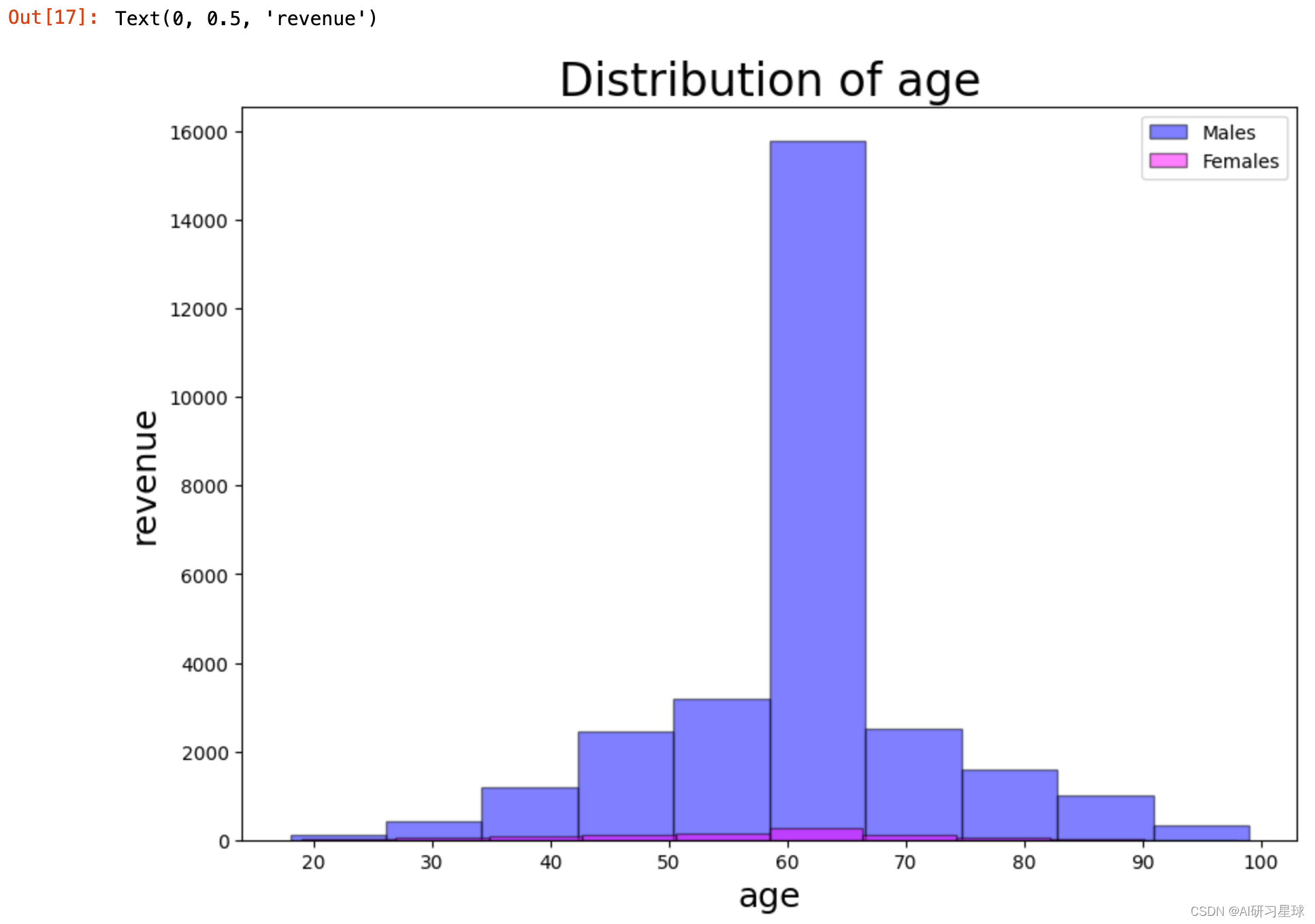
df[df['gender'] == 1.0].age.plot(kind='hist', color='blue', edgecolor='black', alpha=0.5, figsize=(10, 7))
df[df['gender'] == 0.0].age.plot(kind='hist', color='magenta', edgecolor='black', alpha=0.5, figsize=(10, 7))
plt.legend(labels=['males', 'females'])
plt.title('distribution of age', size=24)
plt.xlabel('age', size=18)
plt.ylabel('revenue', size=18)
###60岁年龄段的女性对利润的贡献远大于同年龄段的男性, 但其它年龄段中男性对利润的贡献均比女性大
(2)是否参加活动与先前消费金额
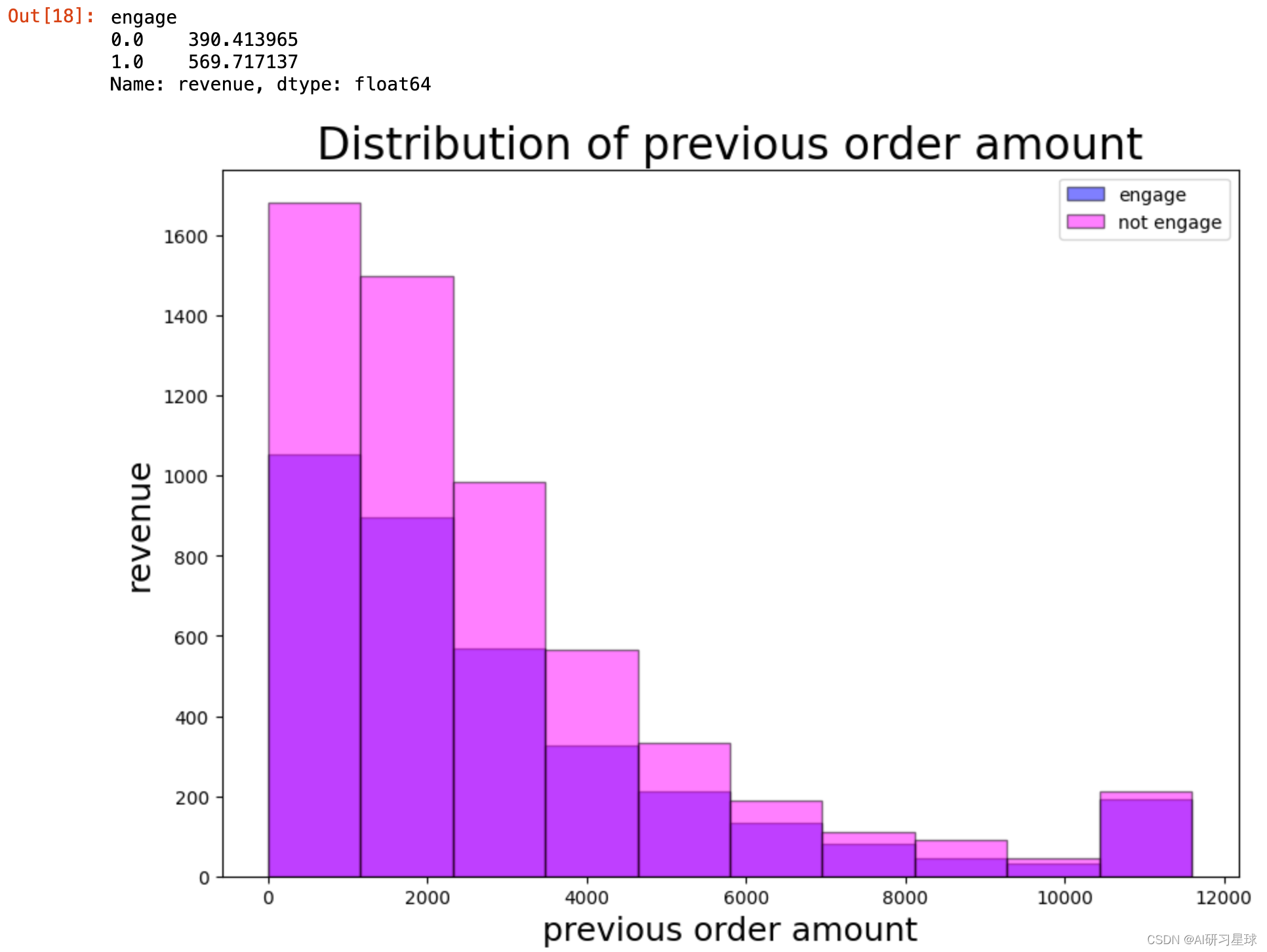
df[df['lifecycle'] == 'a'].accumulation.plot(kind='hist', color='blue', edgecolor='black', alpha=0.5, figsize=(10, 7))
df[df['lifecycle'] == 'b'].accumulation.plot(kind='hist', color='magenta', edgecolor='black', alpha=0.5, figsize=(10, 7))
plt.legend(labels=['engage', 'not engage'])
plt.title('distribution of previous order amount', size=24)
plt.xlabel('previous order amount', size=18)
plt.ylabel('revenue', size=18)
acdiff=df.groupby("engage")['revenue'].mean().sort_values()
acdiff
(3)注册时间与距离上一次下单时间
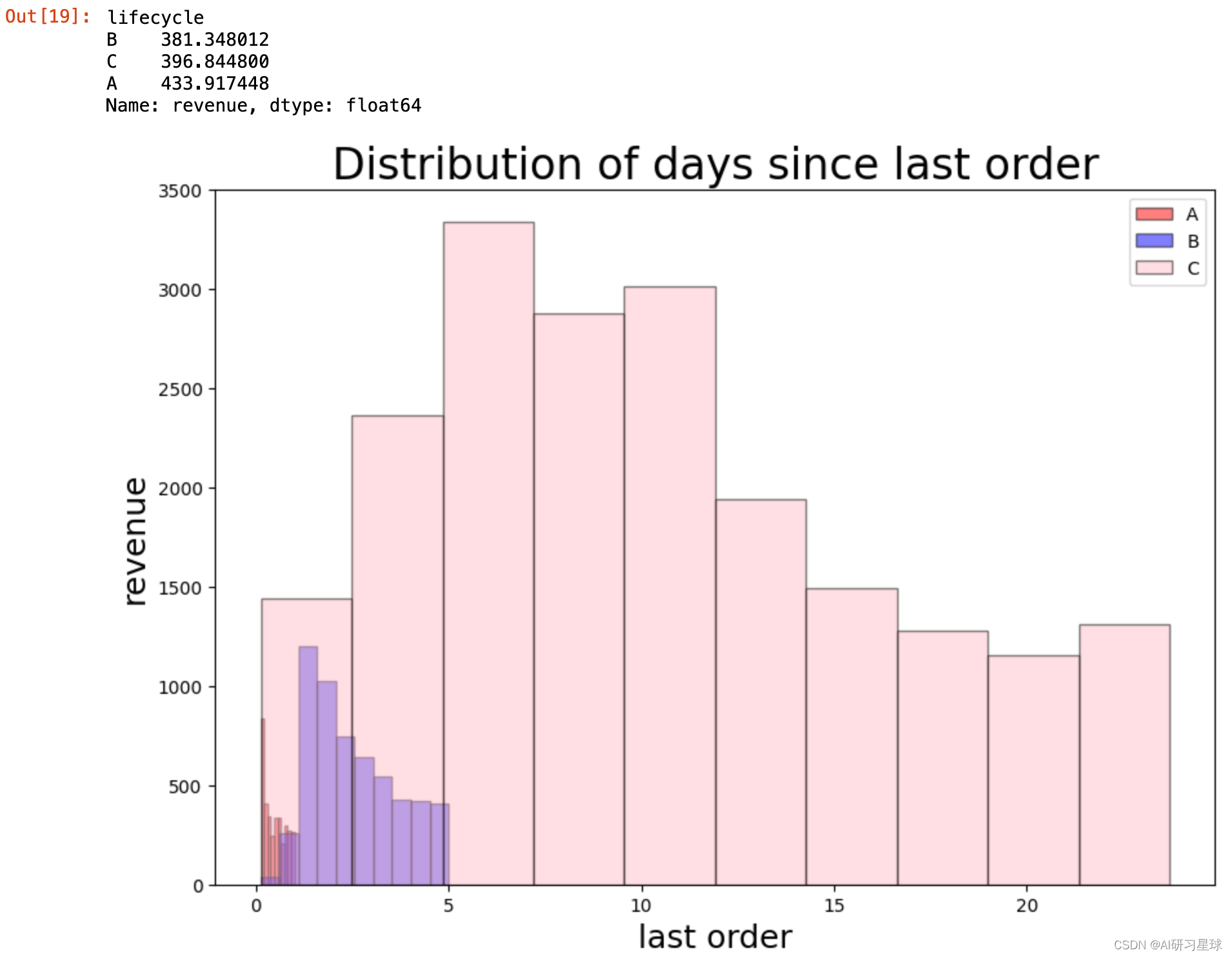
df[df['lifecycle'] == 'a'].last_order.plot(kind='hist', color='red', edgecolor='black', alpha=0.5, figsize=(10, 7))
df[df['lifecycle'] == 'b'].last_order.plot(kind='hist', color='blue', edgecolor='black', alpha=0.5, figsize=(10, 7))
df[df['lifecycle'] == 'c'].last_order.plot(kind='hist', color='pink', edgecolor='black', alpha=0.5, figsize=(10, 7))
plt.legend(labels=['a','b','c'])
plt.title('distribution of days since last order', size=24)
plt.xlabel('last order', size=18)
plt.ylabel('revenue', size=18)
#a: 注册六个月内, b:注册一年内, c:注册两年内
cyclediff= df.groupby("lifecycle")['revenue'].mean().sort_values()
cyclediff
c. 用多线性模型分析数据集
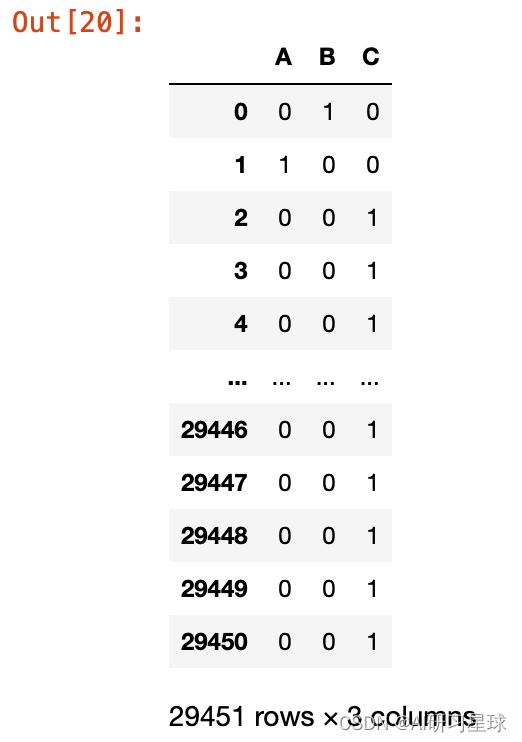
与其它变量不同的是, lifecycle是object, 把它转变为dummy variable(0,1)能方便之后分析多线性关系和绘图
from sklearn.preprocessing import multilabelbinarizer
mlb = multilabelbinarizer()
array_out = mlb.fit_transform(df["lifecycle"])#把原本的a,b,c转变成0,1, 将原本dataframe中的一个column变为a,b,c三个columns
df_out = pd.dataframe(data=array_out, columns=mlb.classes_)
df_out
df = pd.concat([df_out, df], axis=1)#将两个dataframe合并
df1= df.drop(columns=['lifecycle'])#移除原先的lifecycle column
df1.head()
from sklearn import linear_model
x = df[['gender','age', 'engage', 'accumulation', '3rd', 'a','b','c', 'last_order']]
y = df['revenue']
regr = linear_model.linearregression()
result = regr.fit(x, y)
print('intercept: \n', regr.intercept_)
print('coefficients: \n', regr.coef_)
###模型:其中x1到x8 分别对应性别到第三方购买数量, lifecycle c。 只要已知性别, 年龄, 参与活动, 以往购买金额, 第三方购买数量, a,b,c这八个变量就能预测该用户的购买金额

from sklearn import datasets, linear_model
from sklearn.linear_model import linearregression
import statsmodels.api as sm
from scipy import stats
x2 = sm.add_constant(x)
est = sm.ols(y, x2)
est2 = est.fit()
print("summary()\n",est2.summary())
print("pvalues\n",est2.pvalues)
print("tvalues\n",est2.tvalues)
print("rsquared\n",est2.rsquared)
print("rsquared_adj\n",est2.rsquared_adj)

- adjusted r squared等于0.03, 表示只有百分之三的利润变化能用这些变量去解释, 所以这个模型对预测利润的作用很小
- 从这张总结图中看出, 除了性别和第三方购买量的p-value值很大之外, 其它的变量的p-value都为0, 可见这个模型存在很大的multicolinearity问题
4. 结论及建议
- 小红书上的男性消费者相对女性消费者不光群体更庞大且平均购买力更高, 可以面向男性消费者推出更多产品或加大宣传力度
- 经常购买第三方产品和从不购买第三方产品的消费者群体不光更庞大且平均购买力更高
- 未参加活动的群体对消费金额的贡献更大, 但参加活动的消费者群体的平均购买力比为参加的群体高很多, 建议扩大活动影响范围, 增加参加活动的群体
- 年龄60左右的女性消费者群体对总体消费金额贡献相比同龄男性大很多, 需要更重视这个年龄段的群体对产品的喜好
关注公众号:『ai学习星球』
回复:小红书消费情况分析 即可获取数据下载。
算法学习、4对1辅导、论文辅导或核心期刊可以通过公众号或➕v:codebiubiubiu滴滴我

发表评论