聚类
聚类(clustering)是按照某个特定标准(如距离)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。也即聚类后同一类的数据尽可能聚集到一起,不同类数据尽量分离。
聚类是指把相似的数据划分到一起,具体划分的时候并不关心这一类的标签,目标就是把相似的数据聚合到一起。
聚类算法
聚类算法,它是研究(样品或指标)分类问题的一种统计分析方法,同时也是数据挖掘的一个重要算法。另外需要说明的是,聚类是以相似性为基础的。
k均值聚类是最著名的划分聚类算法,由于简洁和效率使得他成为所有聚类算法中最广泛使用的。给定一个数据点集合和需要的聚类数目k,k由用户指定,k均值算法根据某个距离函数反复把数据分入k个聚类中。
kmeans算法
划分聚类(partition based clustering):给定包含n个点的数据集,划分法将构造k个分组;每个分组代表一个聚类,这里每个分组至少包含一个数据点,每个数据点属于且只属于一个分组;对于给定的k值,算法先给出一个初始化的分组方法,然后通过反复迭代的的方法改变分组,知道准则函数收敛。
k-means算法是输入聚类个数k,以及包含 n个数据对象的数据库,输出满足方差最小标准的k个聚类。
k-means 算法接受输入量 k ;然后将n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。
算法定义:
给定样本集: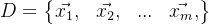 , k均值算法针对聚类所得簇:
, k均值算法针对聚类所得簇: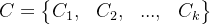
最小化平方差:


发表评论