在追求更高效的机器学习模型部署时,模型量化技术应运而生,它通过降低权重矩阵的位宽来显著减少大型语言模型的存储和计算需求。
我们一般的双精度浮点型double是64位,单精度浮点型float是32位。早年roberta等大模型训练时把精度压缩到了16位的半精度fp16。近年来,大语言模型量化一般都只敢玩到4位或8位量化,因为要是把位宽压得太狠,性能就会直线下滑。
最近,清华和哈工大提出了一个名为onebit的1位量化感知训练框架把大模型量化做到了1比特,同时保证了时间和空间效率以及模型性能之间的平衡,至少能达到非量化性能的83%,而且训练过程还特别稳定。
onebit框架采用创新的1比特参数表示方法,精确量化llm。同时,结合高效的矩阵分解初始化策略——sign-value-independent decomposition(svid),显著提升框架收敛速度。通过量化感知知识蒸馏,成功将教师模型的能力迁移至1比特对应模型。
论文标题:
onebit: towards extremely low-bit large language models
公众号「夕小瑶科技说」后台回复“onebit”获取论文pdf!
背景知识
量化与剪枝和知识蒸馏(kd)同属于模型压缩的主流方法。模型量化的主要思想是将模型中的每个权重矩阵从fp32或fp16格式压缩为低比特值。比如经常将transformer中的linear层的权重矩阵量化为8位、4位,甚至2位。
大多数量化研究主要采用最近舍入(round-to-nearest (rtn))方法,即将权重舍入到量化网格中的最近值。其数学表达形式可以表示为
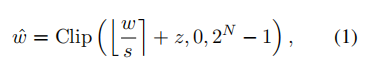
其中,表示量化尺度参数, 表示零点参数,表示量化位宽。将结果截断在0到的范围内。随着位宽的降低,量化网格也变得更稀疏。图1展示了llama-7b在不同量化方法上的困惑度,得分越低表示性能越好。
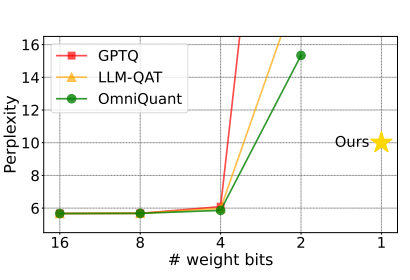
从图中可以看出,基于rtn方法的量化在4位时可能会达到最佳性能。进一步压缩,将模型量化至2位值将导致显著下降。
而当将低秩量化至1位值时在量化模型中只有2个可选的数字可供选择。此外,当n等于1时,基于rtn方法的量化本质上等同于设定一个阈值,权重在阈值两侧被转换为相应的整数值。在这种情况下,公式(1)中的参数和实际上失去了实用意义。
因此,当量化权重为1位时,逐元素的rtn操作极大地降低了权重矩阵的精度,导致量化模型性能较差。
onebit框架
onebit框架的核心思想是将llms的权重矩阵大胆地量化到1位。1位量化意味着每个权重值只能用1位二进制数表示,即只有两种可能的状态(+1或-1)。同时引入两个fp16格式的值向量以补偿由于量化导致的精度损失。这种设计不仅保持了原始权重矩阵的高秩,而且通过值向量提供了必要的浮点精度,有助于模型的训练和知识迁移。
下图展示了二进制量化线性层与常规的fp16线性层的区别,左侧是原始的fp16线性层,其中激活x和权重矩阵w都是以fp16格式呈现。右侧是本文提出的架构onebit。只有值向量g和h是以fp16格式呈现,而权重矩阵由±1组成。
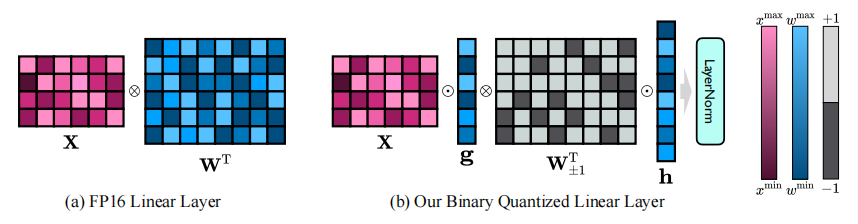
1. 线性层的onebit架构设计
由于1比特权重量化存在严重的精度损失,基于rtn将linear层中的权重矩阵直接从fp32/16转换为1比特格式具有挑战性。作者提出了一种线性层的1-bit架构设计,如下公式所示:
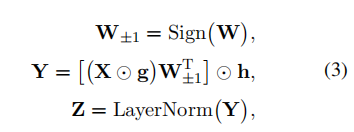
其中表示形状为的量化权重矩阵,表示1位量化矩阵。是linear层的输入,是输出。函数返回符号矩阵。
除此之外还引入两个fp16值向量,来折中量化过程中的精度损失。即使引入了额外的参数,其好处远远超过其小成本。
这里作者举了一个例子来说明:设为4096 × 4096的权重矩阵进行量化时,每个分量中的比特数为:
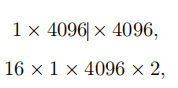
其中第一个是用于1位量化的权重矩阵, 第二个是用于两个fp16值向量。因此,总比特数为16, 908, 288。此外,参数数量为4096 ×4096 + 2 × 4096 × 1= 16, 785, 408。因此,这个linear层量化结果的平均位宽为16, 908, 288 ÷16, 785, 408 ≈ 1.0073。
2. svid
为了使用完全训练好的权重初始化1比特模型,作者引入了权重矩阵w的sign-value-independent decomposition,svid。
在onebit框架中,权重矩阵在数学上被分为两个部分:一个int1格式的符号矩阵和两个fp16格式的值向量。
可以公式化为。其中和。而可进一步近似分解为两个向量和的外积,也称为rank-1 approximation。因此,该矩阵分解方法可以表示为
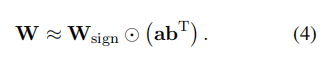
这里可以利用一些广泛使用的矩阵分解方法进行rank-1逼近,例如奇异值分解svd和nmf非负矩阵分解。本文选用nmf,可以获得更好的性能。
命题1:鉴于权重矩阵 和输入 ,根据svid,linear层可以重新表述如下,这桥接了量化模型的结构和其原始权重之间的差距。
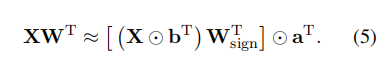
▲具体证明过程见原文。
svid的主要目标是通过利用符号矩阵来近似矩阵,而不仅仅依赖于fp16格式的值向量。为了证实符号矩阵在矩阵近似中的作用,作者提出以下命题:
命题 2:给定矩阵 和 ,。按照 和 的方式分解这些矩阵,其中 表示误差矩阵。根据 frobenius 范数,svid 更接近于原始矩阵 w,这清楚地展示了符号矩阵在矩阵近似中的实际作用。
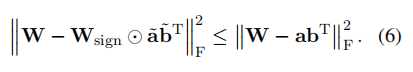
svid并不旨在精确复制原始模型的参数,而是为进一步训练提供了一个有效的起点,以充分利用原始模型的广泛训练。
3. 知识迁移
作者采用量化感知知识蒸馏技术,从原始模型(即教师模型)传递知识到量化后的模型(即学生模型)。在学生模型中,更新矩阵和方程(3)中的向量。
损失函数使用基于交叉熵的 logits 和基于全精度教师模型隐藏状态的均方误差,来指导量化的学生模型:
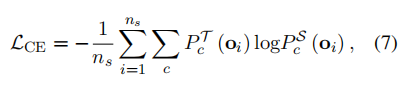
其中c表示类别的数量,表示当前批次的训练样本数量。和分别表示教师模型和学生模型。隐藏状态的误差被定义为:
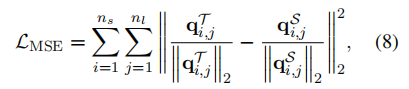
其中表示层数,表示隐藏状态。因此,最 终的目标函数可以被表述为:
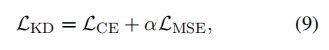
其中,是一个超参数,用于平衡交叉熵损失和中间层特征之间的重要性。
实验设置
数据
使用原始教师模型的下一个令牌生成合成语料库。它从词汇中随机选择第一个令牌,并迭代生成下一个令牌,直到达到<eos>令牌或最大长度。具体来说,前3到5个令牌的top-1预测是确定性选择的,其后的令牌则进行随机抽样。本文利用llama-7b生成了总共132k个数据条目,每个条目的最大长度为2,048。
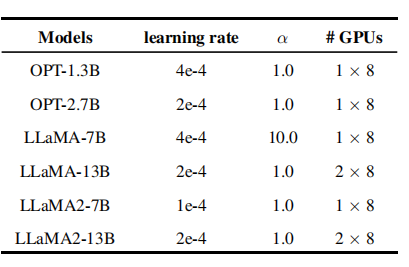
训练细节
每次知识蒸馏实验都会学习50个epoch的训练数据,选择2048个token片段。采用scikit-learn中的nmf来分解svid中的权重矩阵。量化学生模型通过adam优化器进行优化,学习率通过cosine策略进行调度。其他训练细节如下表所示:
评估指标
通过在wikitext2和c4这两个数据集上测试困惑度来评估量化模型的性能。较低的困惑度意味着压缩模型在保持原始模型输出分布方面做得更好。此外,还报告了多个零样本任务的准确性,包括winogrande、hellaswag、piqa、boolq和arc,以检验原始模型在下游任务中的能力是否得以保留。所有这些评估都是通过开源工具包“lm-evaluation-harness”来完成的。
主要实验结果:onebit的性能表现
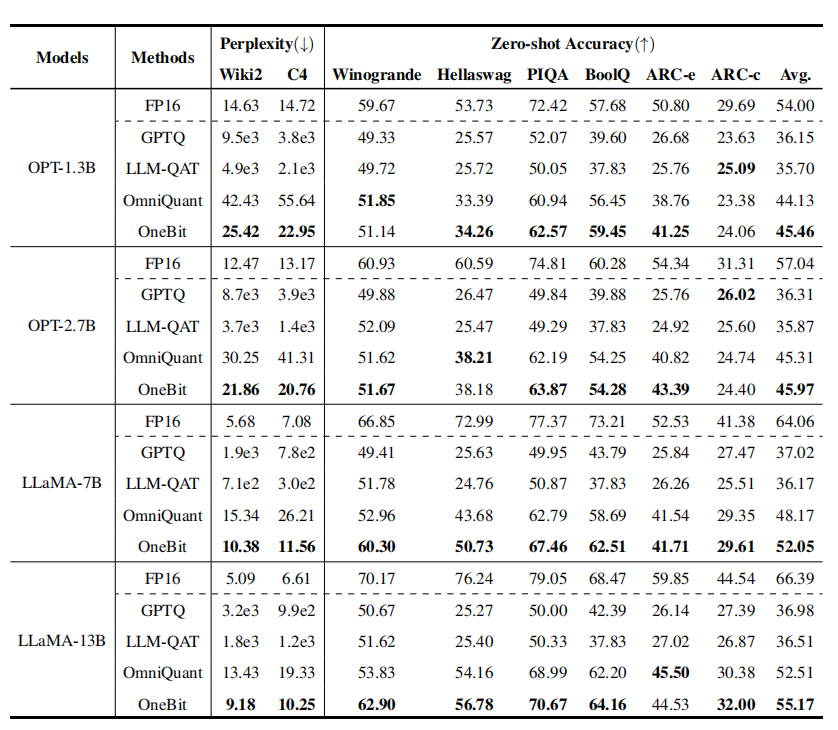
在对llms进行极低比特宽度量化的研究中,onebit框架展现了显著的性能。实验结果如下表所示:
-
从困惑度指标来看,onebit显著优于其他方法。虽然qat方法随着模型大小增加,性能显著提升。但而本文的方法有明显的优势,并且逐渐接近fp16的性能,尤其在llama-13b模型上,困惑度下降明显。
-
对于零样本任务准确率,onebit方法在多数模型中实现了与fp16基线接近的性能,仅在少数任务上落后于omniquant,但相差不大。
模型能力分析:onebit在实际问题解决中的表现
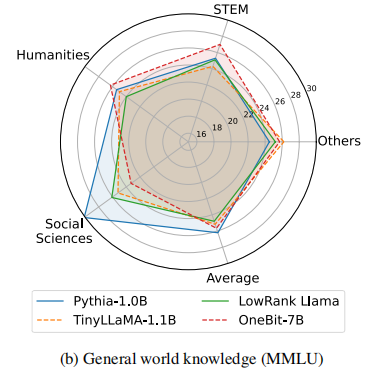
所有方法在1比特权重量化中都不可避免地面临性能下降,因此作者还评测onebit解决实际问题的能力,重点专注常识推理和世界知识能力。
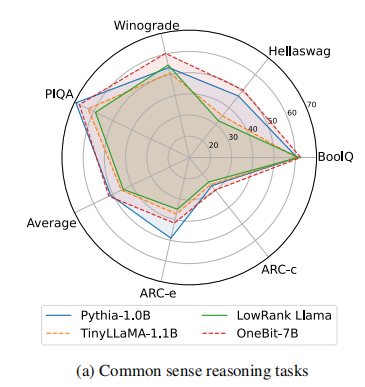
尽管其他模型参数更多且训练更充分,但onebit模型在常识推理方面仍然具有优势。这反应了onebit很好的继承了更大的7b模型中的知识与能力。
而在世界知识方面,尽管onebit在社会科学领域存在一定损失,但在其他领域中表现超过了完全训练pythia-1b模型。
分析与讨论
1. 效率
显然,将模型权重量化为极低位可以大幅度减少其内存占用。实际上,如表3所示,随着模型规模的增大,压缩比也在不断提高。这一点对于大型模型来说尤为重要,因为它使得将这类模型部署到单个gpu上成为可能,从而极大地提高了模型的实际应用性和灵活性。
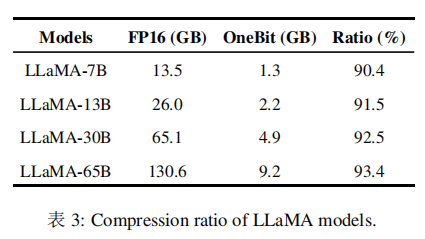
虽然该方法在实施过程中可能会导致一定的性能损失,但如图4所示,它在空间占用和模型性能之间达到了良好的平衡。
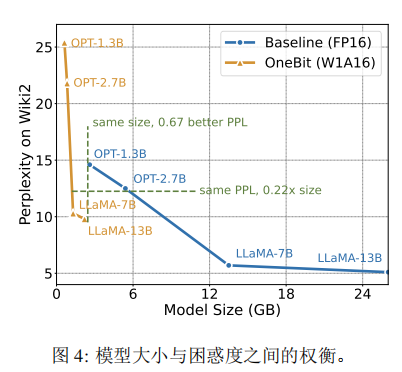
比如只需使用原始模型空间的0.2倍,即可实现与fp16相当的性能表现。此外,通过将权重量化为±1,能够进一步加速cpu上的矩阵乘法操作。这是因为在这种量化方式下,原本需要进行的浮点乘法可以转换为速度更快的位操作,显著提升计算效率。因此,该方法的内存占用显著减少,更符合个人电脑和智能手机等设备的部署需求。
2. 鲁棒性
极低比特量化使训练过程对学习率高度敏感,当学习率过小或过大时,使模型难以收敛。这主要是由于权重元素在+1和-1之间波动时产生的梯度幅度较大,导致linear层输出显著波动。
下图显示了另一种1位量化架构bitnet在使用不同学习率训练时的表现,可以看到非常不稳定:
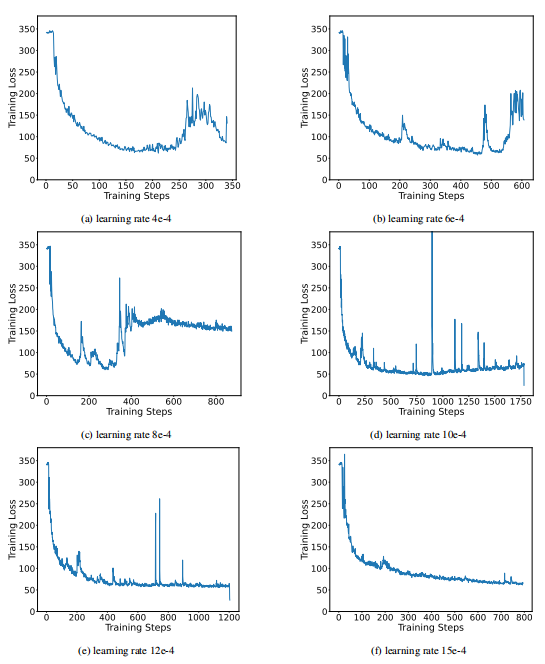
而onebit通过引入两个fp16格式的值向量来补充必要的浮点数值精度,同时限制了量化后矩阵乘法结果的波动范围,从而提高了模型的鲁棒性,展现出更稳定的训练过程,并且对学习率不敏感。
3. 不同组件的影响
onebit主要的可变组件包括post-layernorm、参数初始化等。
-
post-layernorm:在量化感知训练期间,模型存在浮点数溢出的问题,尤其在模型深度增加时,激活值容易急剧增长。为应对此问题,本文选择了post-layernorm策略,而非pre-layernorm。因为在实际应用中,pre-layernorm有时可能无法有效地控制激活值的增长。
-
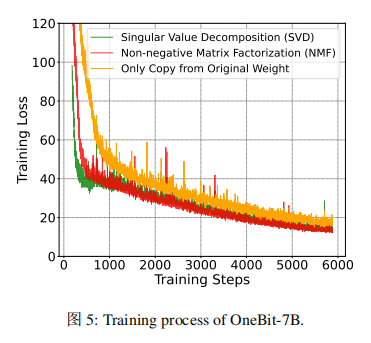
参数初始化:在使用svid做参数初始化时,非负矩阵分解和奇异值分解均可用于分解|w|,但推荐使用奇异值分解。它能加快训练收敛速度,如下图所示,nmf初始化有助于获得更好的性能。
总结
onebit框架提出了一种大胆的1位量化方法,极大地减少了模型部署时的存储和计算开销。尽管存在一些性能损失,但其在模型压缩和部署效率方面的潜力是显而易见的,为研究极低位量化模型提供了一条新的探索途径。
公众号「夕小瑶科技说」后台回复“onebit”获取论文pdf。





发表评论