前言
elasticsearch(简称es)
是一个支持海量搜索引擎服务,当一个分布式系统需要支持海量搜索服务时都会优先上es。因此掌握es技术也是一门进入大厂拿高薪的必修课,笔者一直在追求深入掌握es技术,一方面希望自己有机会还能进大厂并站稳脚跟。退一步讲就算进不了大厂,自己也要能具备做出大厂程序员能做出来的产品,到那时就算自己经营一个日活上万的网站或者app也能有一份不错的收入。
之所以会选择7.12版本的es是因为这个版本的es算是一个比较新稳定的新版本,与之关联的kibana版本的界面也有了较大的更新,所以选择了安装这个版本的es。笔者之前在linux和windows系统下也安装过单独的es服务,但是发现都安装和配置非常麻烦,还容易报各种安装失败的错误。后来看到很多大牛都推荐使用docker安装贼顺利,而且还方便维护,于是笔者也尝试在自己的云服务器中使用docker安装es和kibana及中文分词器,下面我们正式进入安装步骤,本文假设读者已经在自己的云服务器中安装好了docker服务,并通过执行systemctl start docker.service 命令启动了docker服务。
1. 创建网络
因为我们还需要部署kibana容器,因此需要让es和kibana容器互联,这里先创建一个网络。
使用finalshell登录自己的linux云服务器客户端(阿里云或腾讯云)
docker network create es-net2.加载镜像
执行 cd /usr/local进入云服务器的 /usr/local目录执行拉取es和kibana安装包的docker命令
这个elasticsearch镜像体积非常大,接近1g。
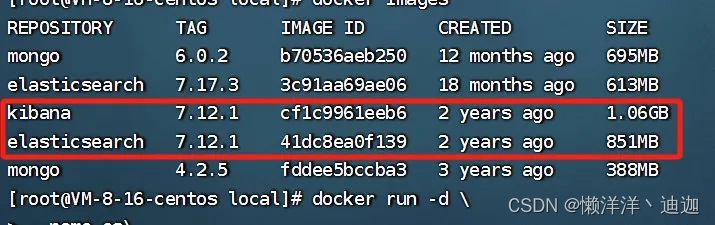
3.运行容器
执行如下docker命令运行es服务:
开通9200端口防火墙
执行如下命令开通9200端口防火墙
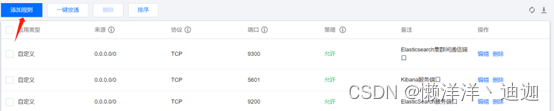
同时需要登录云服务器控制台通过【服务器详情】-> 【防火墙】菜单下点击【添加规则】,在弹出的对话框中分别添加9200和9300端口,如下所示:
验证安装结果
在浏览器地址栏中输入url:http://<你的云服务器公网ip地址>:9200/
返回如下结果表示docker安装和运行elasticsearch服务成功
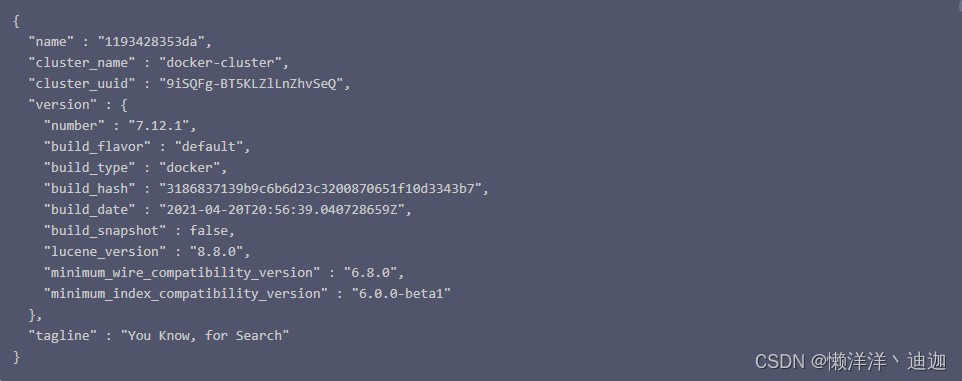
可以看到7.12版本的es对应的lucene引擎已经到了8.8.0版本,可见es的升级也是非常快的,最新的es已经来到8以上版本。
4. 部署kibana
kibana 使操作es数据的可视化界面,使用kibana 操作es非常方便。
在/usr/local目录执行如下docker命令
kibana启动一般比较慢,需要多等待一会,可以通过命令:
docker logs -f kibana 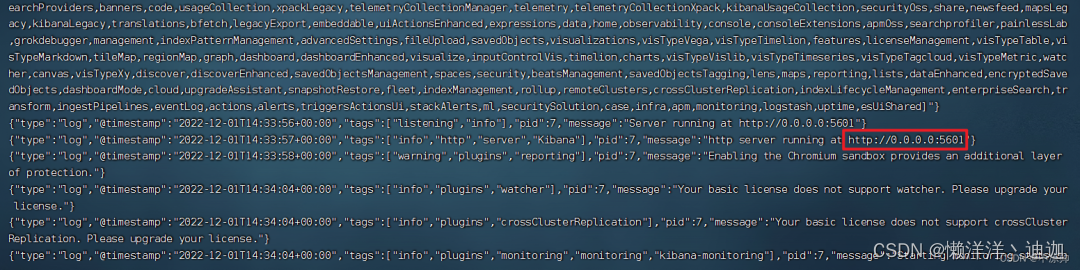
也可以通过浏览器访问:http://<你的云服务器公网ip地址>:5601/app/home#/
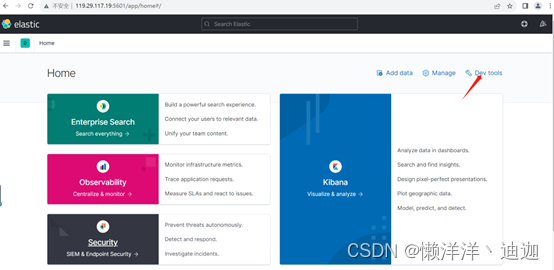
kibana home界面右上角中提供了一个devtools操作按钮,点击该按钮即可进入如下所示的开发操作界面:
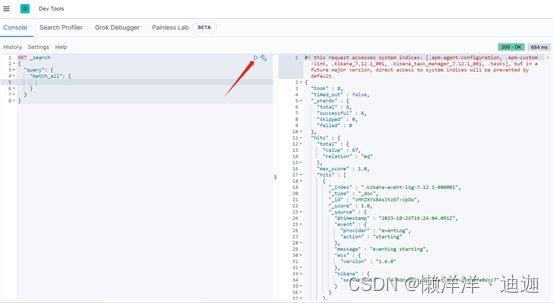
在左边的控制台输入框中输入如下命令,然后点击右上角的三角形按钮执行请求即可在右边的界面看到查询结果。
get _search
{
"query": {
"match_all": {
}
}
}
这个界面中可以编写dsl来操作elasticsearch,并且对dsl语句有自动补全功能。从查询结果来看,es创建的同时就已经自动创建了很多个文档集合,如:.kibana-event-log-7.12.1-000001和.kibana_7.12.1_001等。
5. 安装ik分词器
进入容器内部
docker exec -it es bash复制
进入bin目录
cd /usr/share/elasticsearch/bin复制
在线下载并安装
./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
退出
exit
重启容器
docker restart esk分词器包含两种模式:
- ik_smart:最少切分
- ik_max_word:最细切分
在左边的控制台输入框中输入如下中文分词请求:
get _analyze
{
"analyzer": "ik_smart",
"text": "程序员青年阿福2023年发表的文章集合"
}
然后点击右边的执行请求按钮,可以看到右边的结果窗口返回如下结果
{
"tokens" : [
{
"token" : "程序员",
"start_offset" : 0,
"end_offset" : 3,
"type" : "cn_word",
"position" : 0
},
{
"token" : "青年",
"start_offset" : 3,
"end_offset" : 5,
"type" : "cn_word",
"position" : 1
},
{
"token" : "阿福",
"start_offset" : 5,
"end_offset" : 7,
"type" : "cn_word",
"position" : 2
},
{
"token" : "2023年",
"start_offset" : 7,
"end_offset" : 12,
"type" : "type_cquan",
"position" : 3
},
{
"token" : "发表",
"start_offset" : 12,
"end_offset" : 14,
"type" : "cn_word",
"position" : 4
},
{
"token" : "的",
"start_offset" : 14,
"end_offset" : 15,
"type" : "cn_char",
"position" : 5
},
{
"token" : "文章",
"start_offset" : 15,
"end_offset" : 17,
"type" : "cn_word",
"position" : 6
},
{
"token" : "集合",
"start_offset" : 17,
"end_offset" : 19,
"type" : "cn_word",
"position" : 7
}
]
}
可以看到一句中文"程序员青年阿福2023年发表的文章集合"被ik_smart类型的中文分词器拆分成了7个token对象,每个token对象包含了token、start_offset(开始位移)、end_offset(结束位移)、type(类型)和position(位置)等5个字段。
参考文献:docker 安装7.12.1版本elasticsearch、kibana及中文分词器-腾讯云开发者社区-腾讯云 (tencent.com)



发表评论