
前言
- 之前整理了一篇关于unity面试题相关的所有知识点:2022年unity 面试题 |五萬字 二佰道| unity面试题大全,面试题总结【全网最全,收藏一篇足够面试】
- 为了方便大家可以重点复习某个模块,所以将各方面的知识点进行了拆分并更新整理了新的内容,并对之前的版本中有些模糊的地方进行了纠正。
- 进阶篇中有些题目在基础篇已经有了,这里划分模块时有些会再加一遍用于加深印象学习。
- 所以本篇文章就来整理一下数据结构/算法相关的题目,说不准就会面试的时候就会遇到!
- 内容来源为网上各种优质题目汇总学习使用,若有补充可评论区提出问题,供给大家一起学习进步使用!

💞数据结构
1、常用的数据结构。
数据结构是指相互之间存在着一种或多种关系的数据元素的集合和该集合中数据元素之间的关系组成 。 常用的数据结构有:数组,栈,链表,队列,树,图,堆,散列表等。
2、数组理解
数组是可以再内存中连续存储多个元素的结构,在内存中的分配也是连续的,数组中的元素通过数组下标进行访问,数组下标从0开始。例如下面这段代码就是将数组的第一个元素赋值为 1。 int[] data = new int[100];data[0] = 1;
优点:
a. 按照索引查询元素速度快
b. 按照索引遍历数组方便
缺点:
a. 数组的大小固定后就无法扩容了
b. 数组只能存储一种类型的数据
c. 添加,删除的操作慢,因为要移动其他的元素
适用场景: 频繁查询,对存储空间要求不大,很少增加和删除的情况。
3、list的理解
有序的对象列表,属于数据结构的一种:顺序结构。 泛型集合类,引入system.collections.generic命名空间,常用操作有count属性查看长度,add()添加,remove()去除,addrange()添加集合,clear()清空集合。
4、数组和list的核心区别
数组在c#中最早出现的。在内存中是连续存储的,所以它的索引速度非常快,而且赋值与修改元素也很简单。数组存在一些不足的地方。在数组的两个数据间插入数据是很麻烦的,而且在声明数组的时候必须指定数组的长度,数组的长度过长,会造成内存浪费,过段会造成数据溢出的错误。如果在声明数组时我们不清楚数组的长度,就会变得很麻烦。list是集合,集合元素的数量可以动态变化。增加、插入、删除元素很方便。
5、栈的理解
栈是一种特殊的线性表,仅能在线性表的一端操作,栈顶允许操作,栈底不允许操作。 栈的特点是:先进后出,或者说是后进先出,从栈顶放入元素的操作叫入栈,取出元素叫出栈。 栈的结构就像一个集装箱,越先放进去的东西越晚才能拿出来,所以,栈常应用于实现递归功能方面的场景,例如斐波那契数列。
6、队列的理解
队列与栈一样,也是一种线性表,不同的是,队列可以在一端添加元素,在另一端取出元素,也就是:先进先出。从一端放入元素的操作称为入队,取出元素为出队。使用场景:因为队列先进先出的特点,在多线程阻塞队列管理中非常适用。
7、链表的理解
链表是物理存储单元上非连续的、非顺序的存储结构,数据元素的逻辑顺序是通过链表的指针地址实现,每个元素包含两个结点,一个是存储元素的数据域 (内存空间),另一个是指向下一个结点地址的指针域。根据指针的指向,链表能形成不同的结构,例如单链表,双向链表,循环链表等。
优点:
a. 链表是很常用的一种数据结构,不需要初始化容量,可以任意加减元素;
b. 添加或者删除元素时只需要改变前后两个元素结点的指针域指向地址即可,所以添加,删除很快;
缺点:
a. 因为含有大量的指针域,占用空间较大;
b. 查找元素需要遍历链表来查找,非常耗时。
适用场景:
数据量较小,需要频繁增加,删除操作的场景
8、树的理解
树是一种数据结构,它是由n(n>=1)个有限节点组成一个具有层次关系的集合。把它叫做 “树” 是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
它具有以下的特点:
- a. 每个节点有零个或多个子节点;
- b. 没有父节点的节点称为根节点;
- c. 每一个非根节点有且只有一个父节点;
- d. 除了根节点外,每个子节点可以分为多个不相交的子树;
在日常的应用中,我们讨论和用的更多的是树的其中一种结构,就是二叉树。二叉树是树的特殊一种,具有如下特点:
- a. 每个结点最多有两颗子树,结点的度最大为2。
- b. 左子树和右子树是有顺序的,次序不能颠倒。
- c. 即使某结点只有一个子树,也要区分左右子树。
9、散列表的理解
散列表,也叫哈希表,是根据关键码和值 (key和value) 直接进行访问的数据结构,通过key和value来映射到集合中的一个位置,这样就可以很快找到集合中的对应元素。哈希表的应用场景很多,当然也有很多问题要考虑,比如哈希冲突的问题,如果处理的不好会浪费大量的时间,导致应用崩溃。
10、堆的理解
堆是一种比较特殊的数据结构,可以被看做一棵树的数组对象,具有以下的性质:
a. 堆中某个节点的值总是不大于或不小于其父节点的值;
b. 堆总是一棵完全二叉树;
c. 将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。
因为堆有序的特点,一般用来做数组中的排序,称为堆排序。
11、图的理解
图是由结点的有穷集合v和边的集合e组成。其中,为了与树形结构加以区别,在图结构中常常将结点称为顶点,边是顶点的有序偶对,若两个顶点之间存在一条边,就表示这两个顶点具有相邻关系。 按照顶点指向的方向可分为无向图和有向图: 图是一种比较复杂的数据结构,在存储数据上有着比较复杂和高效的算法,分别有邻接矩阵 、邻接表、十字链表、邻接多重表、边集数组等存储结构。
12、二叉树的所有遍历方式的原理及优缺点
前序遍历,先访问根节点在访问左节点在访问右节点。
中序遍历,先访问左节点在访问根节点在访问右节点。
后序遍历,先访问左节点在访问右节点在访问根节点。
前中后代表的是访问根节点的时序。采用递归方式和非递归方式。前者优点是直观,编写起来简单,缺点是但其开销也比较大。非递归形式开销小,但编写复杂。
13、 设计模式相关
主要使用:工厂模式、代理模式、策略模式、观察者模式、单例模式等
- a. 工厂模式:
简单工厂模式解决的问题是如何去实例化一个合适的对象。 简单工厂模式的核心思想就是:有一个专门的类来负责创建实例的过程。凡是出现了大量的产品需要创建,并且具有共同的接口时,可以通过工厂方法模式进行创建。比如说写技能是一系列类,那么就可以使用工厂模式创建。 - b. 代理模式:
一个是真正的你要访问的对象(目标类),一个是代理对象,真正对象与代理对象实现同一个接口,先访问代理类再访问真正要访问的对象。代理模式就是多一个代理类出来,替原对象进行一些操作,比如我们在租房子的时候回去找中介,为什么呢?因为你对该地区房屋的信息掌握的不够全面,希望找一个更熟悉的人去帮你做,此处的代理就是这个意思。再如我们有的时候打官司,我们需要请律师,因为律师在法律方面有专长,可以替我们进行操作,表达我们的想法。
代理模式的应用场景:如果已有的方法在使用的时候需要对原有的方法进行改进,此时有两种办法:
法一:修改原有的方法来适应。这样违反了“对扩展开放,对修改关闭”的原则。
法二:就是采用一个代理类调用原有的方法,且对产生的结果进行控制。这种方法就是代理模式。 - c. 策略模式:
定义一系列算法,并将每个算法封装起来,使他们可以相互替换,且算法的变化不会影响到使用算法的客户。策略模式的决定权在用户,系统本身提供不同算法的实现,新增或者删除算法,对各种算法做封装。因此,策略模式多用在算法决策系统中,外部用户只需要决定用哪个算法即可。 - d. 观察者模式:
类似于邮件订阅和rss订阅,当我们浏览一些博客或wiki时,经常会看到rss图标,就这的意思是,当你订阅了该文章,如果后续有更新,会及时通知你。其实,简单来讲就一句话:当一个对象变化时,其它依赖该对象的对象都会收到通知,并且随着变化,对象之间是一种一对多的关系。 - e. 单例对象(singleton)是一种常用的设计模式。
在c#应用中,单例对象能保证在一个clr中,该对象只有一个实例存在。这样的模式有几个好处:
(1)某些类创建比较频繁,对于一些大型的对象,这是一笔很大的系统开销。
(2)省去了new操作符,降低了系统内存的使用频率,减轻gc压力。
(3)有些类如交易所的核心交易引擎,控制着交易流程,如果该类可以创建多个的话,系统完全乱了。(比如一个军队出现了多个司令员同时指挥,肯定会乱成一团),所以只有使用单例模式,才能保证核心交易服务器独立控制整个流程。
14、说出面向对象的设计原则,并分别简述它们的含义。
a. 单一职责原则 (the single responsiblity principle,简称 srp):一个类,最好只做一件事,只有一个引起它的变化。
b. 开放-封闭原则 (the open-close principle,简称 ocp):对于扩展是开放的,对于更改是封闭的
c. liskov 替换原则(the liskov substitution principle,简称 lsp):子类必须能够替换其基类。
d. 依赖倒置原则 (the dependency inversion pricinple, 简称 dip):依赖于抽象
e. 接口隔离原则 (the interface segregation principle,简称 isp):使用多个小的专门的接口,而不要使用一个大的总接口。
15、观察者模式的深入理解?
观察者模式:一对多的关系,当被观察这发生改变时会通知所有观察者。让双方都依赖于抽象,使得各自变化不会影响另一方。
16、mvc模式
用一种业务逻辑、数据、界面显示分离的方法组织代码,将业务逻辑聚集到一个部件里面,在改进和个性化定制界面及用户交互的同时,不需要重新编写业务逻辑。经典mvc模式中,m是指业务模型,v是指用户界面,c则是控制器,使用mvc的目的是将m和v的实现代码分离,从而使同一个程序可以使用不同的表现形式。其中,view的定义比较清晰,就是用户界面。
💞算法
想锻炼算法相关内容注意推荐去刷题网站勤加练习,如力扣、牛客网等。
1.十大排序简述
十种常见排序算法可以分为两大类:
- 比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破o(nlogn),因此也称为非线性时间比较类排序。
- 非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此也称为线性时间非比较类排序。
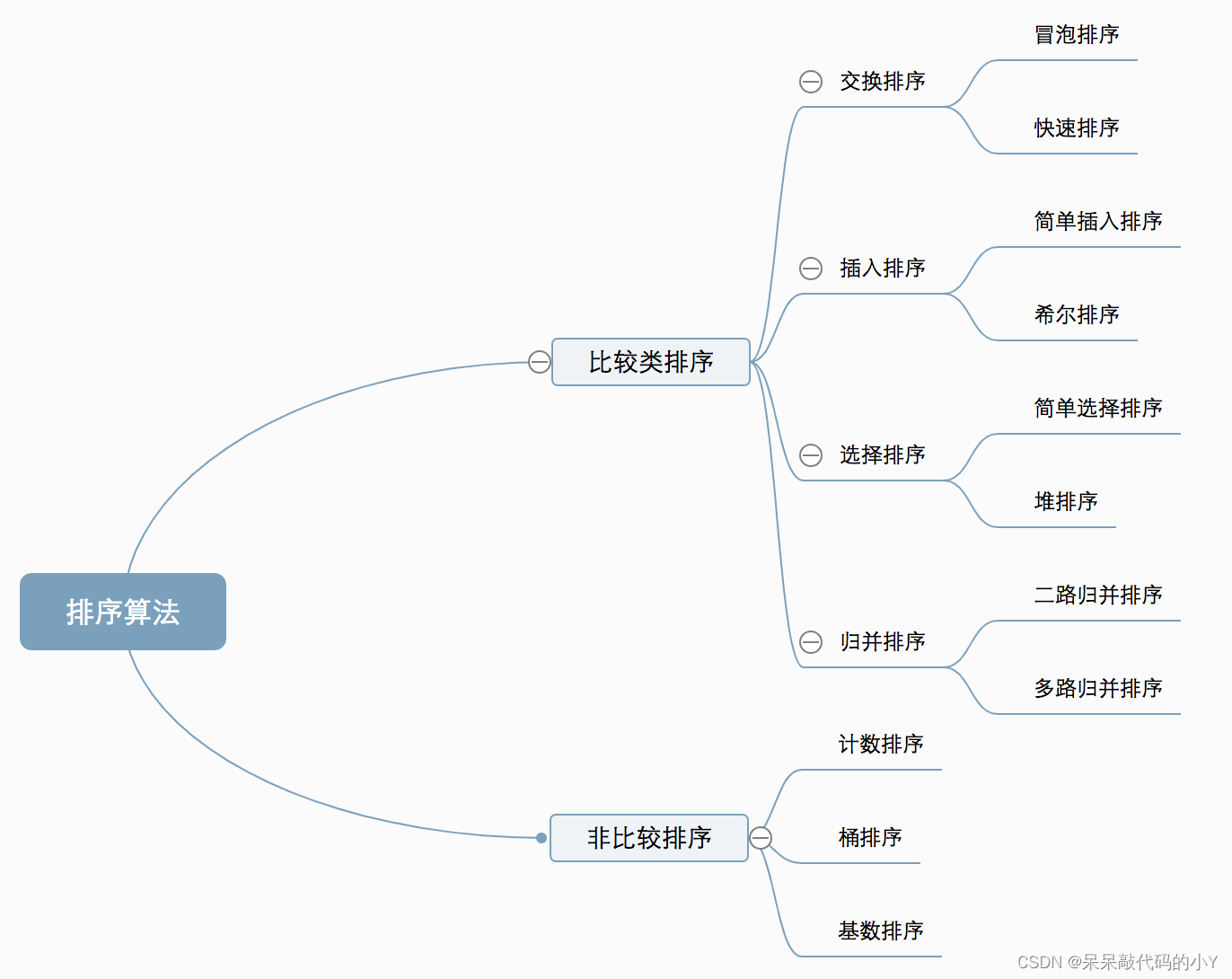
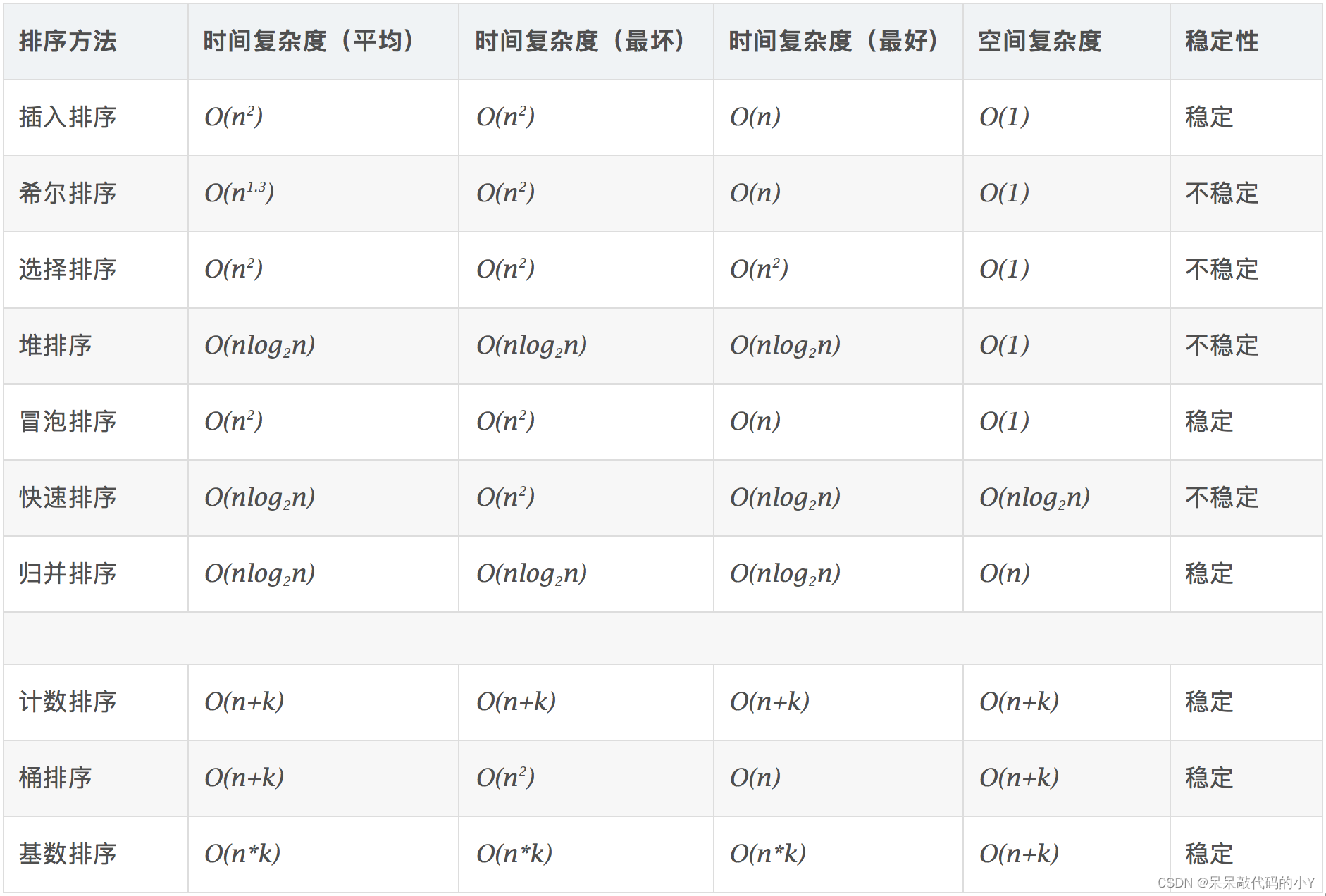
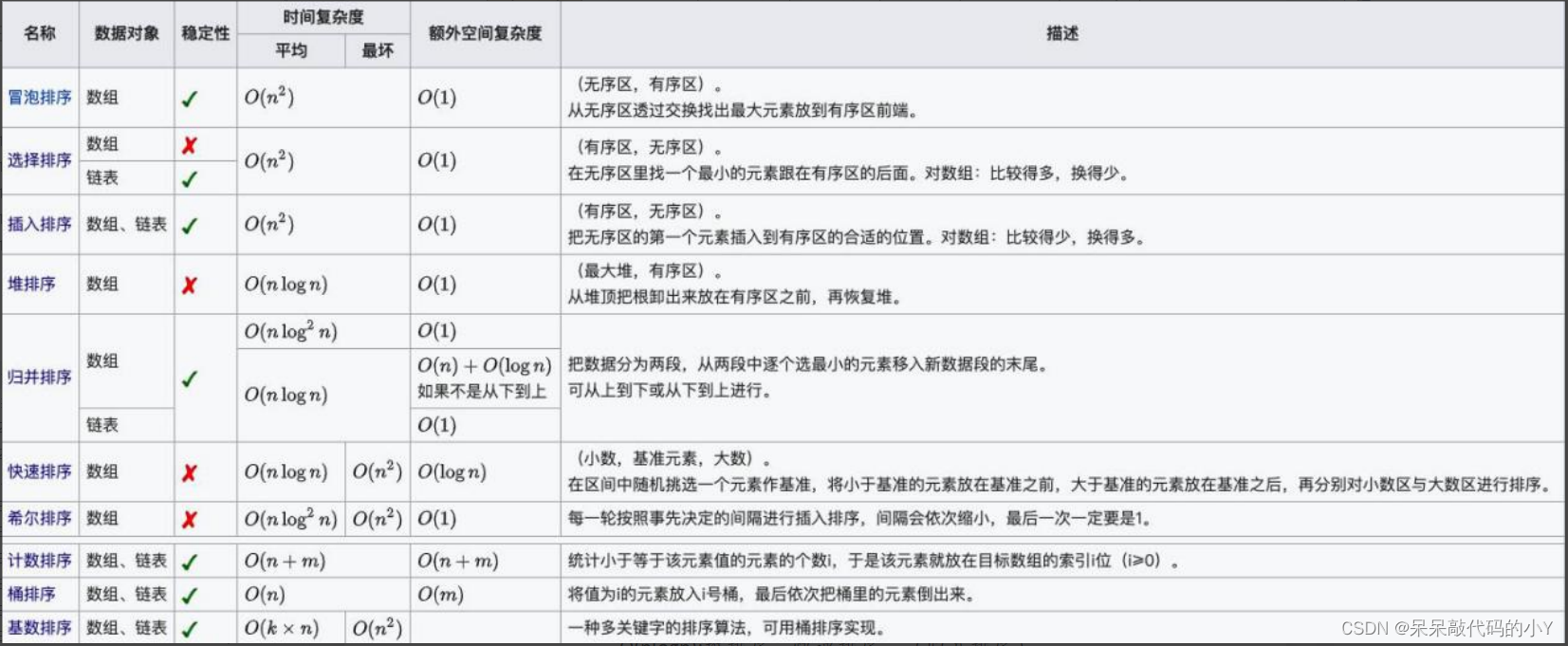
- 冒泡排序(bubble sort)
冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。 - 选择排序(selection sort)
选择排序(selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。 - 插入排序(insertion sort)
插入排序(insertion-sort)的算法描述是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。 - 希尔排序(shell sort)
1959年shell发明,第一个突破o(n2)的排序算法,是简单插入排序的改进版。它与插入排序的不同之处在于,它会优先比较距离较远的元素。希尔排序又叫缩小增量排序。 - 归并排序(merge sort)
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(divide and conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。 - 快速排序(quick sort)
快速排序的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。 - 堆排序(heap sort)
堆排序(heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。 - 计数排序(counting sort)
计数排序不是基于比较的排序算法,其核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。 作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。 - 桶排序(bucket sort)
桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。桶排序 (bucket sort)的工作的原理:假设输入数据服从均匀分布,将数据分到有限数量的桶里,每个桶再分别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排)。 - 基数排序(radix sort)
基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。
2. 请写一个方法判断一个整数是奇数还是偶数。
常规答案
与2取余,若为0则是偶数,否则为奇数。
public static bool iseven(int number)
{
return ((number % 2) == 0);
}
进阶答案
检测数字的二进制最低位是否为0。将最低位和1相与,如果结果为0,则为偶数,否则为奇数。
如奇数3和1位与,实际上是
00000000 00000000 00000000 00000011
& 00000000 00000000 00000000 00000001
---------------------------------------------
00000000 00000000 00000000 00000001
再比如偶数6和1位与,实际上是
00000000 00000000 00000000 00000110
& 00000000 00000000 00000000 00000001
---------------------------------------------
00000000 00000000 00000000 00000000
判断一个整数是奇数还是偶数
/** <summary>
/// 判断一个整数是否是偶数
/// </summary>
/// <param name="number">传入的整数</param>
/// <returns>如果是偶数,返回true,否则为false</returns>
public static bool iseven(int number)
{
return ((number & 1) == 0);
}
/** <summary>
/// 判断一个整数是否是奇数
/// </summary>
/// <param name="number">传入的整数</param>
/// <returns>如果是奇数,返回true,否则为false</returns>
public static bool isodd(int number)
{
return !iseven(number);
}
3. 请写一个方法判断一个整数是否是2的n次方。
常规答案
利用位运算进行判断,将一个数通过不断位右移,最终结果若为1则为true,否则为false。
判断一个整数是否是2的n次方
public static bool ispower(int number)
{
if (number <= 0)
{
return false;
}
while (true)
{
if (number == 1)
{
return true;
}
//如果是奇数
if ((number & 1) == 1)
{
return false;
}
//右移一位
number >>= 1;
}
}
进阶答案
2的n次方其二进制表示只有1个1,如整数8,其二进制表示形式是00001000,减去1后为00000111,让这两者进行位与的结果刚好是0则为true,否则就是falsez。
判断一个整数是否是2的n次方
public static bool ispower(int number)
{
if (number <= 0)
{
return false;
}
if ((number & (number - 1)) == 0)
{
return true;
}
return false;
}
4. 对字节变量,其二进制表示法中求有多少个1,如 00101010则返回值为 3,也是要求效率最高。
代码
private static int getcountgroupbyone(int data)
{
int count = 0;
if (data == 0)
{
}
else if (data > 0)
{
while (data > 0)
{
data &= (data - 1);
count++;
}
}
else
{
int minvalue = -0x40000001;
while (data > minvalue)
{
data &= (data - 1);
count++;
}
count++;
}
return count;
}
5. 100万的数据选出前1万大的数
利用堆排序、小顶堆实现。
先拿10000个数建堆,然后一次添加剩余元素,如果大于堆顶的数(10000中最小的),将这个数替换堆顶,并调整结构使之仍然是一个最小堆,这样遍历完后,堆中的10000个数就是所需的最大的10000个。建堆时间复杂度是o(mlogm),算法的时间复杂度为o (nmlogm)(n为100,m为10000)。
优化的方法:分治。可以把所有10亿个数据分组存放,比如分别放在1000个文件中。这样处理就可以分别在每个文件的10^6个数据中找出最大的10000个数,合并到一起在再找出1000*10000中的最终的结果。
6. 二分查找
算法思路:假设目标值在闭区间[l, r]中,每次将区间长度缩小一半,当l = r时,我们就找到了目标值。
1.当我们将区间[l, r]划分成[l, mid]和[mid + 1, r]时,其更新操作是r = mid或者l = mid + 1;,计算mid时不需要加1。(常用)
int bsearch_1(int 1, int r)
{
while (l <r)
{
int mid = l +r >> 1;
if(check(mid)) r = mid;
else l = mid + 1;
}
return l;
}
2.当我们将区间[l, r]划分成[l, mid - 1]和[mid, r]时,其更新操作是r = mid - 1或者l = mid;,此时为了防止死循环,计算mid时需要加1。
int bsearch_2(int 1, int r)
{
while (l <r)
{
int mid = l + r +1 >> 1;
if(check(mid)) l = mid;
else r = mid - 1;
}
return l;
}
3.代码里的if语句,若变成一个bool函数带入对应的l,r,mid,array等,在函数里面继续二分查找,即可变成“二分答案”。
7. bfs(广度优先搜索)
bfs从根节点开始搜索,并根据树级别模式探索所有邻居根。它使用队列数据结构来记住下一个节点访问。
1.如果不需要确定当前遍历到了哪一层
while queue 不空:
cur = queue.pop()
for 节点 in cur的所有相邻节点:
if 该节点有效且未访问过:
queue.push(该节点)
2.如果要确定当前遍历到了哪一层,bfs 模板如下。 这里增加了 level 表示当前遍历到二叉树中的哪一层了,也可以理解为在一个图中,现在已经走了多少步了。size 表示在当前遍历层有多少个元素,也就是队列中的元素数,我们把这些元素一次性遍历完,即把当前层的所有元素都向外走了一步。
level = 0
while queue 不空:
size = queue.size()
while (size --)
{
cur = queue.pop()
for 节点 in cur的所有相邻节点:
if 该节点有效且未访问过:
queue.push(该节点)
}
level++;
8.dfs(深度优先搜索)
注意搜索的顺序;当搜到叶子节点(递归结束)时就回溯,回退一步看一步。
dfs从根节点开始搜索,并从根节点尽可能远地探索这些节点。使用堆栈数据结构来记住下一个节点访问。
类似于树的 先序遍历

9. 请写出求斐波那契数列任意一位的值的算法
static int fn(int n) {
if (n <= 0) {
throw new argumentoutofrangeexception();
}
if (n == 1||n==2)
{
return 1;
}
return checked(fn(n - 1) + fn(n - 2)); // when n>46 memory will overflow
}
10. 下列代码在运行中会产生几个临时对象?
string a = new string("abc");
a = (a.toupper() +"123").substring(0,2);
实在c#中第⼀⾏是会出错的(java中倒是可⾏)。
应该这样初始化:
string b = new string(new char[] {'a','b','c'});
三个临时对象:abc、abc、ab
11. 怎么判断一个点是否在直线上
已知点p(x,y),以及直线上的两点a(x1,y1)、b(x2,y2),可以通过计算向量ap与向量ab的叉乘是否等于0来计算点p是否在直线ab上。
知识点:叉乘
/// <summary>
/// 2d叉乘
/// </summary>
/// <param name="v1">点1</param>
/// <param name="v2">点2</param>
/// <returns></returns>
public static float crossproduct2d(vector2 v1,vector2 v2)
{
//叉乘运算公式 x1*y2 - x2*y1
return v1.x * v2.y - v2.x * v1.y;
}
/// <summary>
/// 点是否在直线上
/// </summary>
/// <param name="point"></param>
/// <param name="linestart"></param>
/// <param name="lineend"></param>
/// <returns></returns>
public static bool ispointonline(vector2 point, vector2 linestart, vector2 lineend)
{
float value = crossproduct2d(point - linestart, lineend - linestart);
return mathf.abs(value) <0.0003 /* 使用 mathf.approximately(value,0) 方式,在斜线上好像无法趋近为0*/;
}
12. 判断点是否在线段上
已知点p(x,y),以及线段a(x1,y1),b(x2,y2)。
1)方法一
可以进行下面两部来判断点p是否在线段ab上:
(1)点是否在线段ab所在的直线上(点是否在直线上)
(2)点是否在以线段ab为对角线的矩形上,来忽略点在线段ab延长线上
/// <summary>
/// 2d叉乘
/// </summary>
/// <param name="v1">点1</param>
/// <param name="v2">点2</param>
/// <returns></returns>
public static float crossproduct2d(vector2 v1,vector2 v2)
{
//叉乘运算公式 x1*y2 - x2*y1
return v1.x * v2.y - v2.x * v1.y;
}
/// <summary>
/// 点是否在直线上
/// </summary>
/// <param name="point"></param>
/// <param name="linestart"></param>
/// <param name="lineend"></param>
/// <returns></returns>
public static bool ispointonline(vector2 point, vector2 linestart, vector2 lineend)
{
float value = crossproduct2d(point - linestart, lineend - linestart);
return mathf.abs(value) <0.0003 /* 使用 mathf.approximately(value,0) 方式,在斜线上好像无法趋近为0*/;
}
/// <summary>
/// 点是否在线段上
/// </summary>
/// <param name="point"></param>
/// <param name="linestart"></param>
/// <param name="lineend"></param>
/// <returns></returns>
public static bool ispointonsegment(vector2 point, vector2 linestart, vector2 lineend)
{
//1.先通过向量的叉乘确定点是否在直线上
//2.在拍段点是否在指定线段的矩形范围内
if (ispointonline(point,linestart,lineend))
{
//点的x值大于最小,小于最大x值 以及y值大于最小,小于最大
if (point.x >= mathf.min(linestart.x, lineend.x) && point.x <= mathf.max(linestart.x, lineend.x) &&
point.y >= mathf.min(linestart.y, lineend.y) && point.y <= mathf.max(linestart.y, lineend.y))
return true;
}
return false;
}
👥总结
- 全网最全的
unity性能优化面试题都在这里了,希望本篇文章能够让你在面试关卡如鱼得水得到自己想要的工作。 - 看完觉得有用别忘了点赞收藏哦,如果觉得哪个方面的内容不够丰富欢迎在评论区指出!
- 如果你的unity基础知识还不够熟练,也欢迎来 『unity精品学习专栏⭐️』 和『unity 实战100例 教程⭐️』继续学习哦!
- 如果你还有更好的面试题,欢迎在评论区提出,会整理到文章中去哦!!!

资料白嫖,技术互助

| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 unity系统学习专栏 🧡 | 入门级 | 本专栏从unity入门开始学习,快速达到unity的入门水平 |
| 💛 unity实战类项目 💛 | 进阶级 | 计划制作unity的 100个实战案例!助你进入unity世界,争取做最全的unity原创博客大全。 |
| 难度偏高 | 分享学习一些unity成品的游戏demo和其他语言的小游戏! | |
| 互助/吹水 | 数万人游戏爱好者社区,聊天互助,白嫖奖品 | |
| 💙 unity100个实用技能💙 | unity查漏补缺 | 针对一些unity中经常用到的一些小知识和技能进行学习介绍,核心目的就是让我们能够快速学习unity的知识以达到查漏补缺 |

![[HTML]Web前端开发技术21(HTML5、CSS3、JavaScript )HTML5 基础与CSS3 应用,border-radius,box-shadow,transform——喵喵画网页](https://images.3wcode.com/3wcode/20240728/s_0_202407281959312227.png)
发表评论