hive1.2底层使用mapreduce作为计算引擎
hive1.2安装方法
解压apache-hive-1.2.2-bin.tar.gz到/usr/local
添加hive-site.xml到/usr/local/apache-hive-1.2.2-bin/conf
里面的内容是
<configuration>
<property>
<name>javax.jdo.option.connectionurl</name>
<value>jdbc:mysql://192.168.56.103:3306/hive</value>
<description>jdbc connect string for a jdbc metastore</description>
</property>
<property>
<name>javax.jdo.option.connectiondrivername</name>
<value>com.mysql.jdbc.driver</value>
<description>driver class name for a jdbc metastore</description>
</property>
<property>
<name>javax.jdo.option.connectionusername</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.connectionpassword</name>
<value>az63091919</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive3/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<!--如果使用spark集成过hive,要设置元数据检查忽略-->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>
enforce metastore schema version consistency.
true: verify that version information stored in metastore matches with one from hive jars. also disable automatic
schema migration attempt. users are required to manully migrate schema after hive upgrade which ensures
proper metastore schema migration. (default)
false: warn if the version information stored in metastore doesn't match with one from in hive jars.
</description>
</property>
<!--指定tez引擎使用的yarn队列-->
<property>
<name>tez.queue.name</name>
<value>hivequeue</value>
</property>
<!--使用mapreduce引擎使用的yarn队列-->
<property>
<name>mapreduce.job.queuename</name>
<value>hivequeue</value>
</property>
</configuration>
编辑hive-env.sh
export hadoop_home=/usr/local/hadoop-2.8.5
export hive_conf=/usr/local/apache-hive-1.2.2-bin/conf
export hive_aux_jars_path=/usr/local/apahce-hive-1.2.2-bin/conf
代表mysql连接地址,使用mysql驱动,mysql用户名,mysql密码
拷贝mysql的驱动jar包到/usr/local/apache-hive-1.2.2-bin/lib目录下
配置hadoop_home到/etc/profile中去
启动hdfs start-dfs.sh 访问http://node2:50070确认hdfs正常工作
启动yarn start-yarn.sh 访问http://node1:8088确认yarn正常工作、
进入node启动yarn的backupmaster yarn-daemon.sh start resourcemanager
进入mysql mysql -uroot -paz63091919
drop database hive;
create database hive;
alter database hive character set latin1;
初始化hive在mysql中的元数据
bin/schematool -dbtype mysql -initschema
启动hive
bin/hive
在linux的当前用户目录中,编辑一个.hiverc文件,将参数写入其中
set hive.cli.print.header=true; //显示表头
set hive.cli.print.current.db=true; //显示当前正在使用的库名
--------------------------------------------
-------------------------------------------
hive metastore原理及配置
有三种模式
内嵌模式:hive服务和metastore服务运行在同一个进程中,derby服务也运行在该进程中.内嵌模式使用的是内嵌的derby数据库来存储元数据,也不需要额外起metastore服务。
本地模式:不再使用内嵌的derby作为元数据的存储介质,而是使用其他数据库比如mysql来存储元数据。hive服务和metastore服务运行在同一个进程中,mysql是单独的进程,可以同一台机器,也可以在远程机器上。这种方式是一个多用户的模式,运行多个用户client连接到一个数据库中。这种方式一般作为公司内部同时使用hive。每一个用户必须要有对mysql的访问权利,即每一个客户端使用者需要知道mysql的用户名和密码才行。
hive-site.xml中添加
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
远程模式
hive服务和metastore在不同的进程内,可能是不同的机器,该模式需要将hive.metastore.local设置为false,将hive.metastore.uris设置为metastore服务器url,
远程元存储需要单独起metastore服务,然后每个客户端都在配置文件里配置连接到该metastore服务。将metadata作为一个单独的服务进行启动。各种客户端通过beeline来连接,连接之前无需知道数据库的密码。
仅连接远程的mysql并不能称之为“远程模式”,是否远程指的是metastore和hive服务是否在同一进程内.
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop2:9083</value>
</property>
启动metastore服务
nohup bin/hive --service metastore &
启动hiveserver服务
nohup bin/hive --service hiveserver2 &
-----------------------------------------
hive启动指定执行的yarn队列
hive --hiveconf mapreduce.job.queuename=queue
或者在hive启动后使用语句也能改变
hive> set mapreduce.job.queuename=queue;
-------------------------------------
把hive启动为一个服务
在后台启动hive服务
nohup hiveserver2 1>/dev/null 2>&1 &
默认监听10000端口
启动hive客户端beeline
然后输入!connect jdbc:hive2://node4:10000
输入hdfs用户 root
密码直接回车
bin/beeline -u jdbc:hive2://node4:10000 -n root
----------------------------------------------------------------------------------------------------------------
脚本化运行hive
hive -e "select * from user"
vi t_order_etl.sh
#!/bin/bash
hive -e "select * from db_order"
hive -e "select * from t_user"
hql="create table demo as select * from db_order"
hive -e "$hql"
或者把sql写在hql文件里,用hive -f xxx.hql执行文件
vi xxx.hql
select * from db_order;
select * from t_user;
----------------------------------------------------------------------------------------------------------------
show databases; //显示数据库
create database big24; //创建数据库
这时hdfs目录下会产生/user/hive/warehouse/big24.db这个目录
use big24; //使用big24数据库
create table t_big24(id int,name string,age int,sex string); //创建表
这时hdfs目录下会产生 /user/hive/warehouse/big24.db/t_big24这个目录
linux下输入hive默认分隔符^a '\001' 在vi编辑器下先按ctrl+v然后ctrl+a
---------------------------------------------------------------------------------------------------------------
hive建表语句
create table t_order(id string,create_time string,amount float,uid string)
row format delimited
fields terminated by ',';
指定数据文件的字段分隔符为逗号,
删除表
drop table t_order
--------------------------------------------------------------------------------------------------------
hive内部表和外部表
外部表:hdfs的表目录由用户自己指定
create external table t_access(ip string,url string,access_time string)
row format delimited
fields terminated by ','
location '/access/log';
指定的目录
如果删除外部表,外部表的目录和数据文件不会被删除
------------------------------
内部表:hive自己在hdfs中维护数据目录
如果删除内部表,数据目录和数据文件一起被删除
--------------------------------------------------------------------------------------------------------
分区表
/user/hive/warehouse/t_pv_log/day=2017-09-16/
/day=2017-09-17/
如果想查2017-09-16的数据,就去对应目录查
如果想查全部的数据就对应t_pv_log目录
create table t_pv_log(ip string,url string,commit_time string)
partitioned by(day string)
row format delimited
fields terminated by ',';
分区标志字段在表查询时也会返回,分区字段不能是表定义中已存在的字段
从本地路径导入数据,注意要是hiveserver运行的机器
load data local inpath '/root/hivetest/pv.log' into table t_pv_log partition(day='20170915')
如果文件不在本地而在hdfs中
load data inpath '/access.log.2017-08-06.log' into table t_access partition(dt='20170806'); 但是hdfs中的文件会移动而不是复制
---------------------------------------------------------------------------------------------------------
创建一张和已存在表表结构相同的表
create table t_request_2 like t_request; //创建一张空表内部表,只复制了t_request的结构
复制表字段和数据
create table t_request_3
as
select * from t_request
----------------------------------------------------------------------------------------------------------
老段hive第二天练习数据
create table t_a(name string,numb int)
row format delimited
fields terminated by ',';
create table t_b(name string,nick string)
row format delimited
fields terminated by ',';
vi /root/a.txt
a,1
b,2
c,3
d,4
vi /root/b.txt
a,xx
b,yy
d,zz
e,pp
load data local inpath '/root/a.txt' into table t_a;
load data local inpath '/root/b.txt' into table t_b;
1.内连接
select * from t_a inner join t_b;
得
+-----------+-----------+-----------+-----------+--+
| t_a.name | t_a.numb | t_b.name | t_b.nick |
+-----------+-----------+-----------+-----------+--+
| a | 1 | a | xx |
| b | 2 | a | xx |
| c | 3 | a | xx |
| d | 4 | a | xx |
| a | 1 | b | yy |
| b | 2 | b | yy |
| c | 3 | b | yy |
| d | 4 | b | yy |
| a | 1 | d | zz |
| b | 2 | d | zz |
| c | 3 | d | zz |
| d | 4 | d | zz |
| a | 1 | e | pp |
| b | 2 | e | pp |
| c | 3 | e | pp |
| d | 4 | e | pp |
+-----------+-----------+-----------+-----------+--+
------------------------------------------------------
指定条件的内连接
select * from t_a a inner join t_b b on a.name = b.name;
或
select * from t_a a inner join t_b b where a.name = b.name;
得
+---------+---------+---------+---------+--+
| a.name | a.numb | b.name | b.nick |
+---------+---------+---------+---------+--+
| a | 1 | a | xx |
| b | 2 | b | yy |
| d | 4 | d | zz |
+---------+---------+---------+---------+--+
----------------------------------------------------------
左外连接
select
a.*,b.*
from
t_a a left outer join t_b b;
得
+---------+---------+---------+---------+--+
| a.name | a.numb | b.name | b.nick |
+---------+---------+---------+---------+--+
| a | 1 | a | xx |
| a | 1 | b | yy |
| a | 1 | d | zz |
| a | 1 | e | pp |
| b | 2 | a | xx |
| b | 2 | b | yy |
| b | 2 | d | zz |
| b | 2 | e | pp |
| c | 3 | a | xx |
| c | 3 | b | yy |
| c | 3 | d | zz |
| c | 3 | e | pp |
| d | 4 | a | xx |
| d | 4 | b | yy |
| d | 4 | d | zz |
| d | 4 | e | pp |
+---------+---------+---------+---------+--+
select a.*,b.* from
t_a a left outer join t_b b on a.name = b.name;
得
+---------+---------+---------+---------+--+
| a.name | a.numb | b.name | b.nick |
+---------+---------+---------+---------+--+
| a | 1 | a | xx |
| b | 2 | b | yy |
| c | 3 | null | null |
| d | 4 | d | zz |
+---------+---------+---------+---------+--+
-----------------------------------------------
右外连接
select a.*,b.* from t_a a right outer join t_b b;
得
+---------+---------+---------+---------+--+
| a.name | a.numb | b.name | b.nick |
+---------+---------+---------+---------+--+
| a | 1 | a | xx |
| b | 2 | a | xx |
| c | 3 | a | xx |
| d | 4 | a | xx |
| a | 1 | b | yy |
| b | 2 | b | yy |
| c | 3 | b | yy |
| d | 4 | b | yy |
| a | 1 | d | zz |
| b | 2 | d | zz |
| c | 3 | d | zz |
| d | 4 | d | zz |
| a | 1 | e | pp |
| b | 2 | e | pp |
| c | 3 | e | pp |
| d | 4 | e | pp |
+---------+---------+---------+---------+--+
select a.*,b.* from t_a a right outer join t_b b on a.name = b.name;
得
+---------+---------+---------+---------+--+
| a.name | a.numb | b.name | b.nick |
+---------+---------+---------+---------+--+
| a | 1 | a | xx |
| b | 2 | b | yy |
| d | 4 | d | zz |
| null | null | e | pp |
+---------+---------+---------+---------+--+
-------------------------------------------------
全外连接
select a.*,b.* from t_a a full outer join t_b b on a.name=b.name;
得
+---------+---------+---------+---------+--+
| a.name | a.numb | b.name | b.nick |
+---------+---------+---------+---------+--+
| a | 1 | a | xx |
| b | 2 | b | yy |
| c | 3 | null | null |
| d | 4 | d | zz |
| null | null | e | pp |
+---------+---------+---------+---------+--+
------------------------------------------------
左半连接(只返回左表的数据)
select a.* from
t_a a left semi join t_b b on a.name=b.name;
+---------+---------+--+
| a.name | a.numb |
+---------+---------+--+
| a | 1 |
| b | 2 |
| d | 4 |
+---------+---------+--+
--------------------------------------------------
select upper("abc");
将字符串变成大写
--------------------------------------------------
--分组聚合查询
select upper("abc");
--针对每一行进行运算
select ip,upper(url),access_time
from t_pv_log;
-- 求每条url的访问总次数
-- 该表达式是对分好组的数据进行逐组运算
select
url,count(1) as cnts
from t_pv_log
group by url;
-- 求每个url的访问者中ip最大的
select url,max(ip) as ip
from t_pv_log
group by url;
--求每个用户访问同一个页面的所有记录中,时间最晚的一条
select ip,url,max(access_time)
from t_pv_log
group by ip,url;
--------------------------------------------------------------------------------
分组聚合示例
create table t_access(ip string,url string,access_time string)
partitioned by(dt string)
row format delimited
fields terminated by ',';
vi access.log.0804
192.168.33.3,http://www.edu360.cn/stu,2017-08-04 15:30:20
192.168.33.3,http://www.edu360.cn/teach,2017-08-04 15:35:20
192.168.33.4,http://www.edu360.cn/stu,2017-08-04 15:30:20
192.168.33.4,http://www.edu360.cn/job,2017-08-04 16:30:20
192.168.33.5,http://www.edu360.cn/job,2017-08-04 15:40:20
vi access.log.0805
192.168.33.3,http://www.edu360.cn/stu,2017-08-05 15:30:20
192.168.44.3,http://www.edu360.cn/teach,2017-08-05 15:35:20
192.168.33.44,http://www.edu360.cn/stu,2017-08-05 15:30:20
192.168.33.46,http://www.edu360.cn/job,2017-08-05 16:30:20
192.168.33.55,http://www.edu360.cn/job,2017-08-05 15:40:20
vi access.log.0806
192.168.133.3,http://www.edu360.cn/register,2017-08-06 15:30:20
192.168.111.3,http://www.edu360.cn/register,2017-08-06 15:35:20
192.168.34.44,http://www.edu360.cn/pay,2017-08-06 15:30:20
192.168.33.46,http://www.edu360.cn/excersize,2017-08-06 16:30:20
192.168.33.55,http://www.edu360.cn/job,2017-08-06 15:40:20
192.168.33.46,http://www.edu360.cn/excersize,2017-08-06 16:30:20
192.168.33.25,http://www.edu360.cn/job,2017-08-06 15:40:20
192.168.33.36,http://www.edu360.cn/excersize,2017-08-06 16:30:20
192.168.33.55,http://www.edu360.cn/job,2017-08-06 15:40:20
load data local inpath '/root/access.log.0804' into table t_access partition(dt='2017-08-04');
load data local inpath '/root/access.log.0805' into table t_access partition(dt='2017-08-05');
load data local inpath '/root/access.log.0806' into table t_access partition(dt='2017-08-06');
--查看表的分区
show partitions t_access;
--求8月4号以后,每天http://www.edu360.cn/job这个页面总访问次数,及访问者中ip地址最大的
select
count(1) cnts,max(ip),dt
from t_access
where url = 'http://www.edu360.cn/job'
and dt > '2017-08-04'
group by dt;
得
+-------+----------------+-------------+--+
| cnts | _c1 | dt |
+-------+----------------+-------------+--+
| 2 | 192.168.33.55 | 2017-08-05 |
| 3 | 192.168.33.55 | 2017-08-06 |
+-------+----------------+-------------+--+
或者在group by里过滤
select
count(1) cnts,max(ip) ip,dt
from t_access
where url = 'http://www.edu360.cn/job'
group by dt having dt > '2017-08-04';
--求8月4号以后,每天每个页面总访问次数,及访问那个页面最大的ip值
select
count(1) cnts,url,max(ip),dt
from t_access
group by dt,url having dt > '2017-08-04';
得
+-------+---------------------------------+----------------+-------------+--+
| cnts | _c1 | _c2 | dt |
+-------+---------------------------------+----------------+-------------+--+
| 2 | http://www.edu360.cn/job | 192.168.33.55 | 2017-08-05 |
| 2 | http://www.edu360.cn/stu | 192.168.33.44 | 2017-08-05 |
| 1 | http://www.edu360.cn/teach | 192.168.44.3 | 2017-08-05 |
| 3 | http://www.edu360.cn/excersize | 192.168.33.46 | 2017-08-06 |
| 3 | http://www.edu360.cn/job | 192.168.33.55 | 2017-08-06 |
| 1 | http://www.edu360.cn/pay | 192.168.34.44 | 2017-08-06 |
| 2 | http://www.edu360.cn/register | 192.168.133.3 | 2017-08-06 |
+-------+---------------------------------+----------------+-------------+--+
--求8月4号以后,每天每个页面总访问次数,及访问那个页面最大的ip值,并且上述查询结果中总访问次数大于2的记录
select a.* from
(select
count(1) cnts,max(url) url,max(ip) ip,dt
from t_access
group by dt,url having dt > '2017-08-04') a
where a.cnts > 2;
得
+---------+---------------------------------+----------------+-------------+--+
| a.cnts | a.url | a.ip | a.dt |
+---------+---------------------------------+----------------+-------------+--+
| 3 | http://www.edu360.cn/excersize | 192.168.33.46 | 2017-08-06 |
| 3 | http://www.edu360.cn/job | 192.168.33.55 | 2017-08-06 |
+---------+---------------------------------+----------------+-------------+--+
或者
select
count(1) cnts,max(url) url,max(ip) ip,dt
from t_access
group by dt,url having dt > '2017-08-04' and cnts > 2;
-----------------------------------------------------------------------------------------------
hive中的数据类型
数字类型
tinyint 1byte -128到127
smallint 2byte -32768to32767 char
int
bigint long
float
double
日期类型
timestamp 长整型时间戳
date yyyy-mm-dd之类
字符串类型
string
varchar
char
混杂类型
boolean
binary 二进制
复合数据类型
arr数组
战狼2,吴京:龙母:刘亦菲,2017-08-16
create table t_movie(moive_name string,actors array<string>,first_show date)
row format delimited fields terminated by ','
collection items terminated by ':';
select movie_name,actors[0],first_show from t_movie;
-----------------------
array_contains函数
select movie_name,actors,first_show
from t_movie
where array_contains(actors,'吴刚');
在hiveonspark中是array_contains
-----------------------
size函数
select movie_name,actors,first_time,size(actors)
from t_movie;
------------------------------------------------------------------------
map数据类型
有如下数据
1,zhangsan,father:xiaoming#mother:xiaohuang#brother:xiaoxu,28
create table t_user(id int,name string,family_members map<string,string>,age int)
row format delimited fields terminated by ','
collection items terminated by '#'
map keys terminated by ':'
select id,name,family_members['father'],age
from t_user;
--------------------
map_keys函数,查出key的iter
select id,name,map_keys(family_members) as relations,age from t_user;
--------------------
map_values函数,查出value的iter
select id,name,map_values(family_members),age from t_family;
--------------------
--查出每个人的亲人数量
select id,name,size(family_members),age from t_family;
--------------------
--查出所有拥有兄弟的人
select id,name,age,family_members['brother']
from t_family
where array_contains(map_keys(family_members),'brother')
----------------------------------------------------------------------------------------
struct数据类型
有如下数据类型
1,zhangsan,18:male:beijing
2,lisi,22:female:shanghai
create table t_user(id int,name string,info struct<age:int,sex:string,addr:string>)
row format delimited fields terminated by ','
collection items terminated by ':';
select id,name,info.addr from t_user;
-----------------------------------------------------------------------------------------------------
cast函数 强转函数
select cast("5" as int);
select cast(current_timestamp as date);
select cast("2017-09-17" as date);
select id,cast(birthday as date) as bir,cast(salary as float) from t_fun;
select unix_timestamp(); //当前时间戳
select unix_timestamp("2017/08/10 17:50:30","yyyy/mm/dd hh:mm:ss")
------------------------------------------------------------------------------------------------
数学运算函数
select round(5.4) ##5 四舍五入
select round(5.1345,3) ##5.135 四舍五入保留3位小数
select ceil(5.4) ##6 向上取整
select floor(5.4) ##5 向下取整
select abs(-5.4) ##5.4 取绝对值
select greatest(3,6,5) ##6 取最大值
select least(3,6,5) ##3 取最小值
------------------------------------------------------------------------------------------
concat(string a,string b) ##拼接字符串
concat_ws(string rag,string a,string b) ##拼接字符串中间加分隔符rag
有如下信息
192,168,33,66,zhangsan,male
192,168,33,77,wangwu,mail
192,168,43,100,lisi,female
create table t_employ_ip(ip_seg1 string,ip_seg2 string,ip_seg3 string,ip_seg4 string,name string,sex string)
row format delimited fields terminated by ',';
select concat_ws('.',ip_seg1,ip_seg2,ip_seg3,ip_seg4) as ip,name,sex from t_employ_ip;
--------------------------------------------------------
length(string a) ##求字符串长度
--------------------------------------------------------
select split('18:male:beijing',':'); ##按:切割字符串
---------------------------------------------------------------------------------
to_date函数 ##字符串转日期函数
select to_date("2017-09-17 16:58:32")
--------------------------------------------
时间戳转字符串
select from_unixtime(unix_timestamp(),'yyyy-mm-dd hh:mm:ss')
--------------------------------------------------------
把字符串转unix时间戳
select unix_timestamp("2017/08/10 17:50:30","yyyy/mm/dd hh:mm:ss")
----------------------------------------------------------
explode()函数,行转列函数
假如有以下数据
1,zhangsan,化学:物理:数学:语文
2,lisi,化学:数学:生物:生理:卫生
3,wangwu,化学:语文:英语:体育:生物
create table t_stu_subject(id int,name string,subjects array<string>)
row format delimited fields terminated by ','
collection items terminated by ":";
load data local inpath '/root/stu_sub.dat' into table t_stu_subject;
select explode(subjects) from t_stu_subject;
+------+--+
| col |
+------+--+
| 化学 |
| 物理 |
| 数学 |
| 语文 |
| 化学 |
| 数学 |
| 生物 |
| 生理 |
| 卫生 |
| 化学 |
| 语文 |
| 英语 |
| 体育 |
| 生物 |
+------+--+
select distinct tmp.subs from (select explode(subjects) subs from t_stu_subject) tmp;
+-----------+--+
| tmp.subs |
+-----------+--+
| 体育 |
| 化学 |
| 卫生 |
| 数学 |
| 物理 |
| 生物 |
| 生理 |
| 英语 |
| 语文 |
+-----------+--+
------------------------------------------------------------------------------------------------------------
lateral view函数 ##横向连接
select id,name,sub from t_stu_subject lateral view explode(subjects) tmp as sub
+-----+-----------+----------+--+
| id | name | tmp.sub |
+-----+-----------+----------+--+
| 1 | zhangsan | 化学 |
| 1 | zhangsan | 物理 |
| 1 | zhangsan | 数学 |
| 1 | zhangsan | 语文 |
| 2 | lisi | 化学 |
| 2 | lisi | 数学 |
| 2 | lisi | 生物 |
| 2 | lisi | 生理 |
| 2 | lisi | 卫生 |
| 3 | wangwu | 化学 |
| 3 | wangwu | 语文 |
| 3 | wangwu | 英语 |
| 3 | wangwu | 体育 |
| 3 | wangwu | 生物 |
+-----+-----------+----------+--+
炸map
select
id,name,key,value
from t_user lateral view explode(family) tmp as key,value
-----------------------------------------------------------------
hive wordcount
select tmp.word,count(1) cnts
from (select explode(split(words,' ')) word from t_wc) tmp
group by tmp.word order by cnts desc
-----------------------------------------------------------------------------------------------------------------
sort_array()
select sort_array(array('c','b','a'));
+----------------+--+
| _c0 |
+----------------+--+
| ["a","b","c"] |
+----------------+--+
-----------------------------------------------------------------------------------------------
case when
select id,name,
case
when age<28 then 'youngth'
when age >=28 and age < 50 then 'middle'
else 'old'
end
from t_user;
---------------------------------------------------------------------------------------------
if
select movie_name,actors,first_show
if(array_contains(actors,'吴刚'),'好电影','懒电影')
from t_movie
---------------------------------------------------------------------------------------------
row_number() over()
select tmp.*
from (select id,age,name,sex,row_number() over(partition by sex order by age desc) rk from t_rn) tmp
where tmp.rk < 3
有如下数据
1,19,a,male
2,19,b,male
3,22,c,female
4,16,d,female
5,30,e,male
6,26,f,female
create table t_rn(id int,age int,name string,sex string)
row format delimited fields terminated by ',';
load data local inpath '/root/rn.dat' into table t_rn;
-----------------------------------------------------------------------------------------------------------
有如下数据
a,2015-01,5
a,2015-01,15
b,2015-01,5
a,2015-01,8
b,2015-01,25
a,2015-01,5
c,2015-01,10
c,2015-01,20
a,2015-02,4
a,2015-02,6
c,2015-02,30
c,2015-02,10
b,2015-02,10
b,2015-02,5
a,2015-03,14
a,2015-03,6
b,2015-03,20
b,2015-03,25
c,2015-03,10
c,2015-03,20
create table t_accumulate(uid string,month string,amount int)
row format delimited fields terminated by ',';
load data local inpath '/root/accumulate.dat' into table t_accumulate;
求每个用户每个月的销售额和累积的销售额
第一种方法,传统方法
create table t_accumulate_mid
as
select uid,month,sum(amount) samount
from t_accumulate group by uid,month;
得
+------+----------+----------+--+
| uid | month | samount |
+------+----------+----------+--+
| a | 2015-01 | 33 |
| a | 2015-02 | 10 |
| a | 2015-03 | 20 |
| b | 2015-01 | 30 |
| b | 2015-02 | 15 |
| b | 2015-03 | 45 |
| c | 2015-01 | 30 |
| c | 2015-02 | 40 |
| c | 2015-03 | 30 |
+------+----------+----------+--+
select auid uid, bmonth month,max(bsamount) monthsale,sum(asamount) amount
from (select a.uid auid,a.month amonth,a.samount asamount,b.month bmonth,b.samount bsamount
from t_accumulate_mid a join t_accumulate_mid b
on a.uid = b.uid where a.month <= b.month) tmp
group by auid,bmonth;
其中
select a.uid auid,a.month amonth,a.samount asamount,b.month bmonth,b.samount bsamount
from t_accumulate_mid a join t_accumulate_mid b
on a.uid = b.uid where a.month <= b.month
得
+-------+----------+-----------+----------+-----------+--+
| auid | amonth | asamount | bmonth | bsamount |
+-------+----------+-----------+----------+-----------+--+
| a | 2015-01 | 33 | 2015-01 | 33 |
| a | 2015-01 | 33 | 2015-02 | 10 |
| a | 2015-02 | 10 | 2015-02 | 10 |
| a | 2015-01 | 33 | 2015-03 | 20 |
| a | 2015-02 | 10 | 2015-03 | 20 |
| a | 2015-03 | 20 | 2015-03 | 20 |
| b | 2015-01 | 30 | 2015-01 | 30 |
| b | 2015-01 | 30 | 2015-02 | 15 |
| b | 2015-02 | 15 | 2015-02 | 15 |
| b | 2015-01 | 30 | 2015-03 | 45 |
| b | 2015-02 | 15 | 2015-03 | 45 |
| b | 2015-03 | 45 | 2015-03 | 45 |
| c | 2015-01 | 30 | 2015-01 | 30 |
| c | 2015-01 | 30 | 2015-02 | 40 |
| c | 2015-02 | 40 | 2015-02 | 40 |
| c | 2015-01 | 30 | 2015-03 | 30 |
| c | 2015-02 | 40 | 2015-03 | 30 |
| c | 2015-03 | 30 | 2015-03 | 30 |
+-------+----------+-----------+----------+-----------+--+
再用子查询得
+------+----------+------------+---------+--+
| uid | month | monthsale | amount |
+------+----------+------------+---------+--+
| a | 2015-01 | 33 | 33 |
| a | 2015-02 | 10 | 43 |
| a | 2015-03 | 20 | 63 |
| b | 2015-01 | 30 | 30 |
| b | 2015-02 | 15 | 45 |
| b | 2015-03 | 45 | 90 |
| c | 2015-01 | 30 | 30 |
| c | 2015-02 | 40 | 70 |
| c | 2015-03 | 30 | 100 |
+------+----------+------------+---------+--+
第二张方法
窗口分析函数 sum() over()
select uid,month,amount
,sum(amount) over(partition by uid order by month rows between unbounded preceding and current row) accumulate
from //表示从当前行加到最前面一行
(select uid,month,sum(amount) amount
from t_accumulate group by uid,month) tmp
-----------------------------------------------------------------------------------------------------------
hive自定义函数
udf
<dependency>
<groupid>org.apache.hive</groupid>
<artifactid>hive-exec</artifactid>
<version>1.2.2</version>
</dependency>
package com.wyd.hive.udf;
import com.alibaba.fastjson.json;
import com.alibaba.fastjson.jsonarray;
import org.apache.hadoop.hive.ql.exec.description;
import org.apache.hadoop.hive.ql.exec.udf;
描述 详细描述
@description(name = "myjson",value = "",extended = "")
public class myjsonparser extends udf {
public string evaluate(string json, int index){
jsonarray objects = json.parsearray(json);
object o = objects.get(index);
return (string)o;
}
}
打包,上传到服务器
在hive shell里
0: jdbc:hive2://node4:10000> add jar /root/hive24-1.0-snapshot.jar
0: jdbc:hive2://node4:10000> create temporary function myjson as 'com.wyd.hive.udf.myjsonparser'
select jsonpa(json,"movie") movie,cast(jsonpa(json,"rate") as int) rate,from_unixtime(cast(jsonpa(json,"timestamp") as bigint),'yyyy/mm/dd hh:mm:ss') time,jsonpa(json,"uid") uid from t_ratingjson limit 10;
--------------------------------------------------------------------------------------------------
hive自带json解析函数
json_tuple(json,'key1','key2') as (key1,key2)
select json_tuple(json,'movie','rate,'timestamp','uid') as (movie,rate,ts,uid) from t_rating;
-----------------------------------------------------------------------------------------------------------
假如有一个web系统,每天生成以下日志文件:
2017-09-15号的数据:
192.168.33.6,hunter,2017-09-15 10:30:20,/a
192.168.33.7,hunter,2017-09-15 10:30:26,/b
192.168.33.6,jack,2017-09-15 10:30:27,/a
192.168.33.8,tom,2017-09-15 10:30:28,/b
192.168.33.9,rose,2017-09-15 10:30:30,/b
192.168.33.10,julia,2017-09-15 10:30:40,/c
2017-09-16号的数据:
192.168.33.16,hunter,2017-09-16 10:30:20,/a
192.168.33.18,jerry,2017-09-16 10:30:30,/b
192.168.33.26,jack,2017-09-16 10:30:40,/a
192.168.33.18,polo,2017-09-16 10:30:50,/b
192.168.33.39,nissan,2017-09-16 10:30:53,/b
192.168.33.39,nissan,2017-09-16 10:30:55,/a
192.168.33.39,nissan,2017-09-16 10:30:58,/c
192.168.33.20,ford,2017-09-16 10:30:54,/c
2017-09-17号的数据:
192.168.33.46,hunter,2017-09-17 10:30:21,/a
192.168.43.18,jerry,2017-09-17 10:30:22,/b
192.168.43.26,tom,2017-09-17 10:30:23,/a
192.168.53.18,bmw,2017-09-17 10:30:24,/b
192.168.63.39,benz,2017-09-17 10:30:25,/b
192.168.33.25,haval,2017-09-17 10:30:30,/c
192.168.33.10,julia,2017-09-17 10:30:40,/c
create table t_web_log(ip string,uid string,access_time string,url string)
partitioned by (day string)
row format delimited fields terminated by ',';
load data local inpath '/root/9-15.log' into table t_web_log partition(day='2017-09-15');
load data local inpath '/root/9-16.log' into table t_web_log partition(day='2017-09-16');
load data local inpath '/root/9-17.log' into table t_web_log partition(day='2017-09-17');
--统计日活信息
--创建日活跃用户表
create table t_user_active_day(ip string,uid string,first_access string,url string)
partitioned by(day string)
row format delimited fields terminated by ',';
insert into table t_user_active_day partition(day='2017-09-15')
select tmp.ip ip,tmp.uid uid,tmp.access_time first_access,tmp.url url
from
(select ip,uid,access_time,url
,row_number() over(partition by uid order by access_time) rn
from t_web_log where day='2017-09-15') tmp
where tmp.rn < 2
--统计日新用户
逻辑图详见 日新用户统计逻辑.png
--创建历史用户表
create table t_user_history(uid string)
--创建每日新增用户表
create table t_user_new_day like t_user_active_day;
insert into table t_user_new_day partition(day='2017-09-15')
select tuad.ip,tuad.uid,tuad.first_access,tuad.url
from t_user_active_day tuad
left outer join t_user_history tuh on tuad.uid = tuh.uid
where tuad.day = '2017-09-15' and tuh.uid is null;
insert into table t_user_history
select uid from t_user_new_day
where day='2017-09-15';
---------------------------------------------------------------
开发hive脚本
#!/bin/bash
day_str=`date -d '-1 day' + '%y-%m-%d'`
hive_exec=/usr/local/apache-hive-1.2.2-bin/bin/hive
hql_user_active_day="
insert into table big24.t_user_active_day partition(day=\"$day_str\")
select tmp.ip ip,tmp.uid uid,tmp.access_time first_access,tmp.url url
from
(select ip,uid,access_time,url
,row_number() over(partition by uid order by access_time) rn
from big24.t_web_log where day=\"$day_str\") tmp
where tmp.rn < 2;"
hql_user_new_day="
insert into table big24.t_user_new_day partition(day=\"$day_str\")
select tuad.ip,tuad.uid,tuad.first_access,tuad.url
from big24.t_user_active_day tuad
left outer join big24.t_user_history tuh on tuad.uid = tuh.uid
where tuad.day = \"$day_str\" and tuh.uid is null;
"
hql_user_history="
insert into table big24.t_user_history
select uid from big24.t_user_new_day
where day=\"$day_str\";
"
$hive_exec -e "$hql_user_active_day"
$hive_exec -e "$hql_user_new_day"
$hive_exec -e "$hql_user_history"
--------------------------------------------------------------------------------------------------------
使用java代码连接到hive
添加maven依赖
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-jdbc -->
<dependency>
<groupid>org.apache.hive</groupid>
<artifactid>hive-jdbc</artifactid>
<version>1.2.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupid>org.apache.hadoop</groupid>
<artifactid>hadoop-common</artifactid>
<version>2.8.5</version>
</dependency>
public class hiveclientdemo {
public static void main(string[] args) throws classnotfoundexception, sqlexception {
class.forname("org.apache.hive.jdbc.hivedriver");
connection conn = drivermanager.getconnection("jdbc:hive2://node4:10000", "root", "");
statement st = conn.createstatement();
resultset resultset = st.executequery("select name,numb from big24.t_a");
while(resultset.next()){
system.out.println(resultset.getstring(1) +","+resultset.getint(2));
}
resultset.close();
st.close();
conn.close();
}
}
用springdata也可以访问
------------------------------------------------------------------------------------------------------
桶表
create table t3(id int,name string,age int)
clustered by(id) into 3 buckets //按id分桶,分三个桶
row format delimited fields terminated by ',';
注意这样加载数据不会产生分桶操作
load data local inpath '/root/t3.dat' into table t3;
set hive.enforce.bucketing = true;
set mapreduce.job.reduces=3;
insert into t3 select * from t3_1;
这样才会插入分桶数据
桶表适用于就按id查询的情况
桶表中桶的数量如何设定
评估数据量,保证每个桶的数据量是block的2倍
--------------------------------------------------------------------------------------------
union查询
两张连接的表字段个数必须相同,类型可以不一样
select id,name from customers union
export导出数据
export table customers to '/user/exportdata' //将导出表结构和数据
这是hdfs上的目录地址
order是全局排序
sort是map端排序
如果设置task的数量为一,那sort也相当于全排序
set hive.exec.reducers.bytes.per.reducer=xxx //设置reducetask的字节数
set hive.exec.reducers.max=5 //设置reducetask的最大任务数
set mapreduce.job.reduces=2 //设置执行的reduce数量
设置
set hive.exec.reducers.max=0
set mapreduce.job.reduce=0
就会使hive没有reduce阶段
distribute by 类似于 group by
cluster by 等于 distribute by sort by
有如下数据
mid money name
aa 15.0 商店1
aa 20.0 商店2
bb 22.0 商店3
cc 44.0 商店4
执行hive语句:
select mid, money, name from store distribute by mid sort by mid asc, money asc
我们所有的mid相同的数据会被送到同一个reducer去处理,这就是因为指定了distribute by mid,这样的话就可以统计出每个商户中各个商店盈利的排序了(这个肯定是全局有序的,因为相同的商户会放到同一个reducer去处理)。这里需要注意的是distribute by必须要写在sort by之前。
cluster by的功能就是distribute by和sort by相结合,如下2个语句是等价的:
select mid, money, name from store cluster by mid
select mid, money, name from store distribute by mid sort by mid
如果需要获得与3中语句一样的效果:
select mid, money, name from store cluster by mid
注意被cluster by指定的列只能是降序,不能指定asc和desc。
https://blog.csdn.net/jthink_/article/details/38903775
order by:
order by会对所给的全部数据进行全局排序,并且只会“叫醒”一个reducer干活。它就像一个糊涂蛋一样,不管来多少数据,都只启动一个reducer来处理。因此,数据量小还可以,但数据量一旦变大order by就会变得异常吃力,甚至“罢工”。
sort by:
sort by是局部排序。相比order by的懒惰糊涂,sort by正好相反,它不但非常勤快,而且具备分身功能。sort by会根据数据量的大小启动一到多个reducer来干活,并且,它会在进入reduce之前为每个reducer都产生一个排序文件。这样的好处是提高了全局排序的效率。
distribute by:
distribute by的功能是:distribute by 控制map结果的分发,它会将具有相同字段的map输出分发到一个reduce节点上做处理。即就是,某种情况下,我们需要控制某个特定行到某个reducer中,这种操作一般是为后续可能发生的聚集操作做准备。
如果想用sortby实现order by的效果,可以考虑
select * from t_order_demo distribute by classno sort by age desc limit 2
第一个mr会通过classno去向不同reducer上分发数据,然后在reducer上进行局部排序,再开启第二个mr,mapper会取上一个mr中各个reducer里的前2条数据进行发送到一个reducer中进行全局排序
---------------------
作者:自封的羽球大佬
来源:csdn
原文:https://blog.csdn.net/qq_40795214/article/details/82190827
版权声明:本文为博主原创文章,转载请附上博文链接!
--------------------------------------------------------------------------------------
动态分区
set hive.exec.dynamic.partition=true; //表示开启动态分区功能
set hive.exec.dynamic.partition.mode=nonstrict //默认是strict(严格模式),设置为非严格模式
1,tom,18,china,beijing
2,jack,20,china,tianjing
3,hank,16,china,beijing
4,lee,32,us,newyork
5,mary,26,us,la
create table t_employee(id int,name string,age int,state string,city string)
row format delimited fields terminated by ',';
load data local inpath '/root/employee.log' into table t_employee;
create table t_user_depart(id int,name string,age int)
partitioned by(sta string, ct string)
row format delimited fields terminated by ',';
insert into table t_user_depart
partition(sta='china',ct)
select id,name,age,city from t_employee
where state = 'china';
set hive.exec.dynamic.partition.mode=nonstrict;
insert into table t_user_depart
partition(sta,ct)
select id,name,age,state,city from t_employee
严格模式下,至少有一个分区是静态的
如果都是动态分区,那就要用非严格模式
-------------------------------------------------------------------------------------------
orc是列式存储文件
-------------------------------------------------------------------------------------------
hive事务处理在>0.13.0之后支持行级事务
1、所有事务自动提交
2、只支持orc格式
3、使用bucket表
4、配置hive参数,使其支持事务
set hive.support.concurrency = true;
set hive.enforce.bucketing = true;
set hive.exec.dynamic.partition.mode = nonstrict //动态分区模式
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.dbtxnmanager; //事务管理器
set hive.compactor.initiator.on = true;
set hive.compactor.worker.threads = 1; //工作线程数
set hive.support.concurrency = true;
set hive.enforce.bucketing = true;
set hive.exec.dynamic.partition.mode = nonstrict;
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.dbtxnmanager;
set hive.compactor.initiator.on = true;
set hive.compactor.worker.threads = 1;
修改hive-site.xml添加
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>hive.enforce.bucketing</name>
<value>true</value>
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.dbtxnmanager</value>
</property>
<property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
</property>
<property>
<name>hive.compactor.worker.threads</name>
<value>1</value>
</property>
然后更新mysql元数据表
upgrade your hive mysql metastore db with hive-txn-schema-0.14.0.mysql.sql as follows..
mysql> source /usr/local/hadoop/hive/scripts/metastore/upgrade/mysql/hive-txn-schema-0.14.0.mysql.sql;
create table t_e(id int,name string,age int,state string,city string)
clustered by(id) into 3 buckets
row format delimited fields terminated by ','
stored as orc
tblproperties('transactional'='true');
insert into table t_e
select * from t_employee;
就可以支持更新删除操作了
update t_e set name = 'hook' where id = 3;
----------------------------------------------------------------------------------------------------------
hive视图
create view v1 as
select a.name,a.numb,b.nick
from t_a a left outer join t_b b on a.name = b.name;
查询视图
desc formatted v1
select * from v1;
-------------------------------------------------------------------------------------------------
map端join
set hive.auto.convert.join=true;
map端连接暗示
select /*+ mapjoin(t_a) */ a.name,a.numb,b.nick
from t_a a left outer join t_b b on a.name = b.name
查看sql执行计划
explain select ...
---------------------------------------------------------------------------------------
hive本地模式运行
临时设置
set oldjobtracker=${hiveconf:mapred.job.tracker}
set mapred.job.tracker=local
set mapred.tmp.dir=/home/edward/tmp
执行自己想执行的语句
执行完毕后恢复集群模式
set mapred.job.tracker=${oldjobtracker}
还要设置自动执行本地模式
set hive.exec.mode.local.auto=true
或写到hive.site.xml中
------------------------------------------------------------------------------------------------------
并行执行 不存在依赖关系的两个阶段同时执行
set hive.exec.parallel=true //开启自动并行执行
或写到hive.site.xml中
-----------------------------------------------------------------------------------------------------
严格模式
set hive.mapred.mode=strict
1、严格模式下分区表必须指定分区,或者带where的分区字段条件
2、order by时必须使用limit子句,避免全表扫描
3、避免笛卡尔集的查询
------------------------------------------------------------------------------------
设置mr的数量
set hive.exec.reducers.bytes.per.reducer=750000000; //设置reduce处理的字节数
jvm重用
set mapreduce.job.jvm.numtasks=1; //-1为没有限制,适用于大量小文件
hive on spark 写入桶表
要设置两个配置
creating hive bucketed table is supported from spark 2.3 (jira spark-17729). spark will disallow users from writing outputs to hive bucketed tables, by default.
setting `hive.enforce.bucketing=false` and `hive.enforce.sorting=false` will allow you to save to hive bucketed tables.
----------------------------------------------------------------------------------
hive集成hbase
将hive/lib目录下的hbase相关包都删掉
rm -rf hbase*
将hbase/lib目录下的hbase相关包拷贝到hive/lib目录下
cp hbase/lib/hbase* /usr/local/hive/lib
修改hive的配置文件
vi hive-site.xml
添加hbase使用的zookeeper集群地址
<property>
<name>hive.zookeeper.quorum</name>
<value>192.168.56.103,192.168.56.104,192.168.56.105</value>
</property>
如果使用beeline连接不上hbase的regionserver
要在hive-site.xml中加
<property>
<name>hive.server2.enable.doas</name>
<value>false</value>
</property>
注意当使用的hive版本为2.x时
要修改hdfs的core-site.xml
增加
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
这样beeline才能连接上
映射hbase中已经存在的表
create external table hbase_table_2(id string, fensi string)
stored by 'org.apache.hadoop.hive.hbase.hbasestoragehandler'
with serdeproperties ("hbase.columns.mapping" = "f1:from")
tblproperties("hbase.table.name" = "ns1:fensi");
create external table guanzhu(id string, guanzhu string)
stored by 'org.apache.hadoop.hive.hbase.hbasestoragehandler'
with serdeproperties ("hbase.columns.mapping" = "f1:from")
tblproperties("hbase.table.name" = "ns1:guanzhu");
如果有数值类型,要在映射列表后加#b,例如
create external table t_ex_hbase_people(key string,id string, name string, age int,addr string,sex string,score int)
stored by 'org.apache.hadoop.hive.hbase.hbasestoragehandler'
with serdeproperties ("hbase.columns.mapping" = "f1:id,f1:name,f1:age#b,f1:addr,f2:sex,f2:score#b")
tblproperties("hbase.table.name" = "ns1:demo", "hbase.mapred.output.outputtable" = "ns1:demo");
------------------------------------
通过hive创建hbase表
create table hbase_table_1(key int, value string)
stored by 'org.apache.hadoop.hive.hbase.hbasestoragehandler'
with serdeproperties ("hbase.columns.mapping" = ":key,cf1:val")
tblproperties ("hbase.table.name" = "xyz", "hbase.mapred.output.outputtable" = "xyz");
这样可以在hbase中创建一个表 'xyz', {name => 'cf1'}
通过hive向hbase中插入数据
create table xyzforhbase(key int,value string)
row format delimited
fields terminated by ',';
load data local inpath '/root/xyz.txt' into table xyzforhbase;
insert into table hbase_table_1 select * from xyzforhbase;
-----------------------------------------------------------------------------------------------
hive on spark集成hbase
把core-site.xml和hdfs-site.xml和hive-site.xml和hbase-site.xml添加到spark/conf目录下
要修改hdfs的core-site.xml
增加
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
这样beeline才能连接上
复制hive/lib下的
hive-hbase-handler-2.3.5.jar
metrics-core-2.2.0.jar
metrics-core-3.1.0.jar
metrics-json-3.1.0.jar
metrics-jvm-3.1.0.jar
或者推荐提交的时候加载
spark/sbin/start-thriftserver.sh --master yarn --deploy-mode client --queue default --num-executors 5 --driver-memory 1g --jars /root/mysql-connector-java-5.1.32.jar,/usr/local/apache-hive-2.3.5-bin/lib/hive-hbase-handler-2.3.5.jar,/usr/local/apache-hive-2.3.5-bin/lib/hbase-client-1.2.7.jar,/usr/local/apache-hive-2.3.5-bin/lib/hbase-server-1.2.7.jar,/usr/local/apache-hive-2.3.5-bin/lib/hbase-common-1.2.7.jar,/usr/local/apache-hive-2.3.5-bin/lib/hbase-protocol-1.2.7.jar,/usr/local/apache-hive-2.3.5-bin/lib/metrics-core-2.2.0.jar,/usr/local/apache-hive-2.3.5-bin/lib/metrics-core-3.1.0.jar,/usr/local/apache-hive-2.3.5-bin/lib/metrics-json-3.1.0.jar,/usr/local/apache-hive-2.3.5-bin/lib/metrics-jvm-3.1.0.jar,/usr/local/apache-hive-2.3.5-bin/lib/htrace-core-3.1.0-incubating.jar
或者在spark.env里配置
export spark_classpath=$spark_home/lib/mysql-connector-java-5.1.38.jar:$spark_home/lib/hbase-server-0.98.18-hadoop2.jar:$spark_home/lib/hbase-common-0.98.18-hadoop2.jar:$spark_home/lib/hbase-client-0.98.18-hadoop2.jar:$spark_home/lib/hbase-protocol-0.98.18-hadoop2.jar:$spark_home/lib/htrace-core-2.04.jar:$spark_home/lib/protobuf-java-2.5.0.jar:$spark_home/lib/guava-12.0.1.jar:$spark_home/lib/hive-hbase-handler-1.2.1-xima.jar:$spark_home/lib/com.yammer.metrics.metrics-core-2.2.0.jar:${spark_classpath
thriftserver.sh服务器启动后用程序启动,在程序里要加maven依赖
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-jdbc -->
<dependency>
<groupid>org.apache.hive</groupid>
<artifactid>hive-jdbc</artifactid>
<version>2.3.5</version>
</dependency>
然后程序里正常写jdbc查询
package com.wyd.hiveonspark;
import java.sql.*;
public class hiveclientdemo {
public static void main(string[] args) throws classnotfoundexception, sqlexception {
class.forname("org.apache.hive.jdbc.hivedriver");
connection conn = drivermanager.getconnection("jdbc:hive2://node1:10000", "root", "");
statement statement = conn.createstatement();
resultset resultset = statement.executequery("select count(1) cnts from t_web_log group by day");
while (resultset.next()){
system.out.println(resultset.getlong(1));
}
resultset.close();
statement.close();
conn.close();
}
}
如果用sparksql直接操做hive on spark读写hbase
需要把hbase-site.xml拷贝到recourses文件夹下
maven添加依赖
<dependency>
<groupid>org.apache.hbase</groupid>
<artifactid>hbase-client</artifactid>
<version>1.2.7</version>
</dependency>
<dependency>
<groupid>org.apache.spark</groupid>
<artifactid>spark-hive_2.11</artifactid>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupid>org.apache.hive</groupid>
<artifactid>hive-hbase-handler</artifactid>
<version>2.3.5</version>
</dependency>
<dependency>
<groupid>org.apache.hadoop</groupid>
<artifactid>hadoop-client</artifactid>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupid>org.apache.spark</groupid>
<artifactid>spark-core_2.11</artifactid>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupid>org.apache.spark</groupid>
<artifactid>spark-sql_2.11</artifactid>
<version>${spark.version}</version>
</dependency>
package com.wyd.demo
import org.apache.spark.sql.{dataframe, sparksession}
object demo {
def main(args: array[string]): unit = {
val spark = sparksession.builder().appname("sqlhbasetest").enablehivesupport().getorcreate()
val df: dataframe = spark.sql("select * from guanzhu")
df.show();
}
}
-------------------------------------------------------------------------------------------------
窗口函数
sum() min() max() avg() 类
select *,sum(a.pv) over(partition by cookieid, order by create_time rows between 3 preceding and curreent row) as p
要计算的字段 按cookieid分区 开始 结束
以当前行作为参考系
unbounded preceding 最前面一行
current row 当前行
2 preceding 前面2行
3 following 后面3行
unbounded following 最后一行
preceding |
当前行 | 窗口长度
following |
--------------------------------------
ntile(n) row_number() rank() dense_rank()
ntile(n) 比如n=3 ,ntile就会将元素排好序后分为3分,序号1到3,有重复序号
row_number() 打序号
rank() 对于相同的值 序号相同,然后跳过相同值数量的序号
1
2
3
3
5
dense_rank() 对于相同的值序号相同,但不跳过序号
1
2
3
3
4
5
-------------------------------------------
lag(列, n, 默认值) over(partition by order by) 向下移动
lead(列, n, 默认值) over(partition by order by) 向上移动
cookie1,2015-04-10 10:00:02,url2
cookie1,2015-04-10 10:00:00,url1
cookie1,2015-04-10 10:03:04,url3
cookie1,2015-04-10 10:50:05,url6
cookie1,2015-04-10 11:00:00,url7
cookie1,2015-04-10 10:10:00,url4
cookie1,2015-04-10 10:50:01,url5
cookie2,2015-04-10 10:00:02,url22
cookie2,2015-04-10 10:00:00,url11
cookie2,2015-04-10 10:03:04,url33
cookie2,2015-04-10 10:50:05,url66
cookie2,2015-04-10 11:00:00,url77
cookie2,2015-04-10 10:10:00,url44
cookie2,2015-04-10 10:50:01,url55
select cookieid,
createtime,
url,
row_number() over(partition by cookieid order by createtime) as rn,
lag(createtime,1,'1970-01-01 00:00:00') over(partition by cookieid order by createtime) as last_1_time,
lag(createtime,2) over(partition by cookieid order by createtime) as last_2_time
from lxw1234;
cookieid createtime url rn last_1_time last_2_time
-------------------------------------------------------------------------------------------
cookie1 2015-04-10 10:00:00 url1 1 1970-01-01 00:00:00 null
cookie1 2015-04-10 10:00:02 url2 2 2015-04-10 10:00:00 null
cookie1 2015-04-10 10:03:04 1url3 3 2015-04-10 10:00:02 2015-04-10 10:00:00
cookie1 2015-04-10 10:10:00 url4 4 2015-04-10 10:03:04 2015-04-10 10:00:02
cookie1 2015-04-10 10:50:01 url5 5 2015-04-10 10:10:00 2015-04-10 10:03:04
cookie1 2015-04-10 10:50:05 url6 6 2015-04-10 10:50:01 2015-04-10 10:10:00
cookie1 2015-04-10 11:00:00 url7 7 2015-04-10 10:50:05 2015-04-10 10:50:01
cookie2 2015-04-10 10:00:00 url11 1 1970-01-01 00:00:00 null
cookie2 2015-04-10 10:00:02 url22 2 2015-04-10 10:00:00 null
cookie2 2015-04-10 10:03:04 1url33 3 2015-04-10 10:00:02 2015-04-10 10:00:00
cookie2 2015-04-10 10:10:00 url44 4 2015-04-10 10:03:04 2015-04-10 10:00:02
cookie2 2015-04-10 10:50:01 url55 5 2015-04-10 10:10:00 2015-04-10 10:03:04
cookie2 2015-04-10 10:50:05 url66 6 2015-04-10 10:50:01 2015-04-10 10:10:00
cookie2 2015-04-10 11:00:00 url77 7 2015-04-10 10:50:05 2015-04-10 10:50:01
select cookieid,
createtime,
url,
row_number() over(partition by cookieid order by createtime) as rn,
lead(createtime,1,'1970-01-01 00:00:00') over(partition by cookieid order by createtime) as next_1_time,
lead(createtime,2) over(partition by cookieid order by createtime) as next_2_time
from lxw1234;
cookieid createtime url rn next_1_time next_2_time
-------------------------------------------------------------------------------------------
cookie1 2015-04-10 10:00:00 url1 1 2015-04-10 10:00:02 2015-04-10 10:03:04
cookie1 2015-04-10 10:00:02 url2 2 2015-04-10 10:03:04 2015-04-10 10:10:00
cookie1 2015-04-10 10:03:04 1url3 3 2015-04-10 10:10:00 2015-04-10 10:50:01
cookie1 2015-04-10 10:10:00 url4 4 2015-04-10 10:50:01 2015-04-10 10:50:05
cookie1 2015-04-10 10:50:01 url5 5 2015-04-10 10:50:05 2015-04-10 11:00:00
cookie1 2015-04-10 10:50:05 url6 6 2015-04-10 11:00:00 null
cookie1 2015-04-10 11:00:00 url7 7 1970-01-01 00:00:00 null
cookie2 2015-04-10 10:00:00 url11 1 2015-04-10 10:00:02 2015-04-10 10:03:04
cookie2 2015-04-10 10:00:02 url22 2 2015-04-10 10:03:04 2015-04-10 10:10:00
cookie2 2015-04-10 10:03:04 1url33 3 2015-04-10 10:10:00 2015-04-10 10:50:01
cookie2 2015-04-10 10:10:00 url44 4 2015-04-10 10:50:01 2015-04-10 10:50:05
cookie2 2015-04-10 10:50:01 url55 5 2015-04-10 10:50:05 2015-04-10 11:00:00
cookie2 2015-04-10 10:50:05 url66 6 2015-04-10 11:00:00 null
cookie2 2015-04-10 11:00:00 url77 7 1970-01-01 00:00:00 null
first_value(列) over(partition by order by) 截止到当前行,第一个列的值
last_value(列) over(partition by order by) 截止到当前行,最后一个值
select cookieid,
createtime,
url,
row_number() over(partition by cookieid order by createtime) as rn,
first_value(url) over(partition by cookieid order by createtime) as first1
from lxw1234;
cookieid createtime url rn first1
---------------------------------------------------------
cookie1 2015-04-10 10:00:00 url1 1 url1
cookie1 2015-04-10 10:00:02 url2 2 url1
cookie1 2015-04-10 10:03:04 1url3 3 url1
cookie1 2015-04-10 10:10:00 url4 4 url1
cookie1 2015-04-10 10:50:01 url5 5 url1
cookie1 2015-04-10 10:50:05 url6 6 url1
cookie1 2015-04-10 11:00:00 url7 7 url1
cookie2 2015-04-10 10:00:00 url11 1 url11
cookie2 2015-04-10 10:00:02 url22 2 url11
cookie2 2015-04-10 10:03:04 1url33 3 url11
cookie2 2015-04-10 10:10:00 url44 4 url11
cookie2 2015-04-10 10:50:01 url55 5 url11
cookie2 2015-04-10 10:50:05 url66 6 url11
cookie2 2015-04-10 11:00:00 url77 7 url11
select cookieid,
createtime,
url,
row_number() over(partition by cookieid order by createtime) as rn,
last_value(url) over(partition by cookieid order by createtime) as last1
from lxw1234;
cookieid createtime url rn last1
-----------------------------------------------------------------
cookie1 2015-04-10 10:00:00 url1 1 url1
cookie1 2015-04-10 10:00:02 url2 2 url2
cookie1 2015-04-10 10:03:04 1url3 3 1url3
cookie1 2015-04-10 10:10:00 url4 4 url4
cookie1 2015-04-10 10:50:01 url5 5 url5
cookie1 2015-04-10 10:50:05 url6 6 url6
cookie1 2015-04-10 11:00:00 url7 7 url7
cookie2 2015-04-10 10:00:00 url11 1 url11
cookie2 2015-04-10 10:00:02 url22 2 url22
cookie2 2015-04-10 10:03:04 1url33 3 1url33
cookie2 2015-04-10 10:10:00 url44 4 url44
cookie2 2015-04-10 10:50:01 url55 5 url55
cookie2 2015-04-10 10:50:05 url66 6 url66
cookie2 2015-04-10 11:00:00 url77 7 url77
---------------------------------------------------------------------------------------------------
grouping set, cube, rollup
create external table test_data (
month string,
day string,
cookieid string
) row format delimited
fields terminated by ','
stored as textfile location '/user/jc_rc_ftp/test_data';
select * from test_data l;
+----------+-------------+-------------+--+
| l.month | l.day | l.cookieid |
+----------+-------------+-------------+--+
| 2015-03 | 2015-03-10 | cookie1 |
| 2015-03 | 2015-03-10 | cookie5 |
| 2015-03 | 2015-03-12 | cookie7 |
| 2015-04 | 2015-04-12 | cookie3 |
| 2015-04 | 2015-04-13 | cookie2 |
| 2015-04 | 2015-04-13 | cookie4 |
| 2015-04 | 2015-04-16 | cookie4 |
| 2015-03 | 2015-03-10 | cookie2 |
| 2015-03 | 2015-03-10 | cookie3 |
| 2015-04 | 2015-04-12 | cookie5 |
| 2015-04 | 2015-04-13 | cookie6 |
| 2015-04 | 2015-04-15 | cookie3 |
| 2015-04 | 2015-04-15 | cookie2 |
| 2015-04 | 2015-04-16 | cookie1 |
+----------+-------------+-------------+--+
14 rows selected (0.249 seconds)
select
month,
day,
count(distinct cookieid) as uv,
grouping__id
from test_data
group by month,day
grouping sets (month,day)
order by grouping__id;
等价于
select month,null,count(distinct cookieid) as uv,1 as grouping__id from test_data group by month
union all
select null,day,count(distinct cookieid) as uv,2 as grouping__id from test_data group by day
+----------+-------------+-----+---------------+--+
| month | day | uv | grouping__id |
+----------+-------------+-----+---------------+--+
| 2015-04 | null | 6 | 1 |
| 2015-03 | null | 5 | 1 |
| null | 2015-04-16 | 2 | 2 |
| null | 2015-04-15 | 2 | 2 |
| null | 2015-04-13 | 3 | 2 |
| null | 2015-04-12 | 2 | 2 |
| null | 2015-03-12 | 1 | 2 |
| null | 2015-03-10 | 4 | 2 |
+----------+-------------+-----+---------------+--+
8 rows selected (177.299 seconds)
select
month,
day,
count(distinct cookieid) as uv,
grouping__id
from test_data
group by month,day
grouping sets (month,day,(month,day))
order by grouping__id;
等价于
select month,null,count(distinct cookieid) as uv,1 as grouping__id from test_data group by month
union all
select null,day,count(distinct cookieid) as uv,2 as grouping__id from test_data group by day
union all
select month,day,count(distinct cookieid) as uv,3 as grouping__id from test_data group by month,day
+----------+-------------+-----+---------------+--+
| month | day | uv | grouping__id |
+----------+-------------+-----+---------------+--+
| 2015-04 | null | 6 | 1 |
| 2015-03 | null | 5 | 1 |
| null | 2015-03-10 | 4 | 2 |
| null | 2015-04-16 | 2 | 2 |
| null | 2015-04-15 | 2 | 2 |
| null | 2015-04-13 | 3 | 2 |
| null | 2015-04-12 | 2 | 2 |
| null | 2015-03-12 | 1 | 2 |
| 2015-04 | 2015-04-16 | 2 | 3 |
| 2015-04 | 2015-04-12 | 2 | 3 |
| 2015-04 | 2015-04-13 | 3 | 3 |
| 2015-03 | 2015-03-12 | 1 | 3 |
| 2015-03 | 2015-03-10 | 4 | 3 |
| 2015-04 | 2015-04-15 | 2 | 3 |
+----------+-------------+-----+---------------+--+
cube 根据group by的维度的所有组合进行聚合。
select
month,
day,
count(distinct cookieid) as uv,
grouping__id
from test_data
group by month,day
with cube
order by grouping__id;
等价于
select null,null,count(distinct cookieid) as uv,0 as grouping__id from test_data
union all
select month,null,count(distinct cookieid) as uv,1 as grouping__id from test_data group by month
union all
select null,day,count(distinct cookieid) as uv,2 as grouping__id from test_data group by day
union all
select month,day,count(distinct cookieid) as uv,3 as grouping__id from test_data group by month,day
+----------+-------------+-----+---------------+--+
| month | day | uv | grouping__id |
+----------+-------------+-----+---------------+--+
| null | null | 7 | 0 |
| 2015-03 | null | 5 | 1 |
| 2015-04 | null | 6 | 1 |
| null | 2015-04-16 | 2 | 2 |
| null | 2015-04-15 | 2 | 2 |
| null | 2015-04-13 | 3 | 2 |
| null | 2015-04-12 | 2 | 2 |
| null | 2015-03-12 | 1 | 2 |
| null | 2015-03-10 | 4 | 2 |
| 2015-04 | 2015-04-12 | 2 | 3 |
| 2015-04 | 2015-04-16 | 2 | 3 |
| 2015-03 | 2015-03-12 | 1 | 3 |
| 2015-03 | 2015-03-10 | 4 | 3 |
| 2015-04 | 2015-04-15 | 2 | 3 |
| 2015-04 | 2015-04-13 | 3 | 3 |
+----------+-------------+-----+---------------+--+
rollup 是cube的子集,以最左侧的维度为主,从该维度进行层级聚合
比如,以month维度进行层级聚合:
select
month,
day,
count(distinct cookieid) as uv,
grouping__id
from test_data
group by month,day
with rollup
order by grouping__id;
可以实现这样的上钻过程:月天的uv->月的uv->总uv
+----------+-------------+-----+---------------+--+
| month | day | uv | grouping__id |
+----------+-------------+-----+---------------+--+
| null | null | 7 | 0 |
| 2015-04 | null | 6 | 1 |
| 2015-03 | null | 5 | 1 |
| 2015-04 | 2015-04-16 | 2 | 3 |
| 2015-04 | 2015-04-15 | 2 | 3 |
| 2015-04 | 2015-04-13 | 3 | 3 |
| 2015-04 | 2015-04-12 | 2 | 3 |
| 2015-03 | 2015-03-12 | 1 | 3 |
| 2015-03 | 2015-03-10 | 4 | 3 |
+----------+-------------+-----+---------------+--+
--把month和day调换顺序,则以day维度进行层级聚合:
select
day,
month,
count(distinct cookieid) as uv,
grouping__id
from test_data
group by day,month
with rollup
order by grouping__id;
可以实现这样的上钻过程:天月的uv->天的uv->总uv
+-------------+----------+-----+---------------+--+
| day | month | uv | grouping__id |
+-------------+----------+-----+---------------+--+
| null | null | 7 | 0 |
| 2015-04-12 | null | 2 | 1 |
| 2015-04-15 | null | 2 | 1 |
| 2015-03-12 | null | 1 | 1 |
| 2015-04-16 | null | 2 | 1 |
| 2015-03-10 | null | 4 | 1 |
| 2015-04-13 | null | 3 | 1 |
| 2015-04-16 | 2015-04 | 2 | 3 |
| 2015-04-15 | 2015-04 | 2 | 3 |
| 2015-04-13 | 2015-04 | 3 | 3 |
| 2015-03-12 | 2015-03 | 1 | 3 |
| 2015-03-10 | 2015-03 | 4 | 3 |
| 2015-04-12 | 2015-04 | 2 | 3 |
+-------------+----------+-----+---------------+--+
set hive.enforce.bucketing = true; 开启桶表
set hive.mapred.mode=strict 启用hive严格模式
mapred.reduce.tasks=2 设置reducetask的数量
set hive.exec.dynamic.partition=true; //表示开启动态分区功能
set hive.exec.dynamic.partition.mode=nonstrict //默认是strict(严格模式),设置为非严格模式
set hive.exec.reducers.bytes.per.reducer=xxx //设置reducetask的字节数
set hive.exec.reducers.max=5 //设置reducetask的最大任务数
set hive.exec.parallel=true //开启自动并行执行
set mapreduce.job.reduce=2 //设置执行的reduce数量
set mapreduce.job.jvm.numtasks=1; //jvm重用 -1为没有限制,适用于大量小文件
表使用orcfile进行存储,或sequnencefile进行存储
orcfile是列式存储文件,sequencefile是二进制文件
create table a(
...
)
stored as sequencefile
或
stored as orcfile
可以设置hive使用压缩
-- 任务中间压缩
set hive.exec.compress.intermediate=true;
set hive.intermediate.compression.codec=org.apache.hadoop.io.compress.snappycodec;
set hive.intermediate.compression.type=block;
-- map/reduce 输出压缩
set hive.exec.compress.output=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.snappycodec;
set mapred.output.compression.type=block;
=========================================================
hive解决数据倾斜问题
1、解决方法:set hive.map.aggr=true
set hive.groupby.mapaggr.checkinterval = 100000在 map 端进行聚合操作的条目数目
set hive.groupby.skewindata=true
原理:hive.map.aggr=true 这个配置项代表是否在map端进行聚合
hive.groupby.skwindata=true 当选项设定为 true,生成的查询计划会有两个 mr job。第一个 mr job 中,map 的输出结果集合会随机分布到 reduce 中,每个 reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 group by key 有可能被分发到不同的 reduce 中,从而达到负载均衡的目的;第二个 mr job 再根据预处理的数据结果按照 group by key 分布到 reduce 中(这个过程可以保证相同的 group by key 被分布到同一个 reduce 中),最后完成最终的聚合操作。
2、当map端文件数过多时
set hive.merge.mapfiles=true
set mapred.map.tasks 增大
set mapred.max.split.size=134217728 调整每个map读取文件的大小
3、当hiveql中包含count(distinct)时
如果数据量非常大,执行如select a,count(distinct b) from t group by a;类型的sql时,会出现数据倾斜的问题。
解决方法:使用sum...group by代替。如select a,sum(1) from (select a, b from t group by a,b) group by a;
4)当遇到一个大表和一个小表进行join操作时。
解决方法:使用mapjoin 将小表加载到内存中。
如:select /*+ mapjoin(a) */
a.c1, b.c1 ,b.c2
from a join b
where a.c1 = b.c1;
5、(大表join大表)遇到需要进行join的但是关联字段有数据为null,如表一的id需要和表二的id进行关联,null值的reduce就会落到一个节点上
解决方法1:子查询中过滤掉null值,id为空的不参与关联
解决方法2:用case when给空值分配随机的key值(字符串+rand())
from trackinfo a
left outer join pm_info b
on (
case when (a.ext_field7 is not null
and length(a.ext_field7) > 0
and a.ext_field7 rlike '^[0-9]+$')
then
cast(a.ext_field7 as bigint)
else
cast(ceiling(rand() * -65535) as bigint)
end = b.id
)
6、不同数据类型关联产生数据倾斜,需要转换
from trackinfo a
left outer join pm_info b
on (cast(a.ext_field7 as bigint) = b.id)
https://www.cnblogs.com/shaosks/p/9491905.html
=============================================================
hive使用tez作为计算引擎,hive使用2.3.6,tez使用0.9.1,hadoop使用2.7.3
tar -zxvf apache-tez-0.9.1-bin.tar.gz
将tez目录下的share/tez.tar.gz包上传到hdfs的/tez目录下
vim hive-env.sh
#添加以下配置
# set hadoop_home to point to a specific hadoop install directory
export hadoop_home=/app/hadoop-2.7.4 #这是你hadoop的安装目录
# hive configuration directory can be controlled by:
export hive_conf_dir=/app/hive-2.3.6/conf #这是你hive配置文件的目录
# folder containing extra libraries required for hive compilation/execution can be controlled by:
export tez_home=/app/tez-0.9.1 #是你的tez的解压目录
export tez_jars=""
for jar in `ls $tez_home |grep jar`; do
export tez_jars=$tez_jars:$tez_home/$jar
done
for jar in `ls $tez_home/lib`; do
export tez_jars=$tez_jars:$tez_home/lib/$jar
done
export hive_aux_jars_path=/app/hadoop-2.7.4/share/hadoop/common/hadoop-lzo-0.4.20.jar$tez_jars #这是引用的hadoop下的jar包路径
在hive-site.xml下添加
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
在hive/conf目录下新增tez-site.xml
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<!-- 这是设置tez在hdfs上的lib包路径-->
<name>tez.lib.uris</name>
<value>${fs.defaultfs}/tez/tez.tar.gz</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>tez.history.logging.service.class</name> <value>org.apache.tez.dag.history.logging.ats.atshistoryloggingservice</value>
</property>
</configuration>
测试
create table student(
id int,
name string);
insert into student values(1,"zhangsan");
select * from student;
可以在yarn-site.xml上添加如下配置
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
关闭内存检查
-------------------------------------
在hive中更换引擎
set hive.execution.engine=tez
set hive.execution.engine=mr
-----------------------------------------
hive启动时设置调试模式
hive --hiveconf hive.root.logger=debug,console
-------------------------------------------
hive使用tez引擎指定yarn队列需要
set tez.queue.name=etl
如果使用mapreduce引擎需要指定yarn队列
set mapreduce.job.queuename=etl
--------------------------------------------
如果hive集成tez后再换回mapreduce执行引擎报错
那么将hadoop安装包中的jar包
hadoop-mapreduce-client-common-2.7.3.jar和
hadoop-mapreduce-client-core-2.7.3.jar
拷贝到tez安装目录的lib目录下替换tez中的相对应jar包
================================================
hive使用lzo压缩
create table lzo(
id int,
name string)
row format delimited fields terminated by '\t'
stored as inputformat 'com.hadoop.mapred.deprecatedlzotextinputformat'
outputformat 'org.apache.hadoop.hive.ql.io.hiveignorekeytextoutputformat';
然后load data数据是lzo文件就可以识别
需要自己做lzo索引
----------------
如果表已经存在,需要从新支持lzo
alter table things
set fileformat
inputformat "com.hadoop.mapred.deprecatedlzotextinputformat"
outputformat "org.apache.hadoop.hive.ql.io.hiveignorekeytextoutputformat";
alter table后对已经load进表中的数据,需要重新load和创建索引,要不还是不能分块。
-----------------
如果需要执行
insert into t
select
这种语句,而且插入的表是lzo压缩的
需要设置
set hive.exec.compress.output=true;
set mapred.output.compression.codec=com.hadoop.compression.lzo.lzopcodec;
==========================================================
hive使用snappy
创建orc+snappy组合的表
create table t_people_snappy(id int,age int,name string,sex string)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="snappy")
insert into table t_people_snappy
select
* from t_people
-------------------------
创建parquet+snappy组合的表
set parquet.compression=snappy;
create table t_people_parquet_snappy(id int,age int,name string,sex string)
row format delimited fields terminated by "\t"
stored as parquet
insert into table t_people_parquet_snappy
select
* from t_people
---------------------------------
#开启mr中间文件压缩
set hive.exec.compress.intermediate=true;
#开启mr,map阶段输出压缩功能
set mapreduce.map.output.compress=true;
#设置hadoop的mapreduce任务中map阶段压缩算法
set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.snappycodec;
#开启hive最终查询结果输出文件压缩功能:
set hive.exec.compress.output=true;
#开启hadoop中的mr任务的最终输出文件压缩:
set mapreduce.output.fileoutputformat.compress=true;
#设置hadoop中mr任务的最终输出文件压缩算法(对应的编/解码器)
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.snappycodec;
#设置hadoop中mr任务序列化文件的压缩类型,默认为record即按照记录record级别压缩(建议设置成block):
set mapreduce.output.fileoutputformat.compress.type=block;
数据库三范式
第一范式,又称1nf,它指的是bai在一个应用中的数据du都可以组织成由行和列的表zhi格形式,且表格的任意一个dao行列交叉点即单元格,都不可再划分为行和列的形式,实际上任意一张表格都满足1nf; 第二范式,又称2nf,它指的是在满足1nf的基础上,一张数据表中的任何非主键字段都全部依赖于主键字段,没有任何非主键字段只依赖于主键字段的一部分。即,可以由主键字段来唯一的确定一条记录。比如学号+课程号的联合主键,可以唯一的确定某个成绩是哪个学员的哪门课的成绩,缺少学号或者缺少课程号,都不能确定成绩的意义。 第三范式,又称3nf,它是指在满足2nf的基础上,数据表的任何非主键字段之间都不产生函数依赖,即非主键字段之间没有依赖关系,全部只依赖于主键字段。例如将学员姓名和所属班级名称放在同一张表中是不科学的,因为学员依赖于班级,可将学员信息和班级信息单独存放,以满足3nf。
第二范式
定义:如果关系模式r是1nf,且每个非主属性完全函数依赖于候选键,那么就称r是第二范式
简单的说,首先要满足第一范式,其次每个非主属性完全依赖于主键。也就是说,每个非主属性是由整个主键函数决定的,而不能由主键的一部分来决定。第二范式可以说是消除部分依赖。第二范式可以减少插入异常,删除异常和修改异常。
案例:
学生 课程 教师 教师职称 教材 教室 上课时间
李四 spring 张老师 java讲师 《spring深入浅出》 301 08:00
张三 struts 杨老师 java讲师 《struts in action》302 13:00
这里通过(学生,课程)可以确定教师、教师职称、教材、教室和上课时间,所以可以把(学生,课程)作为主键。但是,教材并不完全依赖于(学生,课程),只拿出课程就可以确定教材,这就叫不完全依赖,或者部分依赖。出现这种情况,就不满足二范式。
设计表的时候,只设计一个主键可以规避掉这个问题
变为正确的是
选课表
学生 课程 教师 教师职称 教室 上课时间
李四 spring 张老师 java讲师 301 08:00
张三 struts 杨老师 java讲师 302 13:00
教材表
课程 教材
spring 《spring深入浅出》
struts 《struts in action》
-----------------------------------------
第三范式
定义:如果关系模式r是2nf,且关系模式r(u,f)中的所有非主属性对任何候选关键字都不存在传递依赖,则称关系r是属于第三范式
简单的说,第三范式满足以下的条件:首先要满足第二范式,其次非主属性之间不存在依赖。由于满足了第二范式,表示每个非主属性都依赖于主键,如果非主属性之间存在了依赖,就会存在传递依赖,这样就不满足第三范式。
案例
学生 课程 教师 教师职称 教室 上课时间
李四 spring 张老师 java讲师 301 08:00
张三 struts 杨老师 java讲师 302 13:00
上例中修改后的选课表中,一个教师能确定一个教师职称,这样,教师依赖于(学生,课程),而教师职称又依赖于教师,这叫传递依赖。第三范式就是要消除传递依赖变更为正确的
学生 课程 教师 教室 上课时间
李四 spring 张老师 301 08:00
张三 struts 杨老师 302 13:00
教师表
教师 教师职称
张老师 java讲师
杨老师 java讲师
====================================================
[hive]新增字段(column)后,旧分区无法更新数据问题
解决方法很简单,就是增加col1时加上cascade关键字。示例如下:
alter table tb add columns(col1 string) cascade;
https://blog.csdn.net/elecjack/article/details/89391244
====================================================
hive udaf求平均数
package com.bawei.hive.udf;
import org.apache.hadoop.hive.ql.exec.udfargumenttypeexception;
import org.apache.hadoop.hive.ql.metadata.hiveexception;
import org.apache.hadoop.hive.ql.parse.semanticexception;
import org.apache.hadoop.hive.ql.udf.generic.abstractgenericudafresolver;
import org.apache.hadoop.hive.ql.udf.generic.genericudafevaluator;
import org.apache.hadoop.hive.serde2.lazy.lazydouble;
import org.apache.hadoop.hive.serde2.lazybinary.lazybinarystruct;
import org.apache.hadoop.hive.serde2.objectinspector.objectinspector;
import org.apache.hadoop.hive.serde2.objectinspector.objectinspectorfactory;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.primitiveobjectinspectorfactory;
import org.apache.hadoop.hive.serde2.typeinfo.typeinfo;
import org.apache.hadoop.io.doublewritable;
import org.apache.hadoop.io.longwritable;
import java.util.arraylist;
public class demoudaf extends abstractgenericudafresolver {
@override
public genericudafevaluator getevaluator(typeinfo[] info) throws semanticexception {
if(info.length !=1){
throw new udfargumenttypeexception(info.length-1,
"exactly two argument is expected.");
}
return new myevaluate();
}
public static class myevaluate extends genericudafevaluator {
object[] mapout;
@override
public objectinspector init(mode m, objectinspector[] parameters) throws hiveexception {
super.init(m,parameters);
if(m == mode.partial1 || m == mode.partial2) {
//map阶段
arraylist<string> fieldnames = new arraylist<>();
arraylist<objectinspector> fieldtypes = new arraylist<>();
fieldnames.add("sum");
fieldnames.add("count");
fieldtypes.add(primitiveobjectinspectorfactory.writabledoubleobjectinspector);
fieldtypes.add(primitiveobjectinspectorfactory.writablelongobjectinspector);
mapout = new object[2];
return objectinspectorfactory.getstandardstructobjectinspector(fieldnames,fieldtypes);
} else {
//reduce阶段
return primitiveobjectinspectorfactory.writabledoubleobjectinspector;
}
}
private static class myaggregationbuffer implements aggregationbuffer {
double sum;
long count;
}
@override
public aggregationbuffer getnewaggregationbuffer() throws hiveexception {
myaggregationbuffer myaggregationbuffer = new myaggregationbuffer();
reset(myaggregationbuffer);
return myaggregationbuffer;
}
@override
public void reset(aggregationbuffer agg) throws hiveexception {
myaggregationbuffer myaggregationbuffer = (myaggregationbuffer) agg;
myaggregationbuffer.sum = 0d;
myaggregationbuffer.count = 0l;
}
@override
public void iterate(aggregationbuffer agg, object[] parameters) throws hiveexception {
lazydouble value = (lazydouble)parameters[0];
double v = value.getwritableobject().get();
myaggregationbuffer myaggregationbuffer = (myaggregationbuffer) agg;
myaggregationbuffer.count = myaggregationbuffer.count + 1l;
myaggregationbuffer.sum = myaggregationbuffer.sum + v;
}
@override
public object terminatepartial(aggregationbuffer agg) throws hiveexception {
myaggregationbuffer myaggregationbuffer = (myaggregationbuffer) agg;
doublewritable sum = new doublewritable(myaggregationbuffer.sum);
longwritable count = new longwritable(myaggregationbuffer.count);
mapout[0] = sum;
mapout[1] = count;
return mapout;
}
@override
public void merge(aggregationbuffer agg, object partial) throws hiveexception {
if (partial instanceof lazybinarystruct) {
// 强转参数
lazybinarystruct lbs = (lazybinarystruct) partial;
doublewritable sum = (doublewritable) lbs.getfield(0);
longwritable count = (longwritable) lbs.getfield(1);
// 将本次map输出的数据放到reducer的缓冲区
myaggregationbuffer ab = (myaggregationbuffer) agg;
ab.sum = ab.sum + sum.get();
ab.count = ab.count + count.get();
}
}
@override
public object terminate(aggregationbuffer agg) throws hiveexception {
myaggregationbuffer myaggregationbuffer = (myaggregationbuffer) agg;
double avg = myaggregationbuffer.sum / myaggregationbuffer.count;
return new doublewritable(avg);
}
}
}
======================================================
sql=""
hive -e "$sql"
这里面的sql如果要用转义字符表示特殊字符,那就要用\\\\n
例如: split(line,'\\\\|')
===============================================================
select
url,count(url) cnts
from t group by url
count(url)和count(*)有什么区别
count(url)当url有null值时,不参与统计
count(1)或count(*),不会排除url为空的情况


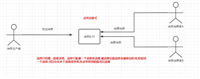
发表评论