目录
一、环境配置
1、java环境
% java -version
java version "1.8.0_202"
java(tm) se runtime environment (build 1.8.0_202-b08)
java hotspot(tm) 64-bit server vm (build 25.202-b08, mixed mode)2、scala环境
scala -version
scala code runner version 2.12.12 -- copyright 2002-2020, lamp/epfl and lightbend, inc.
3、python环境
% python -v
python 3.9.12
4、启动spark集群(只有本机一个节点)
(1)启动脚本
/users/van/desktop/hadoop/spark-3.3.2-bin-hadoop2/sbin/start-all.sh #启动脚本 (2)查看状态
http://localhost:8080 #访问端口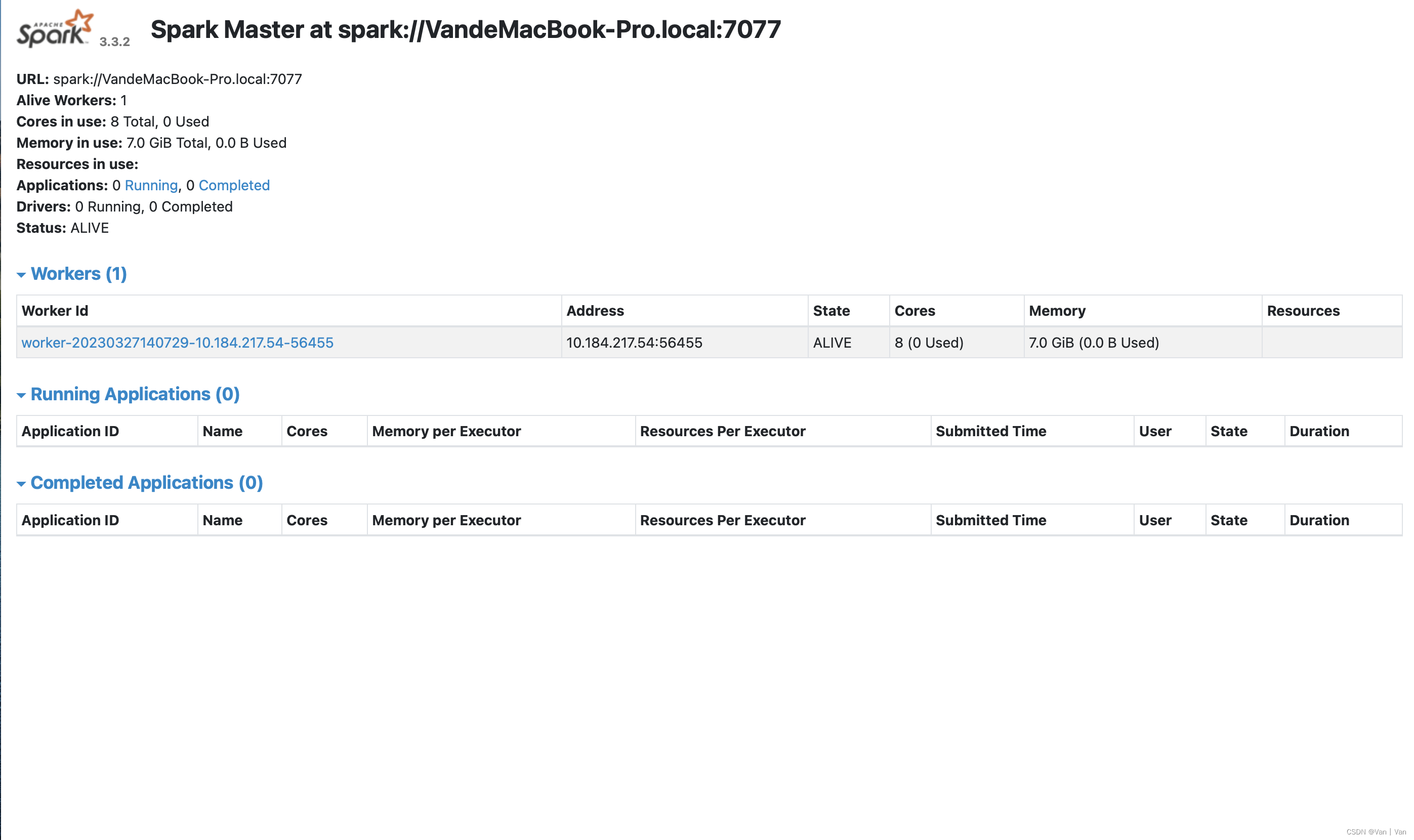
5、启动hdfs(这里环境安装在虚拟机)
(1)启动脚本
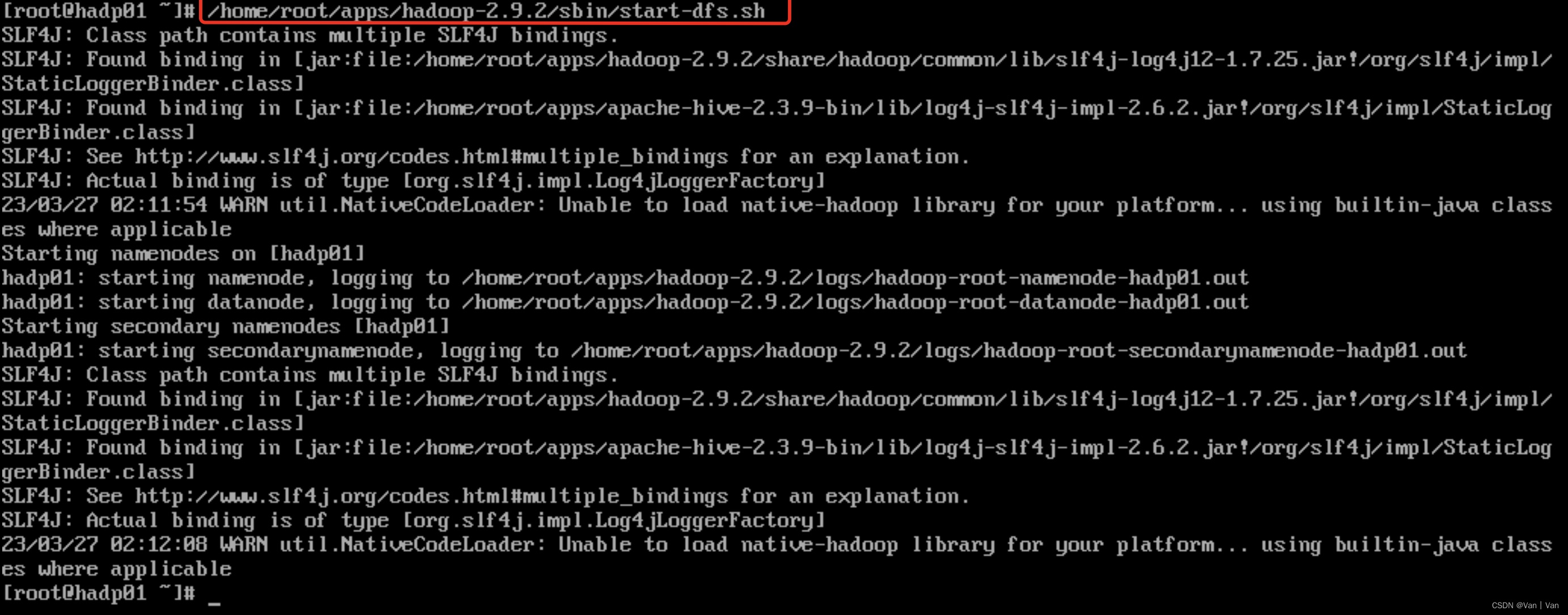
(2)查看状态
http://192.168.151.3:50070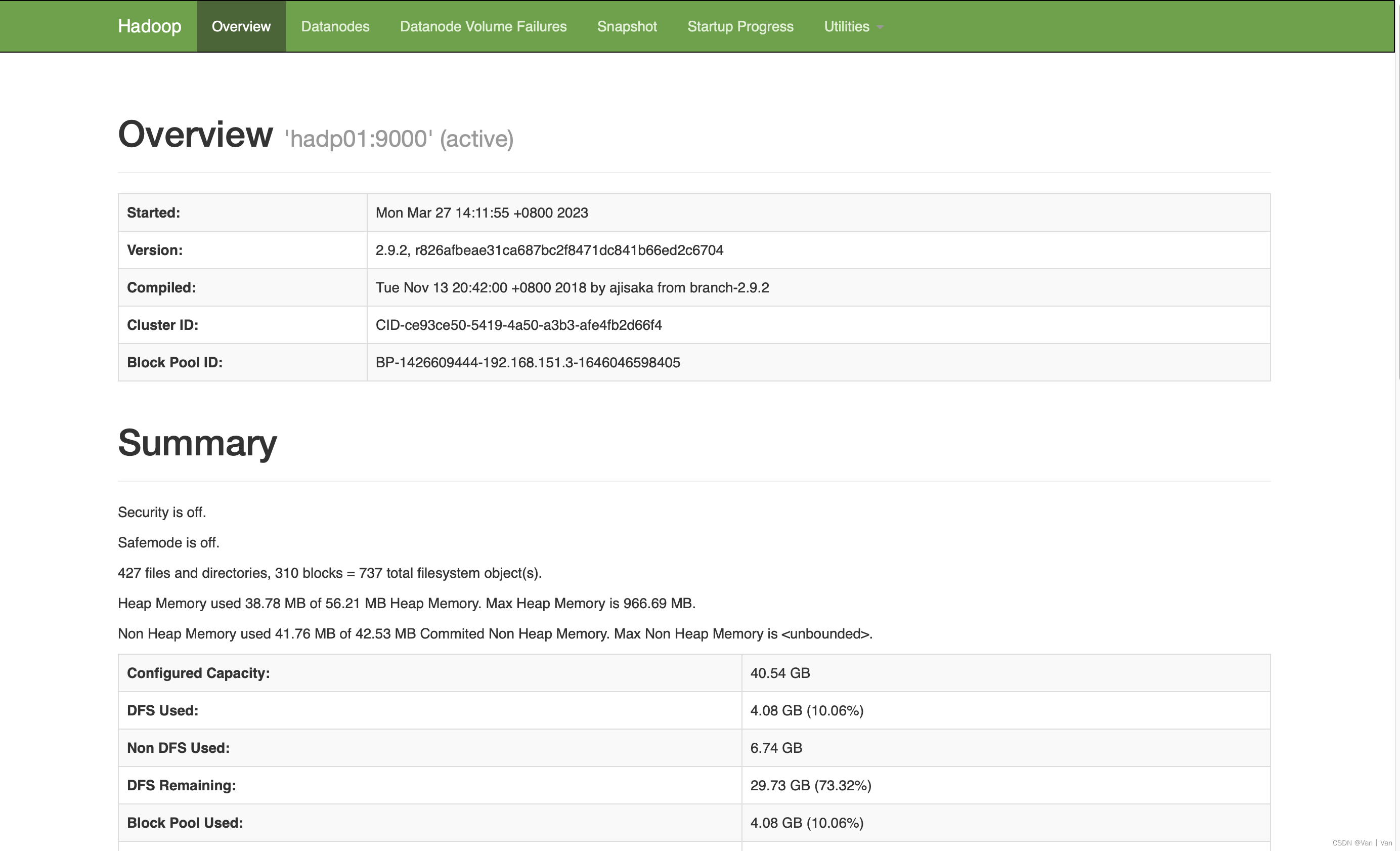
二、通过python编写代码提交
1、pyspark
2、代码
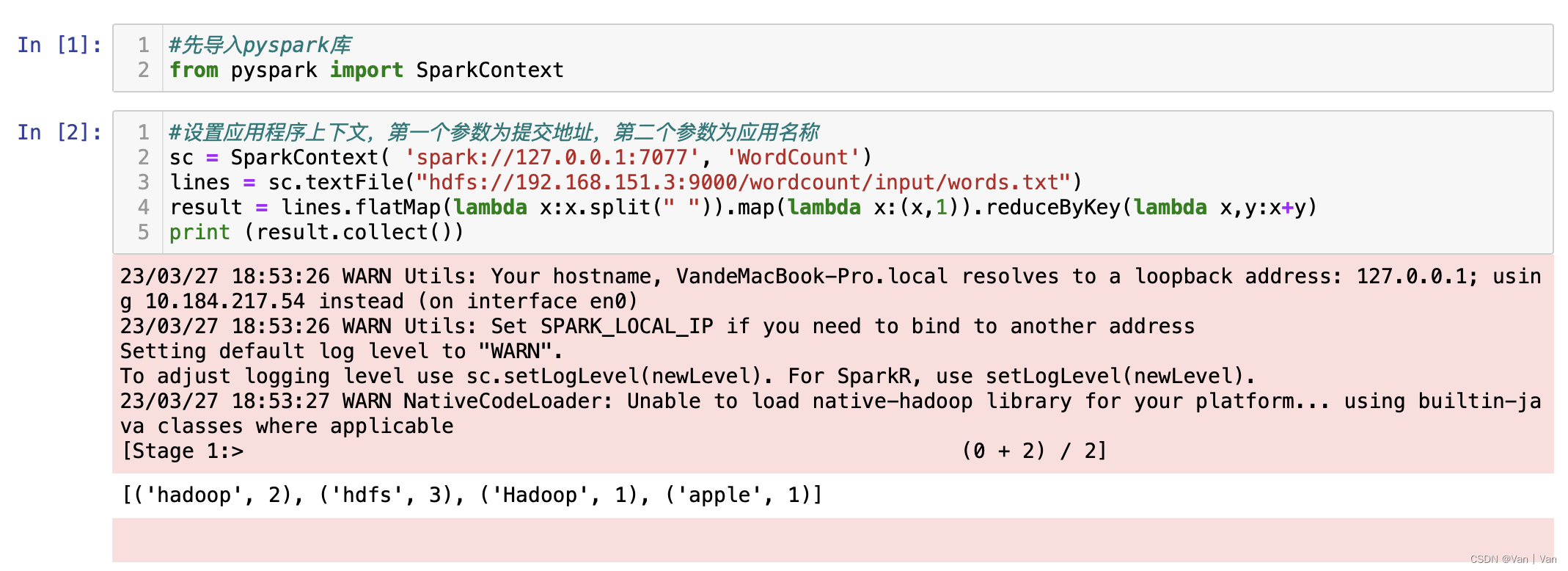
首先是导入pyspark库中的sparkcontext,这是一个spark上下文,通过定义该对象进行相关操作,然后就是设置提交地址和应用名称,如果是选择本地运行的话第一个参数就可以填'local'或者'local[*]'。然后读取文件,文件输入的是hdfs地址,虽然它提供的web访问页面端口是50070但是要访问文件的话端口得设置为9000。然后是wordcount的代码本体。最后是输出操作的结果。
#先导入pyspark库
from pyspark import sparkcontext
#设置应用程序上下文,第一个参数为提交地址,第二个参数为应用名称
sc = sparkcontext( 'spark://127.0.0.1:7077', 'wordcount')
lines=sc.textfile("hdfs://192.168.151.3:9000/wordcount/input/words.txt")
result = lines.flatmap(lambda x:x.split(" ")).map(lambda x:(x,1)).reducebykey(lambda x,y:x+y)
print (result.collect())output:[('hadoop', 2), ('hdfs', 3), ('hadoop', 1), ('apple', 1)]3、运行过程
首先我们需要启动hdfs,然后启动spark。这两步完成之后,就可以运行代码了。这里还算比较方便的(相比于后面讲到的scala)。这里运行完成之后可以看到下面单词计数的结果已经出来了。
这个时候可以通过spark的web页面看到此时正在运行一个应用,状态是running,而且我们可以继续进行操作(在jupyter中编写代码然后运行),应用不会停止。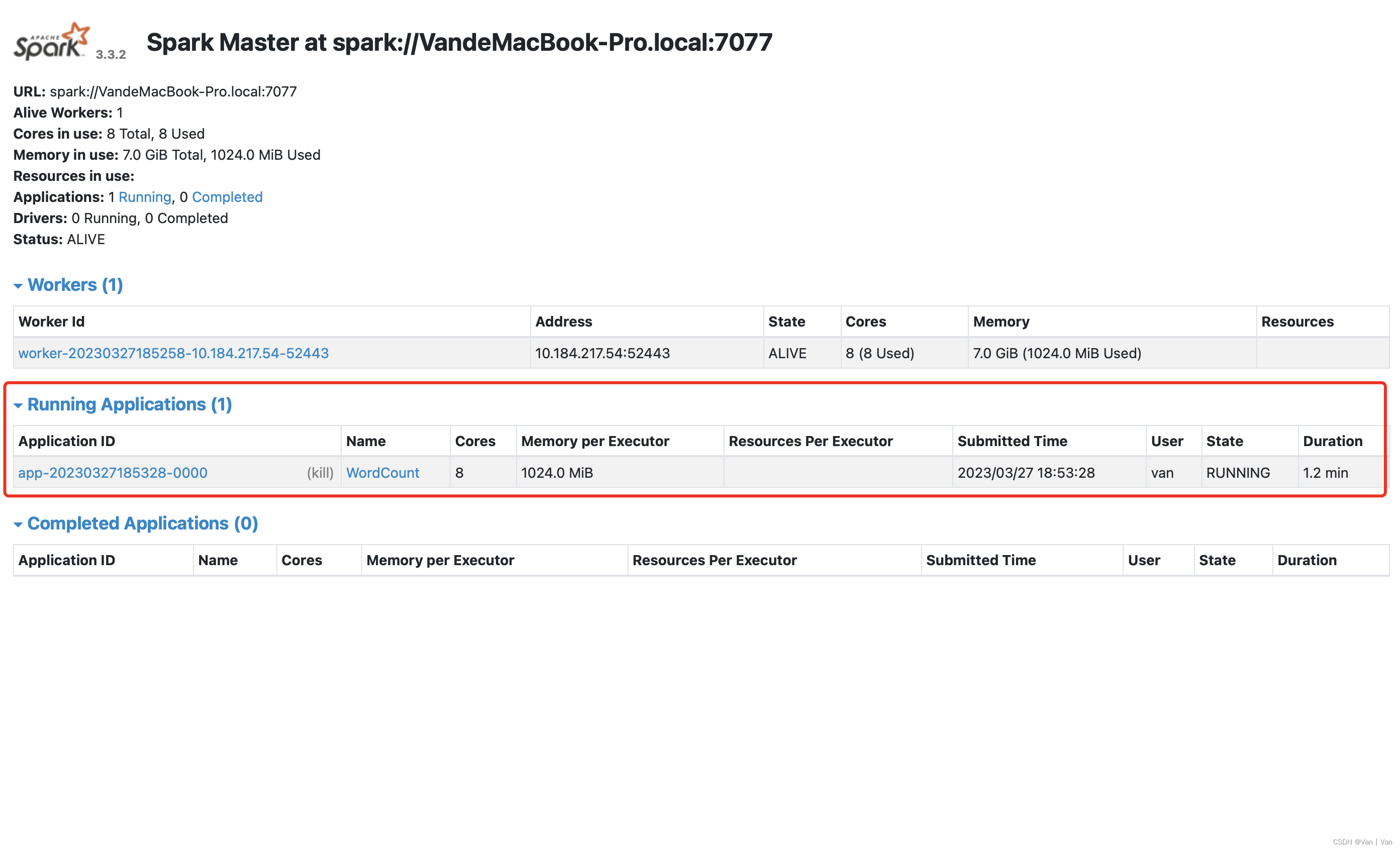
直到我们输入sc.stop(),这个应用才会结束。结束之后这个应用就会显示在下方,然后可以看到它的状态是finished。到这里通过python来完成从hdfs读取文件然后提交应用到集群的过程就完成了。
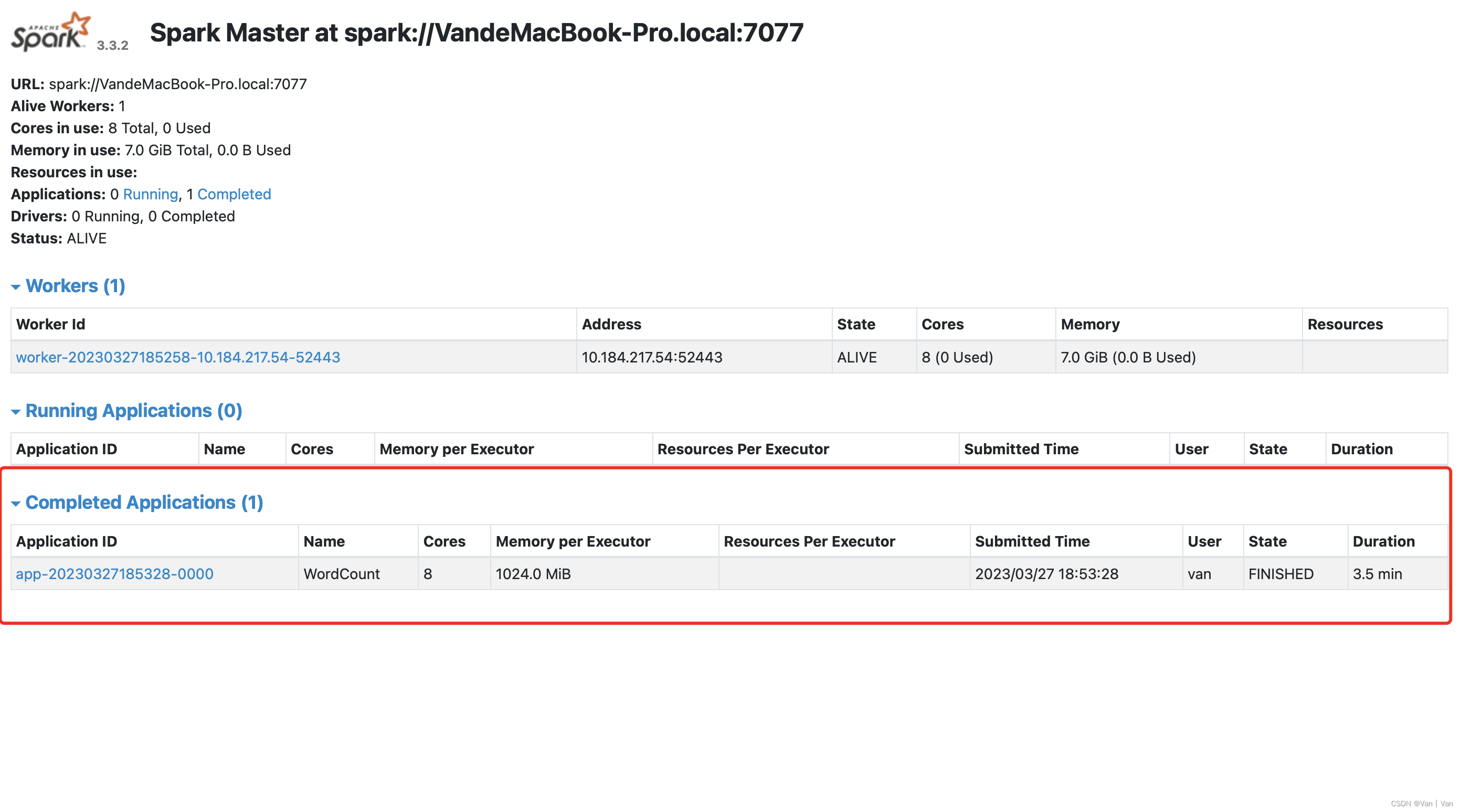
三、通过scala编写代码提交
1、环境准备
这里scala我是通过idea创建的,因为之后要通过sbt打包项目上传(本来写到这里的时候我只用单机运行,但是发现了之前找了好久都没找到的sbt,于是就去完成了一下)似乎是因为java语言的关系不能直接提交到集群,还不太懂。
这是整个的项目结构,其中非常非常重要的一点是,因为此前没有接触过sbt,所以搞它的依赖的时候我直接通过idea导入库,发现可以通过idea运行,但是不能通过sbt打包,打包会显示无依赖,然后我就去官方文档看了一下,要把依赖放在lib下或者取build.sbt上添加。于是我就把spark-core的jar复制到了lib下,但远不止于此,还有很多很多依赖,于是我就把spark的所有依赖复制到了这里。然后通过sbt重新加载、打包。然后就成功了。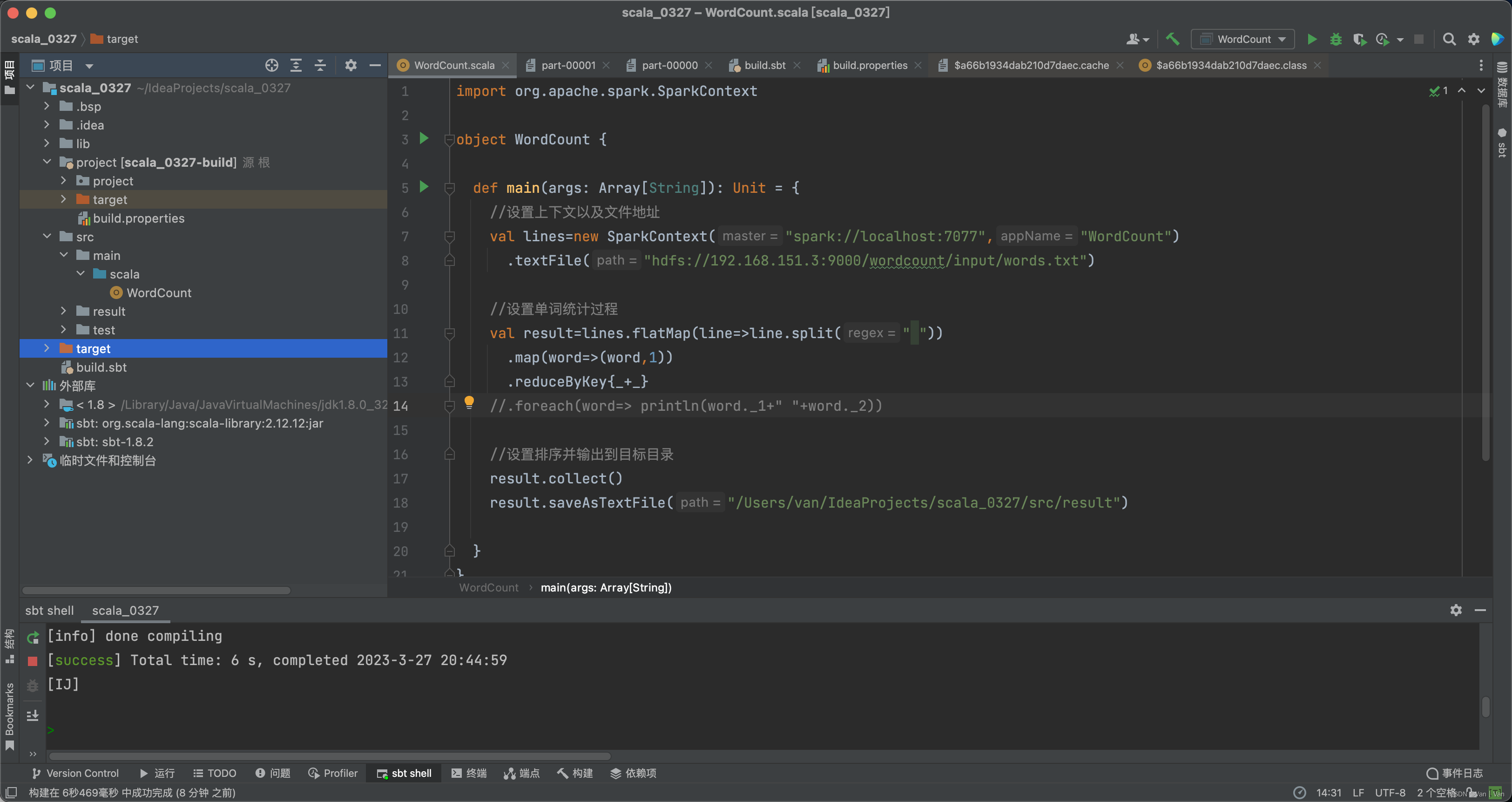
2、代码
代码与python写的类似,不过最重要的一点是,idea不能直接连集群。就是在设置上下文对象的地址属性时,只能选择local,像我下面这样写然后提交是会失败的。唯一的解决方案就是通过sbt打包上传运行。
import org.apache.spark.sparkcontext
object wordcount {
def main(args: array[string]): unit = {
//设置上下文以及文件地址
val lines=new sparkcontext("spark://localhost:7077","wordcount")
.textfile("hdfs://192.168.151.3:9000/wordcount/input/words.txt")
//设置单词统计过程
val result=lines.flatmap(line=>line.split(" "))
.map(word=>(word,1))
.reducebykey{_+_}
//.foreach(word=> println(word._1+" "+word._2))
//设置排序并输出到目标目录
result.collect()
result.saveastextfile("/users/van/ideaprojects/scala_0327/src/result")
}
}
3、上传应用
上传通过的是spark-submit,如果配置好了环境变量的就可以直接输spark-submit加参数就可以了。输入下面这么一串。然后等待运行
(base) van@vandemacbook-pro ~ % spark-submit --class "wordcount" /users/van/ideaprojects/scala_0327/target/scala-2.12/scala_0327_2.12-0.1.0-snapshot.jar 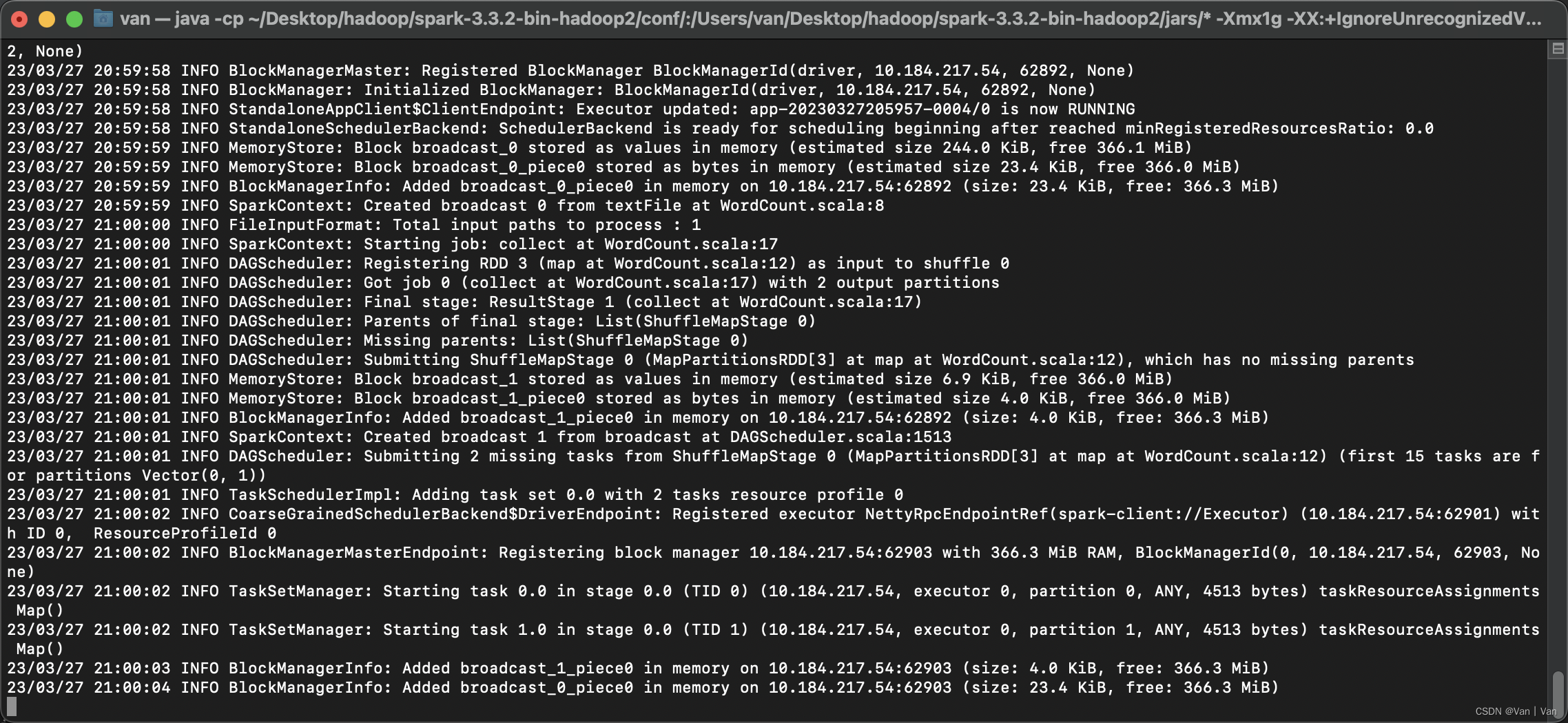
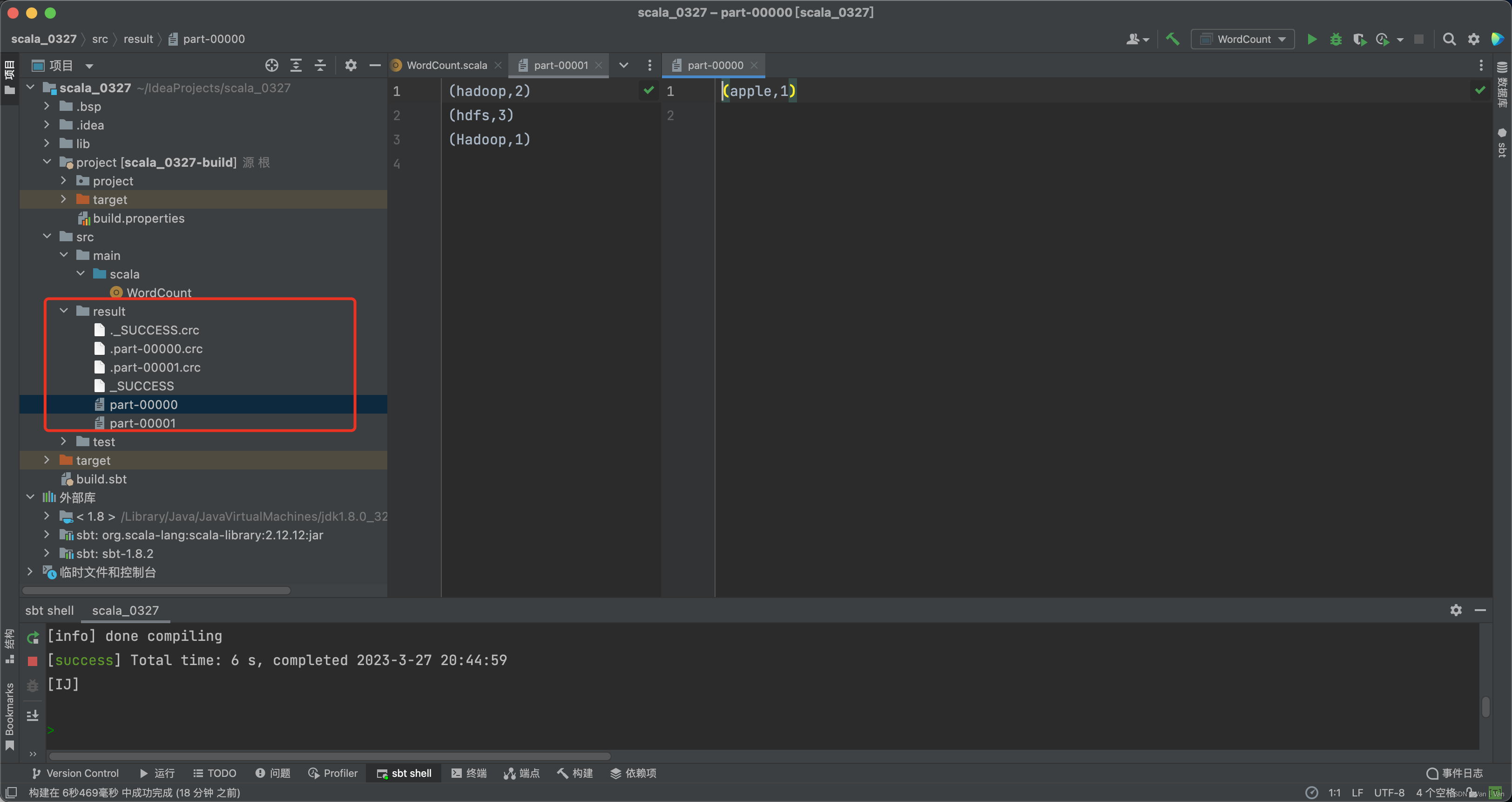
运行结束之后我们查看一下是否有输出结果,代码中我设置的输出结果就在项目目录里。这里可以看到输出结果,但是结果有两个文件,这个还不知道是什么原因,之前运行是只有一个文件的。 到这里就可以看出这样打包上传的不好之处,就是在测试的时候就很麻烦,不像在jupyter里面直接可以接着测试,可能是现在还没接触生产环境的原因吧。
四、总结
本文用来记录一下学习spark的过程,学习过程中一个个的定目标、解决bug还是挺有意思的。有不对的地方还请指出。


发表评论