大数据Hadoop之——部署hadoop+hive+Mysql环境(Linux)
-是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是 true -->--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true -->-- 关闭yarn内存检查 flink on hadoop 配置-->-- 指定HDFS中NameNode的地址 默认 9000端口-->-- 指定Hadoop运行时产生文件的存储目录 -->-- 2nn web端访问地址 可以不配置-->-- 历史服务器web端地址 -->
目录
前期准备
一、jdk的安装
1、安装jdk
2、配置java环境变量
3、加载环境变量
4、进行校验
二、hadoop的集群搭建
1、hadoop的下载安装
2、配置文件设置
2.1. 配置 hadoop-env.sh
2.2. 配置 core-site.xml
2.3. 配置hdfs-site.xml
2.4. 配置 yarn-site.xml
2.5. 配置 mapred-site.xml
2.6. 配置 workers(伪分布式不配置)
2.7 配置sbin下启停命令
3、复制hadoop到其他节点(伪分布式不执行此步)
4、hdfs格式化
5、启动hdfs分布式文件系统
三、msyql安装
1、卸载旧mysql文件
2、mysql下载安装
3、配置环境变量
4、删除用户组
5、创建用户和组
6、创建文件夹
7、更改权限
8、初始化
9、记住初始密码
10 将mysql加入到服务中
11、配置文件
12、设置开机启动并查看进程
13、 创建软连接
14、授权修改密码
四、hive安装
1、下载安装
2、配置环境变量
3、配置文件
4、拷贝jar包
5、初始化
6、启动hive
前期准备
设置虚拟机
vi /etc/syscnfig/network-scripts/ifcfg-eth1
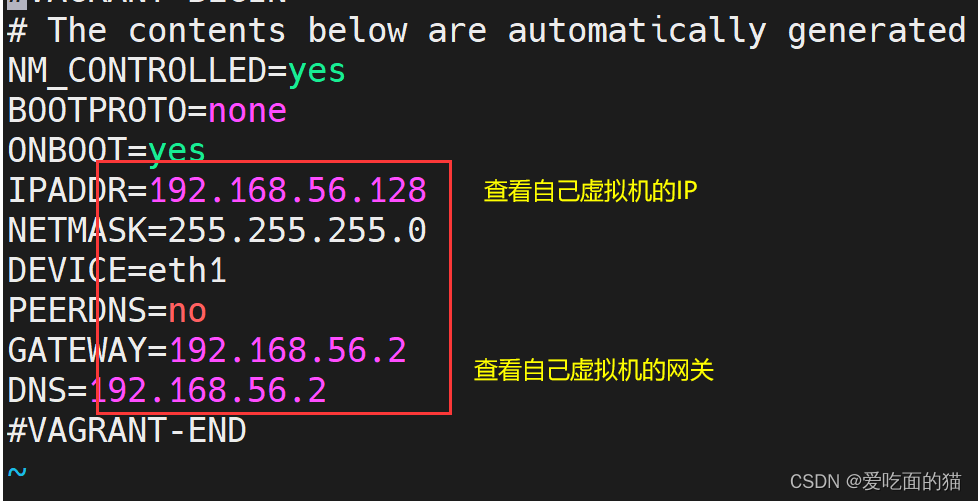
设置主机名
配置ip与主机名映射
vi /etc/hosts

关闭防火墙
一、jdk的安装
1、安装jdk
2、配置java环境变量
vi ~/.bash_profile (或 /etc/profile 或 ~/.profile 或 ~/.bashrc 或 /etc/bashrc 或 /etc/bash.bashrc[在ubuntu 中的位置])
3、加载环境变量
4、进行校验

二、hadoop的集群搭建
1、hadoop的下载安装
2、配置文件设置
2.1. 配置 hadoop-env.sh
2.2. 配置 core-site.xml
2.3. 配置hdfs-site.xml
2.4. 配置 yarn-site.xml
2.5. 配置 mapred-site.xml
2.6. 配置 workers(伪分布式不配置)
2.7 配置sbin下启停命令
3、复制hadoop到其他节点(伪分布式不执行此步)
4、hdfs格式化
5、启动hdfs分布式文件系统
6、启动yarn
三、msyql安装
1、卸载旧mysql文件
2、mysql下载安装
3、配置环境变量
4、删除用户组
5、创建用户和组
6、创建文件夹
7、更改权限
8、初始化
9、记住初始密码

10 将mysql加入到服务中
11、配置文件
12、设置开机启动并查看进程
13、 创建软连接
14、授权修改密码
四、hive安装
1、下载安装
2、配置环境变量
3、配置文件
配置hive-env.sh
配置hive-site.xml
4、拷贝jar包
5、初始化
6、启动hive
相关文章:
-
-
BI:Business Intelligence,商业智能。指用现代数据仓库技术、线上分析处理技术、数据挖掘和数据展现技术进行分析以实现商业价值。简单来说,就是借助BI工具,可以完…
-
-
此篇博客主要记录我大三下学期大数据原理与技术这门课程的大作业内容…
-
MapReduce思想在生活中处处可见。MapReduce 的思想核心是“分而治之”,适用于大规模数据处理场景。Map负责“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理…
-
我本硕都是双非计算机专业,从研一下开始学习大数据开发的相关知识,从找实习到秋招,我投递过100+公司,拿到过10+的offer,包括滴滴、字节、蚂蚁、携程、蔚来、去哪儿等大厂(岗位…
版权声明:本文内容由互联网用户贡献,该文观点仅代表作者本人。本站仅提供信息存储服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 2386932994@qq.com 举报,一经查实将立刻删除。

发表评论