1.绪论
hadoop 是一个开源的分布式计算平台,由 apache 软件基金会开发。它的发展历程可以追溯到 2006 年,旨在处理大规模数据。如今,hadoop 已广泛应用于数据存储、数据处理、数据分析等领域,成为大数据处理的重要技术之一。
本次大作业旨在利用 hadoop 技术对豆瓣电影影评数据进行分析,通过数据采集、数据分析和数据可视化等步骤,实现对影评数据的深入挖掘。使用的技术包括 hadoop 生态系统中的 hdfs、mapreduce、hive 等,以及 python 编写的爬虫程序。目标是获取影评数据,并进行统计分析和可视化展示。基本步骤包括环境搭建、数据采集、数据分析和数据可视化。
2.环境搭建
2.1系统环境
linux的版本采用的是centos7 内存2gb 处理器4 硬盘20gb
图2-1
2.2 编程环境
1.java 版本 jdk1.8.0

图2-2
2.hadoop版本 hadoop-3.3.0

图2-3
3.根据之前的三次实验hadoop hdfs hbase 都已经配置完成
图2-4
4.hive的安装配置
先把下载好的安装包上传到虚拟机:rz
图2-5
4.1下载好之后解压
tar -zxf apache-hive-3.1.0-bin.tar.gz-c /opt/module
mv apache-hive-3.1.0-bin hive
解压到/opt/module目录下并且重命名为hive
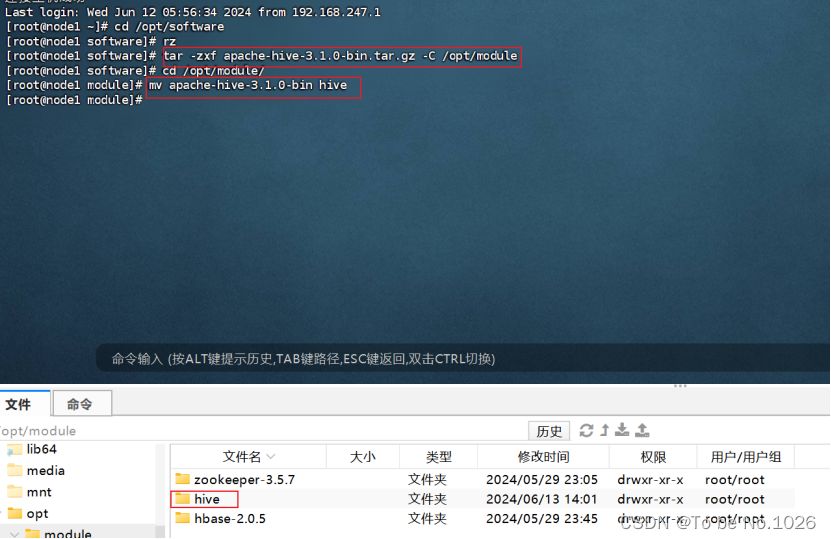
图2-6
4.2配置环境变量
vim /etc/profile
export hive_home=/opt/hive
export path=$hive_home/bin:$path
配置完成之后启动查看版本号时,报错百度查找原因得知:
1.系统找不到相关jar包
2.同一类型的 jar 包有不同版本存在,系统无法决定使用哪一个
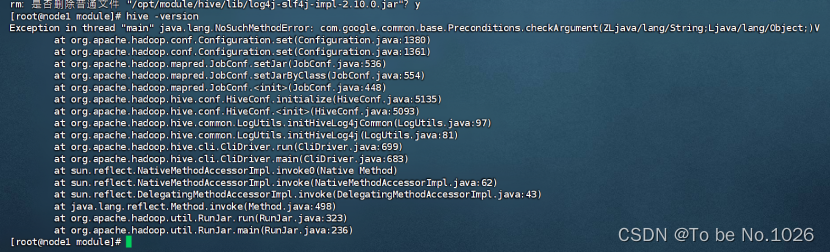
图2-7
删除版本较低的guava-19.0.jar包,把高版本的guava-27.0-jre.jar复制到hive的lib目录下
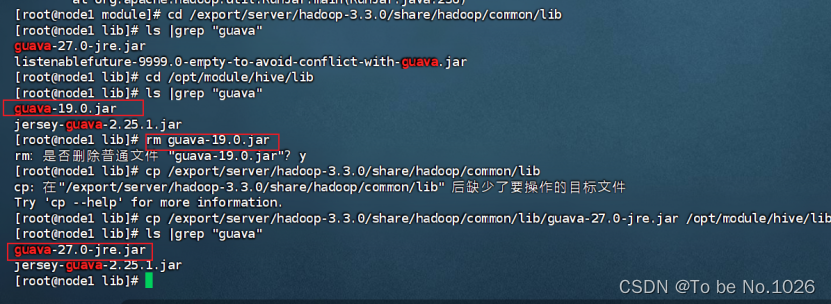
图2-8
hive-site.xml文件的配置
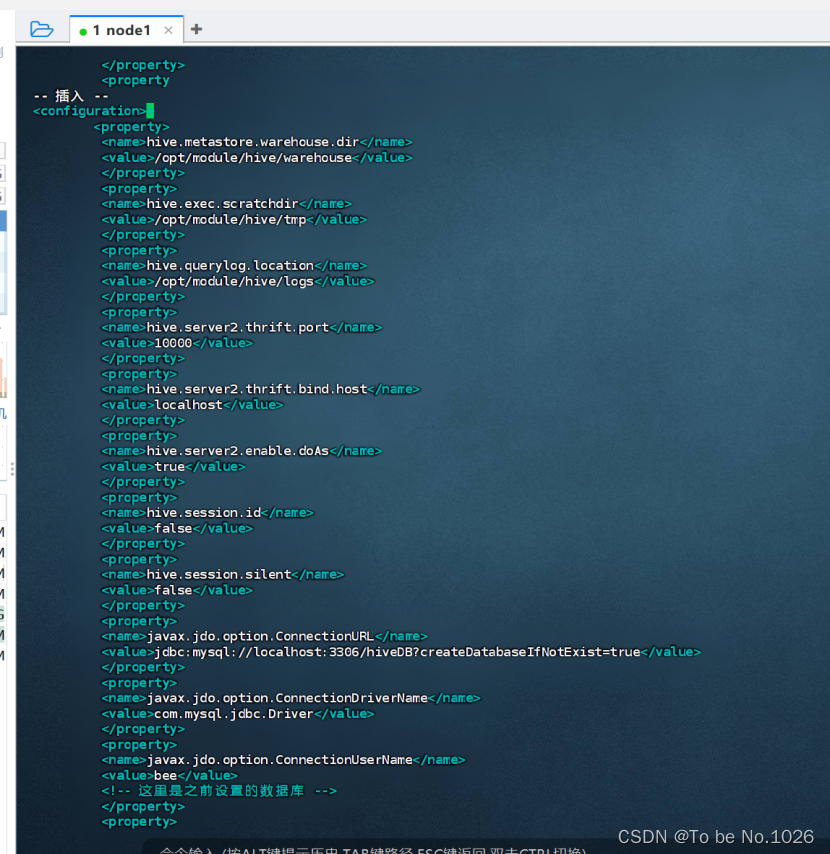
图2-9
初始化元数据信息schematool -dbtype mysql -initschema
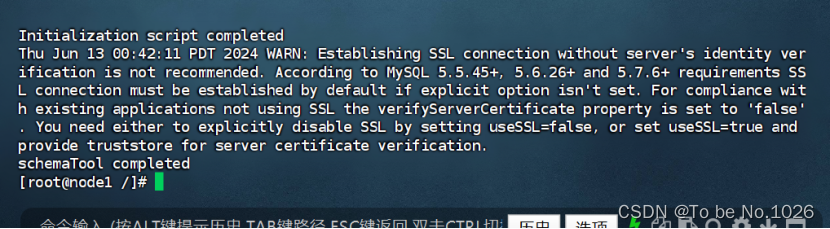
图2-10
先启动hadoop 指令start-all.sh
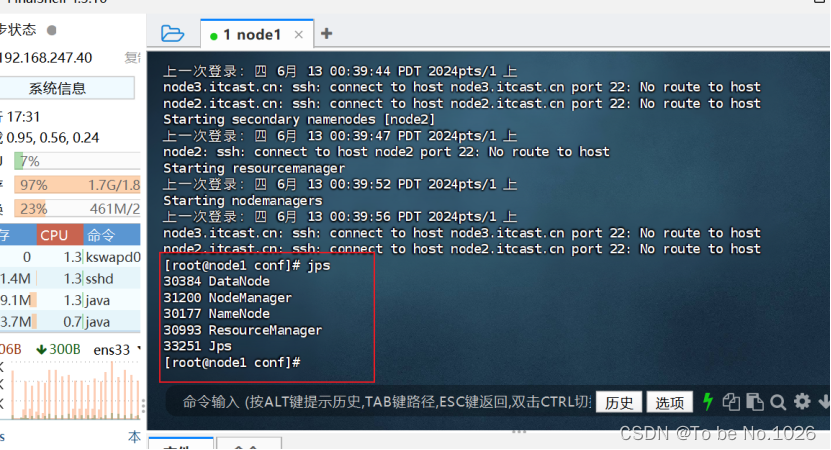
图2-11
进入hive
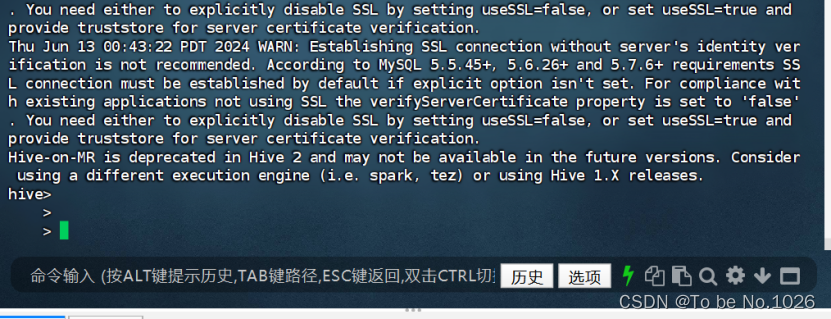
图2-12
5.python版本 python3
图2-13
python项目结构
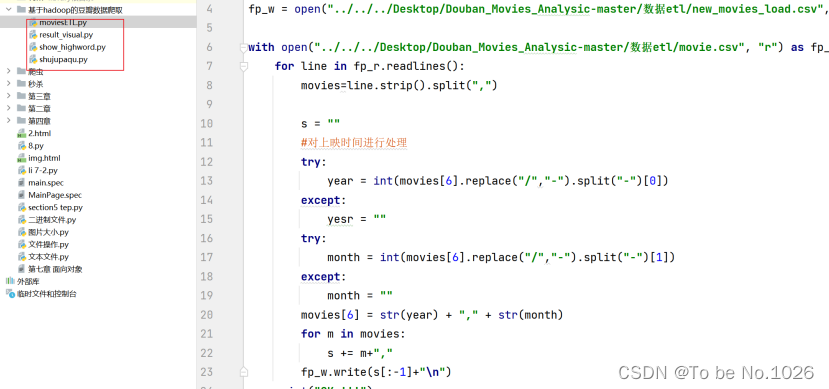
图2-14
java项目结构
图2-15
3.数据采集
3.1 爬虫简介
网络爬虫乃是一种自动的脚本或程序。它能够自动地从万维网上下载内容,而这一过程就被称作网络爬虫。网络爬虫的应用极为广泛。其一,在搜索引擎中,它可作为各类合法站点更新数据的方式。其二,爬虫软件能够当作其他网站以及网络搜索引擎更新网站内容或网站内容索引的工具。其三,网络爬虫通过对被访问页面进行复制,以供搜索引擎进一步处理从而对访问的页面进行索引。 通俗来讲,网络爬虫就是运用特定规则的办法去模仿浏览器来完成数据的读取与存储工作,从原则上说,只要是浏览器能做到的事,爬虫基本都能做到。
3.1.1 requests库简介
requests 是一个极为实用的 python http 客户端库,在进行爬虫以及测试服务器响应数据等操作时常常会用到。requests 属于 python 语言的第三方库,其专门用于发送 http 请求,在使用上比 urllib 要简洁许多。
3.1.2 beautifulsoup库简介
beautifulsoup 是 python 的一个库,其最为主要的功能便是从网页中爬取我们所需要的数据。beautifulsoup 会把 html 解析成对象来加以处理,能将整个页面转换为字典或数组的形式。
3.2 编写爬虫脚本
def getrequest(url):
header = {
"host": "movie.douban.com",
"user-agent": "mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/124.0.0.0 safari/537.36 edg/124.0.0.0",
}
r = requests.get(url, timeout=30, headers=header)
r.raise_for_status()
print(r.status_code)
return r.text
# 封装函数,爬取数据
def getdata(url, commentall):
html = getrequest(url)
# print(html)
soup = beautifulsoup(html, "html.parser")
# 找到装有所有评论的div的class名为comment-item的div
items = soup.find_all('div', class_="comment-item")
# print(items)
# 循环遍历每一条评论
for i in items:
# 找到装着用户名和星级的span标签,class名为comment-info
info = i.select(".comment-info")[0]
# print(info)
# 读出用户名的a标签里面的字符串用户名 [<a></a>]
# author = info.select("a")[0].string 数据在列表里
author = info.find("a").string
# 取星级,找到装着星级的span标签,读取title值
# ['allstar50', 'rating'] 'allstar50'表示五星好评,此处按10分计
temp = info.select("span")[1]["class"]
# print(temp)
if 'allstar' not in temp[0]:
continue
score = int(info.select("span")[1]["class"][0][7]) * 2
# 取评论,找到class名为short的p标签
comment = i.select(".short")[0].string
# 对评论进行分词,然后去掉标点符号和空格,方便统计高频词语
fenci = ' '.join(filter(lambda s: re.match("[^ ,.!;:?'\"/,。!;:?‘“”…]", s), jieba.cut(comment)))
# 将 用户名、星级、评论 装入在字典里面
talk = {"author": author, "score": score, 'fenci': fenci}
print(talk)
# 将字典类型的数据,加到列表里面
commentall.append(talk)
# 返回整个列表
return commentall
# 封装函数,把数据装入表格中
def writeinto(commentall):
save_dir = 'e:\data'
with open(os.path.join(save_dir, "douban_movie_comment1.csv"), "a+", encoding="utf-8", newline="") as file:
# 向表格写入数据
writer = csv.writer(file)
# 数据在commentall列表,循环遍历列表,读取数据
for i in commentall:
# 读取每一个字段 用户名、评分、评论
info = [i["author"], i["score"], i['fenci']]
# 把数据写入表格
writer.writerow(info)
# 关闭表格
file.close()
# 直接输入main,有提示
if __name__ == '__main__':
# 初始化一个空列表,将得到的所有数据
commentall = []
start, end = 0, 10 # 爬取的页数,爬取的评论数:end-start * 20,值不应过大,防止被拒绝访问
for i in range(start, end):
url = "https://movie.douban.com/subject/1291546/comments?start=%d&limit=20&sort=new_score&status=p" % (i * 20)
# 调用函数,爬取数据
getdata(url, commentall)
# 每爬取一个页面数据,休息若干秒,防止被封号
time.sleep(random.randint(1, 10))
# 调用函数,爬取完数据,装入表格
writeinto(commentall)
3.3 爬虫脚本优化
图3-1
3.4 数据采集结果
数据采集之后保存为douban_movie_comment.csv保存之后直接打开可能会出现乱码,通过网上查询资料使用excel表格新建导入表格信息选择编码格式为’utf-8’之后打开乱码问题解决。

图3-2
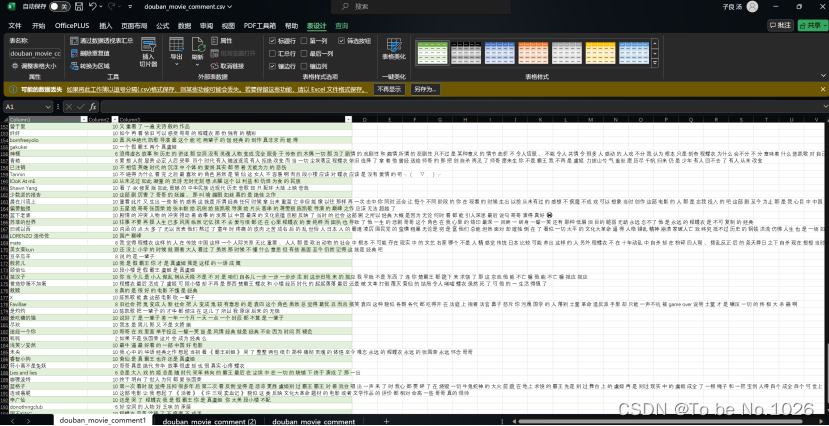
图3-3
4.数据分析
4.1 mapreduce
1. 设置启动程序,配置文件的输入路径和输出路径,配置mapper和reduce类
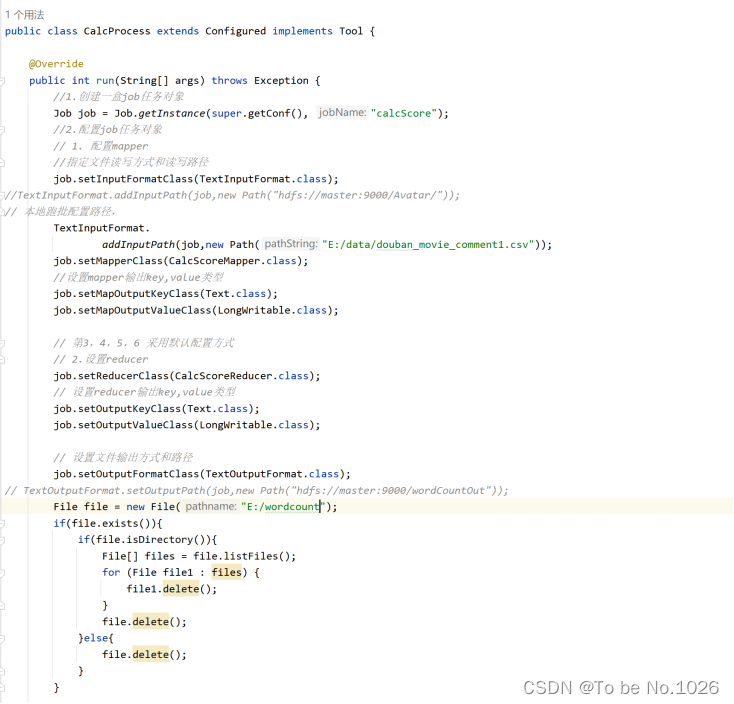
图4-1
2. mapper切割爬虫抓取的csv数据,对的,地,是,得进行筛除
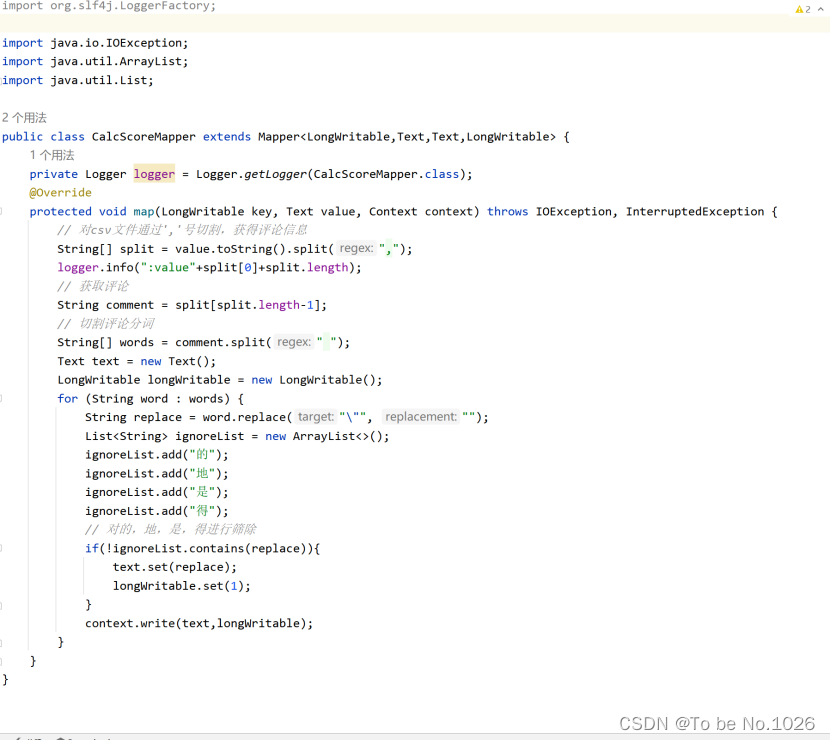
图4-2
- reduce编写程序:将分词进行个数统计

图4-3
4.2 hive
1.创建霸王别姬评论表
create table if not exists bawangbieji(author string,score double,fenci string) row format delimited fields terminated by ',';

图4-4
2. 加载抓取的霸王别姬影评数据到hive库表movie_comment
load data inpath '/douban_movie_comment1.csv' overwrite into table bawangbieji;
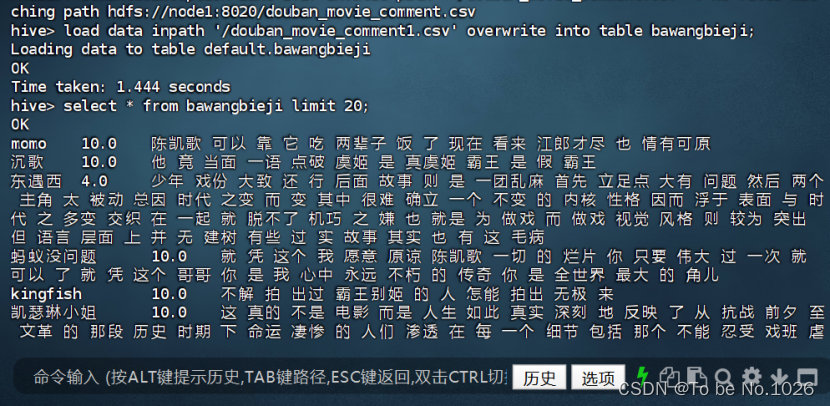
图4-5
3.hive查询影评平均分:select avg(score) from bawnagbieji;
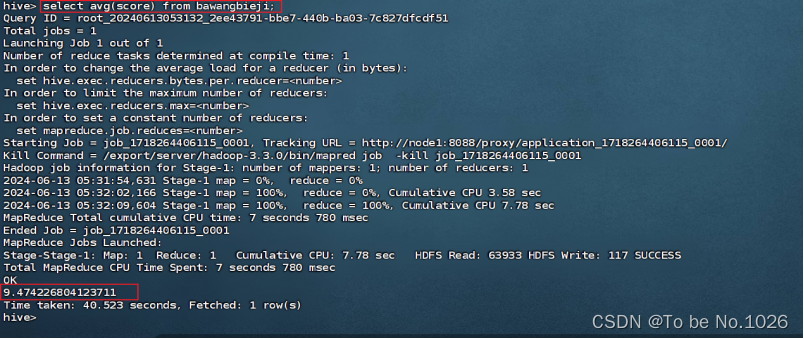
图4-6
4. hive查询影评分数分布人数
select score,count(1) num from bawangbieji group by score;

图4-7
5.创建多频字段表
create table if not exists keyword(keyword string,count int) row format delimited fields terminated by '\t';
6.统计字段进多频字段表
insert overwrite table keyword select t.word,count(*) from (select explode(split(fenci,' '))as word from bawangbieji) as t group by t.word;
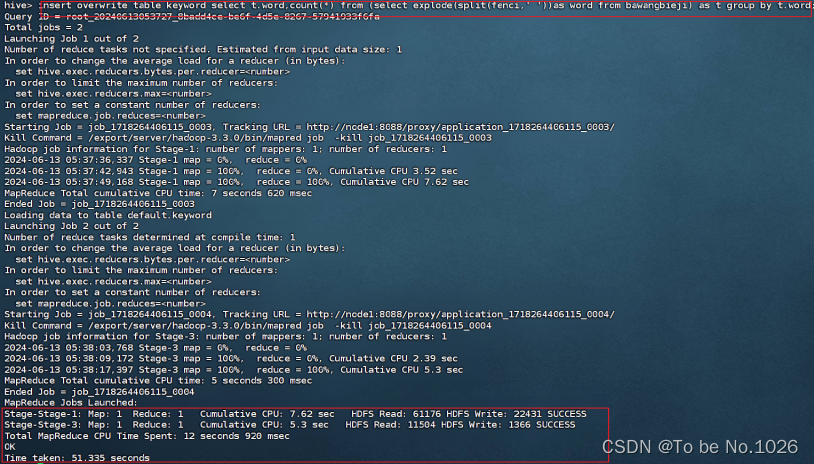
图4-8
7. 频次最高的十大词语(去除的、地、是、得)
select keyword,count from keyword where keyword not in ('是','的','得','地') order by count desc limit 10;
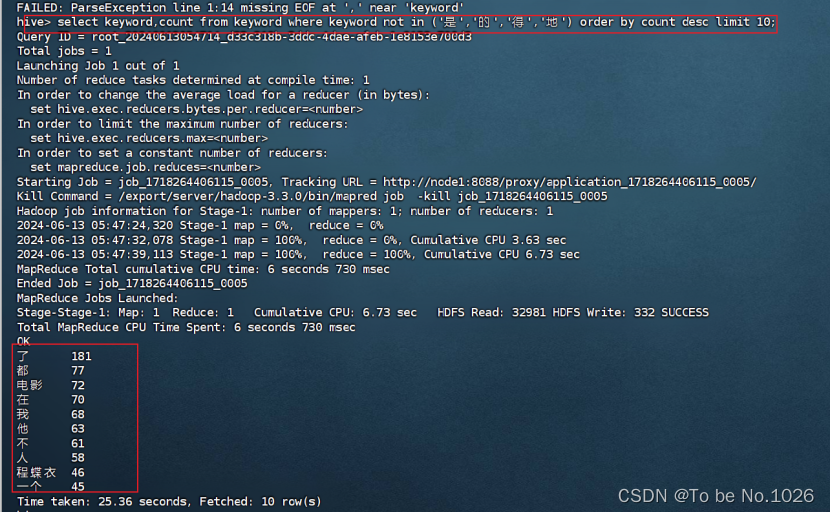
(a)初步筛选图
经过多次数据筛选,剔出常用的关键词提取出较为准确的关键词,并保存在文件keyword3.csv中:hive -e "select keyword,count from keyword where keyword not in ('是','的','得','地','了','都','电影','在','我','他','不','人','一个','也','看','又','和','很','不是','这','你') order by count desc limit 10;" > /root/keyword3.csv
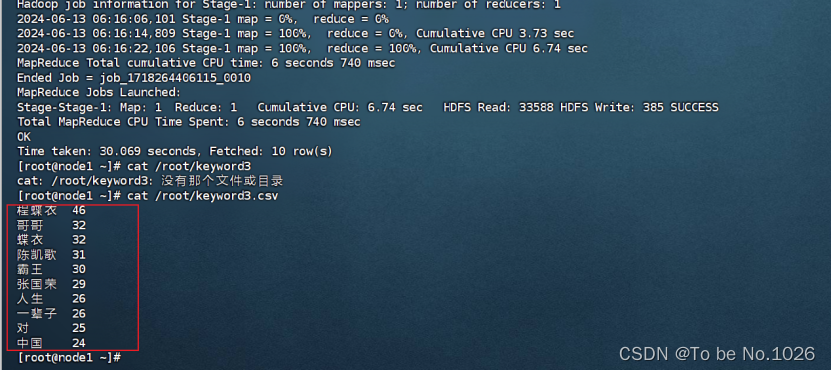
(b)最终筛选图
筛选评分各分段人数分布的数据并保存为score.csv文件:hive -e "select score,count(1) num from bawangbieji group by score;" > /root/score.csv
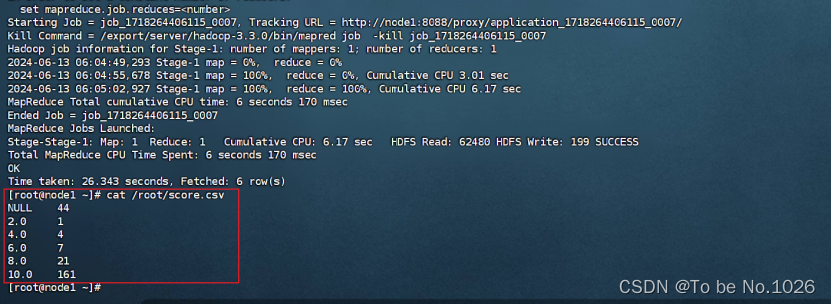
图4-9
5.数据可视化
5.1 简介
数据可视化本质上是把数据转化为直观且易于理解的图形或图表呈现的过程。这一过程意义重大,它能助力人们更高效、明晰地理解与剖析数量庞大且复杂的数据。当数据以可视化的形式展现时,其内在的模式、发展的趋势以及相互间的关系等关键信息都能被更轻易地察觉。如此一来,便能为决策制定提供强有力的支撑,无论是商业决策、科学研究还是社会管理等领域,都能从中受益。数据可视化所包含的技术和工具丰富多样,比如柱状图可清晰对比数量,折线图能直观展现趋势变化,热力图能呈现分布特征等。这些不同的技术和工具可以根据具体的场景和需求进行灵活运用,以达到最佳的可视化效果和信息传达。
5.2 echarts简介
echarts 是一个极为强大且开源的可视化库,它拥有极为丰富的图表类型,像柱状图能够直观地呈现数据的对比情况,折线图可以清晰地展示数据的变化趋势,饼图能很好地反映各部分占比,散点图则有助于分析数据的分布规律等等,多种常见形式一应俱全。不仅如此,它还同时支持复杂且多样化的交互功能,这使得用户能够更加深入地探索和理解数据。echarts 所提供的简洁易用的 api,让开发者可以轻松自如地创建出高度定制化、符合各种特定需求的可视化图表。而且,它具备出色的性能和良好的兼容性,无论是在常见的主流浏览器,还是在各种不同类型的设备上,都能够流畅稳定地运行,不会出现卡顿或不兼容的情况。正因如此,echarts 在数据可视化领域获得了极为广泛的应用,不管是在进行严谨的数据分析工作中,还是在需要进行直观报表展示的场景里,它都发挥着至关重要的作用,成为了众多开发者和使用者的得力助手。
5.3 可视化结果
霸王别姬:十大关键词
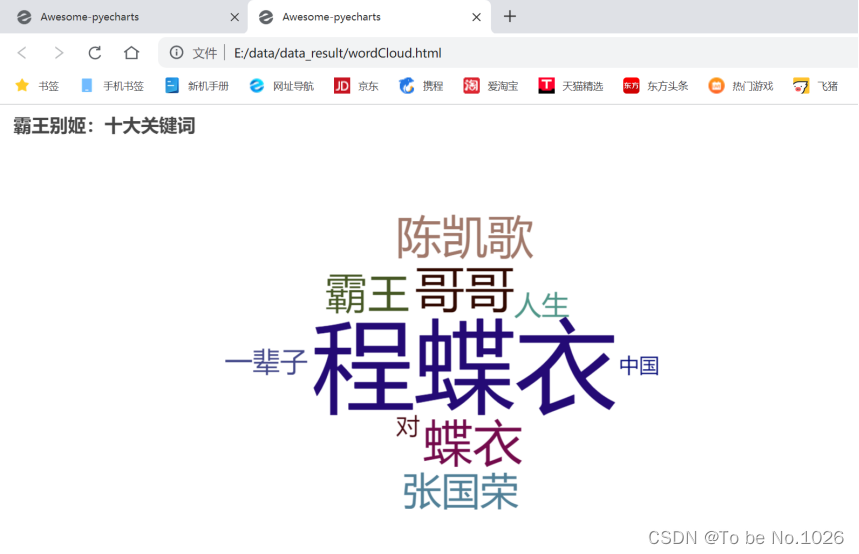
图5-1
霸王别姬:评分人数分布
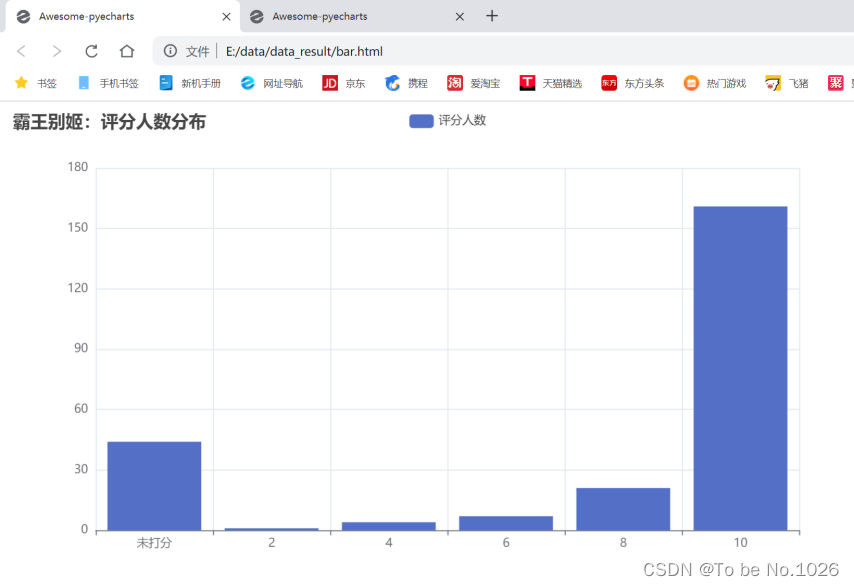
图5-2
6.总结
课程学习总结:
在大数据原理与技术这门课程中,我们深入探索了大数据领域的核心概念和关键技术,学习了一系列重要的知识点。hadoop 作为大数据处理的核心框架,让我们理解了分布式计算和存储的强大能力。通过 hdfs 实现了高效的分布式海量存储,解决了数据规模庞大的问题。hbase 提供了可扩展的列式数据库存储,适用于海量数据的实时读写。zookeeper 在分布式系统中发挥着关键作用,保障了集群的协调和一致性。hive 则构建在 hadoop 之上,使我们能够使用类 sql 语句方便地对大数据进行查询和分析。学习了分布式存储和海量存储,我们掌握了数据分区、副本机制等技术,以确保数据的可靠性和高性能访问。
最后的三次实验内容让我亲身体验了搭建和使用这些技术的过程,深刻认识到它们在处理大规模数据时的不可或缺性。这门课程不仅传授了知识,更培养了我们应对大数据挑战的思维和能力,为我们在大数据领域的进一步探索和应用奠定了坚实基础。无论是在数据分析、系统架构还是数据工程等方面,这些知识都将成为我们的有力工具,帮助我们更好地适应大数据时代的发展需求。
大作业总结:
在本次实验中,以 hadoop 为基础展开了对豆瓣电影影评数据的深入分析。从绪论开始,对整个实验的背景和目标有了清晰认识。在环境搭建阶段,仔细配置了系统环境和编程环境,为后续工作做好铺垫。
数据采集部分,通过对爬虫技术的运用,成功获取了有效的实验影评数据。编写了爬虫脚本优化脚本,提高了数据采集的效率和质量。
数据分析中,使用mapreduce 的分布式计算能力,高效处理海量影评数据。使用hive 提供的便捷的数据分析途径,从复杂的数据中挖掘出有意义的信息。
数据可视化中,借助 echarts 工具,将分析结果以直观的图表形式呈现出来,使实验数据更清晰地理解和解读。
整个实验过程不仅让我深入掌握了 hadoop 相关技术在实际数据分析中的应用,还培养了我们解决问题和处理复杂数据的能力。通过实践操作,我们更加理解了大数据处理的流程和挑战。同时,也让我们看到了数据分析对于理解用户观点、挖掘潜在价值的重要性。这一系列的学习和实践为我们今后在大数据领域的进一步探索和发展奠定了坚实基础,使我们能够更好地应对大数据时代的各种需求和挑战。




发表评论