前言:超市销售数据的管理和分析对于商家来说至关重要。借助hadoop生态系统中的mapreduce框架,我们可以有效地处理大规模的销售数据,并从中提取有价值的信息,比如每个月的销售总额。本文将介绍如何利用hadoop编写mapreduce程序来计算超市消费数据的月份销售总额。
一. 数据准备
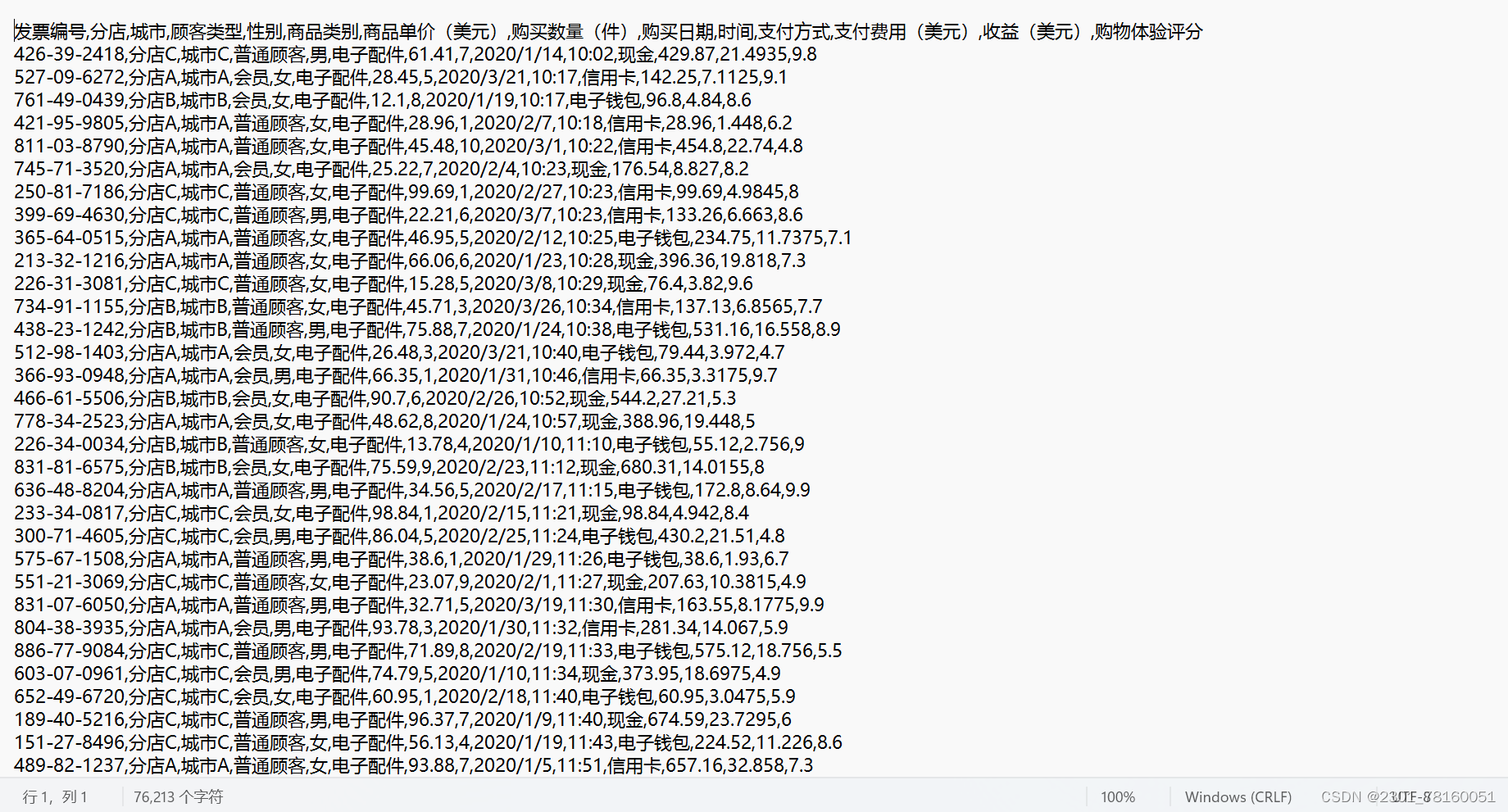
首先,我们需要准备超市的销售数据。假设我们的数据以文本文件的形式存储,每行代表一笔销售记录,包括日期、商品名称和销售额等信息。例如:
二.hadoop分布式文件系统(hdfs)
介绍
hadoop分布式文件系统(hdfs)是apache hadoop生态系统的核心组件之一,用于存储和管理大规模数据集。它设计用于在廉价的硬件上运行,并且提供高可靠性、高性能的分布式存储解决方案。本文将深入探讨hdfs的工作原理、架构和优势。
hdfs架构
hdfs的架构由以下几个重要组件组成:
-
namenode:namenode是hdfs的关键组件之一,负责管理文件系统的命名空间和存储块的元数据信息。它维护了文件系统树及其相关属性,并且记录了每个文件块的位置信息。
-
datanode:datanode是另一个重要组件,负责实际存储数据块。每个datanode管理着其所在节点上的存储,定期向namenode报告其存储容量和健康状况。
-
secondary namenode:secondary namenode并不是namenode的备份,而是协助namenode进行元数据的周期性合并和编辑日志的滚动。它帮助减轻了namenode的压力,并且有助于提高系统的可靠性。
-
客户端:客户端是与hdfs交互的应用程序,负责向hdfs读取和写入数据。
hdfs工作原理
hdfs的工作原理可以简要概括为以下几个步骤:
-
文件分块:当一个文件被上传到hdfs时,它会被划分成固定大小的数据块(通常为128mb或256mb)。这些数据块被分散存储在多个datanode上,以实现数据的分布式存储和处理。
-
命名空间管理:namenode负责管理文件系统的命名空间和元数据信息。它维护文件系统树,记录文件和数据块的位置信息,并处理客户端的文件系统操作请求。
-
数据复制:为了提高数据的可靠性和容错性,hdfs会将每个数据块复制到多个datanode上。这些副本通常分布在不同的机架上,以减少硬件故障对数据的影响。
-
容错机制:hdfs通过周期性的心跳检测和块报告来监视datanode的健康状况。如果发现某个数据块的副本丢失或损坏,hdfs会自动从其他datanode上的副本进行恢复。
hdfs的优势
hdfs作为大数据存储解决方案,具有以下几个显著的优势:
-
高可靠性:hdfs通过数据复制和容错机制,保证了数据的可靠性和容错性,即使在硬件故障的情况下也能保持数据的完整性。
-
高扩展性:hdfs可以轻松地扩展到数以千计的节点,以应对不断增长的数据量和处理需求。
-
高性能:由于数据块的分布式存储和并行处理,hdfs可以实现高吞吐量和低延迟的数据访问。
-
成本效益:hdfs运行在廉价的标准硬件上,并且采用了大规模并行处理的模式,使得它成为一种经济高效的数据存储解决方案。
在hdfs的/<个人学号>/data/路径(例如/202201/data)下创建并存储该数据文件;
通过hdfs dfs -cat/<个人学号>/data/xxx命令查看数据文件的截图,用以证明数据已成功存储在hdfs 上。
1.首先打开hdfs进程,并用hdfs dfs mkdir -p /学号/data 命令在hdfs中创建文件夹,并用hdfs dfs -ls/查看是否创建。
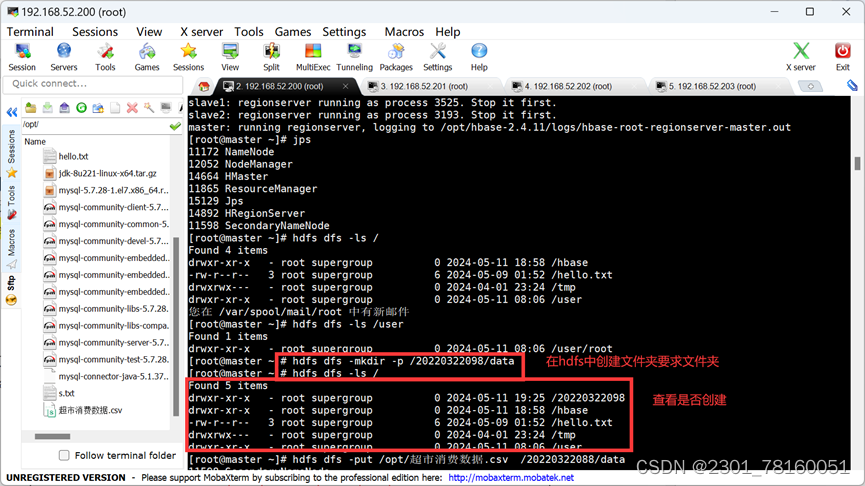
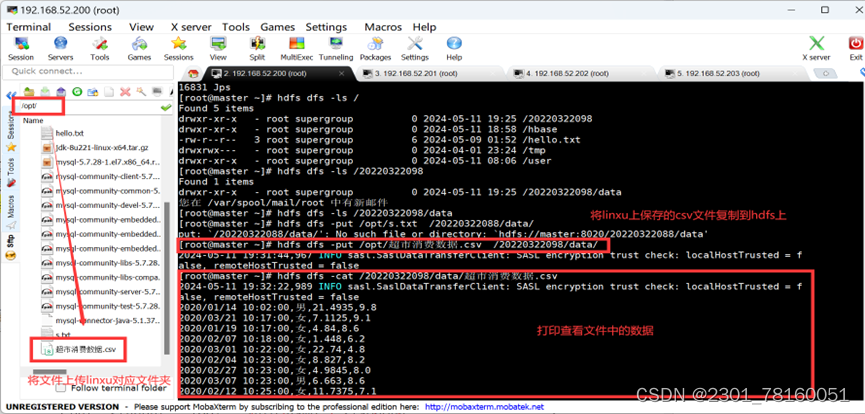
2. 将csv文件准备好,并移动到linxu操作系统的 /opt/ 目录下,运用命令 hdfs dfs -put /opt/超市消费数据.csv /202201/data/(把在linx下的数据转到hdfs上)。
并使用:hdfs dfs -cat查看是否成功上传。
三.mapreduce指标计算与存储
引言
mapreduce是一种用于大规模数据处理的编程模型,最初由google提出,并在apache hadoop项目中得到了广泛的实现和应用。mapreduce分布式文件系统结合了分布式文件系统和mapreduce计算模型,为大规模数据处理提供了高效、可靠的解决方案。本文将深入探讨mapreduce分布式文件系统的原理、架构和应用场景。
mapreduce分布式文件系统架构
mapreduce分布式文件系统的架构通常由以下几个核心组件组成:
-
master节点:master节点是mapreduce系统的控制节点,负责协调整个作业的执行过程。它包含了jobtracker(作业跟踪器)和resource manager(资源管理器)等关键组件。
-
worker节点:worker节点是mapreduce集群中的计算节点,负责执行map和reduce任务。每个worker节点包含了tasktracker(任务跟踪器)和datanode(数据节点)等关键组件。
-
分布式文件系统:mapreduce分布式文件系统通常基于hadoop分布式文件系统(hdfs)或其他分布式文件系统实现。它负责存储输入数据和中间计算结果,并提供高可靠性、高扩展性的分布式存储服务。
工作原理
mapreduce分布式文件系统的工作原理可以简述为以下几个步骤:
-
作业提交:用户通过客户端提交mapreduce作业到master节点,包括输入数据的位置和mapreduce任务的代码。
-
作业调度:master节点接收到作业后,将其分配给空闲的worker节点进行执行。它负责调度map和reduce任务的执行顺序,并监控整个作业的执行进度。
-
数据处理:worker节点根据作业中指定的map和reduce函数对输入数据进行处理。map任务将输入数据划分为多个键值对,并根据键将其分组;reduce任务则对每个键值对组进行聚合计算。
-
中间结果存储:mapreduce分布式文件系统将map任务产生的中间结果存储在分布式文件系统中,以便reduce任务进行读取和处理。
-
结果输出:最终,reduce任务将聚合结果写回到分布式文件系统中,并通知master节点作业执行完成。
mapper类
import java.io.ioexception;
import java.text.parseexception;
import java.text.simpledateformat;
import java.util.calendar;
import java.util.date;
import org.apache.hadoop.io.floatwritable;
import org.apache.hadoop.io.longwritable;
import org.apache.hadoop.io.text;
import org.apache.hadoop.mapreduce.mapper;
public class salesmapper extends mapper<longwritable, text, text, floatwritable> {
private text outputkey = new text();
private floatwritable outputvalue = new floatwritable();
public void map(longwritable key, text value, context context) throws ioexception, interruptedexception {
string[] fields = value.tostring().split(",");
if (fields.length == 3) {
string datestr = fields[0]; // 日期字段
string amountstr = fields[1]; // 销售金额字段
try {
simpledateformat dateformat = new simpledateformat("yyyy-mm-dd");
date date = dateformat.parse(datestr);
calendar calendar = calendar.getinstance();
calendar.settime(date);
int month = calendar.get(calendar.month) + 1; // 月份从0开始,需要加1
outputkey.set(string.valueof(month));
outputvalue.set(float.parsefloat(amountstr));
context.write(outputkey, outputvalue);
} catch (parseexception e) {
e.printstacktrace();
}
}
}
}reducer类
import java.io.ioexception;
import org.apache.hadoop.io.floatwritable;
import org.apache.hadoop.io.text;
import org.apache.hadoop.mapreduce.reducer;
public class salesreducer extends reducer<text, floatwritable, text, floatwritable> {
private floatwritable result = new floatwritable();
public void reduce(text key, iterable<floatwritable> values, context context)
throws ioexception, interruptedexception {
float sum = 0;
for (floatwritable value : values) {
sum += value.get();
}
result.set(sum);
context.write(key, result);
}
}driver类
import org.apache.hadoop.conf.configuration;
import org.apache.hadoop.fs.path;
import org.apache.hadoop.io.floatwritable;
import org.apache.hadoop.io.text;
import org.apache.hadoop.mapreduce.job;
import org.apache.hadoop.mapreduce.lib.input.fileinputformat;
import org.apache.hadoop.mapreduce.lib.output.fileoutputformat;
public class monthlysalesdriver {
public static void main(string[] args) throws exception {
if (args.length != 2) {
system.err.println("usage: monthlysalesdriver <input path> <output path>");
system.exit(-1);
}
configuration conf = new configuration();
job job = job.getinstance(conf, "monthly sales");
job.setjarbyclass(monthlysalesdriver.class);
job.setmapperclass(salesmapper.class);
job.setreducerclass(salesreducer.class);
job.setoutputkeyclass(text.class);
job.setoutputvalueclass(floatwritable.class);
fileinputformat.addinputpath(job, new path(args[0]));
fileoutputformat.setoutputpath(job, new path(args[1]));
system.exit(job.waitforcompletion(true) ? 0 : 1);
}
}将计算结果存储到linux上的mysql数据库中的t_<个人学号>表中(例如t_202201)
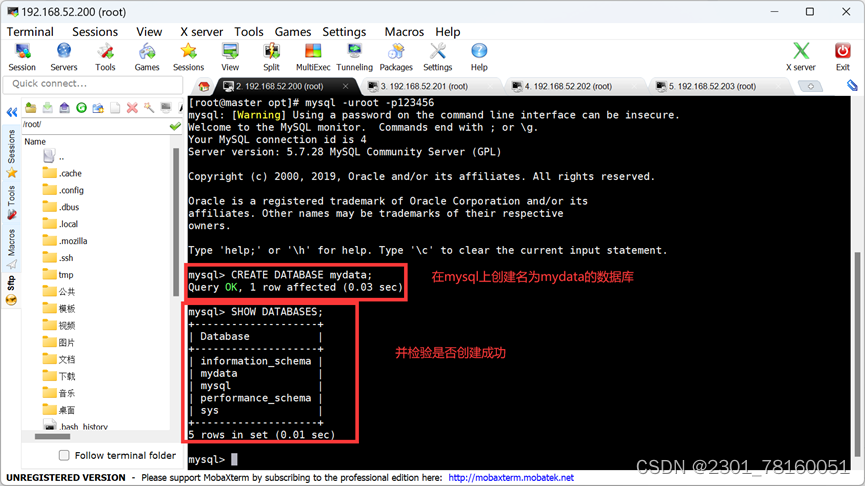
首先登录mysql数据库:mysql -uroot -p123456,并手动创建数据库:create database mydata; 然后并查看是否创建成功:show databases;
使用use mydata 切换到目标数据库,然后使用show tables 查看所有的位于mydata数据库下的所有表。
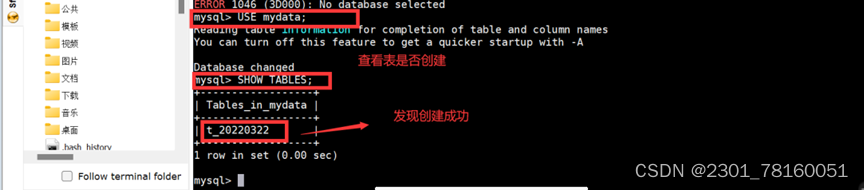
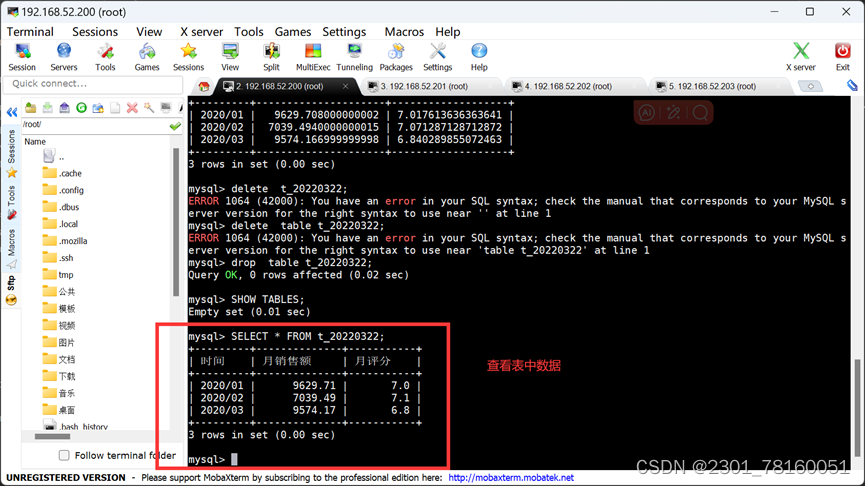
使用select * from t_20220322,查看是否有数据存在,如若有,则说明成功




发表评论