1、windows 安装:最低要求为 win10 / 64 位系统,内存建议 16gb,显卡建议 nvidia 8gb 显存起,硬盘建议 30gb 起。安装方式可参考:https://blog.csdn.net/weixin_40660408/article/details/129896700 2、google drive 安装:云端部署可以将 stable diffusion webui colab 安装到 google drive 上,好处是既可以使用 google 提供的免费硬件资源,又保持了较高自由度的模型和插件扩展。需要注意的是 google drive 免费空间 15g,安装多个模型需要对存储空间进行扩容。安装方式可参考:https://github.com/camenduru/stable-diffusion-webui-colab/tree/drive 3、stable diffusion colab:https://github.com/camenduru/stable-diffusion-webui-colab 中各个版本已更新 controlnet 功能。比较推荐的模型有:protogen(多个优秀模型融合而成)、dreamlike(写实风格模型)、waifu/orangemix(动漫风格模型)、anything(二次元风格模型)、chilloutmix(真人风格模型)、openjourney(midjourney 画风)等,具体可到 huggingface 中了解 https://huggingface.co/models?pipeline_tag=text-to-image&sort=downloads

一、ai 绘画工具的选择与运用
1. 工作场景下 ai 绘画工具的选择
目前文生图的主流 ai 绘画平台主要有三种:midjourney、stable diffusion、dall·e。如果要在实际工作场景中应用,我更推荐 stable diffusion。
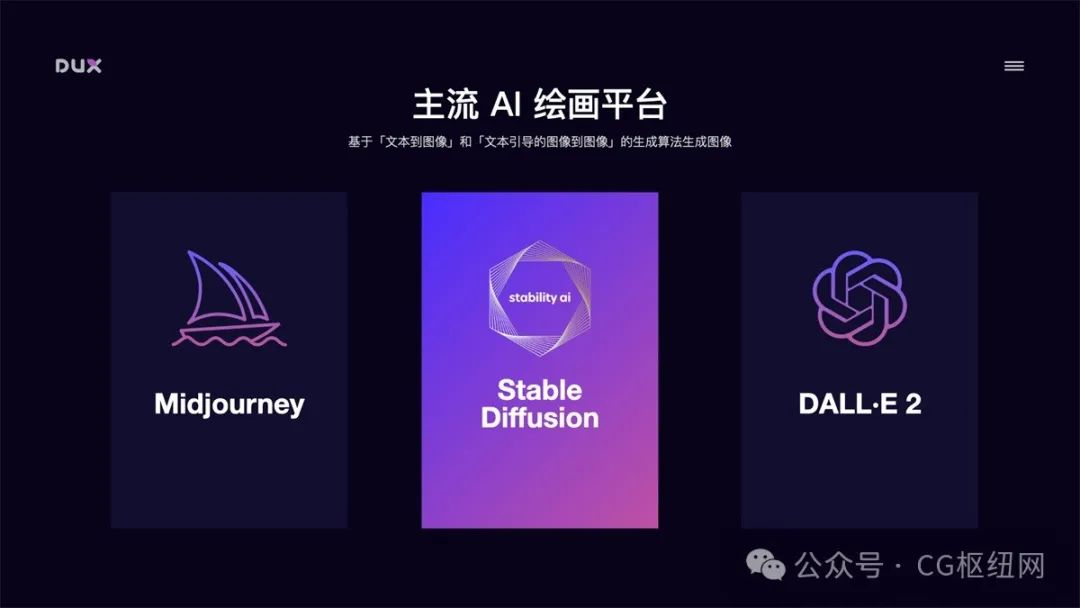
通过对比,stable diffusion 在数据安全性(可本地部署)、可扩展性(成熟插件多)、风格丰富度(众多模型可供下载,也可以训练自有风格模型)、费用版权(开源免费、可商用)等方面更适合我们的工作场景。

那么如何在实际工作中应用 stable diffusion 进行 ai 绘画?
要在实际工作中应用 ai 绘画,需要解决两个关键问题,分别是:图像的精准控制和图像的风格控制。

2. 图像精准控制
图像精准控制推荐使用 stable diffusion 的 controlnet 插件。在 controlnet 出现之前,ai 绘画更像开盲盒,在图像生成前,你永远都不知道它会是一张怎样的图。controlnet 的出现,真正意义上让 ai 绘画上升到生产力级别。简单来说 controlnet 它可以精准控制 ai 图像的生成。

controlnet 主要有 8 个应用模型:openpose、canny、hed、scribble、mlsd、seg、normal map、depth。以下做简要介绍:
openpose 姿势识别
通过姿势识别,达到精准控制人体动作。除了生成单人的姿势,它还可以生成多人的姿势,此外还有手部骨骼模型,解决手部绘图不精准问题。以下图为例:左侧为参考图像,经 openpose 精准识别后,得出中间的骨骼姿势,再用文生图功能,描述主体内容、场景细节和画风后,就能得到一张同样姿势,但风格完全不同的图。

canny 边缘检测
canny 模型可以根据边缘检测,从原始图片中提取线稿,再根据提示词,来生成同样构图的画面,也可以用来给线稿上色。

hed 边缘检测
跟 canny 类似,但自由发挥程度更高。hed 边界保留了输入图像中的细节,绘制的人物明暗对比明显,轮廓感更强,适合在保持原来构图的基础上对画面风格进行改变时使用。

scribble 黑白稿提取
涂鸦成图,比 hed 和 canny 的自由发挥程度更高,也可以用于对手绘线稿进行着色处理。

mlsd 直线检测
通过分析图片的线条结构和几何形状来构建出建筑外框,适合建筑设计的使用。

seg 区块标注
通过对原图内容进行语义分割,可以区分画面色块,适用于大场景的画风更改。

normal map 法线贴图
适用于三维立体图,通过提取用户输入图片中的 3d 物体的法线向量,以法线为参考绘制出一副新图,此图与原图的光影效果完全相同。

depth 深度检测
通过提取原始图片中的深度信息,可以生成具有同样深度结构的图。还可以通过 3d 建模软件直接搭建出一个简单的场景,再用 depth 模型渲染出图。

controlnet 还有项关键技术是可以开启多个 controlnet 的组合使用,对图像进行多条件控制。例如:你想对一张图像的背景和人物姿态分别进行控制,那我们可以配置 2 个 controlnet,第 1 个 controlnet 使用 depth 模型对背景进行结构提取并重新风格化,第 2 个 controlnet 使用 openpose 模型对人物进行姿态控制。此外在保持 seed 种子数相同的情况下,固定出画面结构和风格,然后定义人物不同姿态,渲染后进行多帧图像拼接,就能生成一段动画。
以上通过 controlnet 的 8 个主要模型,我们解决了图像结构的控制问题。接下来就是对图像风格进行控制。
3. 图像风格控制
stable diffusion 实现图像风格化的途径主要有以下几种:artist 艺术家风格、checkpoint 预训练大模型、lora 微调模型、textual inversion 文本反转模型。

artist 艺术家风格
主要通过画作种类 tag(如:oil painting、ink painting、comic、illustration),画家/画风 tag(如:hayao miyazaki、cyberpunk)等控制图像风格。网上也有比较多的这类风格介绍,如:
-
https://promptomania.com
-
https://www.urania.ai/top-sd-artists
但需要注意的是,使用艺术家未经允许的风格进行商用,会存在侵权问题。

checkpoint 预训练大模型
checkpoint 是根据特定风格训练的大模型,模型风格强大,但体积也较大,一般 5-7gb。模型训练难度大,需要极高的显卡算力。目前网上已经有非常多的不同风格的成熟大模型可供下载使用。如:https://huggingface.co/models?pipeline_tag=text-to-image

lora 微调模型
lora 模型是通过截取大模型的某一特定部分生成的小模型,虽然不如大模型的能力完整,但短小精悍。因为训练方向明确,所以在生成特定内容的情况下,效果会更好。lora 模型也常用于训练自有风格模型,具有训练速度快,模型大小适中,配置要求低(8g 显存)的特点,能用少量图片训练出风格效果。常用 lora 模型下载地址:
-
https://stableres.info
-
https//civitai.com(友情提醒:不要在办公场所打开,不然会很尴尬)

textual inversion 文本反转模型
textual inversion 文本反转模型也是微调模型的一种,它是针对一个风格或一个主题训练的风格模型,一般用于提高人物还原度或优化画风,用这种方式生成的模型非常小,一般几十 kb,在生成画作时使用对应 tag 在 prompt 中进行调用。

自有风格模型训练
stable diffusion 的强大之处还在于能够自定义训练风格模型,如果现有风格无法满足要求,我们还可以自己训练特定风格模型。stable diffusion 支持训练大模型和微调模型。我比较推荐的是用 lora 模型训练方法,该方法训练速度快,模型大小适中(100mb 左右),配置要求低(8g 显存),能用极少量图片训练出风格效果。例如:下图中我用了 10 张工作中的素材图,大概花了 20 分钟时间训练出该风格的 lora 模型,然后使用该模型就可以生成风格类似的图片。如果将训练样本量增大,那么训练出来的风格样式会更加精确。

了解了 stable diffusion 能干什么后,再来介绍下如何部署安装使用它。
二、ai 绘画工具的部署安装
以下主要介绍三种部署安装方式:云端部署、本地部署、本机安装,各有优缺点。当本机硬件条件支持的情况下,推荐本地部署,其它情况推荐云端方式。
1. 云端部署 stable diffusion
通过 google colab 进行云端部署,推荐将成熟的 stable diffusion colab 项目复制到自己的 google 云端硬盘运行,省去配置环境麻烦。这种部署方式的优点是:不吃本机硬件,在有限时间段内,可以免费使用 google colab 强大的硬件资源,通常能给到 15g 的 gpu 算力,出图速度非常快。缺点是:免费 gpu 使用时长不固定,通常情况下一天有几个小时的使用时长,如果需要更长时间使用,可以订阅 colab 服务。

推荐两个目前比较好用的 stable diffusion colab,选择相应模型版本运行即可:
-
stable diffusion colab:github.com/camenduru/stable-diffusion-webui-colab (不带 controlnet)
-
controlnet colab:github.com/camenduru/controlnet-colab(带 controlnet)
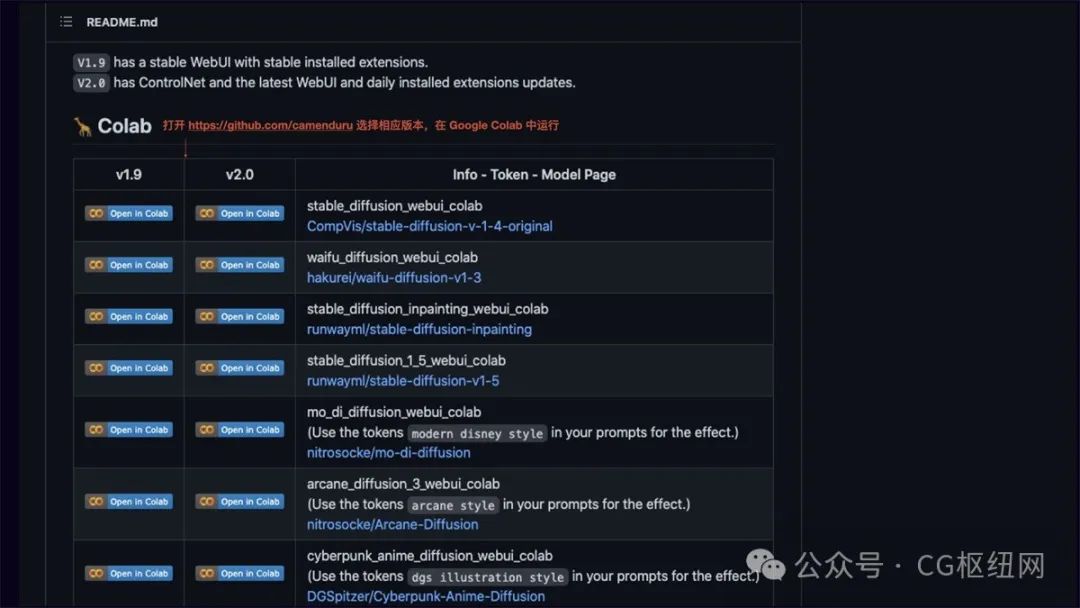
colab 运行界面如下,点击连接虚拟机,连接成功后点击左侧运行代码,等待环境自动配置完成后,点击 webui url 即可运行 stable diffusion。
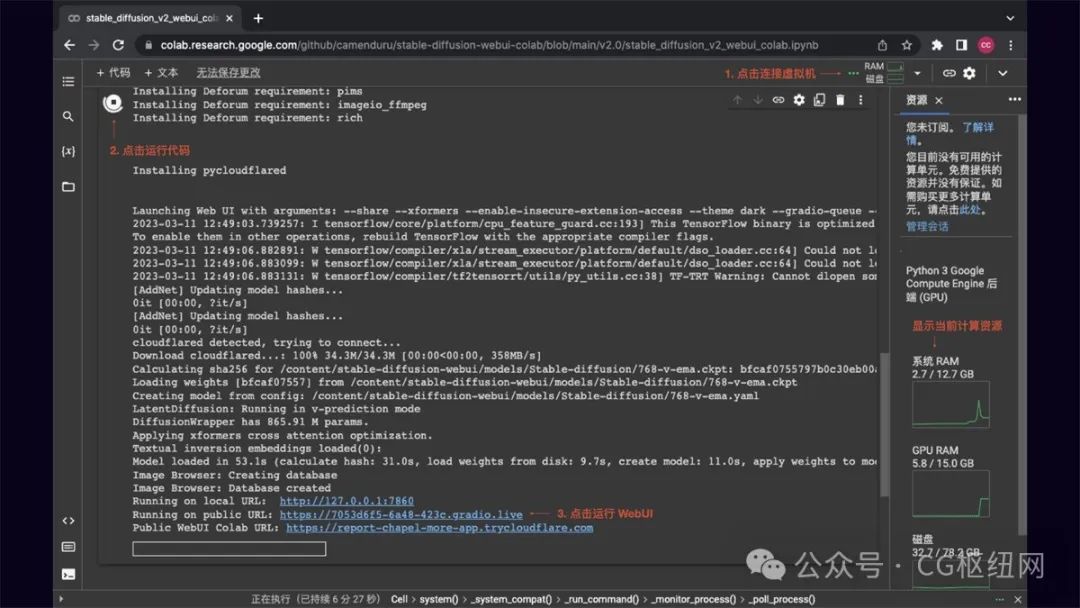
stable diffusion webui 运行界面如下,在后面的操作方法里我会介绍下 stable diffusion 的基础操作。
2. 本地部署 stable diffusion
相较于 google colab 云端部署,本地部署 stable diffusion 的可扩展性更强,可自定义安装需要的模型和插件,隐私性和安全性更高,自由度也更高,而且完全免费。当然缺点是对本机硬件要求高,windows 需要 nvidia 显卡,8g 以上显存,16g 以上内存。mac 需要 m1/m2 芯片才可运行。

本地部署方式主要分四步,以 mac m1 为例:
第 1 步:安装 homebrew 和 python3.10 环境
homebrew 是一个包管理工具,具体安装方法可参考:https://brew.idayer.com/
python3.10 安装:brew install cmake protobuf rust python@3.10 git wget
第 2 步:克隆 stable diffusion webui 项目仓库
推荐下载 automatic1111 的 stable diffusion webui,能很好的支持 controlnet 扩展。
克隆项目仓库:git clone https://github.com/automatic1111/stable-diffusion-webui
第 3 步:下载并存放 stable diffusion 模型
stable diffusion 模型可以下载官方提供的 1.5 或 2.0 版本的 ckpt 文件,其它风格模型则根据自己需要下载。下载地址:huggingface.co/models?pipeline_tag=text-to-image
下载完后找到 stable-diffusion-webui 文件夹,把下载的 ckpt 大模型文件存放到 stable-diffusion-webui/models/stable-diffusion 目录下。
如果下载了 lora 模型的 safetensors 文件,则存放到 stable-diffusion-webui/models/lora 目录中。
textual inversion 文本反转模型的 pt 文件,存放到 stable-diffusion-webui/embeddings 目录中。
第 4 步:运行 stable diffusion webui
模型文件存放完成后,运行 stable diffusion webui:
先输入 cd stable-diffusion-webui 再输入 ./webui.sh,程序会自动完成下载安装。
运行完毕后显示:running on local url: http://127.0.0.1:7860 to create a public link, set `share=true` in `launch()`
在浏览器中打开 http://127.0.0.1:7860 ,即可运行 stable diffusion webui
需要用到的资源:
-
homebrew 包管理工具:brew.idayer.com/guide/
-
python 安装:www.python.org/downloads/
-
stable diffusion 项目仓库:github.com/automatic1111/stable-diffusion-webui
-
stable diffusion 模型:huggingface.co/models?pipeline_tag=text-to-image
controlnet 的安装
安装完 stable diffusion webui 后,我们再安装 controlnet 扩展,以便进行图像的精准控制。
安装方法:
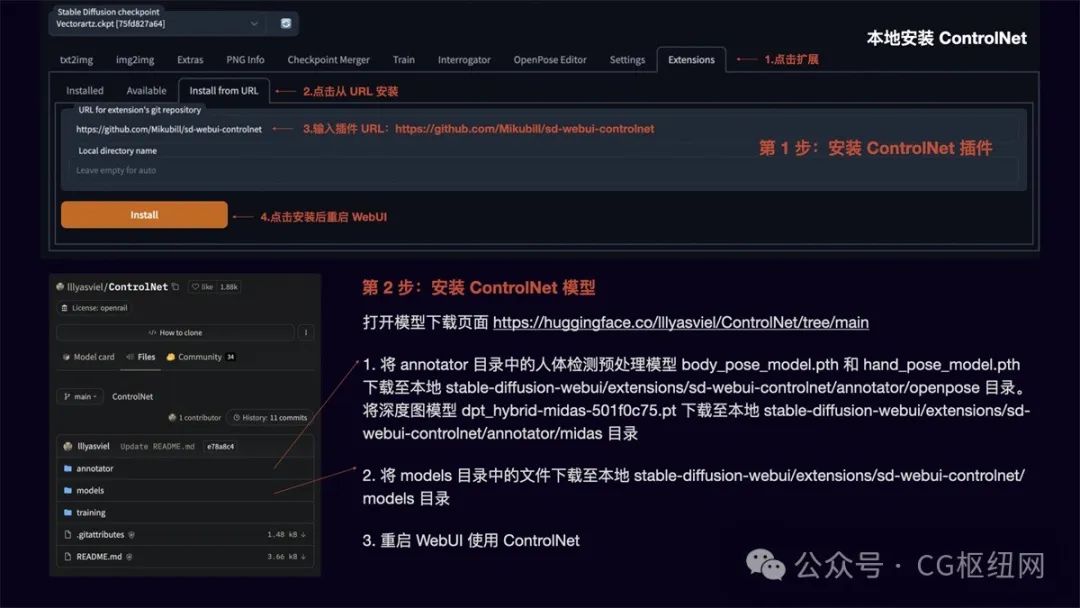
第 1 步:安装 controlnet 插件
点击扩展,选择从 url 安装,输入插件地址 https://github.com/mikubill/sd-webui-controlnet ,点击 install 后重启 webui。
第 2 步:安装 controlnet 模型
打开模型下载页面 https://huggingface.co/lllyasviel/controlnet/tree/main
-
将 annotator 目录中的人体检测预处理模型 body_pose_model.pth 和 hand_pose_model.pth 下载至本地 stable-diffusion-webui/extensions/sd-webui-controlnet/annotator/openpose 目录。
-
将深度图模型 dpt_hybrid-midas-501f0c75.pt 下载至本地 stable-diffusion-webui/extensions/sd-webui-controlnet/annotator/midas 目录
将 models 目录中的文件下载至本地 stable-diffusion-webui/extensions/sd-webui-controlnet/models 目录 -
重启 webui 即可使用 controlnet
解决 controlnet 在 mac m1 上无法运行问题
对于 mac m1 芯片的电脑来说,直接运行 controlnet 会报错,导致无法使用 controlnet。原因是 cuda 是适用于 nvidia gpu 的计算框架,当前 mac os 无法使用此框架,因此脚本会尝试使用 cpu,但 m1 不支持半精度数字。因此我们需要跳过 cuda 并使用 no-half。
解决方法:
-
找到 webui-macos-env.sh 文件
-
添加 export commandline_args=“–precision full --no-half --skip-torch-cuda-test”

3. 本机安装 diffusionbee
如果觉得云端部署和本地部署比较繁琐,或对使用要求没有那么高,那就试下最简单的一键安装方式。下载 diffusionbee 应用:diffusionbee.com/download。优点是方便快捷,缺点是扩展能力差(可以安装大模型,无法进行插件扩展,如 controlnet)。

三、ai 绘画工具的操作技巧
1. stable diffusion 基础操作
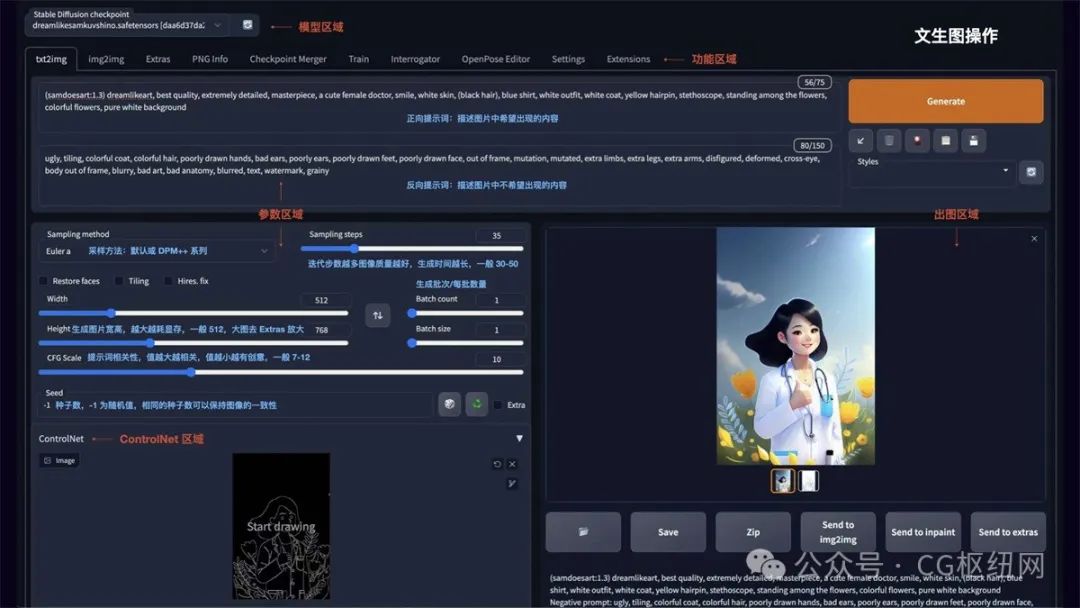
文生图
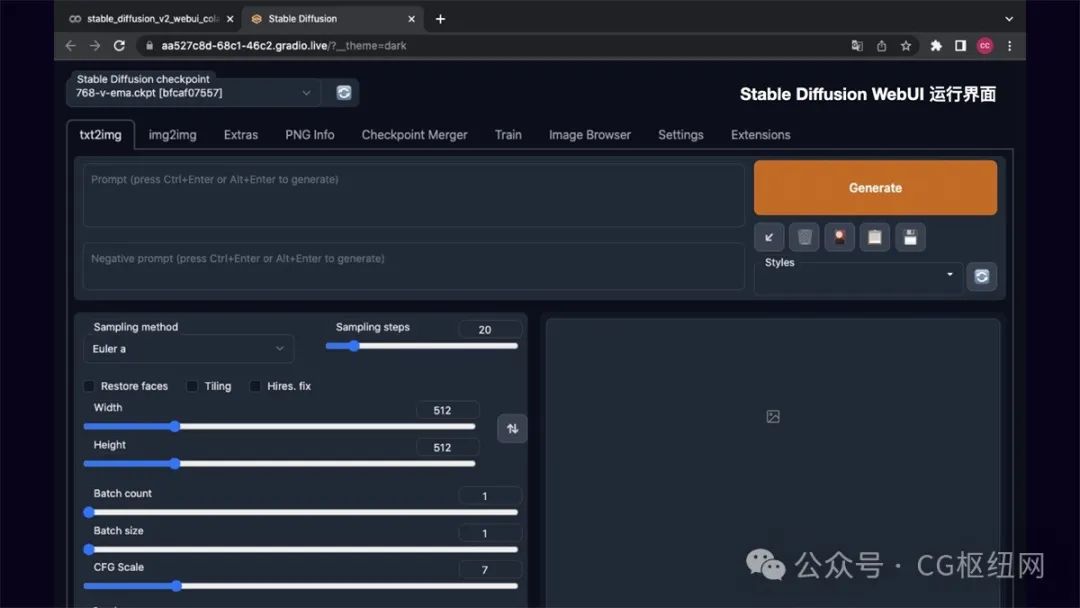
如图所示 stable diffusion webui 的操作界面主要分为:模型区域、功能区域、参数区域、出图区域。
-
txt2img 为文生图功能,重点参数介绍:
-
正向提示词:描述图片中希望出现的内容
-
反向提示词:描述图片中不希望出现的内容
-
sampling method:采样方法,推荐选择 euler a 或 dpm++ 系列,采样速度快
-
sampling steps:迭代步数,数值越大图像质量越好,生成时间也越长,一般控制在 30-50 就能出效果
-
restore faces:可以优化脸部生成
-
width/height:生成图片的宽高,越大越消耗显存,生成时间也越长,一般方图 512x512,竖图 512x768,需要更大尺寸,可以到 extras 功能里进行等比高清放大
-
cfg:提示词相关性,数值越大越相关,数值越小越不相关,一般建议 7-12 区间
-
batch count/batch size:生成批次和每批数量,如果需要多图,可以调整下每批数量
-
seed:种子数,-1 表示随机,相同的种子数可以保持图像的一致性,如果觉得一张图的结构不错,但对风格不满意,可以将种子数固定,再调整 prompt 生成
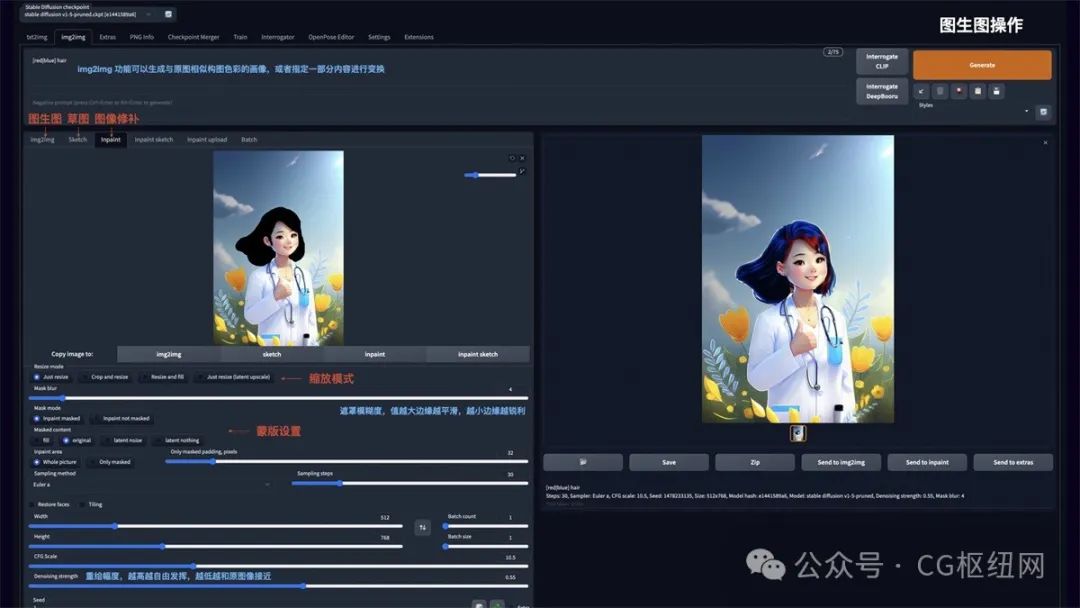
图生图
img2img 功能可以生成与原图相似构图色彩的画像,或者指定一部分内容进行变换。可以重点使用 inpaint 图像修补这个功能:
-
resize mode:缩放模式,just resize 只调整图片大小,如果输入与输出长宽比例不同,图片会被拉伸。crop and resize 裁剪与调整大小,如果输入与输出长宽比例不同,会以图片中心向四周,将比例外的部分进行裁剪。resize and fill 调整大小与填充,如果输入与输出分辨率不同,会以图片中心向四周,将比例内多余的部分进行填充
-
mask blur:蒙版模糊度,值越大与原图边缘的过度越平滑,越小则边缘越锐利
-
mask mode:蒙版模式,inpaint masked 只重绘涂色部分,inpaint not masked 重绘除了涂色的部分
-
masked content:蒙版内容,fill 用其他内容填充,original 在原来的基础上重绘
-
inpaint area:重绘区域,whole picture 整个图像区域,only masked 只在蒙版区域
-
denoising strength:重绘幅度,值越大越自由发挥,越小越和原图接近
controlnet
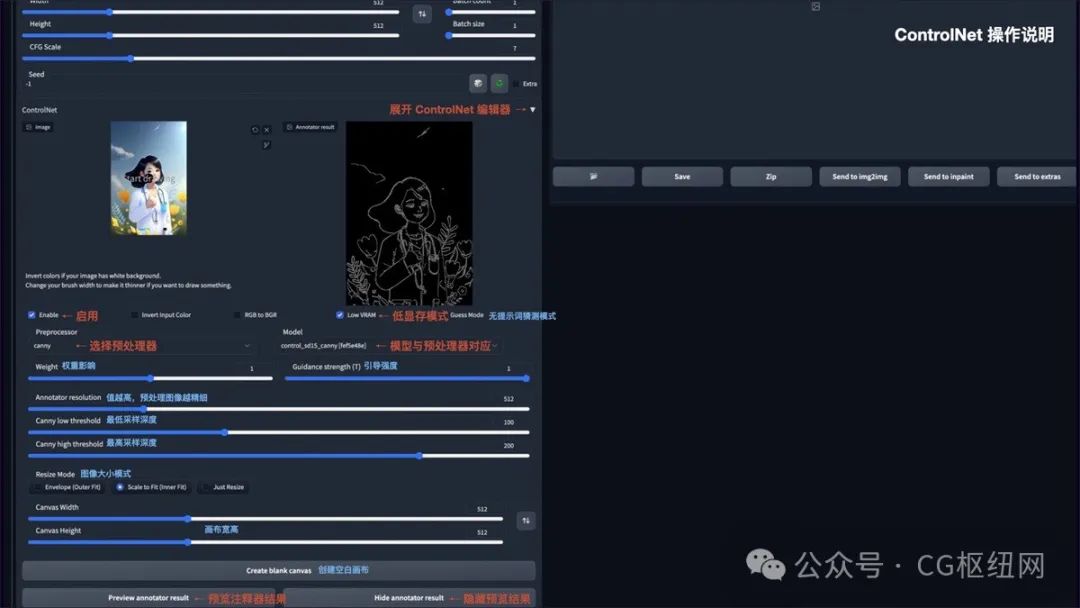
安装完 controlnet 后,在 txt2img 和 img2img 参数面板中均可以调用 controlnet。操作说明:
-
enable:启用 controlnet
-
low vram:低显存模式优化,建议 8g 显存以下开启
-
guess mode:猜测模式,可以不设置提示词,自动生成图片
-
preprocessor:选择预处理器,主要有 openpose、canny、hed、scribble、mlsd、seg、normal map、depth
-
model:controlnet 模型,模型选择要与预处理器对应
-
weight:权重影响,使用 controlnet 生成图片的权重占比影响
-
guidance strength(t):引导强度,值为 1 时,代表每迭代 1 步就会被 controlnet 引导 1 次
-
annotator resolution:数值越高,预处理图像越精细
-
canny low/high threshold:控制最低和最高采样深度
-
resize mode:图像大小模式,默认选择缩放至合适
-
canvas width/height:画布宽高
-
create blank canvas:创建空白画布
-
preview annotator result:预览注释器结果,得到一张 controlnet 模型提取的特征图片
-
hide annotator result:隐藏预览图像窗口
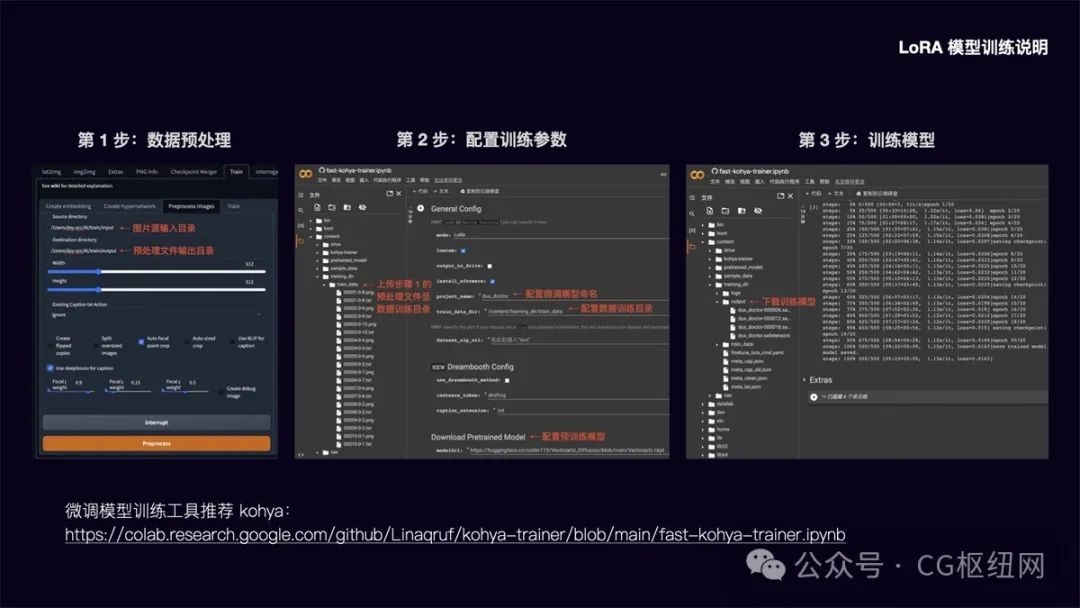
lora 模型训练说明
前面提到 lora 模型具有训练速度快,模型大小适中(100mb 左右),配置要求低(8g 显存),能用少量图片训练出风格效果的优势。
以下简要介绍该模型的训练方法:
第 1 步:数据预处理
在 stable diffusion webui 功能面板中,选择 train 训练功能,点选 preprocess images 预处理图像功能。在 source directory 栏填入你要训练的图片存放目录,在 destination directory 栏填入预处理文件输出目录。width 和 height 为预处理图片的宽高,默认为 512x512,建议把要训练的图片大小统一改成这个尺寸,提升处理速度。勾选 auto focal point crop 自动焦点裁剪,勾选 use deepbooru for caption 自动识别图中的元素并打上标签。点击 preprocess 进行图片预处理。
第 2 步:配置模型训练参数
在这里可以将模型训练放到 google colab 上进行,调用 colab 的免费 15g gpu 将大大提升模型训练速度。lora 微调模型训练工具我推荐使用 kohya,运行 kohya colab:https://colab.research.google.com/github/linaqruf/kohya-trainer/blob/main/fast-kohya-trainer.ipynb
配置训练参数:
先在 content 目录建立 training_dir/training_data 目录,将步骤 1 中的预处理文件上传至该数据训练目录。然后配置微调模型命名和数据训练目录,在 download pretrained model 栏配置需要参考的预训练模型文件。其余的参数可以根据需要调整设置。
第 3 步:训练模型
参数配置完成后,运行程序即可进行模型训练。训练完的模型将被放到 training_dir/output 目录,我们下载 safetensors 文件格式的模型,存放到 stable-diffusion-webui/models/lora 目录中即可调用该模型。由于直接从 colab 下载速度较慢,另外断开 colab 连接后也将清空模型文件,这里建议在 extras 中配置 huggingface 的 write token,将模型文件上传到 huggingface 中,再从 huggingface file 中下载,下载速度大大提升,文件也可进行备份。
2. prompt 语法技巧
文生图模型的精髓在于 prompt 提示词,如何写好 prompt 将直接影响图像的生成质量。
提示词结构化
prompt 提示词可以分为 4 段式结构:画质画风 + 画面主体 + 画面细节 + 风格参考
-
画面画风:主要是大模型或 lora 模型的 tag、正向画质词、画作类型等
-
画面主体:画面核心内容、主体人/事/物/景、主体特征/动作等
-
画面细节:场景细节、人物细节、环境灯光、画面构图等
-
风格参考:艺术风格、渲染器、embedding tag 等

提示词语法
-
提示词排序:越前面的词汇越受 ai 重视,重要事物的提示词放前面
-
增强/减弱:(提示词:权重数值),默认 1,大于 1 加强,低于 1 减弱。如 (doctor:1.3)
-
混合:提示词 | 提示词,实现多个要素混合,如 [red|blue] hair 红蓝色头发混合
-
+ 和 and:用于连接短提示词,and 两端要加空格
-
分步渲染:[提示词 a:提示词 b:数值],先按提示词 a 生成,在设定的数值后朝提示词 b 变化。如[dog🐱30] 前 30 步画狗后面的画猫,[dog🐱0.9] 前面 90%画狗后面 10%画猫
-
正向提示词:masterpiece, best quality 等画质词,用于提升画面质量
-
反向提示词:nsfw, bad hands, missing fingers……, 用于不想在画面中出现的内容
-
emoji:支持 emoji,如 😍 形容表情,🖐 修饰手

常用提示词举例:

3. chatgpt 辅助生成提示词
我们也可以借助 chatgpt 帮我们生成提示词参考。
-
给 chatgpt 一段示例参考:https://dreamlike.art/guides/using-openai-chat-gpt-to-write-stable-diffusion-prompts
-
根据参考生成 prompts,再添加细节润色

4. stable diffusion 全中文环境配置
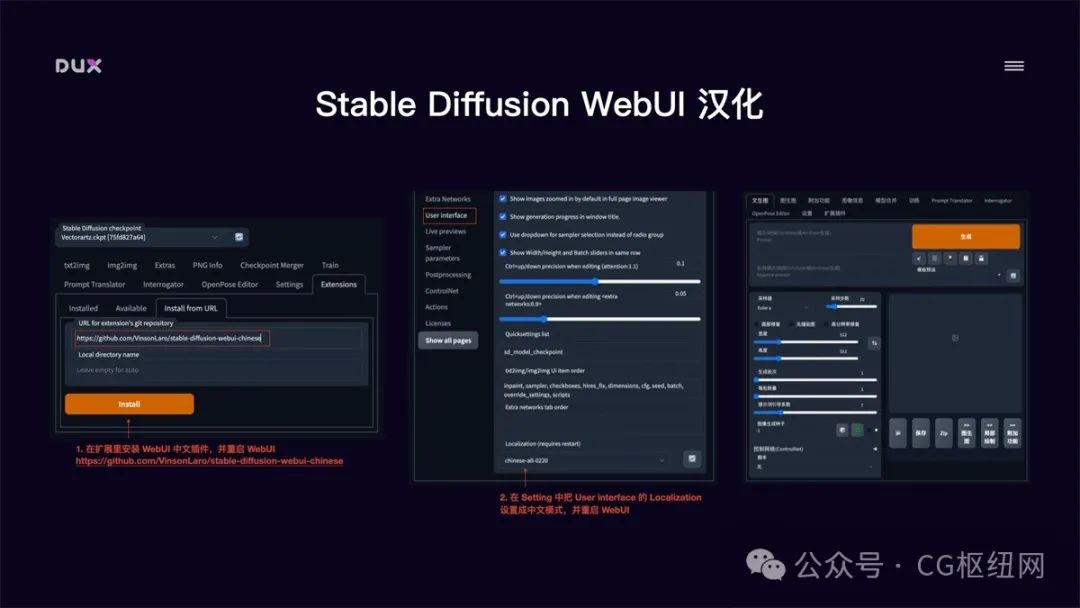
在实际使用中,我们还可以把 stable diffusion 配置成全中文环境,这将大大增加操作友好度。全中文环境包括了 stable diffusion webui 的汉化和 prompt 支持中文输入。
stable diffusion webui 汉化
-
安装中文扩展插件:点击 extensions 选择 install from url,输入 https://github.com/vinsonlaro/stable-diffusion-webui-chinese ,点击 install,并重启 webui
-
切换到中文模式:在 settings 面板中,将 user interface 中的 localization 设置成 chinese 中文模式,重启 webui 即可切换到中文界面
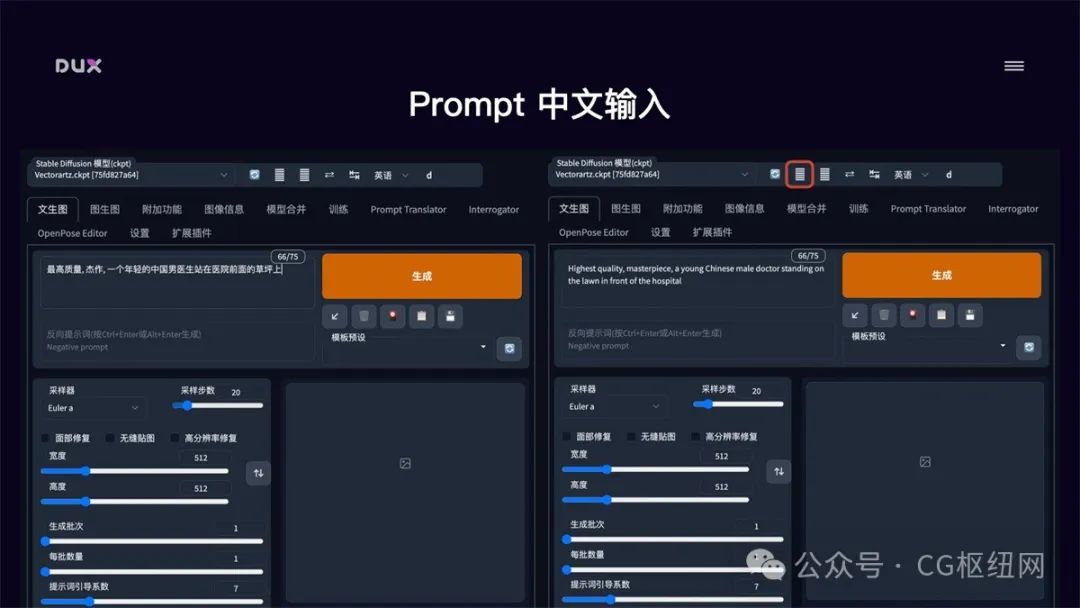
prompt 中文输入
-
下载提示词中文扩展插件:https://github.com/butaixianran/stable-diffusion-webui-prompt-translator ,将项目作为 zip 文件下载,解压后放到 stable-diffusion-webui/extensions 目录中,重启 webui
-
调用百度翻译 api:去 api.fanyi.baidu.com 申请一个免费 api key,并将翻译服务开通。在管理控制台的开发者信息页中确认 app id 和 密钥
-
在 stable diffusion webui 的 prompt translator 面板中,选择百度翻译引擎,并将申请的 app id 和 密钥填写进去,点击保存
-
使用:在 stable diffusion webui 页面顶部会出现一个翻译工具栏,我们在提示词输入框中输入中文,点击工具栏中的翻译就能自动把提示词替换成英文
目前 controlnet 已经更新到 1.1 版本,相较于 1.0 版本,controlnet1.1 新增了更多的预处理器和模型,原有的模型也通过更好的数据训练获得了更优的性能。以下我做简要梳理,想要了解更多内容可以参考作者的文档:https://github.com/lllyasviel/controlnet-v1-1-nightly
controlnet 的使用方式非常灵活,既可以单模型应用,也可以多模型组合应用。清楚 controlnet 的一些原理方法后,可以帮助我们更好的提升出图效果。以下通过一些示例,简要介绍 controlnet 的实际用法。
一、controlnet 单模型应用
1. 线稿上色
**方法:**通过 controlnet 边缘检测模型或线稿模型提取线稿(可提取参考图片线稿,或者手绘线稿),再根据提示词和风格模型对图像进行着色和风格化。
**应用模型:**canny、softedge、lineart。
canny 边缘检测:
canny 是比较常用的一种线稿提取方式,该模型能够很好的识别出图像内各对象的边缘轮廓。
使用说明(以下其它模型同理):
-
展开 controlnet 面板,上传参考图,勾选 enable 启用(如果显存小于等于 4g,勾选低显存模式)。
-
预处理器选择 canny(**注意:**如果上传的是已经经过预处理的线稿图片,则预处理器选择 none,不进行预处理),模型选择对应的 control_v11p_sd15_canny 模型。
-
勾选 allow preview 允许预览,点击预处理器旁的🎆按钮生成预览。
其它参数说明:
-
control weight:使用 controlnet 生成图片的权重占比影响(多个 controlnet 组合使用时,需要调整权重占比)。
-
starting control step:controlnet 开始参与生图的步数。
-
ending control step:controlnet 结束参与生图的步数。
-
preprocessor resolution:预处理器分辨率,默认 512,数值越高线条越精细,数值越低线条越粗糙。
-
canny 低阈值/高阈值:数值越低线条越复杂,数值越高线条越简单。
canny 示例:(保留结构,再进行着色和风格化)
softedge 软边缘检测:
softedge 可以理解为是 controlnet1.0 中 hed 边缘检测的升级版。controlnet1.1 版本中 4 个预处理器按结果质量排序:softedge_hed > softedge_pidi > softedge_hed_safe > softedge_pidi_safe,其中带 safe 的预处理器可以防止生成的图像带有不良内容。相较于 canny,softedge 边缘能够保留更多细节。
softedge 示例:(保留结构,再进行着色和风格化)
lineart 精细线稿提取:
lineart 精细线稿提取是 controlnet1.1 版本中新增的模型,相较于 canny,lineart 提取的线稿更加精细,细节更加丰富。
lineart 的预处理器有三种模式:lineart_coarse(粗略模式),lineart_realistic(详细模式),lineart_standard(标准模式),处理效果有所不同,对比如下:
lineart 示例:(保留结构,再进行着色和风格化)
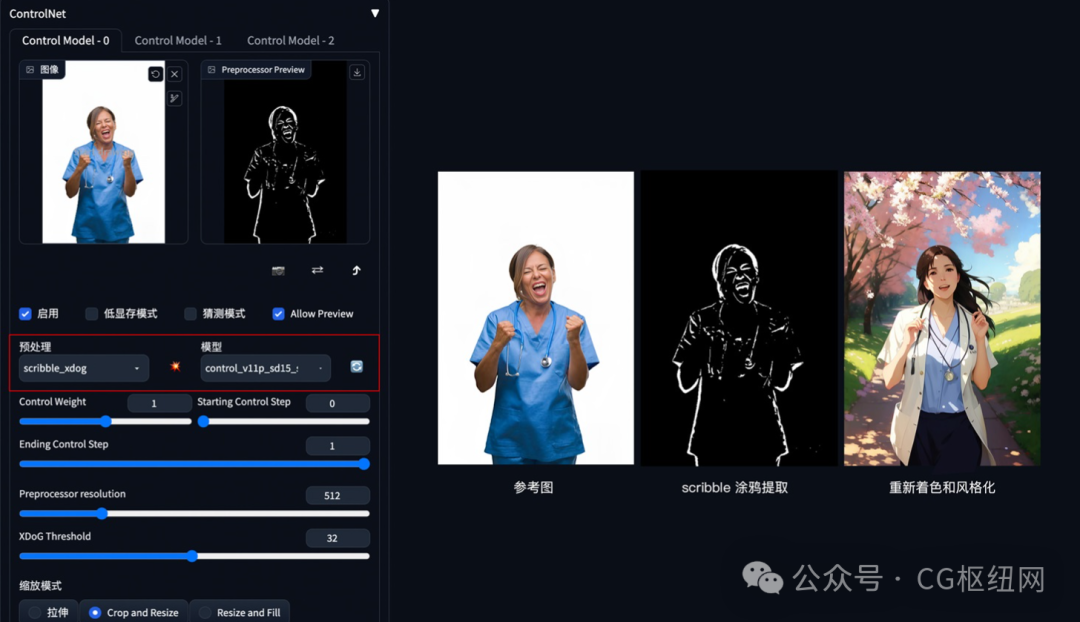
2. 涂鸦成图
方法:通过 controlnet 的 scribble 模型提取涂鸦图(可提取参考图涂鸦,或者手绘涂鸦图),再根据提示词和风格模型对图像进行着色和风格化。
应用模型:scribble。
scribble 比 canny、softedge 和 lineart 的自由发挥度要更高,也可以用于对手绘稿进行着色和风格处理。scribble 的预处理器有三种模式:scribble_hed,scribble_pidinet,scribble_xdog,对比如下,可以看到 scribble_xdog 的处理细节更为丰富:
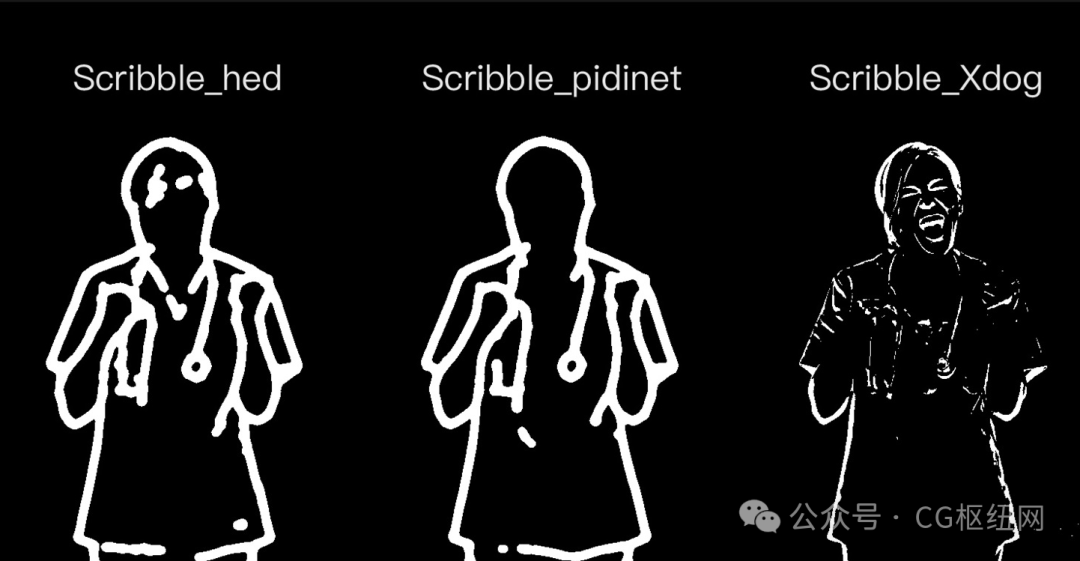
scribble 参考图提取示例(保留大致结构,再进行着色和风格化):
scribble 手动涂鸦示例(根据手绘草图,生成图像):
也可以不用参考图,直接创建空白画布,手绘涂鸦成图。

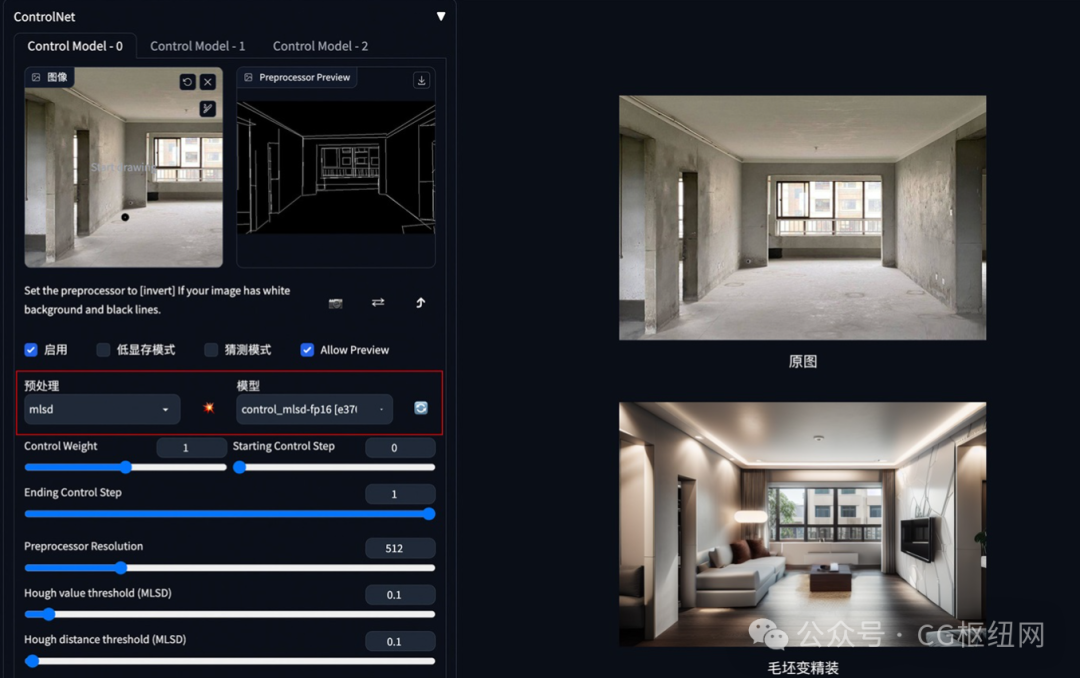
3. 建筑/室内设计
方法:通过 controlnet 的 mlsd 模型提取建筑的线条结构和几何形状,构建出建筑线框(可提取参考图线条,或者手绘线条),再配合提示词和建筑/室内设计风格模型来生成图像。
应用模型:mlsd。
建筑/室内设计风格模型下载:
-
https://civitai.com/?query=interior
-
https://civitai.com/?query=building
mlsd 示例:(毛坯变精装)
4. 颜色控制画面
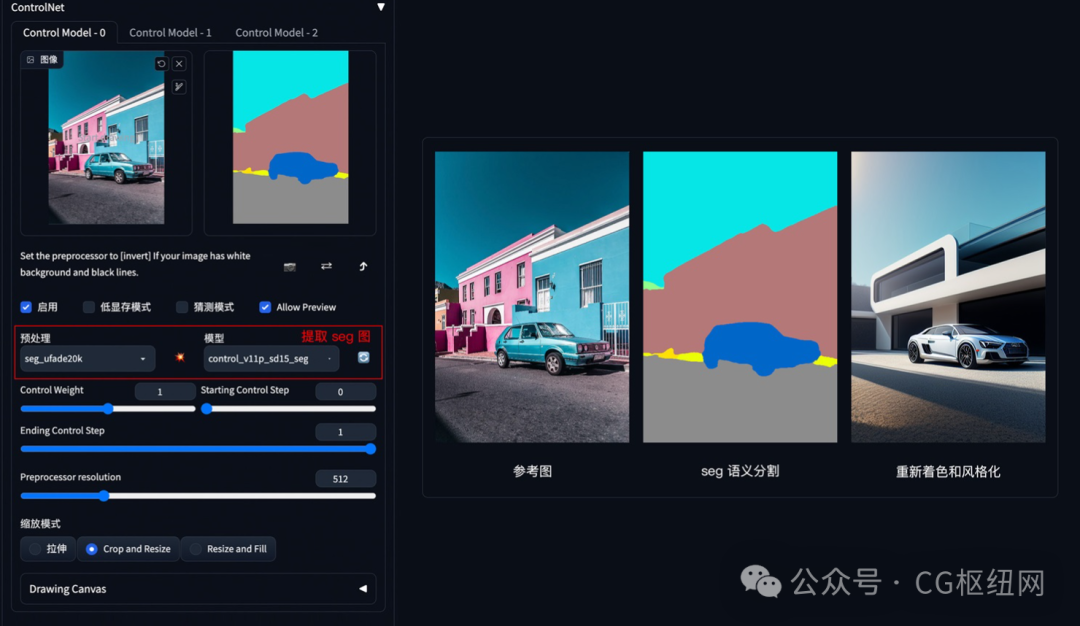
方法:通过 controlnet 的 segmentation 语义分割模型,标注画面中的不同区块颜色和结构(不同颜色代表不同类型对象),从而控制画面的构图和内容。
应用模型:seg。
seg 语义参考:https://docs.qq.com/sheet/dymtkwg5tawxhvkx2?tab=bb08j2
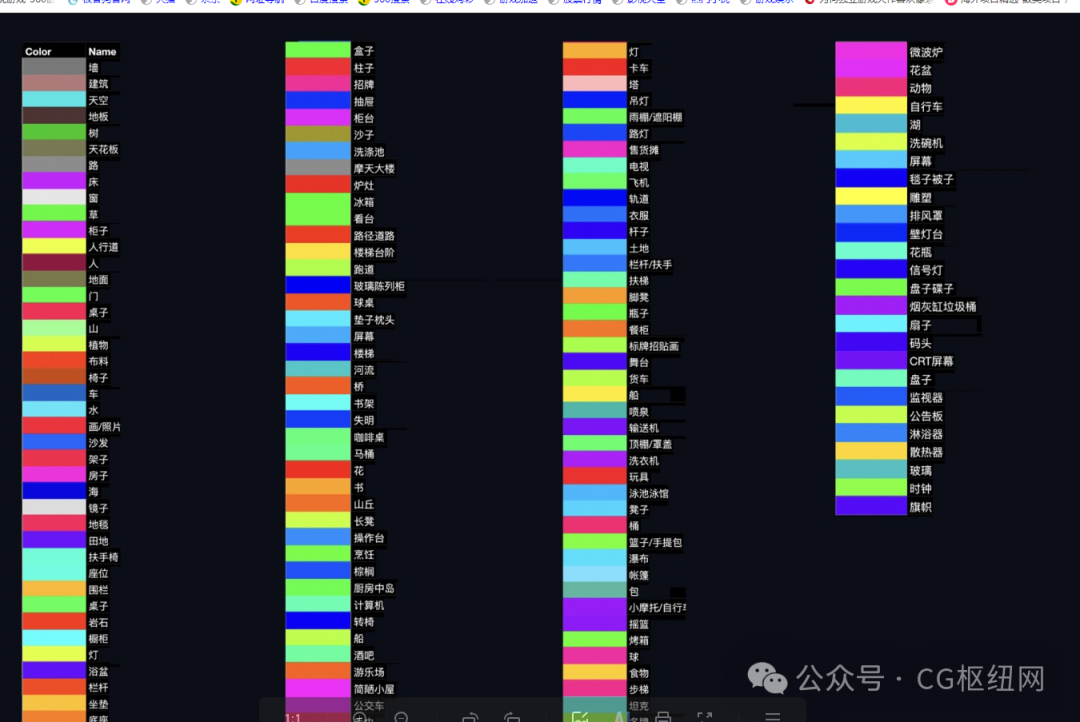
seg 示例:(提取参考图内容和结构,再进行着色和风格化)
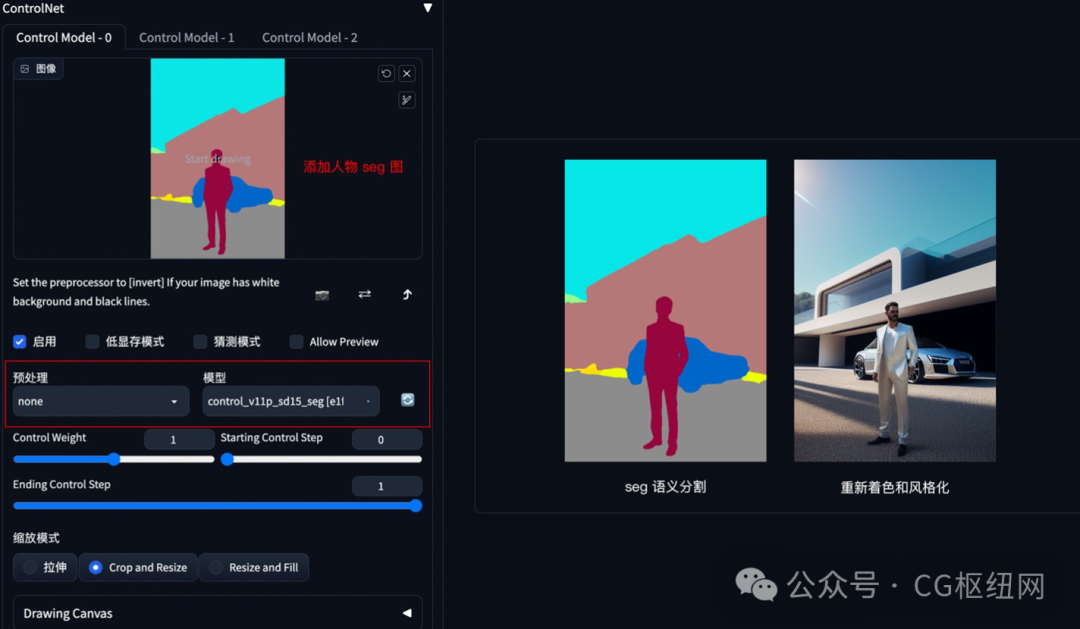
如果还想在车前面加一个人,只需在 seg 预处理图上对应人物色值,添加人物色块再生成图像即可。
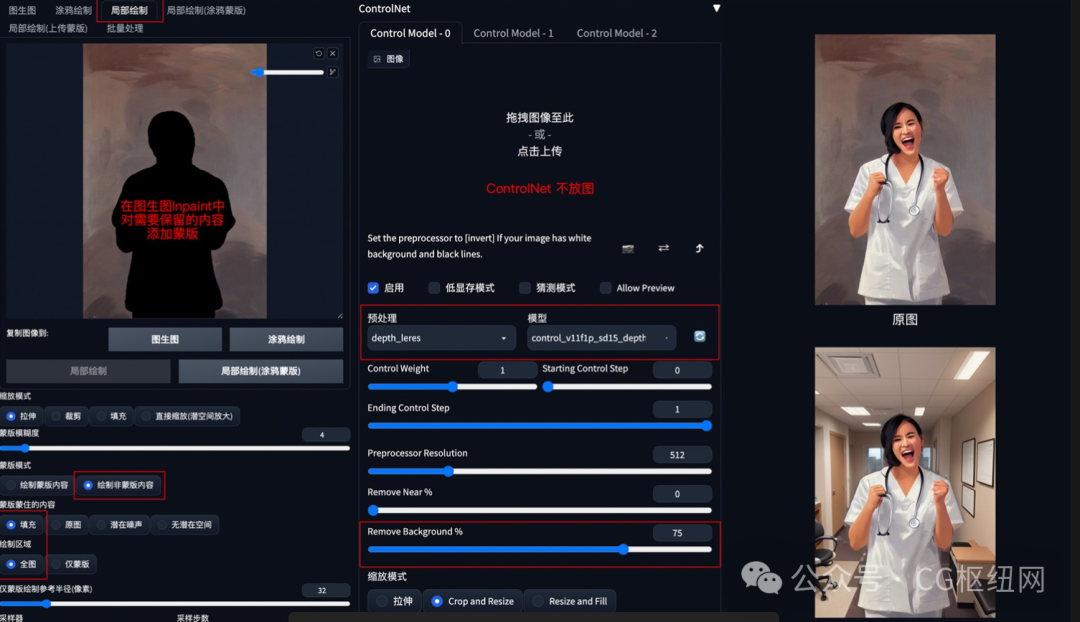
5. 背景替换
方法:在 img2img 图生图模式中,通过 controlnet 的 depth_leres 模型中的 remove background 功能移除背景,再通过提示词更换想要的背景。
应用模型:depth,预处理器 depth_leres。
要点:如果想要比较完美的替换背景,可以在图生图的 inpaint 模式中,对需要保留的图片内容添加蒙版,remove background 值可以设置在 70-80%。
depth_leres 示例:(将原图背景替换为办公室背景)
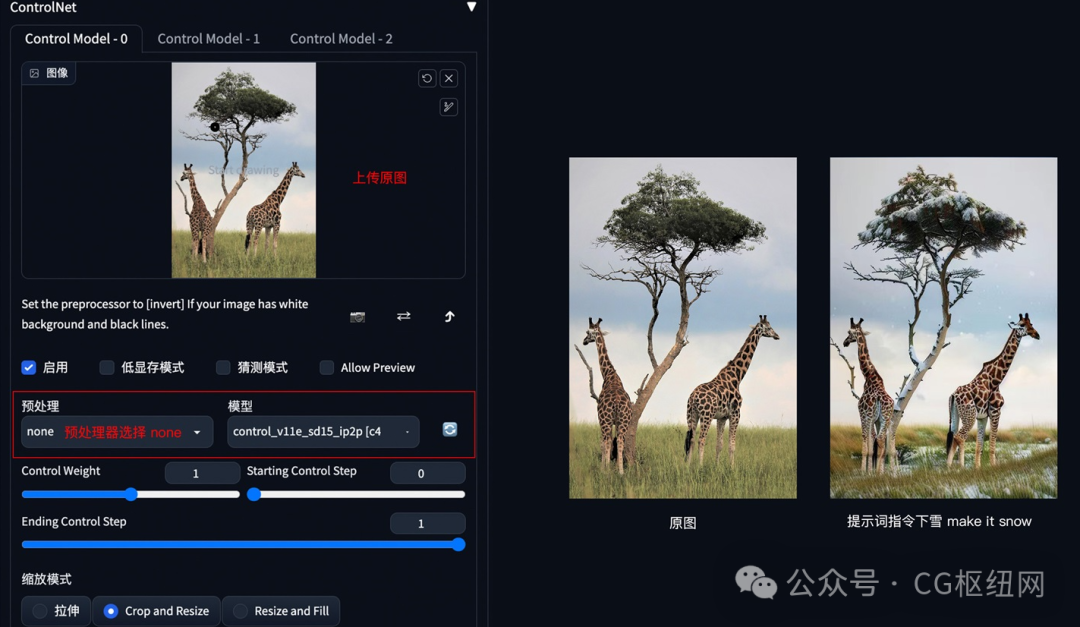
6. 图片指令
方法:通过 controlnet 的 pix2pix 模型(ip2p),可以对图片进行指令式变换。
应用模型:ip2p,预处理器选择 none。
要点:采用指令式提示词(make y into x),如下图示例中的 make it snow,让非洲草原下雪。
pix2pix 示例:(让非洲草原下雪)
7. 风格迁移
方法:通过 controlnet 的 shuffle 模型提取出参考图的风格,再配合提示词将风格迁移到生成图上。
应用模型:shuffle。
shuffle 示例:(根据魔兽道具风格,重新生成一个宝箱道具)
8. 色彩继承
方法:通过 controlnet 的 t2iacolor 模型提取出参考图的色彩分布情况,再配合提示词和风格模型将色彩应用到生成图上。
应用模型:color。
color 示例:(把参考图色彩分布应用到生成图上)
9. 角色三视图
方法:通过 controlnet 的 openpose 模型精准识别出人物姿态,再配合提示词和风格模型生成同样姿态的图片。
应用模型:openpose。在 controlnet1.1 版本中,提供了多种姿态检测方式,包含:openpose 身体、openpose_face 身体+脸、openpose_faceonly 只有脸、openpose_full 身体+手+脸、openpose_hand 手,可以根据实际需要灵活应用。
openpose 角色三视图示例:
要点:上传 openpose 三视图,加载 charturner 风格模型( https://civitai.com/?query=charturner ),添加提示词保持背景干净 (simple background, white background:1.3), multiple views
10. 图片光源控制
方法:如果想对生成的图片进行打光,可以在 img2img 模式下,把光源图片上传到图生图区域,controlnet 中放置需要打光的原图,controlnet 模型选择 depth。
应用模型:depth。
要点:图生图中的所有参数和提示词信息需要与原图生成时的参数一样,具体原图参数可以在 png info 面板中查看并复制。
示例:
二、controlnet 多模型组合应用
controlnet 还支持多个模型的组合使用,从而对图像进行多条件控制。controlnet 的多模型控制可以在设置面板中的 controlnet 模块中开启:
1. 人物和背景分别控制
方法:设置 2 个 controlnet,第一个 controlnet 通过 openpose 控制人物姿态,第二个 controlnet 通过 seg 或 depth 控制背景构成。调整 controlnet 权重,如 openpose 权重高于 depth 权重,以确保人物姿态被正确识别,再通过提示词和风格模型进行内容和风格控制。
应用模型:openpose、seg(自定义背景内容和结构)、depth。
示例:
2. 三维重建
方法:通过 depth 深度检测和 normalbae 法线贴图模型,识别三维目标。再配合提示词和风格模型,重新构建出三维物体和场景。
应用模型:depth、normalbae。
示例:
3. 更精准的图片风格化
方法:在 img2img 图生图中,通过叠加 lineart 和 depth 模型,可以更加精准的提取图像结构,最大程度保留原图细节,再配合提示词和风格模型重新生成图像。
应用模型:lineart、depth。
示例:
4. 更精准的图片局部重绘
方法:在 img2img 图生图的局部重绘中,通过叠加 canny 和 inpaint 模型,可以更加精准的对图像进行局部重绘。
应用模型:canny、inpaint。
示例:
「stable diffusion」
大家好,我是**「查尔斯」**,今天给大家分享一些可以下载stable diffusion模型的网站。
1. civitai
「https://civitai.com/」
第一个肯定是大名鼎鼎的c站,拥有海量的底模和lora。
civitai
2. 哩布哩布ai
「https://www.liblibai.com/」
c站虽好,但需要魔法,哩布哩布ai是中国原创ai模型分享社区,许多魔法师会在c站和哩布哩布同时发布模型,因此哩布哩布ai也拥有大量的模型,足够大家使用玩耍。
哩布哩布ai
3. 炼丹阁
「https://www.liandange.com/」
专业全面的模型平台社区,跟哩布哩布ai差不多。
炼丹阁
4. hugging face
「https://huggingface.co/models?pipeline_tag=text-to-image&sort=downloads」
「https://huggingface.co/anonperson/chilloutmix/tree/main」
huggin face(抱抱脸)是一个允许用户共享机器学习模型和数据集,拥有海量但不限于stable diffusion模型的开源平台。这里有许多最新发布的stable diffusion通用基础模型。此外还有许多用户自己训练上传的底模或者lora,感兴趣可以自己探索。
hugging face text-to-image
chilloutmix
chilloutmix之前在c站,但因为某些原因被扳了🫣,没来得及下载的可以去这里下载。
5. stableres.info
「https://stableres.info/」
直接从hugging face中找模型肯定没有头绪,要是能直接像c站看效果图选模型就好了,欸嘿,这个网站就能满足。该网站的大多数模型都是来自hugging face。
stableres.info
6. 其他
下面是一些赛博菩萨的小众网站,网站虽小,模型可不少。
「https://www.123114514.xyz/」
「https://www.sdziyuan.cn/」
「https://rentry.org/sdmodels」
「https://aituzhan.com/」
如有侵权,请联系删除。
写在最后
感兴趣的小伙伴,赠送全套aigc学习资料,包含ai绘画、ai人工智能等前沿科技教程和软件工具,具体看这里。

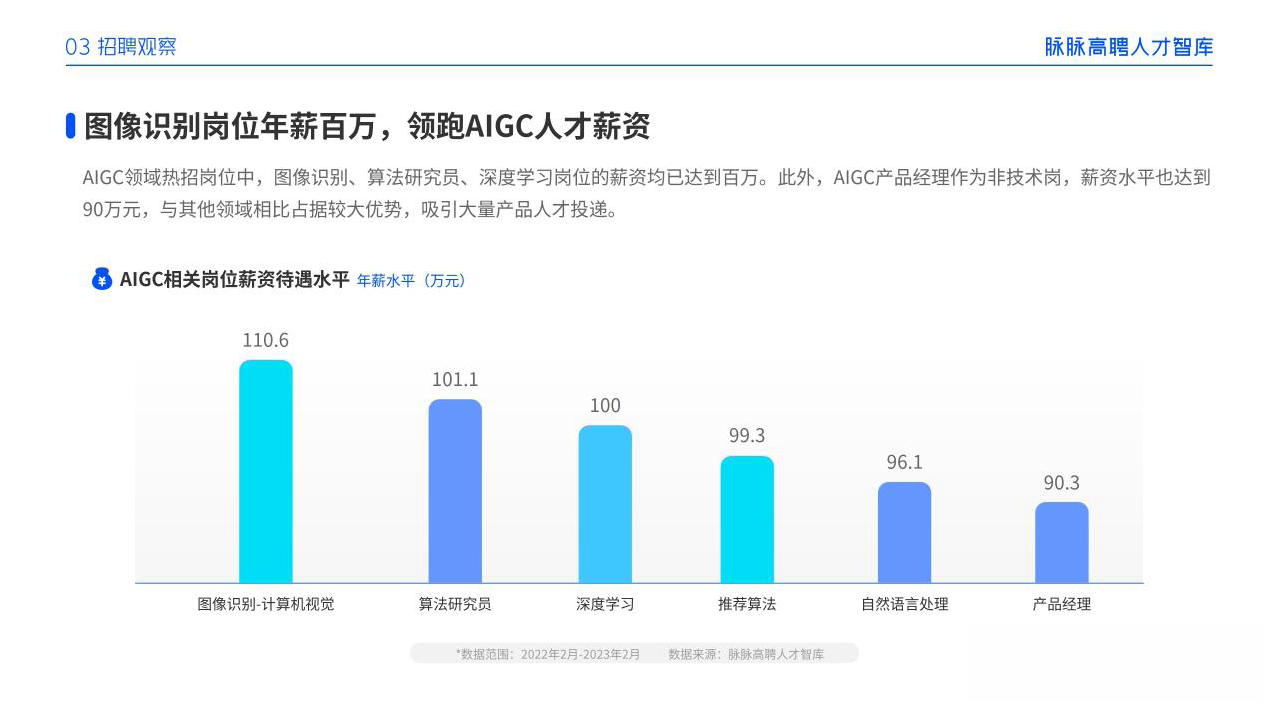
aigc技术的未来发展前景广阔,随着人工智能技术的不断发展,aigc技术也将不断提高。未来,aigc技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,aigc技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,aigc技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
一、aigc所有方向的学习路线
aigc所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。
二、aigc必备工具
工具都帮大家整理好了,安装就可直接上手!
三、最新aigc学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、aigc视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
若有侵权,请联系删除!



发表评论