有时候,我们某个数据表中,可能有几列的数据都是一样的,此时我们可能想查询出这几列数据相同的所有数据行,并保留最新一条,将其他重复的数据删除。
🥇1、row_number函数
假设我们有如下数据表:
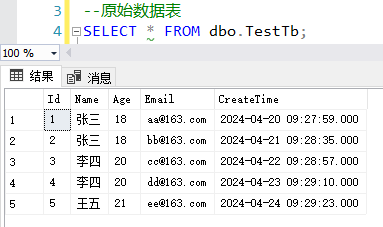
此时我们可以使用row_number函数,根据某几列查询出重复数据的新的排序列,该排序列就是根据某几列重复数据生成的序号(从1开始),如下所示orderno就是我们新生成的列:
--根据name和age这2个字段进行查询并获得新的列orderno(orderno就是根据name和age重复数据生成的序号,从1开始),同时按照createtime降序排列 select *,orderno=row_number() over(partition by [name],age order by createtime desc) from dbo.testtb
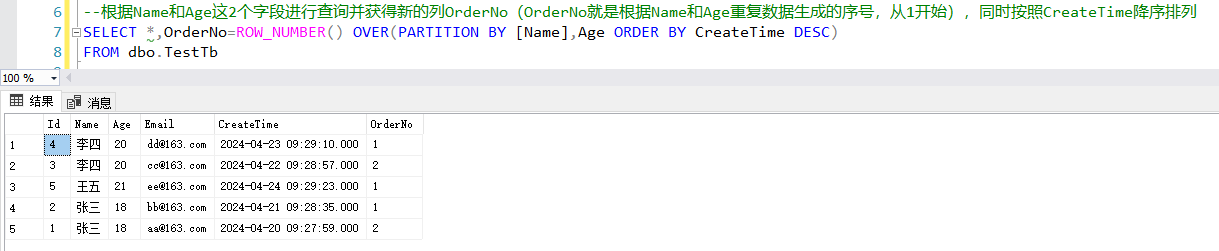
🥈2、删除数据
有了上述代码中的排序列,我们就可以知道,orderno的值>1的数据行都是我们需要删除的数据,完整代码如下所示:
--删除表testtb中字段name和age同时重复的数据,并保留最新一条
delete from dbo.testtb where id in(
--根据name和age这2个字段查询出重复的数据
select id from
(
--根据name和age这2个字段进行查询并获得新的列orderno(orderno就是根据name和age重复数据生成的序号,从1开始),同时按照createtime降序排列
select *,orderno=row_number() over(partition by [name],age order by createtime desc)
from dbo.testtb
) tmp
where orderno>1
);
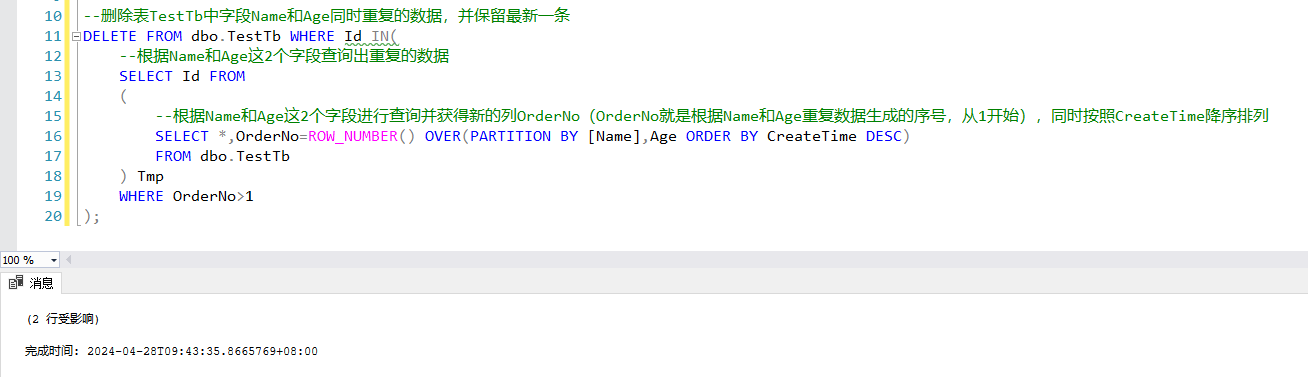
执行删除:
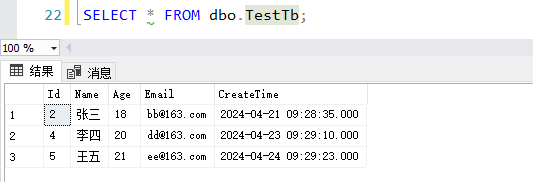
删除后的:

发表评论