一、前馈网络概要
1、定义
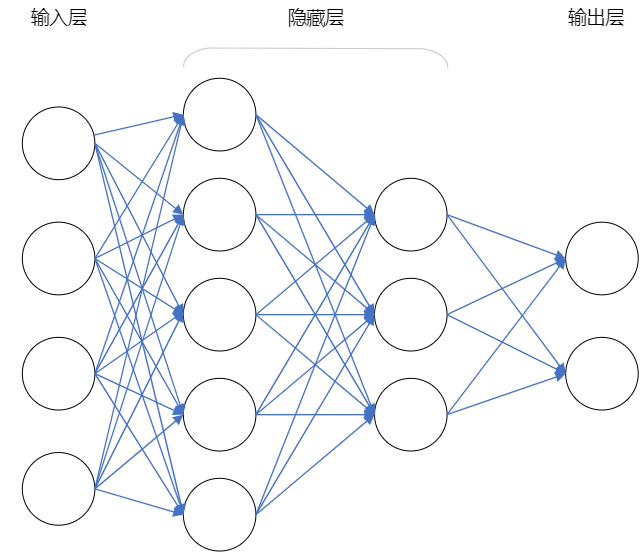
前馈神经网络(fnn)是一种最简单的神经网络结构,其中信息在一个方向上流动,从输入层到输出层,不会有反馈环路。该网络由多个神经元组成,这些神经元通常被组织成几个层,包括输入层、隐藏层和输出层。
2、特点
简单直观:前馈神经网络的结构比较简单明了,信息只朝一个方向传播,便于理解和实现。
高效性能:尽管简单,前馈神经网络在许多任务中表现出色,尤其在处理大规模数据和复杂模式时有很高的性能表现。
可扩展性:前馈神经网络可以很容易地扩展到更深、更宽的网络结构,以适应不同的任务和数据。
并行计算:由于前馈神经网络的结构,其各个神经元之间的计算是独立的,可以实现高效的并行计算加速。
适用性广泛:前馈神经网络广泛应用于图像识别、语音识别、文本分类、回归分析等多个领域,具有很好的适用性和灵活性。
易于训练:前馈神经网络通常使用反向传播算法进行训练,这是一种有效的优化算法,可以通过调整网络的权重和偏差来最小化损失函数,提高网络的性能。
二、自然语言处理与前馈神经网络
前馈神经网络的结构简单,易于实现和训练并且能够处理高维数据,而在自然语言处理中文本数据通常是高维的,故前馈神经网络十分适用于完成各种自然语言处理的任务。现在前馈神经网络被广泛应用于各种自然语言处理任务,包括但不限于以下几个方面:
-
文本分类:前馈神经网络可以用于文本分类任务,例如情感分析、垃圾邮件过滤、新闻分类等。输入文本数据经过处理后,通过前馈神经网络可以实现对文本进行自动分类。
-
语言模型:前馈神经网络可以用于构建语言模型,从而实现自然语言生成和语言理解任务。通过训练前馈神经网络,可以学习文本序列之间的模式和关系,从而生成自然流畅的文本或对文本进行理解。
-
序列标注:在词性标注、命名实体识别、文本分类等序列标注任务中,前馈神经网络也被广泛应用。通过将输入序列数据经过前馈神经网络的处理,可以实现对序列数据进行标注或分类。
-
机器翻译:前馈神经网络在机器翻译任务中也有应用。通过构建编码器-解码器结构的前馈神经网络,可以实现将一种语言的文本翻译成另一种语言的功能。
-
文本生成:前馈神经网络还可用于文本生成任务,如对话生成、摘要生成等。通过学习文本序列的模式和关系,前馈神经网络可以生成自然语言文本。
三、基于pytorch的一个简单实现
任务描述:我们将多层感知机应用于将姓氏分类到其原籍国的任务。
代码实现思路:
1、数据预处理
2、构建多层感知机模型
3、训练模型
4、预测结果
以下是具体代码部分:
1、数据预处理
数据集名为surname.csv,它从互联网上不同的姓名来源收集了了来自18个不同国家的10,000个姓氏。数据预处理的目的一是为了平衡数据集中18个国家的姓氏在数据集中的比例,均匀的比例分布有利于训练有效的模型。另外要将数据集分为三个部分:70%到训练数据集,15%到验证数据集,最后15%到测试数据集,以便跨这些部分的类标签分布具有可比性。
2、构建多层感知机模型
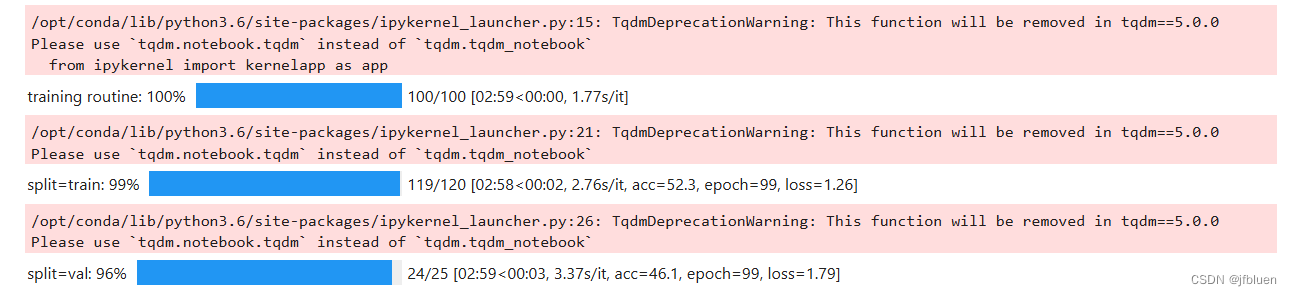
3、训练模型
4、预测结果
# compute the loss & accuracy on the test set using the best available model
classifier.load_state_dict(torch.load(train_state['model_filename']))
classifier = classifier.to(args.device)
dataset.class_weights = dataset.class_weights.to(args.device)
loss_func = nn.crossentropyloss(dataset.class_weights)
dataset.set_split('test')
batch_generator = generate_batches(dataset,
batch_size=args.batch_size,
device=args.device)
running_loss = 0.
running_acc = 0.
classifier.eval()
for batch_index, batch_dict in enumerate(batch_generator):
# compute the output
y_pred = classifier(batch_dict['x_surname'])
# compute the loss
loss = loss_func(y_pred, batch_dict['y_nationality'])
loss_t = loss.item()
running_loss += (loss_t - running_loss) / (batch_index + 1)
# compute the accuracy
acc_t = compute_accuracy(y_pred, batch_dict['y_nationality'])
running_acc += (acc_t - running_acc) / (batch_index + 1)
train_state['test_loss'] = running_loss
train_state['test_acc'] = running_acc
print("test loss: {};".format(train_state['test_loss']))
print("test accuracy: {}".format(train_state['test_acc']))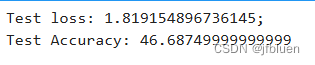





发表评论