第一种方法
按照某列进行由大到小的排序,然后再进去去重,保留第一个值,最终保留的结果就是最大值的数据
# 由大到小排序 data_frame = data_frame.sort_values(by='column_a', ascending=false) # 按照column_b列去重保留第一条,剩下的值即为最大值 data_frame.drop_duplicates(labels='column_b', keep='first', inplace=true)
第二种方法
获取某列最大值的索引,然后再反取索引对应的行即可
比如,有一个daframe有a,b,c三列,现在需要取c列每个值对应a列最大的值:
df = pd.dataframe({
'a': [1, 4, 7, 10, 2],
'b': [5, 2, 9, 3, 6],
'c': [8, 8, 1, 1, 1]
})
print(df)
print('----------------')
# 需要取c列每个值对应的a列的最大值
df_new = df.groupby('c')['a'].agg(pd.series.idxmax)
print(df_new)
print('----------------')
df = df.iloc[df_new]
print(df)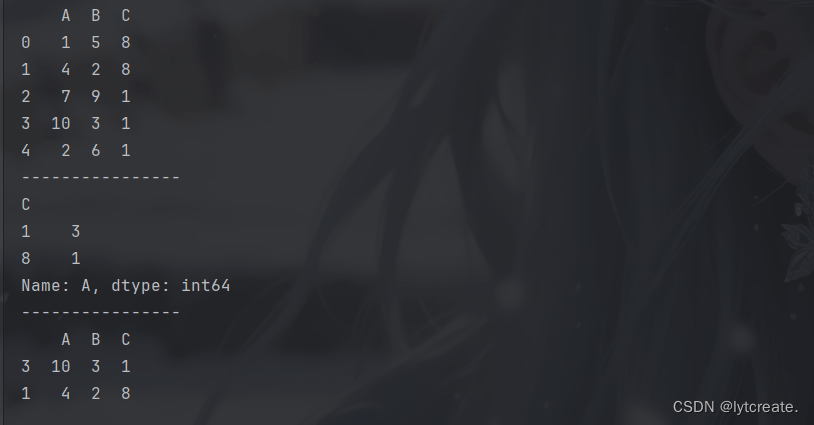
到此这篇关于pandas获取某列最大值的所有数据实现示例的文章就介绍到这了,更多相关pandas获取某列最大值内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论