简介
pandas提供了很多合并series和dataframe的强大的功能,通过这些功能可以方便的进行数据分析。本文将会详细讲解如何使用pandas来合并series和dataframe。
使用concat
concat是最常用的合并df的方法,先看下concat的定义:
pd.concat(objs, axis=0, join='outer', ignore_index=false, keys=none,
levels=none, names=none, verify_integrity=false, copy=true)
看一下我们经常会用到的几个参数:
- objs是series或者series的序列或者映射。
- axis指定连接的轴。
join: {‘inner’, ‘outer’}, 连接方式,怎么处理其他轴的index,outer表示合并,inner表示交集。- ignore_index: 忽略原本的index值,使用0,1,… n-1来代替。
- copy:是否进行拷贝。
- keys:指定最外层的多层次结构的index。
我们先定义几个df,然后看一下怎么使用concat把这几个df连接起来:
in [1]: df1 = pd.dataframe({'a': ['a0', 'a1', 'a2', 'a3'],
...: 'b': ['b0', 'b1', 'b2', 'b3'],
...: 'c': ['c0', 'c1', 'c2', 'c3'],
...: 'd': ['d0', 'd1', 'd2', 'd3']},
...: index=[0, 1, 2, 3])
...:
in [2]: df2 = pd.dataframe({'a': ['a4', 'a5', 'a6', 'a7'],
...: 'b': ['b4', 'b5', 'b6', 'b7'],
...: 'c': ['c4', 'c5', 'c6', 'c7'],
...: 'd': ['d4', 'd5', 'd6', 'd7']},
...: index=[4, 5, 6, 7])
...:
in [3]: df3 = pd.dataframe({'a': ['a8', 'a9', 'a10', 'a11'],
...: 'b': ['b8', 'b9', 'b10', 'b11'],
...: 'c': ['c8', 'c9', 'c10', 'c11'],
...: 'd': ['d8', 'd9', 'd10', 'd11']},
...: index=[8, 9, 10, 11])
...:
in [4]: frames = [df1, df2, df3]
in [5]: result = pd.concat(frames)
df1,df2,df3定义了同样的列名和不同的index,然后将他们放在frames中构成了一个df的list,将其作为参数传入concat就可以进行df的合并。
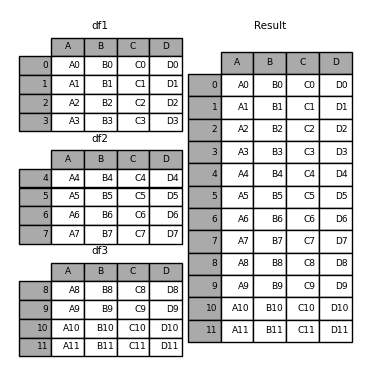
举个多层级的例子:
in [6]: result = pd.concat(frames, keys=['x', 'y', 'z'])
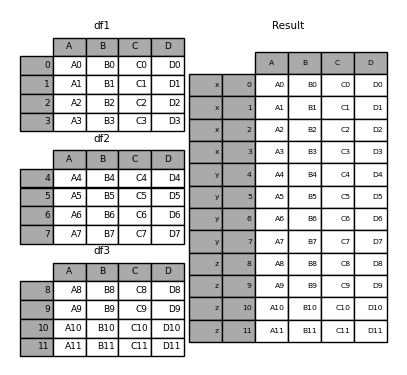
使用keys可以指定frames中不同frames的key。
使用的时候,我们可以通过选择外部的key来返回特定的frame:
in [7]: result.loc['y']
out[7]:
a b c d
4 a4 b4 c4 d4
5 a5 b5 c5 d5
6 a6 b6 c6 d6
7 a7 b7 c7 d7
上面的例子连接的轴默认是0,也就是按行来进行连接,下面我们来看一个例子按列来进行连接,如果要按列来连接,可以指定axis=1:
in [8]: df4 = pd.dataframe({'b': ['b2', 'b3', 'b6', 'b7'],
...: 'd': ['d2', 'd3', 'd6', 'd7'],
...: 'f': ['f2', 'f3', 'f6', 'f7']},
...: index=[2, 3, 6, 7])
...:
in [9]: result = pd.concat([df1, df4], axis=1, sort=false)
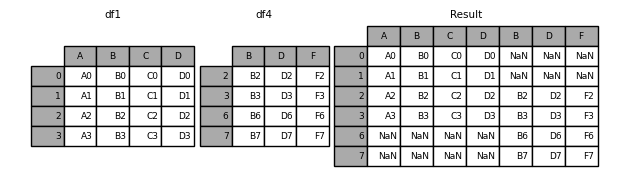
默认的 join='outer',合并之后index不存在的地方会补全为nan。
下面看一个join='inner’的情况:
in [10]: result = pd.concat([df1, df4], axis=1, join='inner')

join=‘inner’ 只会选择index相同的进行展示。
如果合并之后,我们只想保存原来frame的index相关的数据,那么可以使用reindex:
in [11]: result = pd.concat([df1, df4], axis=1).reindex(df1.index)
或者这样:
in [12]: pd.concat([df1, df4.reindex(df1.index)], axis=1)
out[12]:
a b c d b d f
0 a0 b0 c0 d0 nan nan nan
1 a1 b1 c1 d1 nan nan nan
2 a2 b2 c2 d2 b2 d2 f2
3 a3 b3 c3 d3 b3 d3 f3
看下结果:

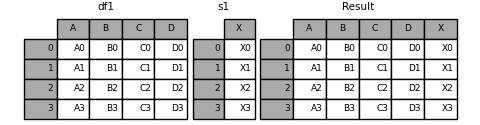
可以合并df和series:
in [18]: s1 = pd.series(['x0', 'x1', 'x2', 'x3'], name='x') in [19]: result = pd.concat([df1, s1], axis=1)
如果是多个series,使用concat可以指定列名:
in [23]: s3 = pd.series([0, 1, 2, 3], name='foo') in [24]: s4 = pd.series([0, 1, 2, 3]) in [25]: s5 = pd.series([0, 1, 4, 5])
in [27]: pd.concat([s3, s4, s5], axis=1, keys=['red', 'blue', 'yellow']) out[27]: red blue yellow 0 0 0 0 1 1 1 1 2 2 2 4 3 3 3 5
使用append
append可以看做是concat的简化版本,它沿着axis=0 进行concat:
in [13]: result = df1.append(df2)
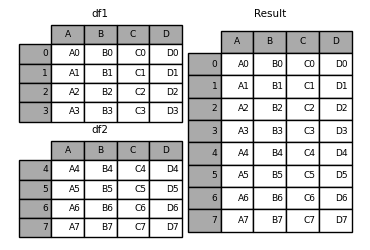
如果append的两个 df的列是不一样的会自动补全nan:
in [14]: result = df1.append(df4, sort=false)
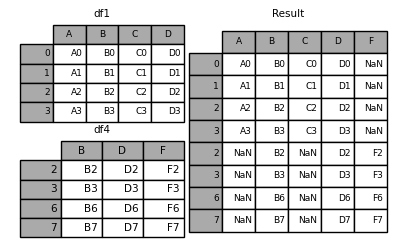
如果设置ignore_index=true,可以忽略原来的index,并重写分配index:
in [17]: result = df1.append(df4, ignore_index=true, sort=false)
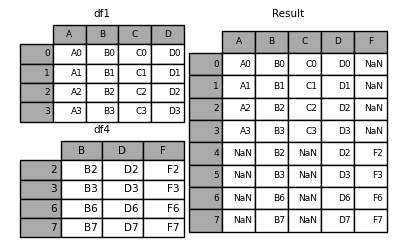
向df append一个series:
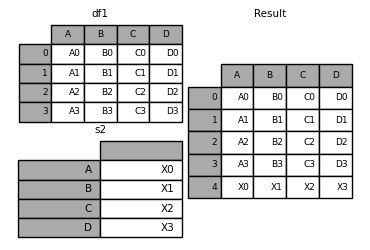
in [35]: s2 = pd.series(['x0', 'x1', 'x2', 'x3'], index=['a', 'b', 'c', 'd']) in [36]: result = df1.append(s2, ignore_index=true)
使用merge
和df最类似的就是数据库的表格,可以使用merge来进行类似数据库操作的df合并操作。
先看下merge的定义:
pd.merge(left, right, how='inner', on=none, left_on=none, right_on=none,
left_index=false, right_index=false, sort=true,
suffixes=('_x', '_y'), copy=true, indicator=false,
validate=none)
left, right是要合并的两个df 或者 series。
on代表的是join的列或者index名。
- left_on:左连接
right_on:右连接left_index: 连接之后,选择使用左边的index或者column。right_index:连接之后,选择使用右边的index或者column。
how:连接的方式,'left', 'right', 'outer', 'inner'. 默认 inner.
sort: 是否排序。suffixes: 处理重复的列。copy: 是否拷贝数据
先看一个简单merge的例子:
in [39]: left = pd.dataframe({'key': ['k0', 'k1', 'k2', 'k3'],
....: 'a': ['a0', 'a1', 'a2', 'a3'],
....: 'b': ['b0', 'b1', 'b2', 'b3']})
....:
in [40]: right = pd.dataframe({'key': ['k0', 'k1', 'k2', 'k3'],
....: 'c': ['c0', 'c1', 'c2', 'c3'],
....: 'd': ['d0', 'd1', 'd2', 'd3']})
....:
in [41]: result = pd.merge(left, right, on='key')
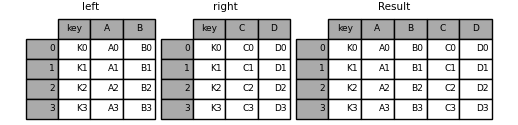
上面两个df通过key来进行连接。
再看一个多个key连接的例子:
in [42]: left = pd.dataframe({'key1': ['k0', 'k0', 'k1', 'k2'],
....: 'key2': ['k0', 'k1', 'k0', 'k1'],
....: 'a': ['a0', 'a1', 'a2', 'a3'],
....: 'b': ['b0', 'b1', 'b2', 'b3']})
....:
in [43]: right = pd.dataframe({'key1': ['k0', 'k1', 'k1', 'k2'],
....: 'key2': ['k0', 'k0', 'k0', 'k0'],
....: 'c': ['c0', 'c1', 'c2', 'c3'],
....: 'd': ['d0', 'd1', 'd2', 'd3']})
....:
in [44]: result = pd.merge(left, right, on=['key1', 'key2'])

how 可以指定merge方式,和数据库一样,可以指定是内连接,外连接等:
| 合并方法 | sql 方法 |
|---|---|
left | left outer join |
right | right outer join |
outer | full outer join |
inner | inner join |
in [45]: result = pd.merge(left, right, how='left', on=['key1', 'key2'])
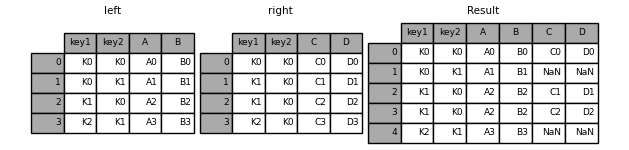
指定indicator=true ,可以表示具体行的连接方式:
in [60]: df1 = pd.dataframe({'col1': [0, 1], 'col_left': ['a', 'b']})
in [61]: df2 = pd.dataframe({'col1': [1, 2, 2], 'col_right': [2, 2, 2]})
in [62]: pd.merge(df1, df2, on='col1', how='outer', indicator=true)
out[62]:
col1 col_left col_right _merge
0 0 a nan left_only
1 1 b 2.0 both
2 2 nan 2.0 right_only
3 2 nan 2.0 right_only
如果传入字符串给indicator,会重命名indicator这一列的名字:
in [63]: pd.merge(df1, df2, on='col1', how='outer', indicator='indicator_column') out[63]: col1 col_left col_right indicator_column 0 0 a nan left_only 1 1 b 2.0 both 2 2 nan 2.0 right_only 3 2 nan 2.0 right_only
多个index进行合并:
in [112]: leftindex = pd.multiindex.from_tuples([('k0', 'x0'), ('k0', 'x1'),
.....: ('k1', 'x2')],
.....: names=['key', 'x'])
.....:
in [113]: left = pd.dataframe({'a': ['a0', 'a1', 'a2'],
.....: 'b': ['b0', 'b1', 'b2']},
.....: index=leftindex)
.....:
in [114]: rightindex = pd.multiindex.from_tuples([('k0', 'y0'), ('k1', 'y1'),
.....: ('k2', 'y2'), ('k2', 'y3')],
.....: names=['key', 'y'])
.....:
in [115]: right = pd.dataframe({'c': ['c0', 'c1', 'c2', 'c3'],
.....: 'd': ['d0', 'd1', 'd2', 'd3']},
.....: index=rightindex)
.....:
in [116]: result = pd.merge(left.reset_index(), right.reset_index(),
.....: on=['key'], how='inner').set_index(['key', 'x', 'y'])
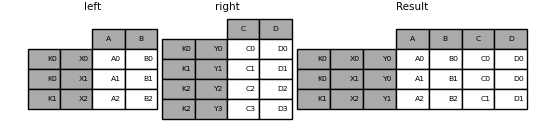
支持多个列的合并:
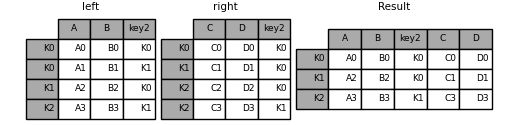
in [117]: left_index = pd.index(['k0', 'k0', 'k1', 'k2'], name='key1')
in [118]: left = pd.dataframe({'a': ['a0', 'a1', 'a2', 'a3'],
.....: 'b': ['b0', 'b1', 'b2', 'b3'],
.....: 'key2': ['k0', 'k1', 'k0', 'k1']},
.....: index=left_index)
.....:
in [119]: right_index = pd.index(['k0', 'k1', 'k2', 'k2'], name='key1')
in [120]: right = pd.dataframe({'c': ['c0', 'c1', 'c2', 'c3'],
.....: 'd': ['d0', 'd1', 'd2', 'd3'],
.....: 'key2': ['k0', 'k0', 'k0', 'k1']},
.....: index=right_index)
.....:
in [121]: result = left.merge(right, on=['key1', 'key2'])
使用join
join将两个不同index的df合并成一个。可以看做是merge的简写。
in [84]: left = pd.dataframe({'a': ['a0', 'a1', 'a2'],
....: 'b': ['b0', 'b1', 'b2']},
....: index=['k0', 'k1', 'k2'])
....:
in [85]: right = pd.dataframe({'c': ['c0', 'c2', 'c3'],
....: 'd': ['d0', 'd2', 'd3']},
....: index=['k0', 'k2', 'k3'])
....:
in [86]: result = left.join(right)
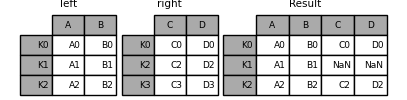
可以指定how来指定连接方式:
in [87]: result = left.join(right, how='outer')
默认join是按index来进行连接。
还可以按照列来进行连接:
in [91]: left = pd.dataframe({'a': ['a0', 'a1', 'a2', 'a3'],
....: 'b': ['b0', 'b1', 'b2', 'b3'],
....: 'key': ['k0', 'k1', 'k0', 'k1']})
....:
in [92]: right = pd.dataframe({'c': ['c0', 'c1'],
....: 'd': ['d0', 'd1']},
....: index=['k0', 'k1'])
....:
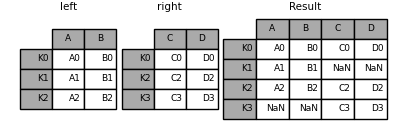
in [93]: result = left.join(right, on='key')
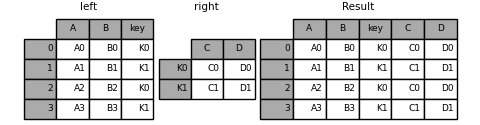
单个index和多个index进行join:
in [100]: left = pd.dataframe({'a': ['a0', 'a1', 'a2'],
.....: 'b': ['b0', 'b1', 'b2']},
.....: index=pd.index(['k0', 'k1', 'k2'], name='key'))
.....:
in [101]: index = pd.multiindex.from_tuples([('k0', 'y0'), ('k1', 'y1'),
.....: ('k2', 'y2'), ('k2', 'y3')],
.....: names=['key', 'y'])
.....:
in [102]: right = pd.dataframe({'c': ['c0', 'c1', 'c2', 'c3'],
.....: 'd': ['d0', 'd1', 'd2', 'd3']},
.....: index=index)
.....:
in [103]: result = left.join(right, how='inner')
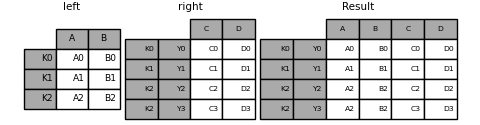
列名重复的情况:
in [122]: left = pd.dataframe({'k': ['k0', 'k1', 'k2'], 'v': [1, 2, 3]})
in [123]: right = pd.dataframe({'k': ['k0', 'k0', 'k3'], 'v': [4, 5, 6]})
in [124]: result = pd.merge(left, right, on='k')
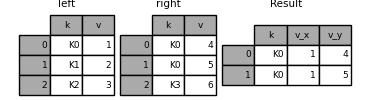
可以自定义重复列名的命名规则:
in [125]: result = pd.merge(left, right, on='k', suffixes=('_l', '_r'))

覆盖数据
有时候我们需要使用df2的数据来填充df1的数据,这时候可以使用combine_first:
in [131]: df1 = pd.dataframe([[np.nan, 3., 5.], [-4.6, np.nan, np.nan], .....: [np.nan, 7., np.nan]]) .....: in [132]: df2 = pd.dataframe([[-42.6, np.nan, -8.2], [-5., 1.6, 4]], .....: index=[1, 2]) .....:
in [133]: result = df1.combine_first(df2)
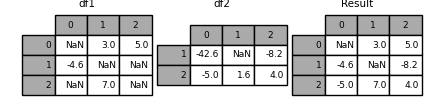
或者使用update:
in [134]: df1.update(df2)
到此这篇关于pandas中dataframe合并的实现的文章就介绍到这了,更多相关pandas dataframe合并内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论